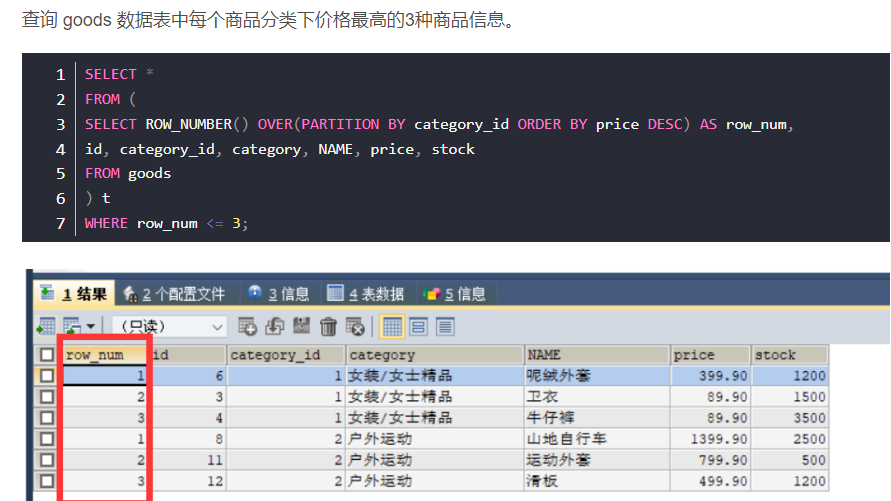
Python+Selenium 自动化 - 浏览器调用与驱动配置
- 一、浏览器版本查看与驱动下载
- 二、selenium 库安装与调用
- 三、常用命令解释
一、浏览器版本查看与驱动下载
通过关于可以看到浏览器的版本。
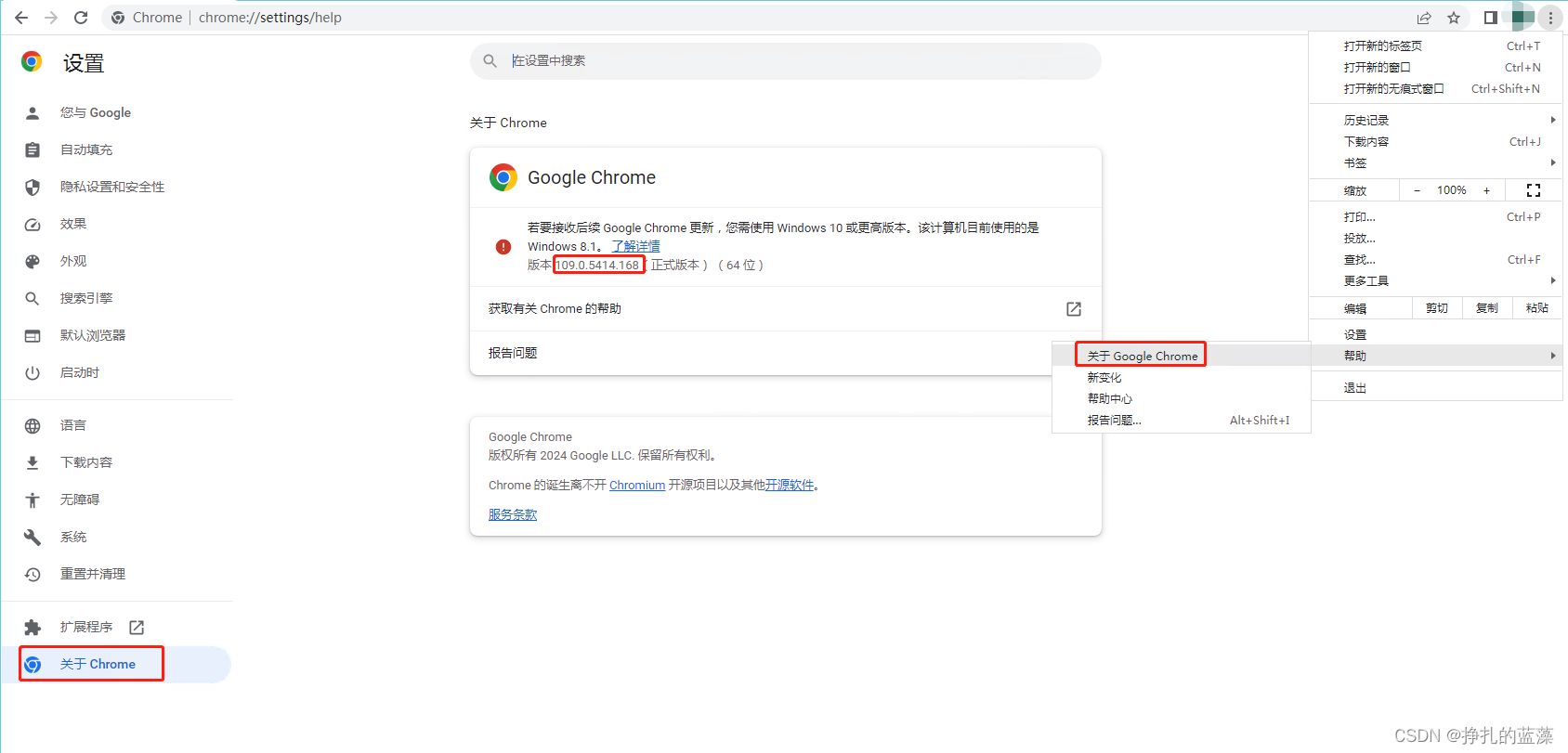
如果是新版浏览器,可以在这个地址下载:https://googlechromelabs.github.io/chrome-for-testing/
