讲解视频:可以在bilibili搜索《MATLAB教程新手入门篇——数学建模清风主讲》。
MATLAB教程新手入门篇(数学建模清风主讲,适合零基础同学观看)_哔哩哔哩_bilibili
到目前为止,我们已经系统地介绍了正则表达式的基本语法,以及如何通过regexp函数利用这些语法规则来匹配和提取特定文本。注意,关于regexp函数的用法我们并没有进行系统的讲解,它的完整的使用方法非常丰富,除了常用的'match'和'tokens'参数外,它还支持其他一些输入参数,但使用的频率较低。感兴趣的同学可以查阅MATLAB的官方文档进行自学。
在本小节中,我们将通过解决三道综合性的题目来进一步展示正则表达式在实际应用中的强大功能。这三道例题不仅会巩固你对正则表达式基础语法的理解,还将帮助你把这些概念应用于解决实际问题,从而更好地理解正则表达式的实际应用价值和潜力。
例题1:整理王者荣耀的英雄资料
本章配套的代码压缩包中有一个名为“王者荣耀英雄资料”的文件夹,大家可以看本书的第一页下载。该文件夹中存放着王者荣耀游戏中117名英雄的介绍资料,这些资料来自于王者荣耀的官网(txt文件中的字符编码为UTF-8)。

我们需要提取各位英雄的称号、英雄名称、生存能力、攻击伤害、技能效果和上手难度。
以英雄“白起”为例,我们所需的六个指标位于箭头所指的位置:

为了提取这些信息,我们提供了以下MATLAB代码示例:
% 确保MATLAB的当前文件夹位于【王者荣耀英雄资料】这个文件夹下
feature('DefaultCharacterSet','UTF-8'); % 防止中文乱码
S = strings(117,6);
for ii = 1:117
% 使用char函数将文件名更改为字符向量类型(防止低版本MATLAB报错)
s = fileread(char(ii+".txt"));
expression = ['cover-title">(.+?)<.+?' ...
'cover-name">(.+?)<.+?' ...
'width:(.+?)">.+?' ...
'width:(.+?)">.+?' ...
'width:(.+?)">.+?' ...
'width:(.+?)">'];
s1 = regexp(s, expression, 'tokens');
s2 = string(s1{1});
S(ii,:) = s2;
end
S
运行上述代码后,得到的S是一个117行6列的字符串数组。其中,第一列的部分数据中存在错误:
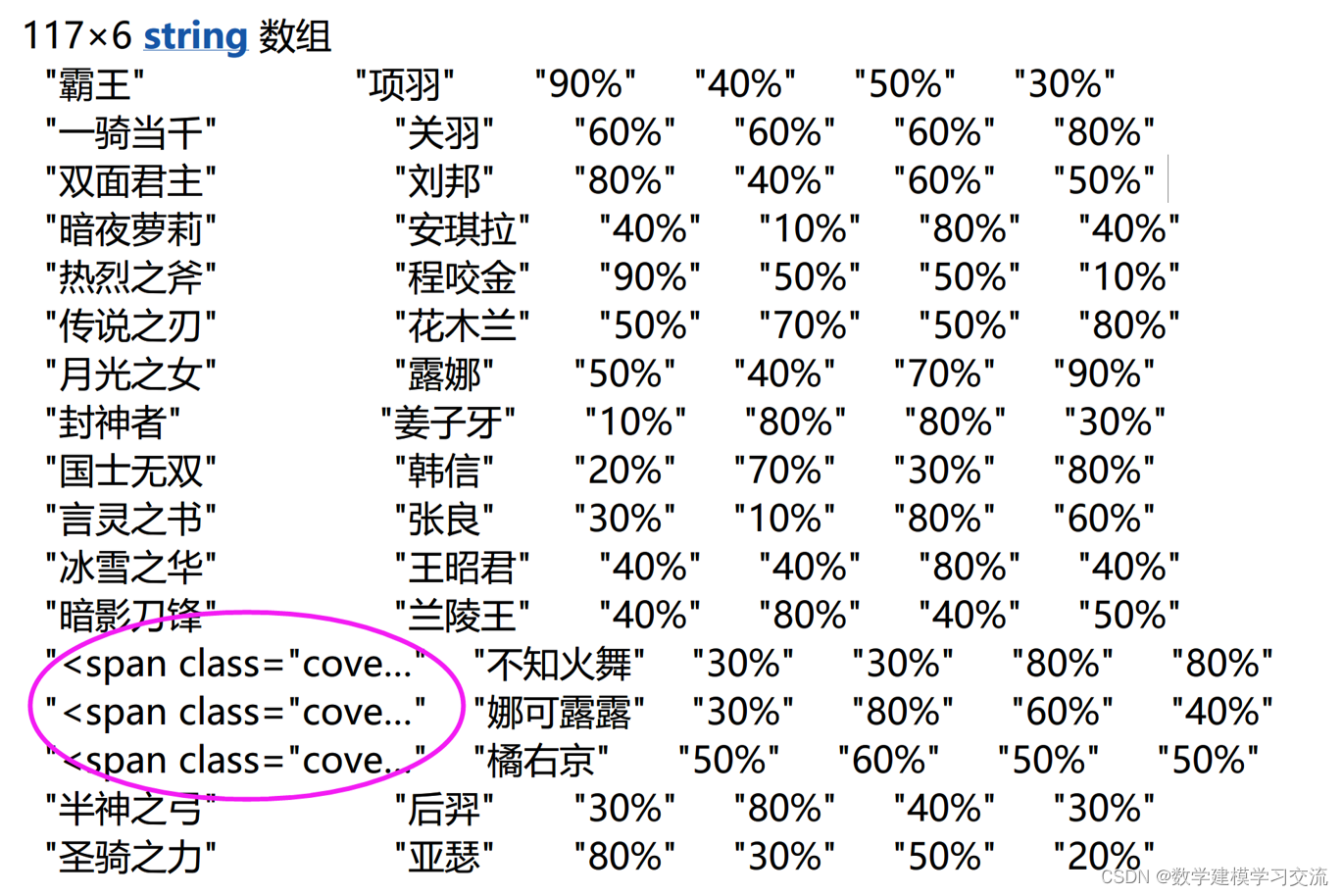
例如第13行第1列的数据为:

我们可以打开对应的txt文件来查看出错的原因,以“13.txt”为例:

和一般的文件相比,这里多了一个网页标签: <span class="cover-title-inner">,而我们上面的正则表达式没考虑到这种情况,因此会导致匹配到多余的文本。
为解决这一问题,我们提供了两种解决方案:
(1)对已提取的字符串数组S进行二次处理,删除掉不需要的部分

