这次应该是互联网及软件行业的第三次寒潮,大家在寒潮中一定要继续保持学习,寒潮挺过去以后还是会迎来新的发展机遇。
有粉丝去阿里面试,跟码哥分享了其中一题面试问题「如何将重复性比较高的 String 类型的地址信息从 20GB 降到几百兆?」。
今天,码哥从多个角度带你完全攻克这个知识点,让面试官眼前一亮。
切入正文......
莫慌,今天给大家见识一下不一样的 String,从根上拿捏直达 G 点。
并且码哥分享一个例子:通过性能调优我们能实现百兆内存轻松存储几十 G 数据。
String对象是我们每天都「摸」的对象类型,但是她的性能问题我们却总是忽略。
爱她,不能只会简单一起玩耍,要深入了解String 的内心深处,做一个「心有猛虎,细嗅蔷薇」的暖男。
通过以下几点分析,我们一步步揭开她的衣裳,直达内心深处,提升一个 Level,让 String 直接起飞。
String 身体解密
想要深入了解,就先从基本组成开始……
「String 缔造者」对 String 对象做了大量优化来节省内存,从而提升 String 的性能:
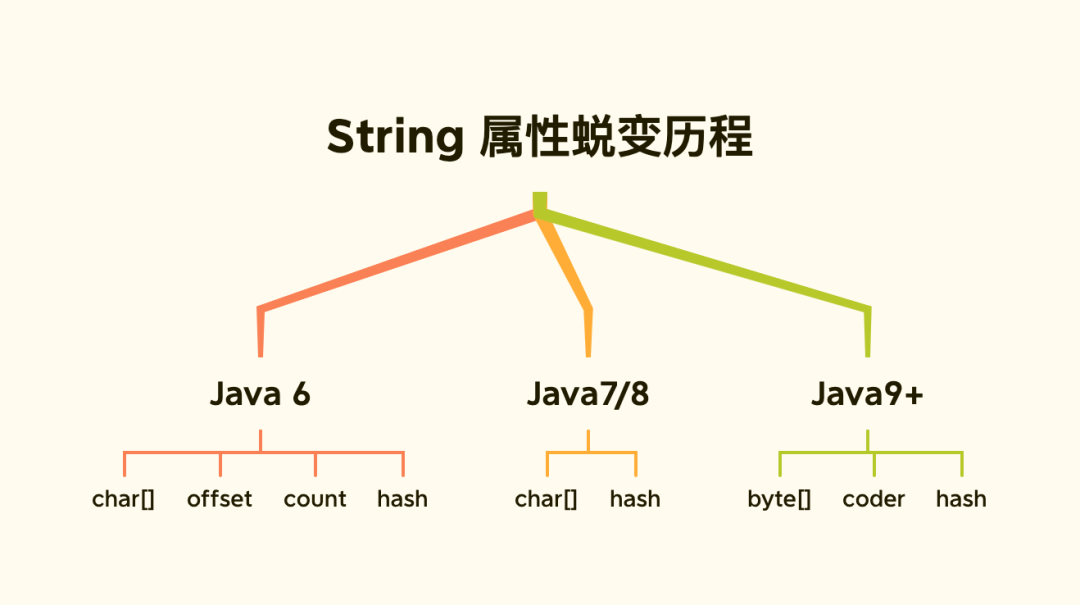
Java 6 及之前
数据存储在 char[]数组中,String通过 offset 和 count两个属性定位 char[] 数据获取字符串。
这样可以高效快速的定位并共享数组对象,并且节省内存,但是有可能导致内存泄漏。
共享 char 数组为啥可能会导致内存泄漏呢?
