莫名地这篇论文我特别难理解,配合代码也食用不了
1.论文介绍
Head-Free Lightweight Semantic Segmentation with Linear Transformer
基于线性Transformer的无头轻量级语义分割
2023年 AAAI
Paper Code
2.摘要
现有的语义分割工作主要集中在设计有效的解码器,但长期以来忽略了整体结构引入的计算负载,这阻碍了它们在资源受限的硬件上的应用。在本文中,我们提出了一个专门用于语义分割的无头轻量级架构,名为自适应频率Transformer(AFFormer)。AFFormer采用并行架构,利用原型表示作为特定的可学习局部描述,取代解码器并保留高分辨率特征上丰富的图像语义。虽然去除解码器压缩了大部分计算,但并行结构的精度仍然受到低计算资源的限制。因此,我们采用异构运算符(CNN和Vision Transformer)进行像素嵌入和原型表示,以进一步保存计算成本。此外,从空间域的角度线性化视觉Transformer的复杂性是非常困难的。由于语义分割对频率信息非常敏感,我们构造了一个轻量级的原型学习块,其复杂度为O(n)的自适应频率滤波器来代替标准的自我注意,复杂度为O(n2)。
Keywords:无头轻量结构(无解码器),语义分割,线性Transformer
创新:1)无解码器的轻量结构,使用原型表示代替解码器; 2)自适应频率滤波器
3.Introduction
语义分割的目的是将图像划分为子区域(像素集合),并定义为像素级分类任务。与图像分类相比,它有两个独特的特点:逐像素的密集预测和多类表示,这通常是建立在高分辨率的功能,并需要图像语义的全局归纳能力,分别。以前的语义分割方法专注于使用分类网络作为主干来提取多尺度特征,并设计复杂的解码器头来建立多尺度特征之间的关系。然而,这些改进是以较大的模型尺寸和较高的计算成本为代价的。
最近视觉Transformer在语义分割方面表现出了巨大的潜力,然而,当部署在超低计算功率设备上时,它们面临平衡性能和存储器使用的挑战。标准Transformer在空间域中的计算复杂度为O(n2),其中n是输入分辨率。现有的方法通过减少标记的数量或滑动窗口来缓解这种情况,但它们对计算复杂性的降低有限,甚至会损害分割任务的全局或局部语义。同时,语义分割作为一个基础研究领域,有着广泛的应用场景,需要处理各种分辨率的图像。
因此,本文提出了两个问题:语义分割能像图像分类一样简单吗?我们能否设计一个高效、轻量级的Transformer网络,用于超低计算场景下的语义分割?
本文提出了一个无头轻量级语义分割的具体架构,自适应频率Transformer(AFFormer)。受ViT维护单个高分辨率特征图以保留细节的属性的启发,金字塔结构降低了探索语义和降低计算成本的分辨率,AFFormer采用并行架构来利用原型表示作为特定的可学习局部描述,其取代解码器,保留了高分辨率特征上丰富的图像语义。并行结构通过去除解码器来压缩大部分计算,但对于超低计算资源来说仍然不够。此外,我们采用异构算子的像素嵌入功能和本地描述功能,以节省保存更多的计算成本。一个名为原型学习(PL)的基于转换器的模块用于学习原型表示,而一个名为像素描述符(PD)的基于卷积的模块将像素嵌入特征和学习的原型表示作为输入,将它们转换回完整的像素嵌入空间以保留高分辨率语义。
然而,从空间域的角度对视觉Transformer的复杂度进行线性化仍然是非常困难的。灵感来自于频率对分类任务的影响,我们发现语义分割对频率信息也非常敏感。因此,我们构造了一个复杂度为O(n)的轻量级自适应频率滤波器作为原型学习,以O(n2)代替标准的自注意。该模块的核心由频率相似性核、动态低通和高通滤波器组成,分别从强调重要频率成分和动态滤除频率的角度捕捉有利于语义切分的频率信息。最后,通过在高频和低频提取和增强模块中共享权重来进一步降低计算成本。我们还在前馈网络(FFN)层中嵌入了一个简化的去卷积卷积层,以增强融合效果,减少两个矩阵变换的大小。