除了使用eraseBetween函数之外,我们也可以使用另外一个正则表达式函数regexprep来解决这个问题,它的用法如下:newStr = regexprep(str,expression,replace) 将 str 中与 expression 匹配的文本替换为 replace 描述的文本。regexprep 函数在 newStr 中返回更新的文本。

上述两种方法得到的结果完全相同。
(2)调整正则表达式,其余的代码不变,运行后得到的S就是所需的正确结果
expression = ['cover-title">(?:<span class="cover-title-inner">)?(.+?)<.+?' ...
'cover-name">(.+?)<.+?' ...
'width:(.+?)">.+?' ...
'width:(.+?)">.+?' ...
'width:(.+?)">.+?' ...
'width:(.+?)">'];
调整后的正则表达式通过加入一个非捕获组(?:<span class="cover-title-inner">)?,使得正则表达式能够匹配到可能存在的<span class="cover-title-inner">文本,并将其作为可选部分进行处理。
例题2:提取《西游记》章回概述中的标题并统计每一回的字符数
本题将使用正则表达式的相关知识重新解决上一章5.4.5节的案例3,大家可以打开本章配套文件中的“西游记数据”这个子文件夹,并将MATLAB的当前文件夹切换到这个文件夹内。本题所需的数据保存在 “《西游记》章回内容梗概.txt”这个文件中。

任务一比较简单,我们直接给出相应的代码:
% 确保MATLAB的当前文件夹位于【西游记数据】这个文件夹下
feature('DefaultCharacterSet','UTF-8'); % 防止中文乱码
s = fileread('《西游记》章回内容梗概.txt');
H = regexp(s,'第\w*?回\s*(.*?)\n','tokens');
H = strip(string(H)) % 将H转换成字符串类型,并删除掉前后的空白字符
% 得到的结果和上一章的代码完全相同
对于任务二,为了统计每一回正文的字数,下面我们采用了一种创新的策略。为了清晰地区分每一回的开始和结束,我们预先在“第”字前插入一个特殊字符(使用unicode编码为9999对应的字符)。这个预处理步骤简化了后续的文本分析,使我们能够更精确地使用正则表达式提取每一回的正文内容。然后,通过去除所有换行符和回车符,并计算剩余文本的字符数,我们得到了每一回正文的字数。这一过程的代码如下所述:
ss = s; % 将原来的数据赋值给ss,后面我们对ss进行修改时不会影响到s
% count(ss,'第') % 结果等于100
ss = regexprep(ss,'第',[char(9999), '第']); % 在'第'的前面插入一个特殊字符
% 下面我们借助正则表达式的捕获组来获取每一回的正文内容
s1 = regexp([ss, char(9999)], ...
