主要是摘取书中,个人感觉比较重要的内容。
文章目录
- 第一部分 熟知Go的一切
- 理解Go的设计哲学
- 使用Go语言原生编程思维写Go代码
- 第二部分 项目结构、代码风格和标识符命名
- 第三部分 声明、类型、语句与控制结构
- 13 了解切片的底层原理
- 14 了解Map实现原理并高效使用
- 15. string类型
- 16. 理解Go语言的包导入
- 17 理解Go语言表达式的求值顺序
- 19 了解控制语句惯用法
- 第四部分 函数和方法
- 20. 包级别的init函数
- 21. 让自己习惯于函数是一等公民
- 22. 使用defer让函数更简单更健壮
- 23 理解方法的本质以及选择正确的receiver类型
- 24 方法集合决定接口实现
- 25. 变长参数函数的妙用
- 第五部分 接口
- 26 了解接口类型变量的内部表示
- 27 尽量定义小接口
- 29 使用接口作为程序水平组合的连接点
- 第六部分 并发编程
- 31 优先考虑并发设计
- 32 了解goroutine的调度原理
- 33 掌握Go并发模型和常见的并发模式
- 34 Channel 的理解
- 35 了解sync包的正确用法
- 第七部分 错误处理
- 37 了解错误处理的4种策略
- 38 尽量优化反复出现的if err != nil
- 39 不要使用panic进行正常的错误处理
第一部分 熟知Go的一切
理解Go的设计哲学
- 追去简单,少就是多。Go设计者推崇最简单方式思维,事情仅有一种或者尽可能少的方式去完成。Go的复杂性被go设计者所隐藏。比方:通过大小写来说明是不是要暴露接口。
- 水平和垂直组合。接口与实现之间隐士关联,包之间是相互独立的,没有子包概念。通过类型嵌入,快速让一个新类型复用其他类型已经实现的能力,实现功能垂直扩展。这似乎是其他语言没有实现的功能点。例子:
// $GOROOT/src/sync/pool.go
type poolLocal struct {
private interface{}
shared []interface{}
Mutex
pad [128]byte
}
poolLocal中嵌入了Mutex。所有poolLocal有了Mutex的Lock和Unlock方法,在实际调用中,方法调用会被传给poolLocal的Mutex实例。通过Interface实现水平组合,将程序各个部分组合在一起。通过Interface将程序各个部分组合在一起的方式,笔者称为水平组合。
3. 原生并发。面向多核的。传统的多线程是,操作系统对进程,线程进行调度,因此消耗资源多。而go是实现了自己一套goroutine,然后对操作系统而言只是调度了go,至于如何多线程是go关心的事情,go实现了自己的一套goroutine调度器。并发是将一个程序分解成多个小片段并且每个小片段都可以独立执行的程序设计方法。
4. 面向工程,自带电池。故意不支持默认函数参数,因为默认函数参数,会降低清晰度和可读性。并且标准库功能丰富,多数功能无需依赖第三方包。
使用Go语言原生编程思维写Go代码
不能影响到你的编程思维方式的编程语言不值得学习和使用。Go语言的编程思维,会随着本书的阅读,越发清晰。
第二部分 项目结构、代码风格和标识符命名
- 使用gofmt 对代码进行format。
- Go官方要求标识符命名采用驼峰命名法。变量名不要带类型信息。
- 循环和条件变量多采用单个字母命名;
- 函数/方法的参数和返回值变量以单个单词或单个字母为主;
- 由于方法在调用时会绑定类型信息,因此方法的命名以单个单词为主;
- 函数多以多单词的复合词进行命名;类型多以多单词的复合词进行命名。
- 常量通常用大写的单词命名。
- 接口一般是 方法名 + er的命名
第三部分 声明、类型、语句与控制结构
- 使用iota实现枚举常量。
- 尽量定义零值可用的类型。Go语言每个原生类型都有默认值。整型:0,浮点类型:0.0,布尔: false,字符串: “”,指针,interface,slice, channel,map,function: nil。
13 了解切片的底层原理
传递数组是指拷贝,切片之于数组,就像是文件描述符之于文件。Go语言中,数组承担的是底层存储空间的角色,切片则是为底层的数组打开了一个访问的窗口。所以,切片是数组的“描述符”。
切片的内部表述:
//$GOROOT/src/runtime/slice.go
