论文地址:link
code:link
摘要:
任意不确定性捕获了观测结果中的噪声。对于伪装目标检测,由于伪装前景和背景的外观相似,很难获得高精度的注释,特别是目标边界周围的注释。我们认为直接使用“嘈杂”的伪装图进行训练可能会导致模型泛化能力较差。在本文中,我们引入了一种明确的任意不确定性估计技术来表示由于噪声标签而导致的预测不确定性。具体来说,我们提出了一种具有置信度的伪装目标检测(COD)框架,使用动态监督来生成准确的伪装图和可靠的“任意不确定性”。与根据点估计管道产生确定性预测的现有技术不同,我们的框架将任意不确定性形式化为模型输出和输入图像上的概率分布。我们声称,一旦经过训练,我们的置信度估计网络就可以评估预测的像素精度,而无需依赖地面真实伪装图。广泛的结果说明了所提出的模型在解释伪装预测方面的优越性能。
1.模型结构图

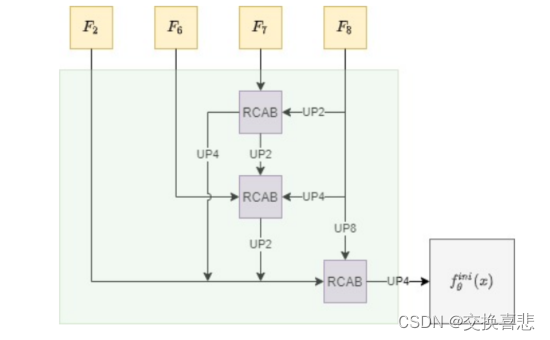
上图是fusion融合模块,利用到了RCAB结构,关于RCAB我在之前的论文阅读中有发,是一个固定的残差通道注意力模块。

2.方法
模型一共分为两个模块,COD和OCE模块,OCE模块较为简单,是说在U-Net的基础上,融合高层和浅层特征,COD比较复杂,涉及到
f
θ
r
e
f
f_\theta ^{ref}
fθref和
f
θ
i
n
i
f_\theta^{ini}
fθini
C
n
U
=
D
(
C
o
n
v
3
(
C
o
n
v
3
(
C
n
−
1
D
)
)
)
C_n^U = D(Conv3(Conv3(C_{n - 1}^D)))
CnU=D(Conv3(Conv3(Cn−1D)))
C
n
U
=
D
(
C
o
n
v
3
(
C
o
n
v
3
(
∐
(
C
n
D
,
D
(
T
C
o
n
v
2
(
C
n
+
1
U
)
)
)
)
)
)
C_{\rm{n}}^U = D(Conv3(Conv3(\coprod (C_n^D,D(TConv2(C_{n + 1}^U))))))
CnU=D(Conv3(Conv3(∐(CnD,D(TConv2(Cn+1U))))))
重要结构:
动态置信监督:
为置信度估计网络引入动态监督 ,定义如下:
y
c
=
y
×
(
1
−
y
^
)
+
(
1
−
y
)
×
y
^
{y_c} = y \times (1 - \hat y) + (1 - y) \times \hat y
yc=y×(1−y^)+(1−y)×y^
置信估计网络:
l
c
=
0.5
×
(
l
c
e
(
c
i
n
i
,
y
i
n
i
)
+
l
c
e
(
c
r
e
f
,
y
r
e
f
)
)
{l_c} = 0.5 \times ({l_{ce}}({c^{ini}},{y^{ini}}) + {l_{ce}}({c^{ref}},{y^{ref}}))
lc=0.5×(lce(cini,yini)+lce(cref,yref))
置信感知学习:
伪装目标检测在整个图像中具有不同的学习难度,沿着对象边界的像素比远离伪装对象的背景像素更难区分,此外,迷彩前景包含不同程度迷彩的部分,其中一些部分很容易识别,例如,眼睛嘴巴等,还有一些很难区分的,例如主体区域和背景具有相似的背景外观,我们打算通过将估计的置信度图导入我们的伪装对象检测网络来对图像中这种不同的学习难度来进行建模,具体来说,受【47】的启发,建议使用置信感知结构损失来训练伪装目标检测网络,其在等式中定义:
l
s
=
∑
u
,
v
w
u
,
v
l
c
e
+
∑
u
,
v
w
u
,
v
l
d
i
c
e
{l_s} = \sum\limits_{u,v} {{w^{u,v}}{l_{ce}}} + \sum\limits_{u,v} {{w^{u,v}}{l_{dice}}}
ls=u,v∑wu,vlce+u,v∑wu,vldice
3.结论
我们引入了一种用于伪装物体检测的在线不确定性估计技术,任意不确定性建模的传统方法仅涉及对任务相关损失函数的监督,如方程式3所示,在本文中,我们处理在线任意不确定性估计,并对任意不确定性估计模块引入动态监督以突出错误性的区域,具体来说,我们的框架由相互依赖的伪装对象检测网络和在线置信度估计网络组成。生成动态网络置信度标签来训练OCENet,该标签源自CODNet和地面实况图的预测。OCENet估计的置信图指示CODNet更加重视预测不确定的学习区域。我们提出的网络在四个基准伪装物体检测测试数据集上的表现由于现有的伪装物体检测方法,此外,生成的置信图提供了一种有效地解决方案来解释模型预测,而无需依赖地面实况图


![华为OD-C卷-攀登者1[100分]](https://img-blog.csdnimg.cn/direct/538ba52235ab42708ca3c6a9ea7b1fcc.png)