4.网络结构详解
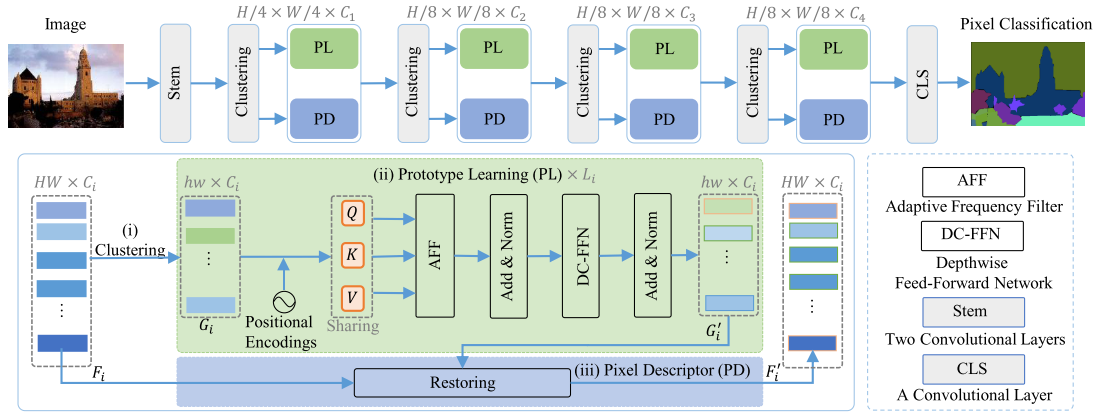
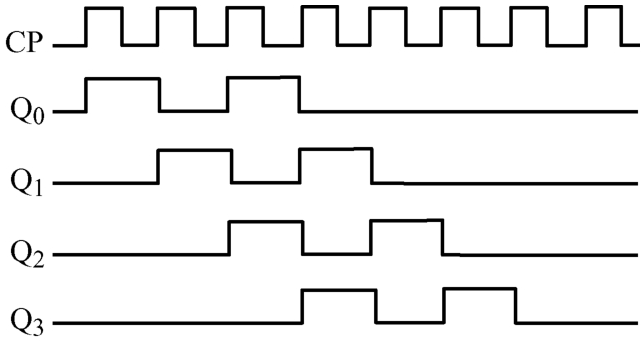
网络整体流程如上。首先输入图像经过Stem两层卷积,然后进行patch embedding后得到特征F进行聚类,得到原型特征G,从而构造一个并行网络结构,该结构包含两个异构算子。基于变换器的模块作为原型学习,以捕获G中的有利频率分量,从而产生原型表示G’。最后,通过基于CNN的像素描述符恢复G’,得到下一阶段的F’。
上面是原文中的描述,其实它是经过两层卷积后,进入主流阶段,图上画了四个,每个阶段如下:
首先经过patch embedding处理,然后入encoder中,得到的输出入下一阶段,把所有阶段的结果整合输出作为最后的结果。
对于每一个阶段:如果是第一个阶段则把输入的前两个patch直接Restore成最终结果(如上图中左下方箭头),如果不是第一个阶段,则Restore第一个输入patch作out[0],然后MHCAEncoder剩余的作剩余out,最后把out的前两个相加作最后结果。
至于说F聚类成G,不知道在哪实现的。
而并行异构体系是指,PL是基于Transformer的,而PD是基于CNN的,他俩并行,我感觉是串行但是没有输入输出的关联,所以并。
并行异构体系结构:
语义解码器将编码器获得的图像语义传播到每个像素,并恢复下采样中丢失的细节。一个简单的替代方法是在高分辨率特征中提取图像语义,但它引入了大量的计算,特别是对于vision transformer。与此相反,本文提出了一种新的策略来描述像素的语义信息与原型语义。对于每个阶段,给定一个特征
F
∈
R
H
×
W
×
C
F ∈ R^{H×W×C}
F∈RH×W×C,我们首先初始化一个网格
G
∈
R
h
×
w
×
C
G ∈ R^{h×w×C}
G∈Rh×w×C作为图像的原型,其中G中的每个点作为局部聚类中心,初始状态仅包含周围区域的信息。在这里,我们使用1 × C向量来表示每个点的局部语义信息。对于每个特定的像素,由于周围像素的语义不一致,每个聚类中心之间存在重叠语义。聚类中心在其对应的区域α2中进行加权初始化,每个聚类中心的初始化表示为:
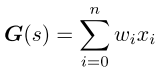
其中n = α × α,wi表示Xi的权重,α设置为3。目的是更新网格G中的每个聚类中心s,而不是直接更新特征F。当h × w << H ×W时,大大简化了计算。在这里,使用一个基于transformer的模块作为原型学习来更新每个聚类中心,它总共包含L层,更新后的中心表示为G(s)。对于每个更新的聚类中心,恢复它的像素描述符。令 F i ′ F'_i Fi′表示恢复的特征,其不仅包含来自F的丰富像素语义,而且还包含由聚类中心G(s)收集的原型语义。由于聚类中心聚集了周围像素的语义,导致局部细节的丢失,PD首先用像素语义对F中的局部细节进行建模。具体来说,F被投影到低维空间,建立像素之间的局部关系,使得每个局部补丁保持不同的边界。然后通过双线性插值将G(s)嵌入到F中,恢复到原始空间特征F。最后,它们通过线性投影层集成。
基于自适应频率滤波激励的原型学习:
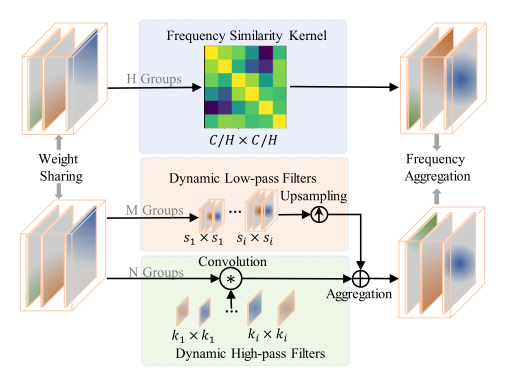