type slice struct {
array unsafe.Pointer // 指向下层数组的某元素的指针,该元素也是切片的起始元素。
len int // 切片的长度
cap int // 切片的最大容量
}
假设创建一个切片实例: s:= make([]byte, 5)。运行时层面的内部表示如下:

当切片作为函数参数传递给函数时,实际传递的是切片的内部表示,也就是runtime.slice结构,所以节省空间,没有数组的拷贝。
另外切片还有动态扩容的特性。动态扩容带来的是性能损耗,需要复制数组。因此,如果可以预估切片底层数组需要承载的元素数量,强烈建议在创建切片时带上cap参数。
14 了解Map实现原理并高效使用
Map不支持零值可用。Map也是引用类型,将map类型变量作为函数参数传入不会有很大的性能损耗。
最佳实践是总是使用comma ok 惯用法来读取map中的值。
m := map[string]int
v, ok := m["key"]
if !ok {
// key 不在map中
}
fmt.Println(v)
// 删除数据
delete(m, "key2") // 即使删除的数据在map中不存在,delete也不会导致panic
map不支持并发读写。并且尽量使用cap参数类创建map。
15. string类型
string类型底层存储。
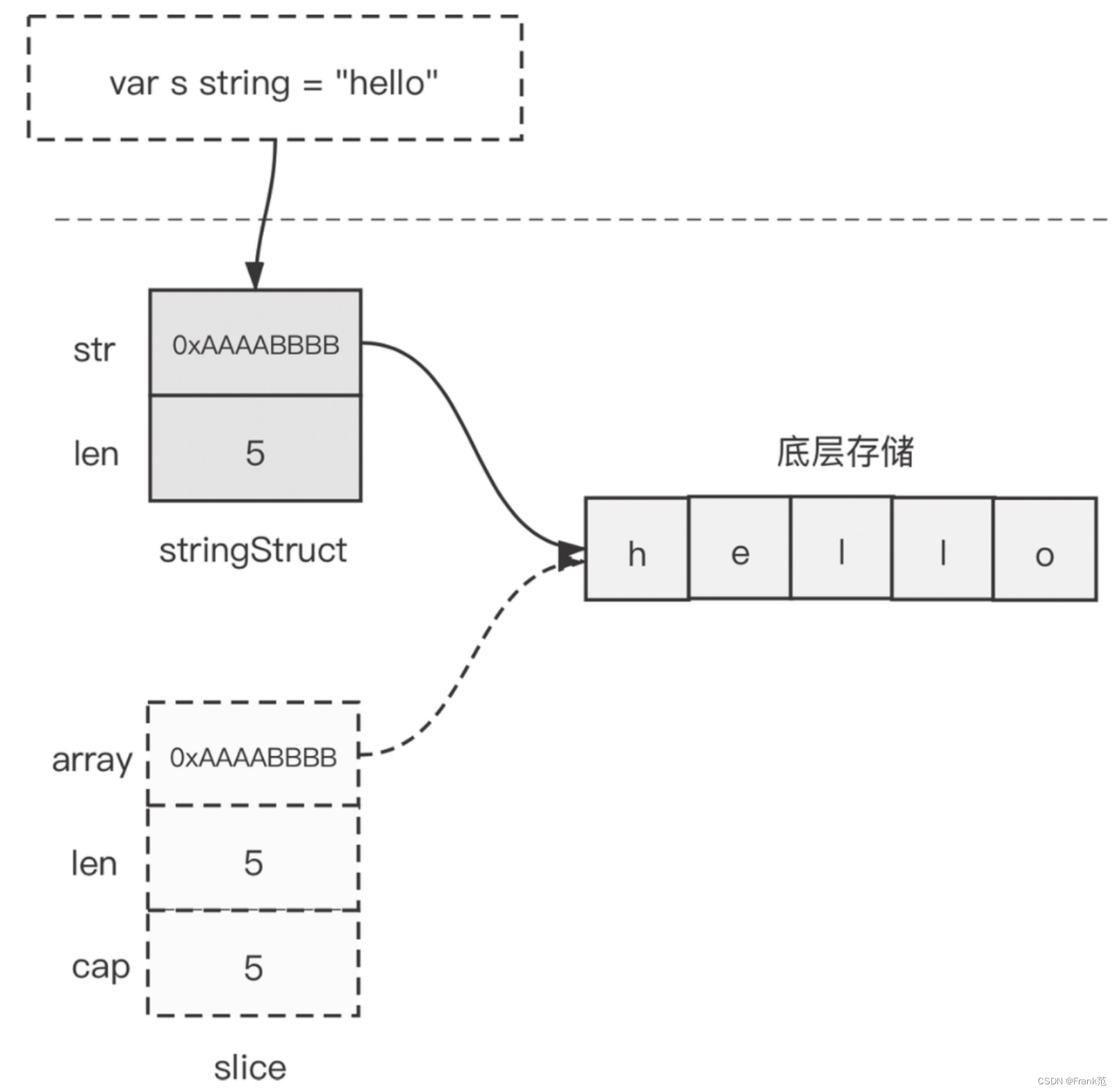
// $GOROOT/src/runtime/string.go
type stringStruct struct {
str unsafe.Pointer
len int
}
sring类型是一个描述符,本身并不真正存储数据,而是由一个指向底层存储的指针和字符串长度组成。
string类型通过函数/方法参数传入也不会有太多的损耗,因为传入的仅仅是一个“描述符”,而不是真正的字符串数据。
byte string 相互转换:
s := "haofan"
byteS := []byte(s)
h := string(byteS)
16. 理解Go语言的包导入
- Go 程序构建过程。先编译成.a文件,再把.a文件,链接成.o文件。
- Go包导入语句中import后面的部分是一个路径,路径的最后一个分段是目录名而不是包名。
17 理解Go语言表达式的求值顺序
- 包级别变了初始化,按照变量声明先后顺序进行,a = b + c ,则是从c开始算。
- Go规定表达式操作数中的所有函数、方法以及channel操作从左到右的次序进行求值。
- 另外,赋值语句求值,是按照从左到右的顺序对变量进行赋值。
19 了解控制语句惯用法
- 使用if语句遵循快乐路径原则。所谓,快乐路径:
- 出现错误时,快速返回。成功逻辑,不要嵌入if-else中,返回值一般在函数最后一行。
- for range 闭坑。用短变量 := 赋值,
- 参与迭代的是range表达式的副本,所以如果在range语句内,修改数组值,则原数组不变。如果要修改数组,则需要用数组指针。
// chapter3/sources/control_structure_idiom_2.go
...
func pointerToArrayRangeExpression() {
var a = [5]int{1, 2, 3, 4, 5}
var r [5]int
fmt.Println("pointerToArrayRangeExpression result:")
fmt.Println("a = ", a)
for i, v := range &a {
if i == 0 {
a[1] = 12
a[2] = 13
}
r[i] = v
}
fmt.Println("r = ", r)
fmt.Println("a = ", a)
}
- break 语句跳到哪里。是跳到同一函数内break语句所在的最内层的for, switch或select的执行。go 是可以通过定义label的方式,指定break到哪里?
第四部分 函数和方法
20. 包级别的init函数
main包中,Go运行时,会按照常量->变量->init函数的顺序进行初始化。
init函数特点: 运行时调用、顺序、仅执行一次。通过init函数的注册模式:
import (
"database/sql"
