本文中,第一部分概述了各种回归损失函数,当然也包括了今天的主角MPDIou。第二部分内容为在YOLOv9中使用MPDIou回归损失函数的方法。
1 回归损失函数(Bounding Box Regression Loss)
边界框回归损失计算的方法包括GIoU、DIoU、CIoU、EIoU和MPDIou等。
IOU_Loss(2016)-> GIOU_Loss(2019)-> DIOU_Loss(2020)-> CIOU_Loss(2020)-> EIoU (2022 ) -> MPDIou(2023 )
① IOU
IoU的计算是用预测框(A)和真实框(B)的交集除以二者的并集,IoU的值越高说明二者的重合程度就越高,意味着模型预测的越准确。其公式为:

② GIOU
论文官网地址:https://arxiv.org/pdf/1902.09630.pdf
论文中将IoU推广为一种新的度量,即GIoU,用于比较任意两个任意形状。同时,证明了这个新指标具有IoU所具有的所有吸引人的属性,同时解决了它的弱点。因此,它可以作为2D/3D视觉任务中依赖IoU度量的所有性能度量的一个很好的选择。证明了GIoU可以用作边界框回归损失。
除了考虑IoU(交并比)之外,GIoU还考虑了边界框之间的包含关系和空间分布。
适合处理有重叠和非重叠区域的复杂场景,比如说拥挤场景。
GIOU的计算方式可以见下图:

③ DIoU
论文官网地址:https://arxiv.org/pdf/1911.08287.pdf
DIOU能够直接最小化预测框和真实框的中心点距离加速收敛,适用于需要快速收敛和精确定位的任务,但是Bounding box的回归还有一个重要的因素纵横比没有考虑。
DIoU的计算方式可以见下图:

④ CIoU
DIoU的作者考虑到,在两个框中心点重合时,c与d的值都不变。所以此时需要引入框的宽高比,即CIOU。
适合需要综合考虑重叠区域、形状和中心点位置的复杂场景。
CIoU_LOSS的计算方式见下图:

⑤ EIoU
论文官网地址:https://arxiv.org/pdf/2101.08158.pdf
EIoU考虑了预测边界框与真实边界框之间的预期相似度。只用于训练。
适合于优化边界框对齐和形状相似性的高级场景需求。
EIoU_Loss的计算公式如下所示:

EIoU的计算方式理解见下图:

⑥ MPDIou
论文官网地址:https://arxiv.org/abs/2307.07662
MPDIoU损失,通过最小化预测边界框和真实边界框之间的左上和右下点距离,以更好地训练目标检测、字符级场景文本识别和实例分割的深度模型。
绿框表示真实边界框,红框表示预测边界框。具有不同边界框回归结果的两种情况,如下图所示:
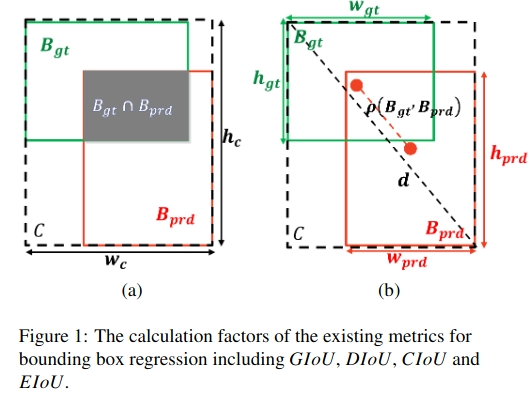

从上图中可以看出:其他的几种计算方法针对上图中的两种情况所得值均相同,只有MPDIou_Loss是不同的。
提出的MPDIoU简化了两个边界框之间的相似性比较,可以适应重叠或非重叠的边界框回归。
MPDIou的计算公式如下所示:

实验结果展示:


⑦ SIoU
官方论文地址:https://arxiv.org/ftp/arxiv/papers/2205/2205.12740.pdf
本文提出了一种新的边界框回归损失函数极大地改进了目标检测算法的训练和推理。通过在损失函数代价中引入方向性,与现有方法(如CIoU损失)相比,训练阶段的收敛速度更快,推理性能更好。这种改进有效地减少了自由度(一个坐标VS两个坐标),收敛速度更快,更准确。与广泛使用的最先进的方法和报告的可测量的改进进行了比较,所提出的损失函数可以很容易地包含在任何目标检测pipeline中,并有助于获得更好的结果。
适用于精细的物体检测和小目标检测。
SIoU损失函数包含四个部分:角度损失(Angle cost)、距离损失(Distance cost)、形状损失(Shape cost)、IoU损失(IoU cost)。
最终LOSS定义如下:

检测效果对比如下图所示:

2 YOLOv9中使用MPDIou
首先,我们看utils/metrics.py文件中的bbox_iou函数,如下图:
![]()
从上图中可以看出:官方代码中集成了MPDIoU,因此不需要修改损失函数的内部,只需要在使用的地方对应上额外需要的参数即可。

以下对YOLOv9的代码DualDetect版本进行具体的修改,修改的部分均在utils/loss_tal_dual.py文件中。
① 第一部分
| before |
|
|
| after |
|
|
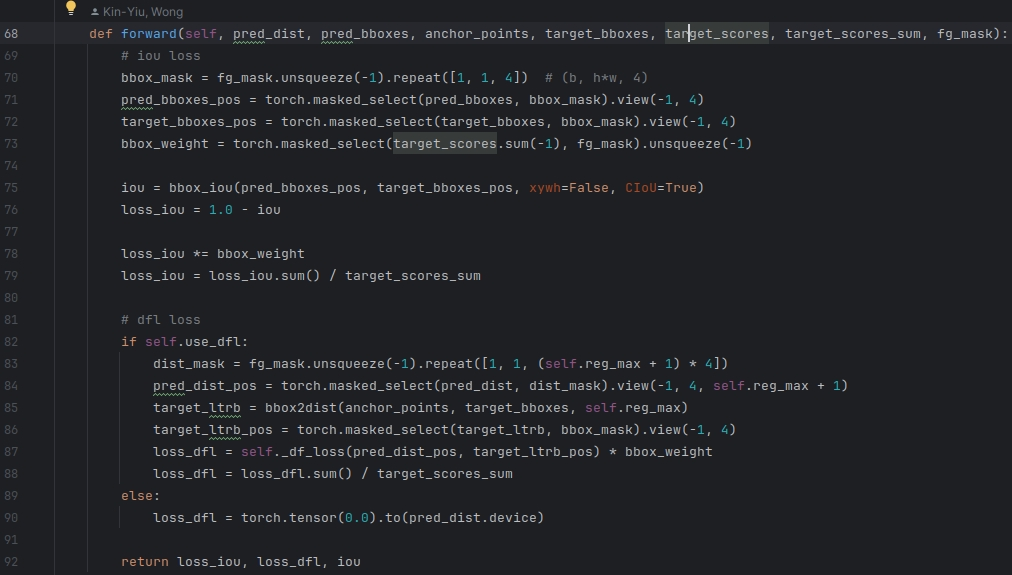