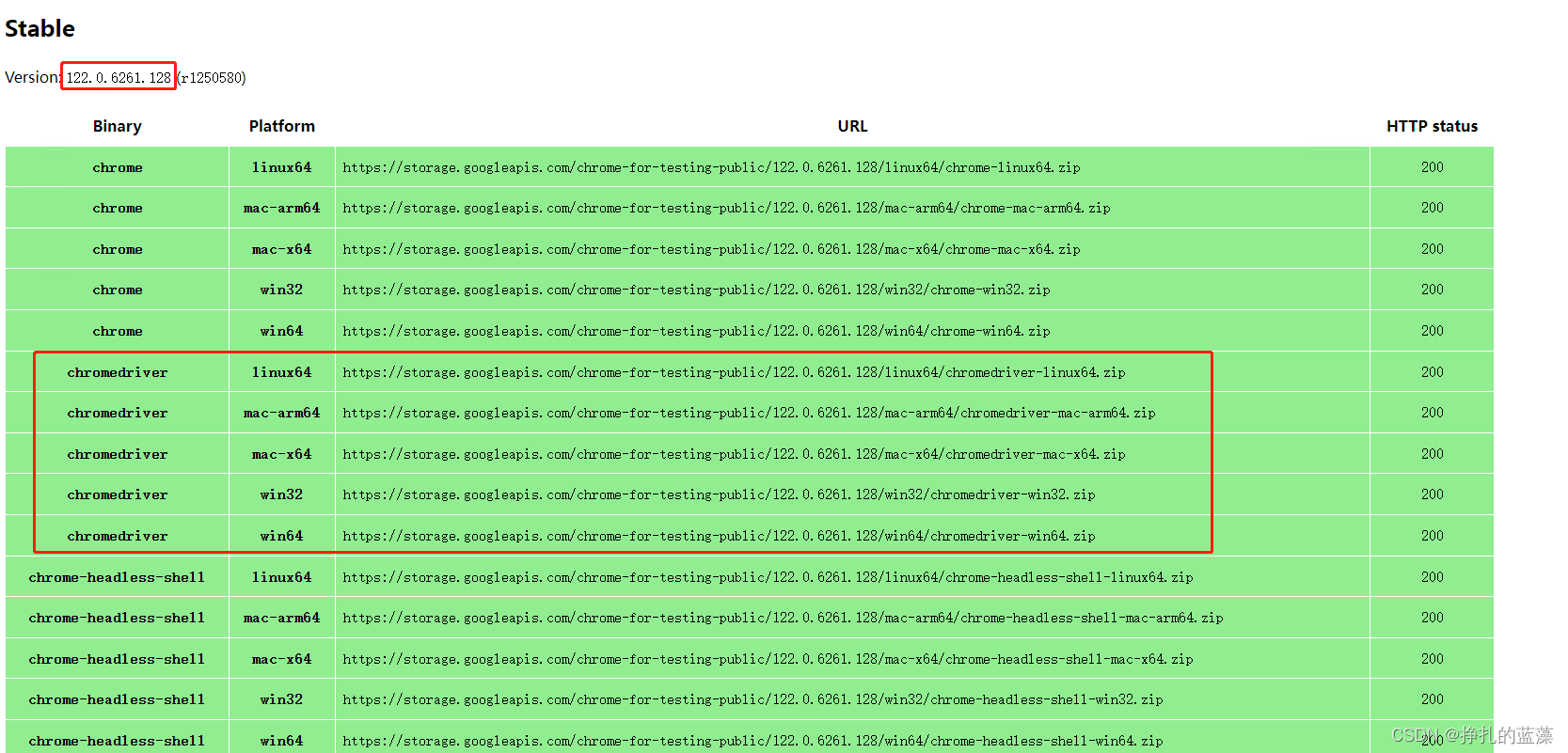
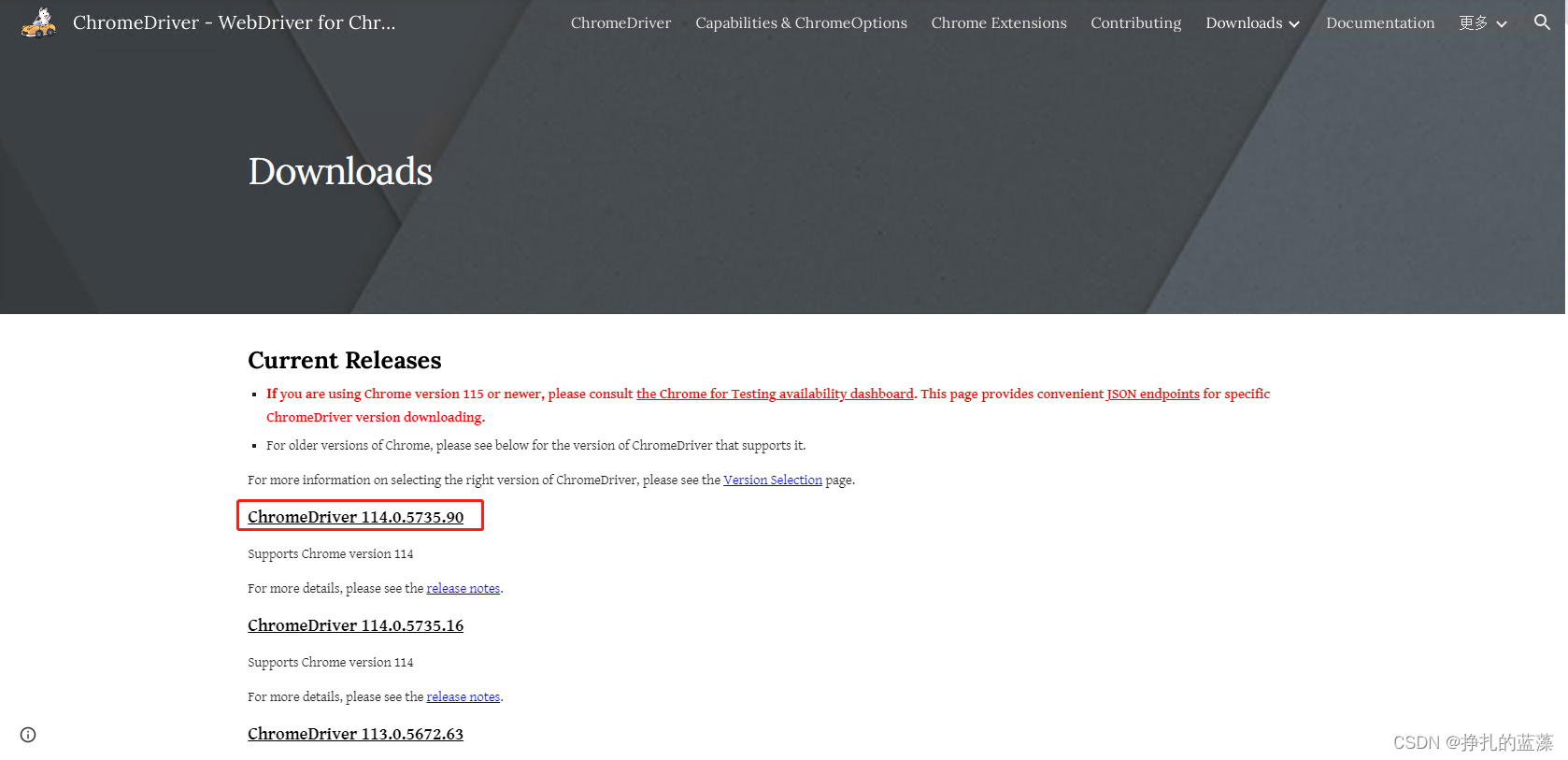
如果是 114 版本之前的浏览器,可以在下面的地址下载:https://chromedriver.chromium.org/downloads

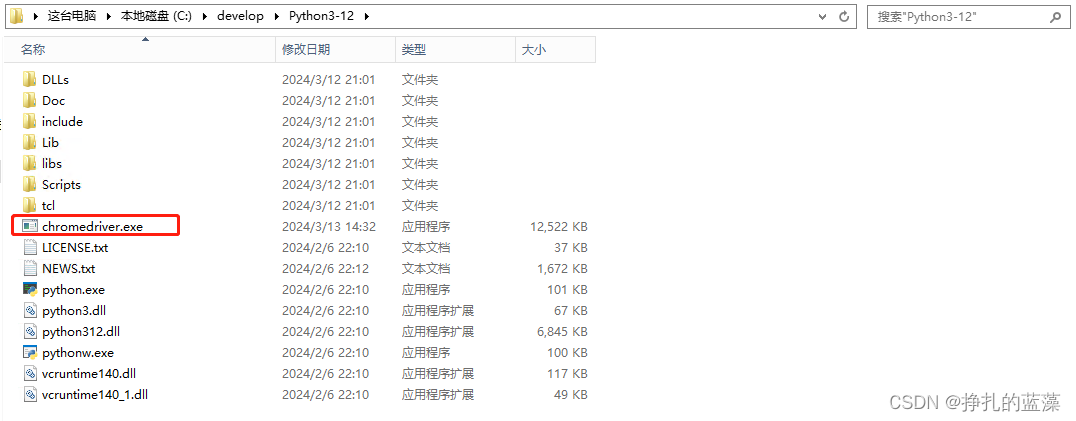
下载后把包里的 chromedriver.exe 放到我们安装的 python 根目录下:

根目录是程序默认找驱动的位置。
如果看不到拓展名,可以这样设置放开。