_ "github.com/lib/pq"
)
func main() {
db, err := sql.Open("postgres", "user=pqgotest dbname=pqgotest sslmode=verify-full")
if err != nil {
log.Fatal(err)
}
age := 21
rows, err := db.Query("SELECT name FROM users WHERE age = $1", age)
...
}
神奇的地方是,在import pg package后,似乎没有地方调用,奥秘全在:
// github.com/lib/pq/conn.go
...
func init() {
sql.Register("postgres", &Driver{})
}
...
pg包的Init函数执行后,pg包将自己实现的dirver注册到sql包中。这样,在应用层代码在打开数据库的时候传入驱动的名字(postgress),通过sql.Open返回的句柄,就是pg这个驱动的相应实现。
21. 让自己习惯于函数是一等公民
如果一门编程语言对某种语言元素的创建和使用没有限制,我们可以像对待value一样对待这种语法元素,那么我们就称这种语法元素是这门编程语言的"一等公民"。
满足的条件成为一等公民(像普通整型值那样被创建和使用):
- 在函数内创建,也就是在函数内定义一个新的函数。
- 作为类型,使用函数来自定义类型。type HandlerFunc func(ReponseWriter, *Request)
- 存储到变量中。
- 作为参数传入函数。
- 作为返回值从函数返回。
例子:
func greeting(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "Welcome, Gopher!\n")
}
func main() {
http.ListenAndServe(":8080", http.HandlerFunc(greeting))
}
func ListenAndServe(addr string, handler Handler) error {
server := &Server{Addr: addr, Handler: handler}
return server.ListenAndServe()
}
// $GOROOT/src/net/http/server.go
// HandlerFunc是一个机遇函数定义的新类型,它的底层类型为func(ResponseWriter, *Request),该类型有一个方法是ServeHTTP
// 因而实现了Handler接口。http.HandlerFunc(greeting)这句代码的真正含义
// 是将函数greeting显式转换为HandlerFunc类型,而后者实现了Handler接口
// 这样转型后的greeting就满足了ListenAndServe函数第二个参数的要求。
type HandlerFunc func(ResponseWriter, *Request)
// ServeHTTP调用f(w, r)
func (f HandlerFunc) ServeHTTP(w ResponseWriter, r *Request) {
f(w, r)
}
// 接口handler
type Handler interface {
ServeHTTP(ResponseWriter, *Request)
}
22. 使用defer让函数更简单更健壮
按照后进先出的顺序,调度执行defer
23 理解方法的本质以及选择正确的receiver类型
方法和函数的区别是,方法需要有receiver。
Go方法的本质:一个以方法所绑定类型实例为第一个参数的普通函数。
如果没有对类型实例修改的需求,那么为receiver选择T类型或T类型均可;但考虑到Go方法调用时,receiver是以值复制的形式传入方法中的,如果类型的size较大,以值形式传入会导致较大损耗,这时选择T作为receiver类型会更好些。
24 方法集合决定接口实现
Go语言的一个创新是,自定义类型与接口之间的实现关系是松耦合的。如果某个自定义类型T的方法集合是某个接口类型方法集合的超集,那么就说类型T实现了该接口,并且类型T的变量可以被赋值给该接口类型的变量,也就是方法集合决定接口实现。