② 第二部分
| before |
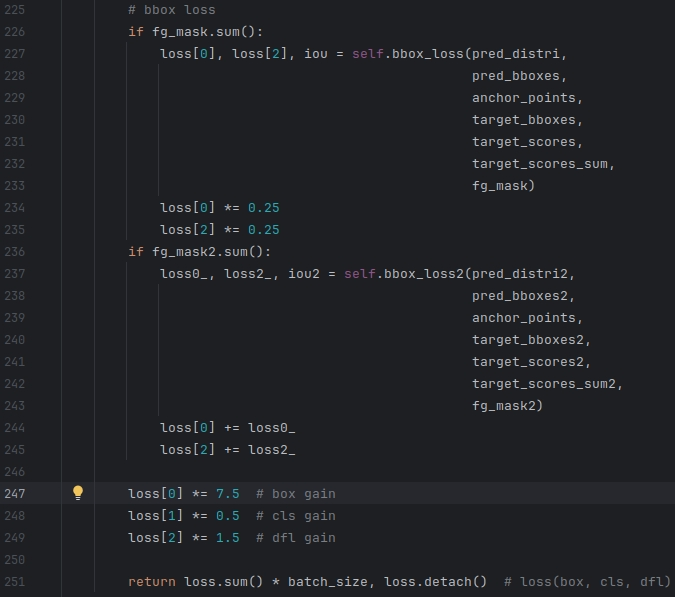 |
| after |
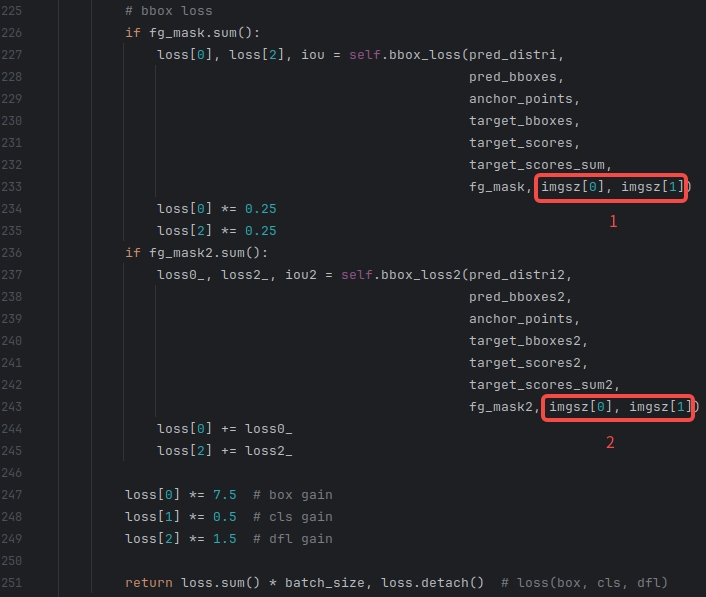 |
以上是全部的修改。本文也提供了修改后的loss_tal_dual.py,方便大家直接替换,内容如下:
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
from utils.general import xywh2xyxy
from utils.metrics import bbox_iou
from utils.tal.anchor_generator import dist2bbox, make_anchors, bbox2dist
from utils.tal.assigner import TaskAlignedAssigner
from utils.torch_utils import de_parallel
def smooth_BCE(eps=0.1): # https://github.com/ultralytics/yolov3/issues/238#issuecomment-598028441
# return positive, negative label smoothing BCE targets
return 1.0 - 0.5 * eps, 0.5 * eps
class VarifocalLoss(nn.Module):
# Varifocal loss by Zhang et al. https://arxiv.org/abs/2008.13367
def __init__(self):
super().__init__()
def forward(self, pred_score, gt_score, label, alpha=0.75, gamma=2.0):
weight = alpha * pred_score.sigmoid().pow(gamma) * (1 - label) + gt_score * label
with torch.cuda.amp.autocast(enabled=False):
loss = (F.binary_cross_entropy_with_logits(pred_score.float(), gt_score.float(),
reduction="none") * weight).sum()
return loss
class FocalLoss(nn.Module):
# Wraps focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
super().__init__()
self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
self.gamma = gamma
self.alpha = alpha
self.reduction = loss_fcn.reduction
self.loss_fcn.reduction = "none" # required to apply FL to each element
def forward(self, pred, true):
loss = self.loss_fcn(pred, true)
# p_t = torch.exp(-loss)
# loss *= self.alpha * (1.000001 - p_t) ** self.gamma # non-zero power for gradient stability
# TF implementation https://github.com/tensorflow/addons/blob/v0.7.1/tensorflow_addons/losses/focal_loss.py
pred_prob = torch.sigmoid(pred) # prob from logits
p_t = true * pred_prob + (1 - true) * (1 - pred_prob)
alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
modulating_factor = (1.0 - p_t) ** self.gamma
loss *= alpha_factor * modulating_factor
if self.reduction == "mean":
return loss.mean()
elif self.reduction == "sum":
return loss.sum()
else: # 'none'
return loss
class BboxLoss(nn.Module):
def __init__(self, reg_max, use_dfl=False):
super().__init__()
self.reg_max = reg_max
self.use_dfl = use_dfl
def forward(self, pred_dist, pred_bboxes, anchor_points, target_bboxes, target_scores, target_scores_sum, fg_mask, h, w):
# iou loss
bbox_mask = fg_mask.unsqueeze(-1).repeat([1, 1, 4]) # (b, h*w, 4)
pred_bboxes_pos = torch.masked_select(pred_bboxes, bbox_mask).view(-1, 4)
target_bboxes_pos = torch.masked_select(target_bboxes, bbox_mask).view(-1, 4)
bbox_weight = torch.masked_select(target_scores.sum(-1), fg_mask).unsqueeze(-1)
iou = bbox_iou(pred_bboxes_pos, target_bboxes_pos, xywh=False, CIoU=False, MDPIoU=True, feat_h=h, feat_w=w)
loss_iou = 1.0 - iou
loss_iou *= bbox_weight