二、selenium 库安装与调用
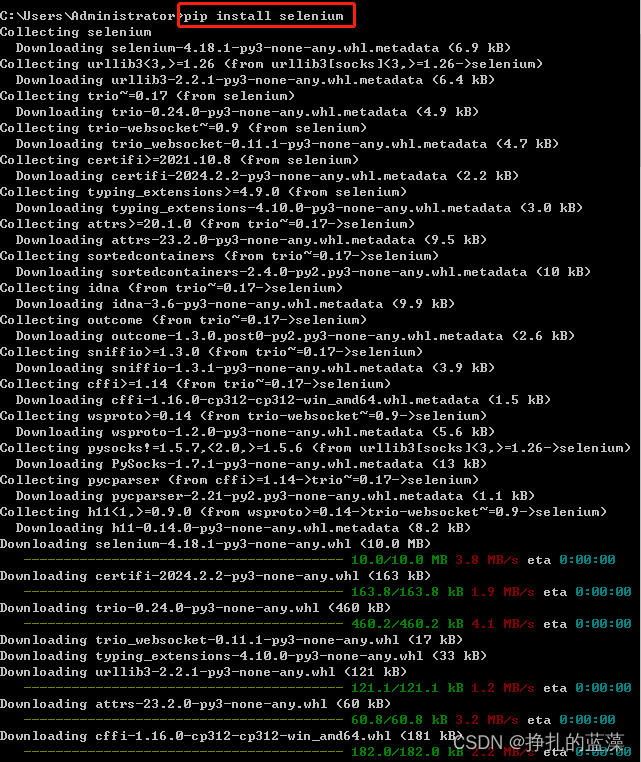
打开 cmd,通过 pip install selenium 命令安装 selenium 库。
下面的代码可实现调用浏览器,打开百度网页,等待 3 秒后再关闭浏览器。
from selenium import webdriver
import time
driver = webdriver.Chrome() # 使用 Chrome 浏览器
driver.get("https://www.baidu.com") # 打开网页