类型T的方法集合是以T为receiver类型的所有方法的集合,类型T的方法集合是以T为receiver类型的所有方法的集合与类型T方法集合的并集;
25. 变长参数函数的妙用
什么是变长参数函数:
func sum(args ...int) int {
var total int
for _, v := range args {
total += v
}
return total
}
Go 语言不支持函数重载,那通过变长函数如何实现呢? 如下。同样也可以通过变长函数实现默认参数,但是这种做法其实比较丑陋。
// chapter4/sources/variadic_function_5.go
func concat(sep string, args ...interface{}) string {
var result string
for i, v := range args {
if i != 0 {
result += sep
}
switch v.(type) {
case int, int8, int16, int32, int64,
uint, uint8, uint16, uint32, uint64:
result += fmt.Sprintf("%d", v)
case string:
result += fmt.Sprintf("%s", v)
case []int:
ints := v.([]int)
for i, v := range ints {
if i != 0 {
result += sep
}
result += fmt.Sprintf("%d", v)
}
case []string:
strs := v.([]string)
result += strings.Join(strs, sep)
default:
fmt.Printf("the argument type [%T] is not supported", v)
return ""
}
}
return result
}
func main() {
println(concat("-", 1, 2))
println(concat("-", "hello", "gopher"))
println(concat("-", "hello", 1, uint32(2),
[]int{11, 12, 13}, 17,
[]string{"robot", "ai", "ml"},
"hacker", 33))
}
功能选项模式:
// chapter4/sources/variadic_function_9.go
type FinishedHouse struct {
style int // 0: Chinese; 1: American; 2: European
centralAirConditioning bool // true或false
floorMaterial string // "ground-tile"或"wood"
wallMaterial string // "latex"或"paper"或"diatom-mud"
}
type Option func(*FinishedHouse)
func NewFinishedHouse(options ...Option) *FinishedHouse {
h := &FinishedHouse{
// default options
style: 0,
centralAirConditioning: true,
floorMaterial: "wood",
wallMaterial: "paper",
}
for _, option := range options {
option(h)
}
return h
}
func WithStyle(style int) Option {
return func(h *FinishedHouse) {
h.style = style
}
}
func WithFloorMaterial(material string) Option {
return func(h *FinishedHouse) {
h.floorMaterial = material
}
}
func WithWallMaterial(material string) Option {