String(int offset, int count, char value[]) {
this.value = value;
this.offset = offset;
this.count = count;
}
public String substring(int beginIndex, int endIndex) {
//check boundary
return new String(offset + beginIndex, endIndex - beginIndex, value);
}调用 substring() 的时候虽然创建了新的字符串,但字符串的值 value 仍然指向的是内存中的同一个数组,如下图所示:
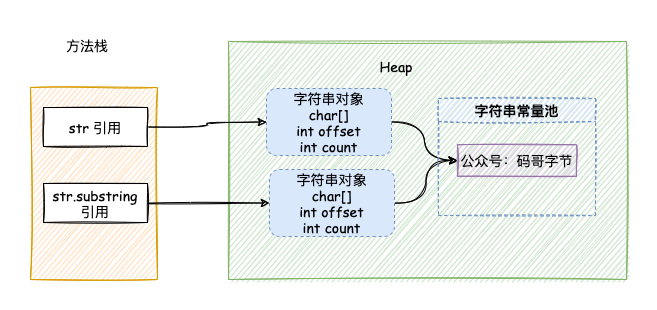
如果我们仅仅是用 substring 获取一小段字符,而原始 string字符串非常大的情况下,substring 的对象如果一直被引用。
此时 String 字符串也无法回收,从而导致内存泄露。
如果有大量这种通过 substring 获取超大字符串中一小段字符串的操作,会因为内存泄露而导致内存溢出。
JDK7、8
去掉了 offset 和 count两个变量,减少了 String 对象占用的内存。
substring 源码:
public String(char value[], int offset, int count) {
this.value = Arrays.copyOfRange(value, offset, offset + count);
}
public String substring(int beginIndex, int endIndex) {
int subLen = endIndex - beginIndex;
return new String(value, beginIndex, subLen);
}substring() 通过 new String() 返回了一个新的字符串对象,在创建新的对象时通过 Arrays.copyOfRange() 深度拷贝了一个新的字符数组。
如下图所示:
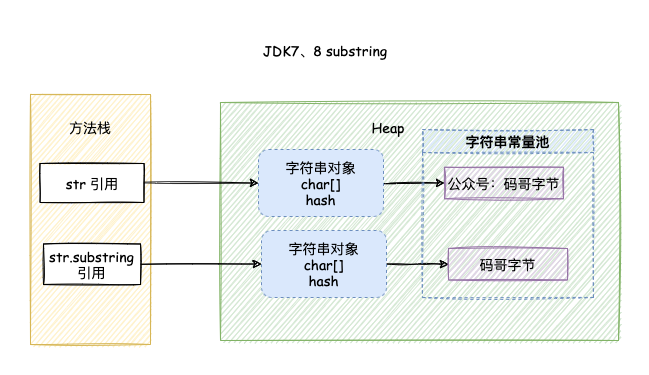
String.substring 方法不再共享 char[]数组的数据,解决了可能内存泄漏的问题。
Java 9
将 char[]字段改为 byte[],新增 coder属性。
码哥,为什么这么改呢?
一个 char 字符占 2 个字节,16 位。存储单字节编码内的字符(占一个字节的字符)就显得非常浪费。
为了节约内存空间,于是使用了 1 个字节占 8 位的 byte 数组来存放字符串。
勤俭节约的女神,谁不爱……
新属性 coder 的作用是:在计算字符串长度或者使用 indexOf()方法时,我们需要根据编码类型来计算字符串长度。
coder 的值分别表示不同编码类型:
0:表示使用
Latin-1(单字节编码);1:使用
UTF-16。
String 的不可变性
了解了String 的基本组成之后,发现 String 还有一个比外在更性感的特性,她被 final关键字修饰,char 数组也是。
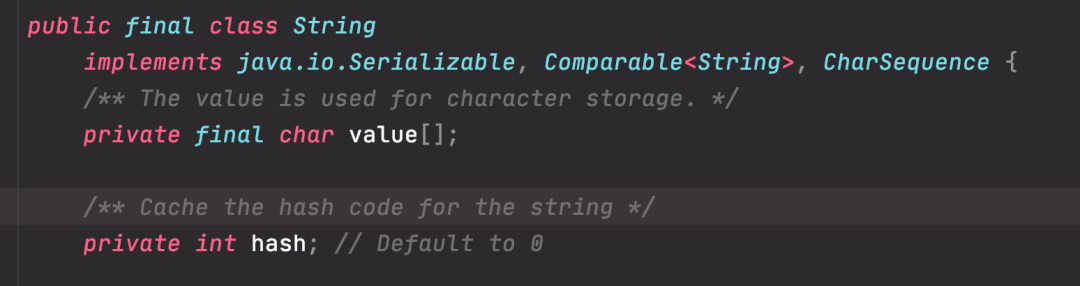
我们知道类被 final 修饰代表该类不可继承,而 char[]被 final+private 修饰,代表了 String 对象不可被更改。
String 对象一旦创建成功,就不能再对它进行改变。
Chaya:“String class 对象使用 final 修饰有什么好处?”