['第\w*?回.*?\n(.*?)', char(9999)],'tokens');
s2 = regexprep(string(s1),'[\n\r]',''); % 删除掉换行符和回车符
N = strlength(s2) % 统计字符数(得到的结果和上一章完全相同)
这个解决方案不仅展示了MATLAB正则表达式处理文本数据的强大能力,也体现了在文本分析任务中面对复杂问题时的创造性思维。
例题3:导入人口统计数据
本题数据来自国家统计局发布的《第七次全国人口普查公报(第五号)》:
第七次全国人口普查公报(第五号) - 国家统计局
大家可以在上述网页中找到下面这张表格:
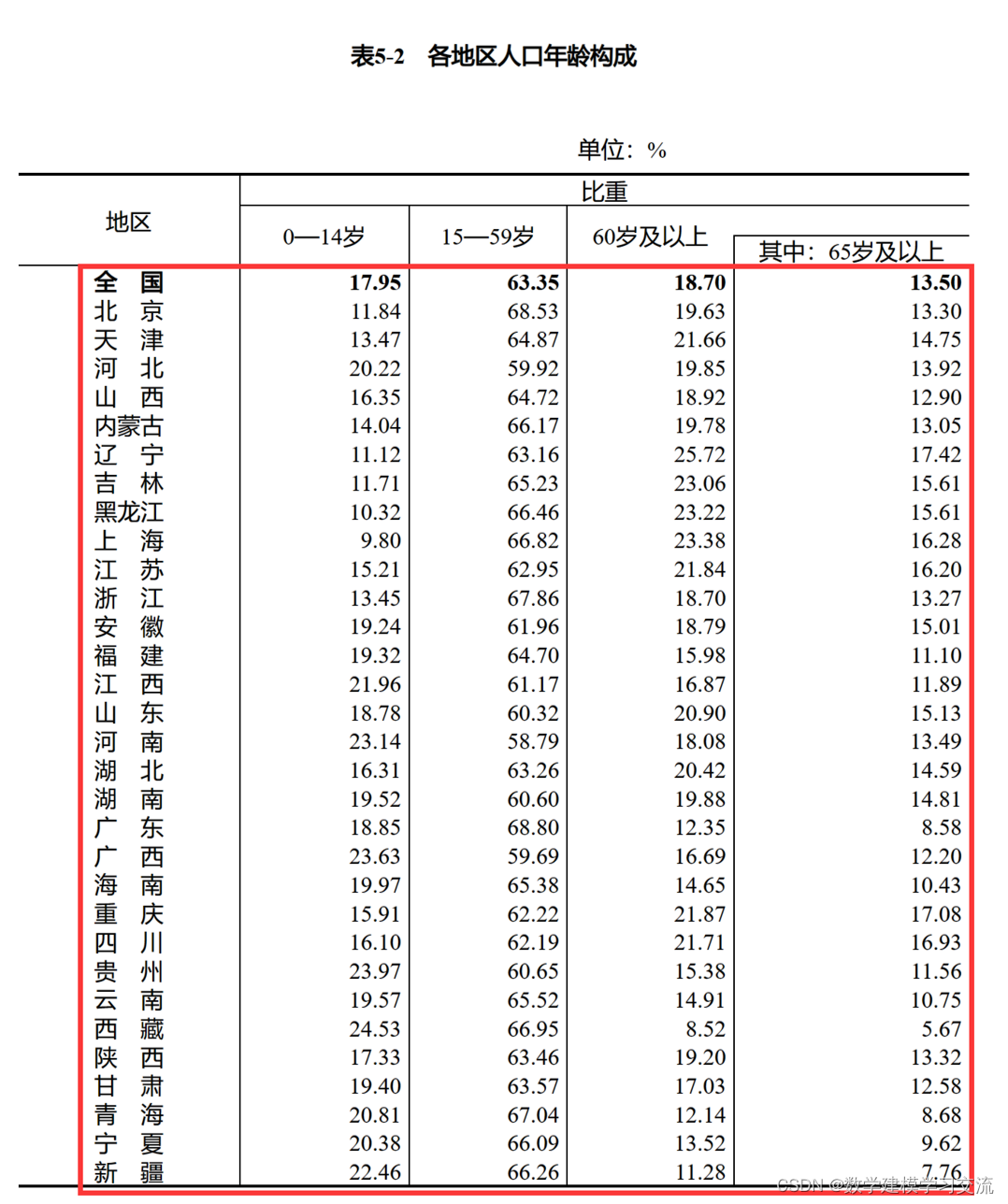