return func(h *FinishedHouse) {
h.wallMaterial = material
}
}
func WithCentralAirConditioning(centralAirConditioning bool) Option {
return func(h *FinishedHouse) {
h.centralAirConditioning = centralAirConditioning
}
}
func main() {
fmt.Printf("%+v\n", NewFinishedHouse()) // 使用默认选项
fmt.Printf("%+v\n", NewFinishedHouse(WithStyle(1),
WithFloorMaterial("ground-tile"),
WithCentralAirConditioning(false)))
}
第五部分 接口
Go语言推崇面向组合编程,接口是组合编程的重要手段。接口是Go这门静态类型语言中唯一“动静兼备”的语言特性。
当一个接口类型变量被赋值时,编译器会检查右值的类型是否实现了该接口方法集合中的所有方法。
接口类型变量在程序运行时可以被赋值为不同的动态类型变量,从而支持运行时多态。
26 了解接口类型变量的内部表示
接口类型变量在运行时表示为eface和iface,eface用于表示空接口类型变量,iface用于表示非空接口类型变量;当且仅当两个接口类型变量的类型信息(eface._type/iface.tab._type)相同,且数据指针(eface.data/iface.data)所指数据相同时,两个接口类型才是相等的;通过println可以输出接口类型变量的两部分指针变量的值;可通过复制runtime包eface和iface相关类型源码,自定义输出eface/iface详尽信息的函数;接口类型变量的装箱操作由Go编译器和运行时共同完成。
27 尽量定义小接口
Go语言中接口与实现之间是隐式的,实现者仅需实现接口方法集中的全部方法,便算是自动遵守了契约,实现了该接口。接口的方法数量尽量控制在1~3个。
小接口优势:
- 接口越小,抽象度越高,被接纳度越高
- 易于实现和测试。
- 契约职责单一,易于复用组合。
29 使用接口作为程序水平组合的连接点
如果说C++和Java是关于类型层次结构和类型分类的语言,那么Go则是关于组合的语言。 — Rob Pike Go语言之父
Go的组合方式:
- 垂直组合。Go通过类型嵌入机制实现垂直组合,进而实现方法实现的复用、接口定义重用等。
- 水平组合。Go程序以接口类型变量作为程序水平组合的连接点。接口好比人体的关节,连接人体不同的部分。
以接口为连接点的水平组合的几种形式:
- 基本形式。接受接口类型参数的函数和方法。
func YourFuncName(param InterfaceType) - 包裹函数。接受接口类型参数,并返回与其参数类型相同的返回值。
func YourWrapperFunc(param InterfaceType) InterfaceType通过包裹函数可以实现对输入数据的过滤,装饰,变换等操作,并将结果再次返回给调用者。
例子:
// chapter5/sources/horizontal-composition-2.go
func CapReader(r io.Reader) io.Reader {
return &capitalizedReader{r: r}
}
type capitalizedReader struct {
r io.Reader
}
func (r *capitalizedReader) Read(p []byte) (int, error) {
n, err := r.r.Read(p)
if err != nil {
return 0, err
}
q := bytes.ToUpper(p)
for i, v := range q {
p[i] = v
}
return n, err
}
func main() {
r := strings.NewReader("hello, gopher!\n")
r1 := CapReader(io.LimitReader(r, 4))
if _, err := io.Copy(os.Stdout, r1); err != nil {