loss_iou = loss_iou.sum() / target_scores_sum
# dfl loss
if self.use_dfl:
dist_mask = fg_mask.unsqueeze(-1).repeat([1, 1, (self.reg_max + 1) * 4])
pred_dist_pos = torch.masked_select(pred_dist, dist_mask).view(-1, 4, self.reg_max + 1)
target_ltrb = bbox2dist(anchor_points, target_bboxes, self.reg_max)
target_ltrb_pos = torch.masked_select(target_ltrb, bbox_mask).view(-1, 4)
loss_dfl = self._df_loss(pred_dist_pos, target_ltrb_pos) * bbox_weight
loss_dfl = loss_dfl.sum() / target_scores_sum
else:
loss_dfl = torch.tensor(0.0).to(pred_dist.device)
return loss_iou, loss_dfl, iou
def _df_loss(self, pred_dist, target):
target_left = target.to(torch.long)
target_right = target_left + 1
weight_left = target_right.to(torch.float) - target
weight_right = 1 - weight_left
loss_left = F.cross_entropy(pred_dist.view(-1, self.reg_max + 1), target_left.view(-1), reduction="none").view(
target_left.shape) * weight_left
loss_right = F.cross_entropy(pred_dist.view(-1, self.reg_max + 1), target_right.view(-1),
reduction="none").view(target_left.shape) * weight_right
return (loss_left + loss_right).mean(-1, keepdim=True)
class ComputeLoss:
# Compute losses
def __init__(self, model, use_dfl=True):
device = next(model.parameters()).device # get model device
h = model.hyp # hyperparameters
# Define criteria
BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h["cls_pw"]], device=device), reduction='none')
# Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
self.cp, self.cn = smooth_BCE(eps=h.get("label_smoothing", 0.0)) # positive, negative BCE targets
# Focal loss
g = h["fl_gamma"] # focal loss gamma
if g > 0:
BCEcls = FocalLoss(BCEcls, g)
m = de_parallel(model).model[-1] # Detect() module
self.balance = {3: [4.0, 1.0, 0.4]}.get(m.nl, [4.0, 1.0, 0.25, 0.06, 0.02]) # P3-P7
self.BCEcls = BCEcls
self.hyp = h
self.stride = m.stride # model strides
self.nc = m.nc # number of classes
self.nl = m.nl # number of layers
self.no = m.no
self.reg_max = m.reg_max
self.device = device
self.assigner = TaskAlignedAssigner(topk=int(os.getenv('YOLOM', 10)),
num_classes=self.nc,
alpha=float(os.getenv('YOLOA', 0.5)),
beta=float(os.getenv('YOLOB', 6.0)))
self.assigner2 = TaskAlignedAssigner(topk=int(os.getenv('YOLOM', 10)),
num_classes=self.nc,
alpha=float(os.getenv('YOLOA', 0.5)),
beta=float(os.getenv('YOLOB', 6.0)))
self.bbox_loss = BboxLoss(m.reg_max - 1, use_dfl=use_dfl).to(device)
self.bbox_loss2 = BboxLoss(m.reg_max - 1, use_dfl=use_dfl).to(device)
self.proj = torch.arange(m.reg_max).float().to(device) # / 120.0
self.use_dfl = use_dfl
def preprocess(self, targets, batch_size, scale_tensor):
if targets.shape[0] == 0:
out = torch.zeros(batch_size, 0, 5, device=self.device)
else:
i = targets[:, 0] # image index
_, counts = i.unique(return_counts=True)
out = torch.zeros(batch_size, counts.max(), 5, device=self.device)