语义分割是一个非常复杂的像素级分类任务,很容易出现类别混淆。频率表示可以作为一种新的学习类别之间差异的范式,它可以挖掘人类视觉忽略的信息。由于特征F包含丰富的频率特征,因此网格G中的每个聚类中心也收集这些频率信息。受上述分析的启发,在网格G中提取更多的有益频率有助于区分每个聚类的属性。为了提取不同的频率特征,最直接的方法是通过傅立叶变换将空间域特征转换为谱特征,并在频域使用简单的掩模滤波器以增强或衰减频谱的每个频率分量的强度。然后,提取的频率特征被转换到空间域的逆傅立叶变换。然而,傅立叶变换和逆变换带来额外的计算开销,并且这些运算符在许多硬件上不支持。因此,我们从谱相关的角度设计了一个基于vanilla vision Transformer的自适应频率滤波器模块,直接在空间域中捕获重要的高频和低频特征。核心组件如上图所示,公式定义为:
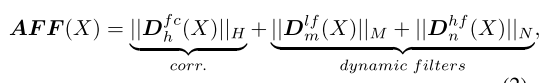
其中
D
h
f
c
D^{fc}_h
Dhfc、
D
m
l
f
(
X
)
D^{lf}_m(X)
Dmlf(X)和
D
n
h
f
(
X
)
D^{hf}_n(X)
Dnhf(X)分别表示具有H组的频率相似性核以实现频率分量相关增强、具有M组的动态低通滤波器和具有N组的动态高通滤波器。|| · ||表示串联。值得注意的是,这些算子采用并行结构,通过共享权重进一步降低计算成本。
频率相似核(FSK):
不同的频率成分分布在G中,我们的目的是选择和增强有助于语义分析的重要成分。为此,我们设计了一个频率相似性核模块。通常,该模块由视觉Transformer实现。给定一个特征
X
∈
R
h
w
×
C
X ∈ R^{hw×C}
X∈Rhw×C,通过卷积层对G进行相对位置编码。该算法首先使用一个固定大小的相似性核
A
∈
R
C
/
H
×
C
/
H
A ∈ R^{C/H×C/H}
A∈RC/H×C/H来表示不同频率分量之间的对应关系,并通过查询相似性核来选择重要的频率分量。我们将其视为函数传递,其通过线性函数传递计算频率分量的键K和值V,并通过Softmax运算在频率分量上对键进行归一化。每个分量集成相似性核Ai,j,其被计算为:
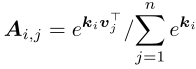
其中ki表示K中的第i个频率分量,vj表示V中的第j个频率分量。我们还通过线性层将输入X转换为查询Q,并通过在固定大小的相似性核上的交互获得分量增强的输出。
动态低通滤波器(DLF):低频分量占据了绝对图像中的大部分能量,代表了大部分的语义信息。低通滤波器允许低于截止频率的信号通过,而阻止高于截止频率的信号。因此,我们采用典型的平均池作为低通滤波器。然而,不同图像的截止频率不同。为此,我们在多组中控制不同的内核和步幅来生成动态低通滤波器。对于第m组,我们有:
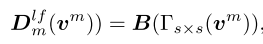
其中B(·)表示双线性插值,Γs×s表示输出大小为s × s的自适应平均池化。
动态高通滤波器(DHF):高频信息对于保持分割中的细节至关重要。卷积作为一种典型的高通算子,可以滤除不相关的低频冗余分量,保留有利的高频分量。高频分量决定图像质量,并且每个图像的高通截止频率不同。因此,我们将值V分成N组,得到vn。对于每组,我们使用具有不同内核的卷积层来模拟不同高通滤波器中的截止频率。对于第n组,我们有:
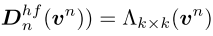
其中Λk×k表示具有k×k的核大小的深度卷积层。此外,我们使用的Hadamard产品的查询和高频功能,以抑制高频内的对象,这是分割的噪声。FFN有助于融合捕获的频率信息,但计算量大,在轻量级设计中经常被忽略。在这里,我们通过引入卷积层来减少隐藏层的维度,以弥补由于维度压缩而丢失的功能。
最后疏通了大部分,还是没理解初始化G的过程,可能是代码能力不行,有看明白的请帮我解答一下。