log.Fatal(err)
}
}
- 适配器函函数类型。
- 中间件。在Go web中,常常指的是一个实现了http.Handler接口的http.HandlerFunc类型实例。
// chapter5/sources/horizontal-composition-4.go
func validateAuth(s string) error {
if s != "123456" {
return fmt.Errorf("%s", "bad auth token")
}
return nil
}
func greetings(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "Welcome!")
}
func logHandler(h http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
t := time.Now()
log.Printf("[%s] %q %v\n", r.Method, r.URL.String(), t)
h.ServeHTTP(w, r)
})
}
func authHandler(h http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
err := validateAuth(r.Header.Get("auth"))
if err != nil {
http.Error(w, "bad auth param", http.StatusUnauthorized)
return
}
h.ServeHTTP(w, r)
})
}
func main() {
http.ListenAndServe(":8080", logHandler(authHandler(http.HandlerFunc(greetings))))
}
另外使用接口接口可以降低耦合,从而更好的方便代码测试。 例子
第六部分 并发编程
31 优先考虑并发设计
并发不是并行,并发关乎结构,并行关乎执行 – Rob Pike
并发与并行区别:
- 并行方案:处理器核数充足的情况下启动多个单线程应用的实例,这样每个实例运行在一个核上。这种方案是有约束的,对于不支持在同一环境下部署多实例。
- 并发方案:并发是重新做应用结构设计,将应用分解成多个基本执行单元中执行。应用内部拆分成多个可独立运行的模块。这样虽然应用仍然以单例方法运行,但其中内部模块都运行一个单独的操作系统线程中,多核资源得以充分利用。
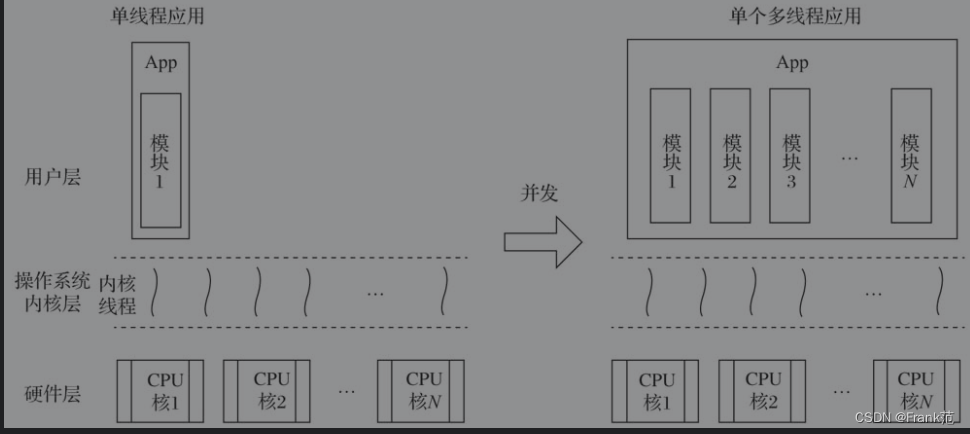
传统编程语言,是基于多线程模型设计的,是以操作系统线程作为承载分解后的代码片段的执行单元,由操作系统执行调度。
而Go语言并未使用操作系统线程作为承载分解后的代码片段的基本执行单元,而是实现了goroutine这一由go运行时负责调度的用于层轻量级线程提供原生支持。goroutine相比传统操作系统线程的优势:
- 资源占用小。每个goroutine初始栈大小仅为2KB。
- Goroutine上下文切换代价小。
- 语言原生支持。又go关键字。
- 语言内置channel,作为goroutine通信机制。
因为Go是面向并发而生的,应用设计阶段,优先考虑并发。
典型例子: link
32 了解goroutine的调度原理
Go运行时负责对goroutine进行调度,调度就是决定何时哪个goroutine将获得资源开始执行,哪个goroutine应该停止执行让出资源等。
GPM调度模型:
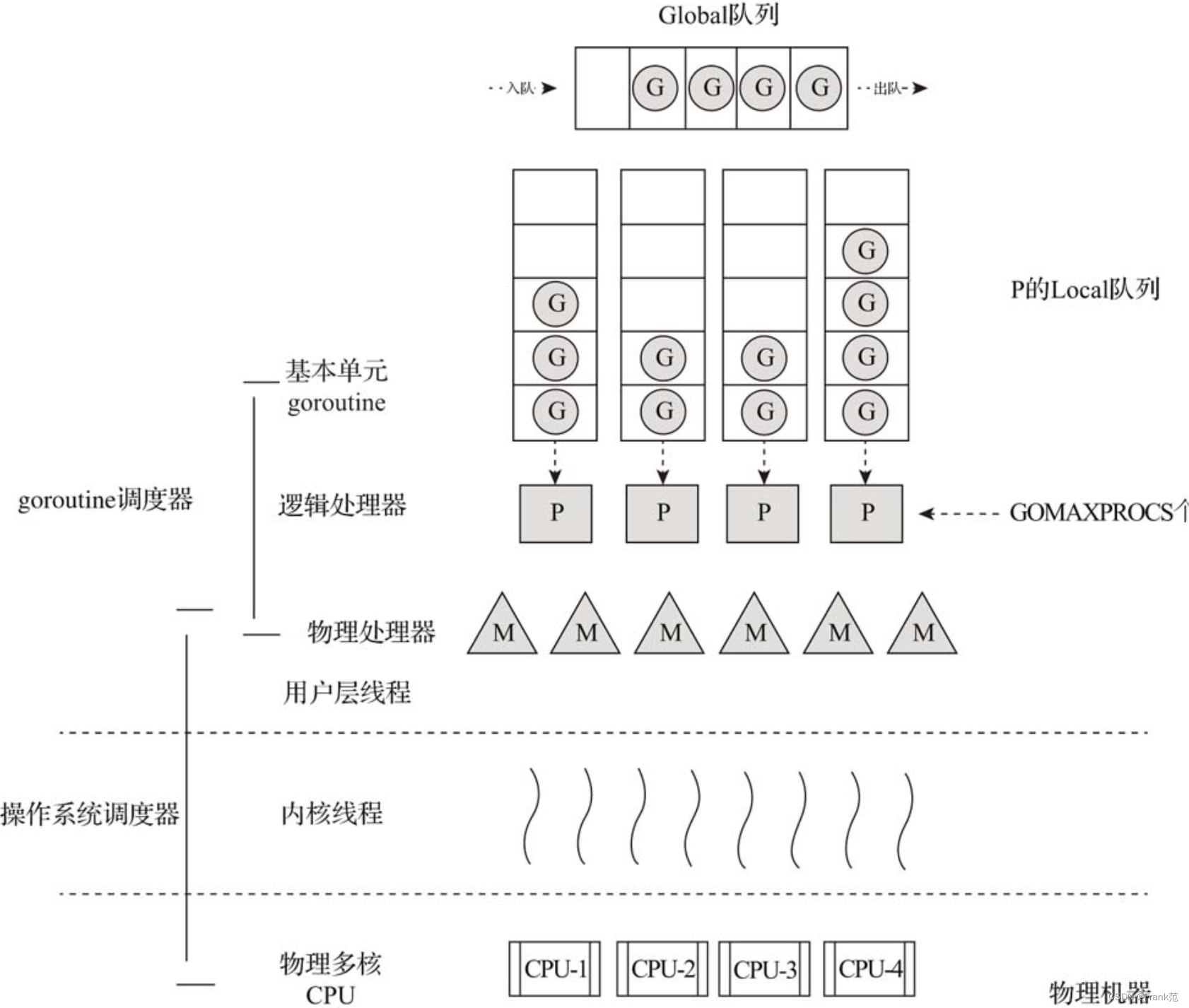
其中,P是一个逻辑处理器,每个G要想真正运行起来,首先需要被分配一个P,即进入P的本地运行队列中。对于G来说,P就是运行它的CPU。但从goroutine调度来说,真正的CPU是M,只有将P和M绑定才能让P本地运行队列中的G真正运行起来。
- G: 代表goroutine,存储了goroutine的执行栈信息,goroutine状态以及任务函数等。
- P:代表processor,p的数量决定了系统内最大可并行的G的数量。
- M:代表真正的执行计算资源。在绑定有效的P后,进行一个调度循环。调度循环的机制大致是从各种队列、P的本地队列中获取G,然后执行G的函数。