for j in range(batch_size):
matches = i == j
n = matches.sum()
if n:
out[j, :n] = targets[matches, 1:]
out[..., 1:5] = xywh2xyxy(out[..., 1:5].mul_(scale_tensor))
return out
def bbox_decode(self, anchor_points, pred_dist):
if self.use_dfl:
b, a, c = pred_dist.shape # batch, anchors, channels
pred_dist = pred_dist.view(b, a, 4, c // 4).softmax(3).matmul(self.proj.type(pred_dist.dtype))
# pred_dist = pred_dist.view(b, a, c // 4, 4).transpose(2,3).softmax(3).matmul(self.proj.type(pred_dist.dtype))
# pred_dist = (pred_dist.view(b, a, c // 4, 4).softmax(2) * self.proj.type(pred_dist.dtype).view(1, 1, -1, 1)).sum(2)
return dist2bbox(pred_dist, anchor_points, xywh=False)
def __call__(self, p, targets, img=None, epoch=0):
loss = torch.zeros(3, device=self.device) # box, cls, dfl
feats = p[1][0] if isinstance(p, tuple) else p[0]
feats2 = p[1][1] if isinstance(p, tuple) else p[1]
pred_distri, pred_scores = torch.cat([xi.view(feats[0].shape[0], self.no, -1) for xi in feats], 2).split(
(self.reg_max * 4, self.nc), 1)
pred_scores = pred_scores.permute(0, 2, 1).contiguous()
pred_distri = pred_distri.permute(0, 2, 1).contiguous()
pred_distri2, pred_scores2 = torch.cat([xi.view(feats2[0].shape[0], self.no, -1) for xi in feats2], 2).split(
(self.reg_max * 4, self.nc), 1)
pred_scores2 = pred_scores2.permute(0, 2, 1).contiguous()
pred_distri2 = pred_distri2.permute(0, 2, 1).contiguous()
dtype = pred_scores.dtype
batch_size, grid_size = pred_scores.shape[:2]
imgsz = torch.tensor(feats[0].shape[2:], device=self.device, dtype=dtype) * self.stride[0] # image size (h,w)
anchor_points, stride_tensor = make_anchors(feats, self.stride, 0.5)
# targets
targets = self.preprocess(targets, batch_size, scale_tensor=imgsz[[1, 0, 1, 0]])
gt_labels, gt_bboxes = targets.split((1, 4), 2) # cls, xyxy
mask_gt = gt_bboxes.sum(2, keepdim=True).gt_(0)
# pboxes
pred_bboxes = self.bbox_decode(anchor_points, pred_distri) # xyxy, (b, h*w, 4)
pred_bboxes2 = self.bbox_decode(anchor_points, pred_distri2) # xyxy, (b, h*w, 4)
target_labels, target_bboxes, target_scores, fg_mask = self.assigner(
pred_scores.detach().sigmoid(),
(pred_bboxes.detach() * stride_tensor).type(gt_bboxes.dtype),
anchor_points * stride_tensor,
gt_labels,
gt_bboxes,
mask_gt)
target_labels2, target_bboxes2, target_scores2, fg_mask2 = self.assigner2(
pred_scores2.detach().sigmoid(),
(pred_bboxes2.detach() * stride_tensor).type(gt_bboxes.dtype),
anchor_points * stride_tensor,
gt_labels,
gt_bboxes,
mask_gt)
target_bboxes /= stride_tensor
target_scores_sum = max(target_scores.sum(), 1)
target_bboxes2 /= stride_tensor
target_scores_sum2 = max(target_scores2.sum(), 1)
# cls loss
# loss[1] = self.varifocal_loss(pred_scores, target_scores, target_labels) / target_scores_sum # VFL way
loss[1] = self.BCEcls(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum # BCE
