CVPR 2024 - Open-Vocabulary Video Anomaly Detection
- 论文:https://arxiv.org/abs/2311.07042
- 原始文档:https://github.com/lartpang/blog/issues/14

这篇文章主要研究了开放词汇视频异常检测(openvocabulary video anomaly detection,OVVAD)的问题,这是一个具有挑战性但实际重要的问题。
传统方法不能处理开放词汇场景下的视频异常检测:
- 主要是因为它们通常针对特定类别或已知异常进行训练和检测,缺乏对未知异常(即开放词汇)的泛化能力。
- 此外,传统方法往往难以充分挖掘和利用视频数据中的时空信息以及外部知识,从而限制了其在开放词汇场景下的性能。
该研究提出了一种基于预训练大型模型的解决方案。利用语言图像预训练模型,如 CLIP 作为基础,得益于其强大的零样本泛化能力。
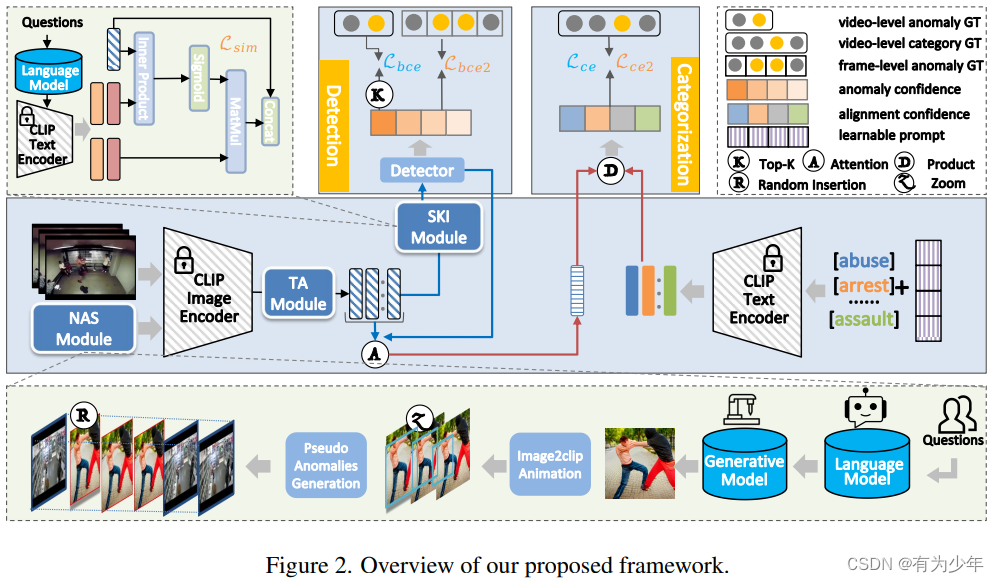
具体而言,将开放词汇视频异常检测任务分解为类无关检测(class-agnostic detection)和类特定分类(class-specific categorization)这样两个互补的子任务,以更好地处理开放词汇视频异常检测问题。并引入了几个专用模块来促进对基线和新异常的检测。
- 对于类无关的检测:设计了时序适配器模块(TA)和语义知识注入模块(SKI),主要旨在提高检测性能;
- 时序适配器模块 TA:现有的基于时序 Transformer 的设计面对新的类别时性能衰退严重,可能的原因是其中的额外参数特化于训练集,损害了对于新类别的泛化能力。因此本文设计了一个构建在经典的图卷积网络之上的几乎无权重的时序适配器来处理时序依赖,即 x t = LN ( softmax ( H ) x f ) , H i , j = − ∣ i − j ∣ σ x_t = \text{LN}(\text{softmax}(H)x_f), H_{i,j}=\frac{-|i-j|}{\sigma} xt=LN(softmax(H)xf),Hi,j=σ−∣i−j∣ 来对各帧特征进行交互重组,这里仅有的额外参数来自于 LN。
- 语义知识注入模块 SKI:该模块旨在将额外的语义知识引入视觉检测任务中,以提高模型性能。SKI 引入额外的关于异常场景的短语(包括场景名词和动作动词)作为先验知识输入 CLIP。然后使用视觉特征利用类似于 cross-attention 的操作从文本特征中寻找相关的语义知识 F k n o w = sigmoid ( x t F t e x t ⊤ ) F t e x t ⊤ / l F_{know} = \text{sigmoid}(x_t F^{\top}_{text})F^{\top}_{text}/l Fknow=sigmoid(xtFtext⊤)Ftext⊤/l。这里使用 sigmoid 函数来促使视觉信号可以组合更多相关的语义概念。模块输出直接送入二值检测器中获得类无关检测的帧异常和视频异常得分。
- 对于细粒度异常分类:考虑到 CLIP 这样的预训练 VLM 面对视频相关的数据时 zore-shot 能力有限,本文使用新异常合成模块(NAS)基于潜在的异常类别生成可能的伪新异常视频样本,以帮助模型更准确地分类新异常类型。主要由三个关键过程组成:
- 首先,使用预定义的模板提示生成器(prompt_gen)来提示大型语言模型(LLMs),例如 ChatGPT 和 ERNIE Bot,以生成有关现实世界中“战斗”的十个简短场景描述。
- 然后,使用 AI 生成模型(AIGC)例如 DALLE mini 和 Gen-2,从生成的文本描述中产生相应的图像(Igen)或短视频(Sgen)。
- Igen 会从单个图像转成视频片段,具体使用不同的检测比例中心剪裁图像中的对应区域,然后放缩到原始尺寸后,堆叠形成新的视频片段 Scat。
- 为了模拟完整长异常视频中真实世界场景,这里将生成的 Scat 或者 Sgen 被随机插入到正常视频中的随机位置上,从而获得最终的伪异常视频样本 Vnas。
- 利用这些 Vnas 可以微调训练在现有标准数据集(包含正常样本和异常样本)上的模型,从而增强其对于新异常的泛化能力。
实验结果表明,该模型在三个公开基准 UBnormal,UCF-Crime,XD-Violence 上优于现有方法,特别是在处理新类别时表现出明显的优势。