问题:为什么在死循环的情况下,多个goroutine依旧会被调度并轮流执行 ?
// chapter6/sources/go-scheduler-model-case1.go
func deadloop() {
for {
}
}
func main() {
go deadloop()
for {
time.Sleep(time.Second * 1)
fmt.Println("I got scheduled!")
}
}
$go run go-scheduler-model-case1.go
I got scheduled!
I got scheduled!
I got scheduled!
...
因为P的数量是CPU的核数,上面的例子启动后,创建了两个P,main goroutine一个P,for loop一个P,所以会执行。
33 掌握Go并发模型和常见的并发模式
传统编程语言是基于共享内存的并发模型。Go语言是通过channel来实现。
Go的并发原语:
- goroutine: 封装了数据的处理逻辑,是go运行时调度的基本执行单元。
- channel: 用于goroutine之间的通信和同步。
- select: 用于应对多路输入、输出,可以让goroutine同时协调处理多个channel操作
1 等待一个goroutine的退出, 例子。mian goroutine在创建完新的goroutine后,便在channel上阻塞等待,直到新goroutine退出前向该channel发送了一个信号。
2 等待多个goroutine的退出,例子。通过sync.WaitGroup方法
3 支持超时机制的等待。通过timer
// chapter6/sources/go-concurrency-pattern-4.go
func main() {
done := spawnGroup(5, worker, 30)
println("spawn a group of workers")
timer := time.NewTimer(time.Second * 5)
defer timer.Stop()
// 通过select原语同时监听timer.C和done两个channel,哪个先返回数据就执行哪个case 分支
select {
case <-timer.C:
println("wait group workers exit timeout!")
case <-done:
println("group workers done")
}
}
34 Channel 的理解
channel是go的一等公民。我们可以像使用普通变量那样使用channel。
c := make(chan int) // 创建一个无缓冲(unbuffered)的int类型的channel
c := make(chan int, 5) // 创建一个带缓冲的int类型的channel
c <- x // 向channel c中发送一个值
<- c // 从channel c中接收一个值
x = <- c // 从channel c接收一个值并将其存储到变量x中
x, ok = <- c // 从channel c接收一个值。若channel关闭了,ok将被置为false
for i := range c { ... } // 将for range与channel结合使用
close(c) // 关闭channel c
c := make(chan chan int) // 创建一个无缓冲的chan int类型的channel
func stream(ctx context.Context, out chan<- Value) error // 将只发送(send-only) channel作为函数参数
func spawn(...) <-chan T // 将只接收(receive-only)类型channel作为返回值
当需同时对多个channel进行操作时,会使用select。通过select,可以同时在多个channel上进行发送、接收操作。
select {
case x := <-c1: // 从channel c1接收数据
...
case y, ok := <-c2: // 从channel c2接收数据,并根据ok值判断c2是否已经关闭
...
case c3 <- z: // 将z值发送到channel c3中
...