time.sleep(3) # 等待3秒
driver.close() # 关闭窗口
driver.quit() # 关闭浏览器
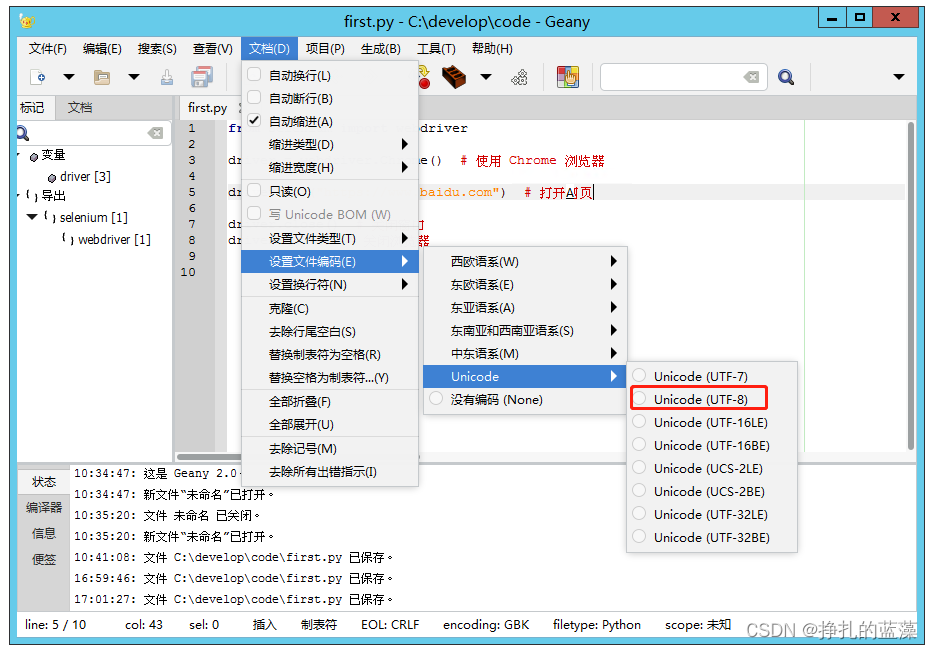
如果里面包含中文报错,可以修改文件的编码类型为 utf-8。
三、常用命令解释
1. 导入 Selenium 模块
from selenium import webdriver
2. 创建一个 WebDriver 实例
driver = webdriver.Chrome() # 使用 Chrome 浏览器
或者你也可以使用其他浏览器,比如 Firefox :