安全性
当你在调用其他方法时,比如调用一些系统级操作指令之前,可能会有一系列校验。
如果是可变类的话,可能在你校验过后,它的内部的值又被改变了,这样有可能会引起严重的系统崩溃问题。
高性能缓存
String不可变之后就能保证 hash值得唯一性,使得类似 HashMap容器才能实现相应的 key-value 缓存功能。
实现字符串常量池
由于不可变,才得以实现字符串常量池。
字符串常量池指的是在创建字符串的时候,先去「常量池」查找是否创建过该「字符串」;
如果有,则不会开辟新空间创建字符串,而是直接把常量池中该字符串的引用返回给此对象。
创建字符串的两种方式:
String str1 = “码哥字节”;
String str2 = new String(“码哥字节”);
当代码中使用第一种方式创建字符串对象时,JVM 首先会检查该对象是否在字符串常量池中,如果在,就返回该对象引用。
否则新的字符串将在常量池中被创建,并返回该引用。
这样可以减少同一个值的字符串对象的重复创建,节约内存。
第二种方式创建,在编译类文件时,"码哥字节" 字符串将会放入到常量结构中,在类加载时,“码哥字节" 将会在常量池中创建;
在调用 new 时,JVM 命令将会调用 String 的构造函数,在堆内存中创建一个 String 对象,同时该对象指向「常量池」中的“码哥字节”字符串,str 指向刚刚在堆上创建的 String 对象;
如下图:
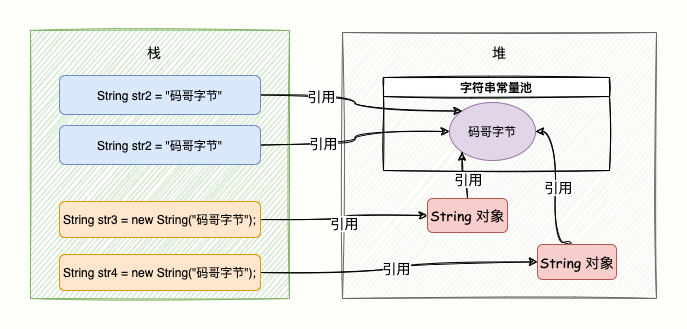
什么是对象和对象引用呀?
str 属于方法栈的字面量,它指向堆中的 String 对象,并不是对象本。
对象在内存中是一块内存地址,str 则是指向这个内存地址的引用。
也就是说 str 并不是对象,而只是一个对象引用。
码哥,字符串的不可变到底指的是什么呀?
String str = "Java";
str = "Java,yyds"第一次赋值 「Java」,第二次赋值「Java,yyds」,str 值确实改变了,为什么我还说 String 对象不可变呢?
这是因为 str 只是 String 对象的引用,并不是对象本身。
真正的对象依然还在内存中,没有被改变。
优化实战
了解了 String 的对象实现原理和特性,是时候要深入女神内心,结合实际场景,如何更上一层楼优化 String 对象的使用。
大量字符串拼接对象如何优化
既然 String 对象是不可变,所以我们在频繁拼接字符串的时候是否意味着创建多个对象呢?
String str = "癞蛤蟆撩青蛙" + "长的丑" + "玩的花";上面你的代码,你是不是以为先生成「癞蛤蟆撩青蛙」对象,再生成「癞蛤蟆撩青蛙长的丑」对象,最后生成「癞蛤蟆撩青蛙长得丑玩的花」对象。
实际运行中,只有一个对象生成。
Chaya:这是为什么呢?
虽然代码写的丑陋,但是编译器自动优化了代码。再看下面例子:
String str = "小青蛙";
for(int i=0; i<1000; i++) {
str += i;
}上面的代码编译后,你可以看到编译器同样对这段代码进行了优化。
Java 在进行字符串的拼接时,JVM 编译器会把上述代码优化,偏向使用 StringBuilder,这样可以提高程序的效率。优化后的代码如下。
String str = "小青蛙";
for(int i=0; i<1000; i++) {
str = (new StringBuilder(String.valueOf(str))).append(i).toString();
}即使如此,还是循环内重复创建 StringBuilder对象。
敲黑板
所以做字符串拼接的时候,我建议你还是要显示地使用 String Builder 来提升系统性能。
如果在多线程编程中,String 对象的拼接涉及到线程安全,你可以使用 StringBuffer。
重复性高的 String 信息优化
重点在于使用运用 intern 节省内存。直接看intern() 方法的定义与源码:

intern() 是一个本地方法,它的定义中说的是,当调用 intern 方法时,如果字符串常量池中已经包含此字符串,则直接返回此字符串的引用。
否则将此字符串添加到常量池中,并返回字符串的引用。
如果不包含此字符串,先将字符串添加到常量池中,再返回此对象的引用。
Chaya:什么情况下适合使用
intern()方法?