default: // 当上面case中的channel通信均无法实施时,执行该默认分支
}
收发操作:
- channel的收发操作都是向左的箭头
(<-),data = <- chanX,表示向从channel里接收数据。chanX <- data表示发送数据到channel。 - 读出操作可以是
data := <-chanX 、 data = <-chanX 、 _ = <-chanX 、 <-chanX、 、 data, ok := <-chanX
Channel具有先进先出(FIFO)的性质,内部确定使用了循环队列。
- buffered channel,
chanX := make(chan int, 3). 当发送者向channel发送数据而接收者还没有就绪时,如果buffer未满,就会将数据放入buffer; - unbuffered channel,
chanX := make(chan int). 由于没有暂存数据的地方,unbuffered channel的数据传输只能是同步的,即只有读写双方都就绪时,通信才能成功。如果一方没有ready,则会阻塞。
mychan := make(chan int)
go func() {
fmt.Println("Send 100")
mychan <- 100
fmt.Println("Has sent")
}()
# 如果comment下面的代码,则只会输出"Send 100",因为channel被阻塞了。
<-mychan
time.Sleep(time.Second * time.Duration(1))
发送步骤:
- 如果存在阻塞等待的接收者(goroutine),那么直接将待发送的数据交给"等待接收队列"中的第一个goroutine。
- 如果不存在。若buffer还有空间,则将待发送的数据送到buffer的队尾。若buffer没有空间,则将发送者(goroutine)和要发送的数据打包成一个struct,加入到等待发送队列的队尾,同时将该发送者block。
接收步骤:
3. 如果存在阻塞等待的发送者。若buffer已满,从buffer中取出首元素交给接收者,同时将对应的goroutine唤醒。若没有buffer,从等待发送队列中取出对首元素,将要发送的数据copy给接收者,并将goroutine唤醒。
4. 如果没有在阻塞等待的发送者。若buffer有数据,则取出首元素给接收者。若buffer空,那么将接收者block。
for range 读取select:
5. 如果发送端不是一直发数据,且没有关闭channel,那么,for range读取会陷入block,道理很简单,没有数据可读了。所以,要么您能把控全局,确保您的for range读取不会block;要么,别用for range读channel。
6. select不是loop,当它select了一个case执行后,整个select就结束了。所以,如果想要一直select,那就在select外层加上for吧。
35 了解sync包的正确用法
Go语言在提供CSP并发模型原语的同时,还通过sync包提供了传统的基于共享内存并发模型的基本同步原语。包括sync.Mutex(互斥锁),sync.RWMutex(读写锁),sync.Cond(条件变量)。
可以使用sync.Once实现单例模式。
第七部分 错误处理
写出高质量的Go代码,我们需要始终想着错误处理。
37 了解错误处理的4种策略
构造错误值。任何实现了Error() string方法类型的实例均可作为错误复制给error 接口变量。
err := errors.New("your first demo error")
errWithCtx = fmt.Errorf("index %d is out of bounds", i)
wrapErr = fmt.Errorf("wrap error: %w", err) // 仅Go 1.13及后续版本可用
- 透明错误处理策略。不关心返回错误值携带的具体上下文信息,只要发生错误就进入唯一的错误处理执行路径。80%都是这种错误处理策略。
err := doSomething()
if err != nil {
// 不关心err变量底层错误值所携带的具体上下文信息
// 执行简单错误处理逻辑并返回
...
return err
}
- 哨兵 错误处理策略
// $GOROOT/src/bufio/bufio.go
var (
ErrInvalidUnreadByte = errors.New("bufio: invalid use of UnreadByte")
ErrInvalidUnreadRune = errors.New("bufio: invalid use of UnreadRune")
ErrBufferFull = errors.New("bufio: buffer full")
ErrNegativeCount = errors.New("bufio: negative count")
)
// 错误处理代码
data, err := b.Peek(1)
if err != nil {
switch err {
case bufio.ErrNegativeCount:
// ...
return
case bufio.ErrBufferFull:
// ...
return
case bufio.ErrInvalidUnreadByte:
// ...
return
default:
// ...
return
}
}
// 或者
if err := doSomething(); err == bufio.ErrBufferFull {
// 处理缓冲区满的错误情况
...
}
- 错误值类型检视策略
- 错误行为特征检视策略
38 尽量优化反复出现的if err != nil
优化反复出现的if err != nil代码块的根本目的是让错误检查和处理较少,不要干扰正常业务代码,让正常业务代码更具视觉连续性。大致有两个努力的方向。
- 改善代码的视觉呈现。
func SomeFunc() error {
err := doStuff1()
if err != nil {
// 处理错误
}
err = doStuff2()
if err != nil {
// 处理错误
}
err = doStuff3()
if err != nil {
// 处理错误
}
}
- 重构:减少if err != nil 的重复次数
- 内置error 状态