driver = webdriver.Firefox()
3. 打开一个网页
driver.get("https://www.example.com")
4. 查找元素
element = driver.find_element("xpath", "//input[@id='search']")
或者使用其他查找方式,比如通过 ID :
element = driver.find_element("id", "search")
5. 在输入框中输入文本
element.send_keys("hello Selenium")
6. 单击按钮
button = driver.find_element("xpath", "//button[@id='submit']")
button.click()
7. 获取元素的文本
text = element.text
8. 获取当前页面的 URL
current_url = driver.current_url
9. 关闭当前窗口
driver.close()
10. 关闭整个浏览器
driver.quit()
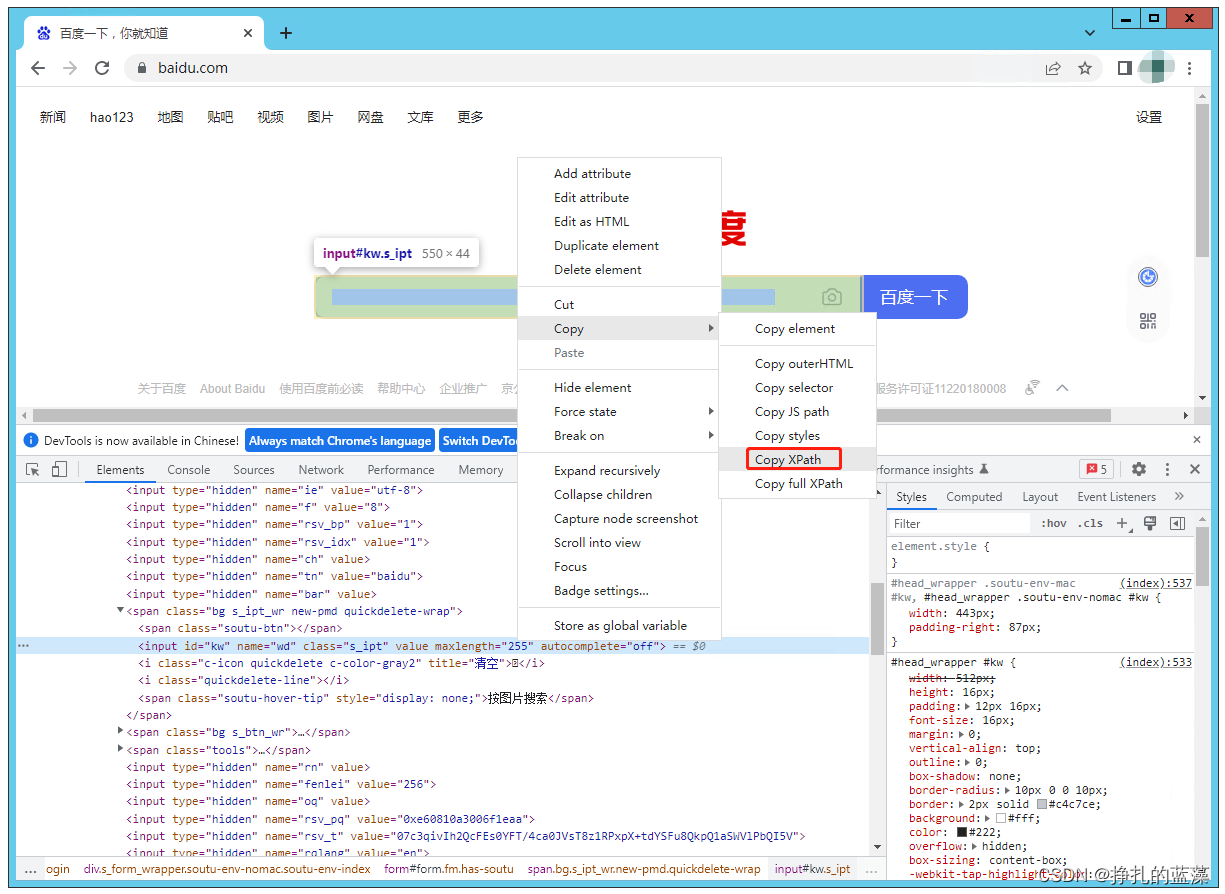
用下面的方法可以快速复制元素的 xpath 路径。