Twitter 工程师曾分享过一个 String.intern() 的使用示例,Twitter 每次发布消息状态的时候,都会产生一个地址信息,以当时 Twitter 用户的规模预估,服务器需要 20G 的内存来存储地址信息。
public class Location {
private String city;
private String region;
private String countryCode;
private double longitude;
private double latitude;
}考虑到其中有很多用户在地址信息上是有重合的,比如,国家、省份、城市等,这时就可以将这部分信息单独列出一个类,以减少重复,代码如下:
public class SharedLocation {
private String city;
private String region;
private String countryCode;
}
public class Location {
private SharedLocation sharedLocation;
double longitude;
double latitude;
}通过优化,数据存储大小减到了 20G 左右。
但对于内存存储这个数据来说,依然很大,怎么办呢?
Twitter 工程师使用 String.intern() 使重复性非常高的地址信息存储大小从 20G 降到几百兆,从而优化了 String 对象的存储。
核心代码如下:
SharedLocation sharedLocation = new SharedLocation();
sharedLocation.setCity(messageInfo.getCity().intern());
sharedLocation.setCountryCode(messageInfo.getRegion().intern());
sharedLocation.setRegion(messageInfo.getCountryCode().intern());弄个简单例子方便理解:
String a =new String("abc").intern();
String b = new String("abc").intern();
System.out.print(a==b);输出结果:true。
在加载类的时候会在常量池中创建一个字符串对象,内容是「abc」。
创建局部 a 变量时,调用 new Sting() 会在堆内存中创建一个 String 对象,String 对象中的 char 数组将会引用常量池中字符串。
在调用 intern 方法之后,会去常量池中查找是否有等于该字符串对象的引用,有就返回引用。
创建 b 变量时,调用 new Sting() 会在堆内存中创建一个 String 对象,String 对象中的 char 数组将会引用常量池中字符串。
在调用 intern 方法之后,会去常量池中查找是否有等于该字符串对象的引用,有就返回引用给局部变量。
而刚在堆内存中的两个对象,由于没有引用指向它,将会被垃圾回收。
所以 a 和 b 引用的是同一个对象。
字符串分割优化
split() 方法使用了正则表达式实现了其强大的分割功能,而正则表达式的性能是非常不稳定的。
使用不恰当会引起回溯问题,很可能导致 CPU 居高不下。
Java 正则表达式使用的引擎实现是 NFA(Non deterministic Finite Automaton,确定型有穷自动机)自动机,这种正则表达式引擎在进行字符匹配时会发生回溯(backtracking),而一旦发生回溯,那其消耗的时间就会变得很长,有可能是几分钟,也有可能是几个小时,时间长短取决于回溯的次数和复杂度。
所以我们应该慎重使用 split() 方法,我们可以用String.indexOf()方法代替 split() 方法完成字符串的分割。
最后,出一个问题给大家,欢迎在评论区留言。
通过三种不同的方式创建了三个对象,再依次两两匹配,每组被匹配的两个对象是否相等?代码如下:
String str1 = "abc";
String str2 = new String("abc");
String str3 = str2.intern();
assertSame(str1 == str2);
assertSame(str2 == str3);
assertSame(str1 == str3)博主简介
码哥,9 年互联网公司后端工作经验,InfoQ 签约作者、51CTO Top 红人,阿里云开发者社区专家博主,目前担任后端架构师主责,擅长 Redis、Spring、Kafka、MySQL技术和云原生微服务。
喜欢的可以给个关注,也可以在公众号后台回复“资料”下载我原创300多页的《Redis 高手心法》。
![[大模型]# Yi-6B-Chat Lora 微调](https://img-blog.csdnimg.cn/direct/13a4758156e6487fb0183110c0613100.png#pic_center)