loss[1] *= 0.25
loss[1] += self.BCEcls(pred_scores2, target_scores2.to(dtype)).sum() / target_scores_sum2 # BCE
# bbox loss
if fg_mask.sum():
loss[0], loss[2], iou = self.bbox_loss(pred_distri,
pred_bboxes,
anchor_points,
target_bboxes,
target_scores,
target_scores_sum,
fg_mask, imgsz[0], imgsz[1])
loss[0] *= 0.25
loss[2] *= 0.25
if fg_mask2.sum():
loss0_, loss2_, iou2 = self.bbox_loss2(pred_distri2,
pred_bboxes2,
anchor_points,
target_bboxes2,
target_scores2,
target_scores_sum2,
fg_mask2, imgsz[0], imgsz[1])
loss[0] += loss0_
loss[2] += loss2_
loss[0] *= 7.5 # box gain
loss[1] *= 0.5 # cls gain
loss[2] *= 1.5 # dfl gain
return loss.sum() * batch_size, loss.detach() # loss(box, cls, dfl)
class ComputeLossLH:
# Compute losses
def __init__(self, model, use_dfl=True):
device = next(model.parameters()).device # get model device
h = model.hyp # hyperparameters
# Define criteria
BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h["cls_pw"]], device=device), reduction='none')
# Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
self.cp, self.cn = smooth_BCE(eps=h.get("label_smoothing", 0.0)) # positive, negative BCE targets
# Focal loss
g = h["fl_gamma"] # focal loss gamma
if g > 0:
BCEcls = FocalLoss(BCEcls, g)
m = de_parallel(model).model[-1] # Detect() module
self.balance = {3: [4.0, 1.0, 0.4]}.get(m.nl, [4.0, 1.0, 0.25, 0.06, 0.02]) # P3-P7
self.BCEcls = BCEcls
self.hyp = h
self.stride = m.stride # model strides
self.nc = m.nc # number of classes
self.nl = m.nl # number of layers
self.no = m.no
self.reg_max = m.reg_max
self.device = device
self.assigner = TaskAlignedAssigner(topk=int(os.getenv('YOLOM', 10)),
num_classes=self.nc,
alpha=float(os.getenv('YOLOA', 0.5)),
beta=float(os.getenv('YOLOB', 6.0)))
self.bbox_loss = BboxLoss(m.reg_max - 1, use_dfl=use_dfl).to(device)
self.proj = torch.arange(m.reg_max).float().to(device) # / 120.0
self.use_dfl = use_dfl
def preprocess(self, targets, batch_size, scale_tensor):
if targets.shape[0] == 0:
out = torch.zeros(batch_size, 0, 5, device=self.device)
else:
i = targets[:, 0] # image index
_, counts = i.unique(return_counts=True)
out = torch.zeros(batch_size, counts.max(), 5, device=self.device)
for j in range(batch_size):
matches = i == j
n = matches.sum()
if n:
out[j, :n] = targets[matches, 1:]
out[..., 1:5] = xywh2xyxy(out[..., 1:5].mul_(scale_tensor))
return out
def bbox_decode(self, anchor_points, pred_dist):
if self.use_dfl:
b, a, c = pred_dist.shape # batch, anchors, channels
pred_dist = pred_dist.view(b, a, 4, c // 4).softmax(3).matmul(self.proj.type(pred_dist.dtype))
# pred_dist = pred_dist.view(b, a, c // 4, 4).transpose(2,3).softmax(3).matmul(self.proj.type(pred_dist.dtype))
# pred_dist = (pred_dist.view(b, a, c // 4, 4).softmax(2) * self.proj.type(pred_dist.dtype).view(1, 1, -1, 1)).sum(2)
return dist2bbox(pred_dist, anchor_points, xywh=False)