我们的任务是将上述表格中的数据保存到MATLAB中。
为了完成这个任务,我们可以依次完成如下三个步骤:
第一步:将表格上的数据复制粘贴到文本文件中
大家可以新建一个txt后缀的文本文件,然后在网页中复制所需的数据部分(上图用红色框选的部分),将复制的内容粘贴到这个txt文件中。
例如,我创建的txt文件名为“各地区人口年龄构成.txt”,该文件的编码为UTF-8,大家可以在本章配套的代码压缩包中找到。
第二步:读取txt文件中的数据到MATLAB中
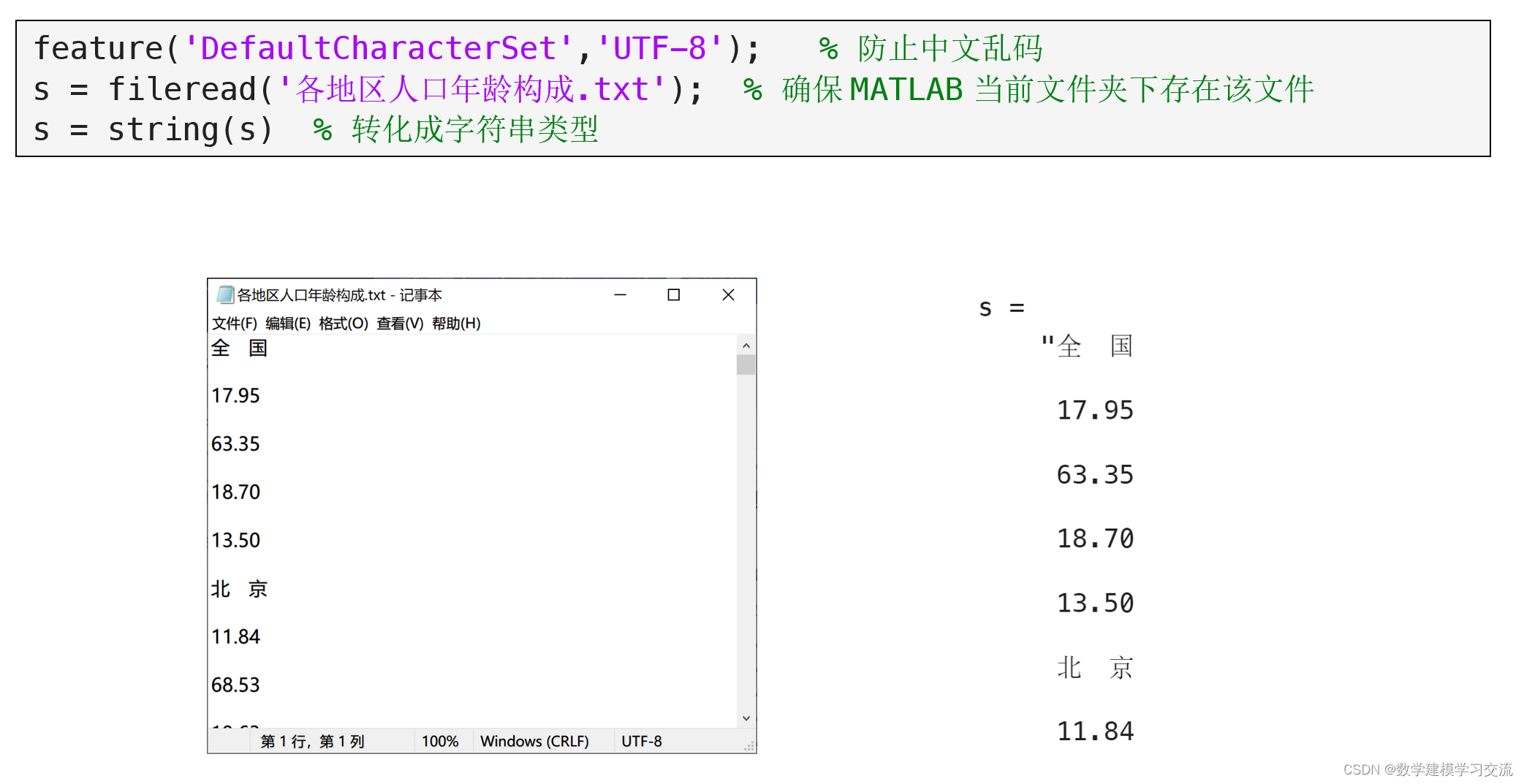
第三步:从字符串s中提取所需的数据
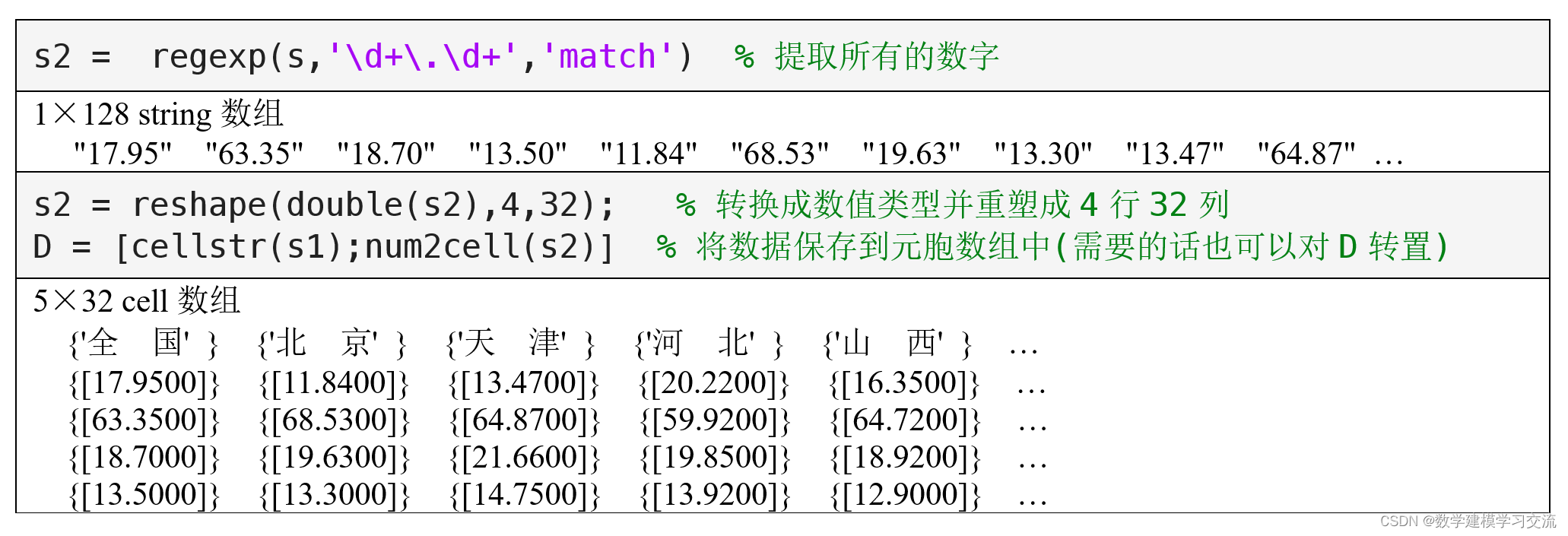
注意,提取的方法并不唯一,下面我们使用正则表达式进行提取,你也可以使用我们上一章所学的知识点。
s1 = regexp(s,'[一-龥]\s?[一-龥]{1,2}','match') % 提取地区名称
注意:'一'和'龥'分别是汉字在Unicode编码中的第一个字符和最后一个字符,所以正则表达式'[一-龥]'可用于匹配单个的汉字。另外,提取得到的两个字的地区名称中间的空格并不是普通的空格(Unicode编码为32),而是全角空格(Unicode编码为12288),因此大家如果将正则表达式中的\s换成普通的空格会得到错误的结果。
点击下方的CSDN专栏阅读下一篇文章:
MATLAB入门课程专栏