synchronized的优化策略
- 一:synchronized 的"自适应"
- 1.1:偏向锁
- 二:锁消除
- 三:锁粗化
一:synchronized 的"自适应"
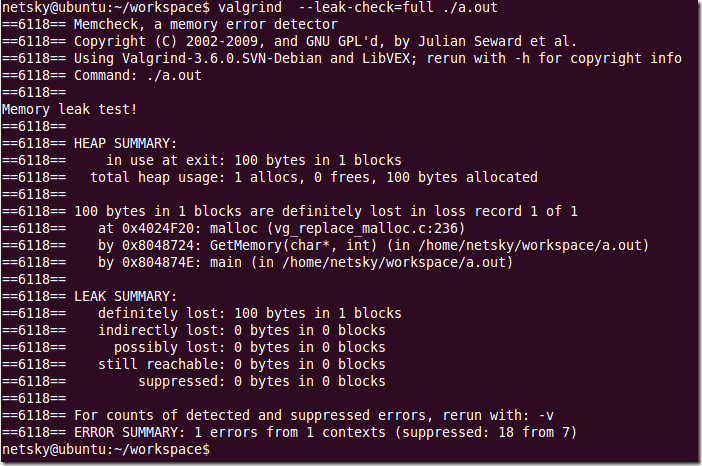
锁升级的过程:
(1)未加锁的状态(无锁)
当代码中开始调用执行synchronized
(2)偏向锁
遇到锁冲突
(3)轻量级锁
冲突进一步提升
(4)重量级锁
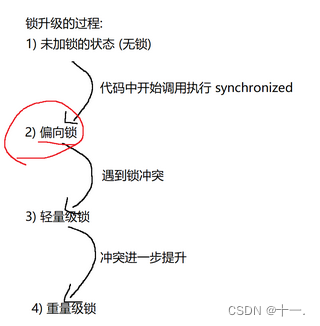
上述的升级过程,针对一个锁对象来说,是不可逆的,只能升级,不能降级,一旦升级到了重量级锁,不会回退到轻量级锁(当前JVM里面的做法)
1.1:偏向锁
首次使用synchronized对对象进行加锁的时候,不是真的加锁,而只是做一个"标记"(非常轻量,几乎没有开销),如果没有别的线程尝试对这个对象加锁,就可以保持这个状态,一直到解锁(解锁也就是修改一个上述标记,也几乎没有开销).
上述过程,就相当于没有任何加锁操作,速度是非常快的.
但是,如果在偏向锁状态下,有某个线程也尝试对这个对象加锁,立即把偏向锁升级成了轻量级锁(真的加锁了,真的有互斥了).
本质上,偏向锁策略就是"懒"字具体体现,能不加锁,就不加锁,能晚加锁,就晚加锁,在很多时候能够把加锁的开销给省下.
二:锁消除
锁消除实际上是编译器的优化策略.
编译器优化:要确保优化前的逻辑和优化后的是等价的.
你代码里写了加锁操作,编译器和JVM对对你当前的代码做出判定,看这个地方到底是不是真的需要加锁,如果这里不需要加锁,就会自动的把这个加锁操作给优化掉.
比如:只有一个线程的时候,使用synchronized,不会产生线程安全问题,从而编译器就会把加锁操作给优化掉.
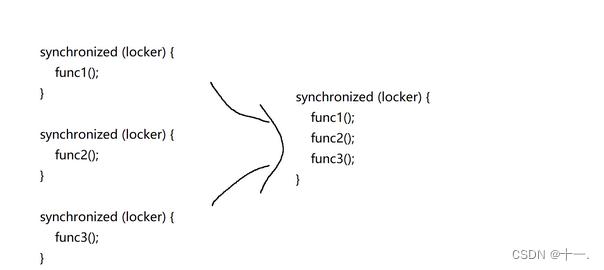
三:锁粗化
锁的粒度:指的是:加锁的范围内,包含多少代码,包含的代码越多,锁的粒度就越粗,反之,锁的粒度就越细.
锁粗化,也是一种加锁优化策略
有些逻辑中,需要频繁的加锁解锁,编译器就会自动的把多次细粒度的锁,合并成一次粗粒度的锁.
举个栗子:
有一天,领导给你安排了三个工作,你做完了,要给领导汇报工作.
有两种方法:
(1)分三次给领导打电话,每次打电话,都是对领导的加锁过程,这个过程是比较低效的,每次打电话,都可能会涉及到锁竞争,都可能要阻塞等待.
(2)一次电话,把三个事情都说清楚,一次加锁即可.