def __call__(self, p, targets, img=None, epoch=0):
loss = torch.zeros(3, device=self.device) # box, cls, dfl
feats = p[1][0] if isinstance(p, tuple) else p[0]
feats2 = p[1][1] if isinstance(p, tuple) else p[1]
pred_distri, pred_scores = torch.cat([xi.view(feats[0].shape[0], self.no, -1) for xi in feats], 2).split(
(self.reg_max * 4, self.nc), 1)
pred_scores = pred_scores.permute(0, 2, 1).contiguous()
pred_distri = pred_distri.permute(0, 2, 1).contiguous()
pred_distri2, pred_scores2 = torch.cat([xi.view(feats2[0].shape[0], self.no, -1) for xi in feats2], 2).split(
(self.reg_max * 4, self.nc), 1)
pred_scores2 = pred_scores2.permute(0, 2, 1).contiguous()
pred_distri2 = pred_distri2.permute(0, 2, 1).contiguous()
dtype = pred_scores.dtype
batch_size, grid_size = pred_scores.shape[:2]
imgsz = torch.tensor(feats[0].shape[2:], device=self.device, dtype=dtype) * self.stride[0] # image size (h,w)
anchor_points, stride_tensor = make_anchors(feats, self.stride, 0.5)
# targets
targets = self.preprocess(targets, batch_size, scale_tensor=imgsz[[1, 0, 1, 0]])
gt_labels, gt_bboxes = targets.split((1, 4), 2) # cls, xyxy
mask_gt = gt_bboxes.sum(2, keepdim=True).gt_(0)
# pboxes
pred_bboxes = self.bbox_decode(anchor_points, pred_distri) # xyxy, (b, h*w, 4)
pred_bboxes2 = self.bbox_decode(anchor_points, pred_distri2) # xyxy, (b, h*w, 4)
target_labels, target_bboxes, target_scores, fg_mask = self.assigner(
pred_scores2.detach().sigmoid(),
(pred_bboxes2.detach() * stride_tensor).type(gt_bboxes.dtype),
anchor_points * stride_tensor,
gt_labels,
gt_bboxes,
mask_gt)
target_bboxes /= stride_tensor
target_scores_sum = target_scores.sum()
# cls loss
# loss[1] = self.varifocal_loss(pred_scores, target_scores, target_labels) / target_scores_sum # VFL way
loss[1] = self.BCEcls(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum # BCE
loss[1] *= 0.25
loss[1] += self.BCEcls(pred_scores2, target_scores.to(dtype)).sum() / target_scores_sum # BCE
# bbox loss
if fg_mask.sum():
loss[0], loss[2], iou = self.bbox_loss(pred_distri,
pred_bboxes,
anchor_points,
target_bboxes,
target_scores,
target_scores_sum,
fg_mask)
loss[0] *= 0.25
loss[2] *= 0.25
if fg_mask.sum():
loss0_, loss2_, iou2 = self.bbox_loss(pred_distri2,
pred_bboxes2,
anchor_points,
target_bboxes,
target_scores,
target_scores_sum,
fg_mask)
loss[0] += loss0_
loss[2] += loss2_
loss[0] *= 7.5 # box gain
loss[1] *= 0.5 # cls gain
loss[2] *= 1.5 # dfl gain
return loss.sum() * batch_size, loss.detach() # loss(box, cls, dfl)
修改之后,开始训练模型吧。
使用yolov9训练自己的数据集/验证 /推理 /参数分析 内容 点击即可跳转
训练示例命令
cd yolov9项目路径
python3 train_dual.py --weights=yolov9-c.pt --cfg=models/detect/yolov9-c.yaml --data=data/fire.yaml --epoch=50 --batch-size=4 --imgsz=640 --hyp=data/hyps/hyp.scratch-high.yaml