对比学习可以通过自我监督的方式捕捉时间序列数据中的时间依赖性和动态变化,这使得它特别适合处理时间序列数据,因为时间序列的本质特征就在于其随时间的演变和变化。
因此,相较于传统的时序,基于对比学习的时间序列能够适应更广泛、更复杂的应用场景,它可以更有效地从原始数据中学习到有用的特征,而不需要大量的标注数据,显著提高模型的泛化能力和性能。
以南京航空航天大学提出的TimesURL为例:
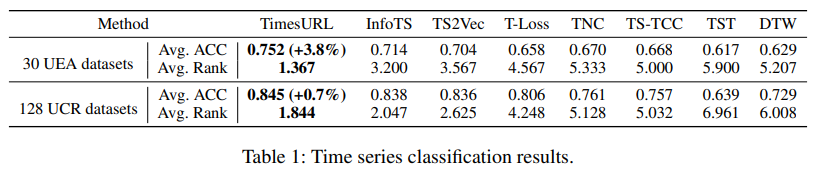
TimesURL引入了基于频率时间的增强以保持时间属性,并构建双重universe作为硬负样本来提升对比学习效果,同时将时间重构作为联合优化目标以提取段级和实例级特征。在30个单变量数据集和128个多变量数据集上的实验中,TimesURL的平均准确率分别为75.2%和84.5%。目前该工作已经被AI顶会 AAAI 2024 收录。
本文挑选了11个基于对比学习的时间序列最新成果,可借鉴的方法和创新点做了简单提炼,原文以及相应代码都整理了,方便同学们学习。
论文和开源代码需要的同学看文末
TimesURL: Self-supervised Contrastive Learning for Universal Time Series Representation Learning
方法:论文介绍了一种名为TimesURL的自监督学习框架,用于学习适用于各种类型下游任务的通用时间序列表示。该框架包括对比学习和时间重建两个关键组件,并使用设计的增强和双宇宙合成方法来增强性能。实验结果表明,TimesURL在多个下游任务中取得了最先进的性能,证明了其学习时间序列通用表示的能力。
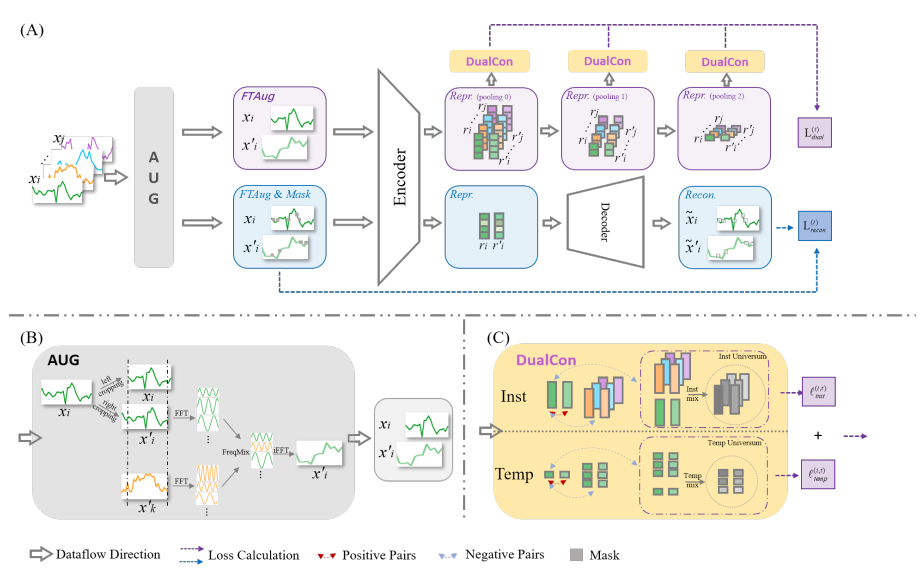
创新点:
-
FTAug 方法:通过频率混合和随机裁剪生成增强上下文,保持时间序列的重要时序关系和语义一致性,有助于各种任务的高质量时间序列表示学习。
-
TimesURL框架:引入了频率-时间增强方法和双重Universums作为高质量难负样本,同时结合对比学习和时间重建来捕捉段级和实例级信息,学习出适用于多种任务的高质量通用表示。
SELF-SUPERVISED CONTRASTIVE FORECASTING
方法:论文介绍了一种新颖的对比学习方法,以帮助模型捕捉不同窗口之间存在的长期依赖关系。该方法利用了小批量可以包含时间上相隔较远的窗口的事实,并且允许窗口之间的间隔跨越整个序列长度。论文中描述了对比损失的详细细节,并且将该损失与基于分解的模型架构结合起来,该架构包括一个短期分支和一个长期分支。该损失主要应用于长期分支。
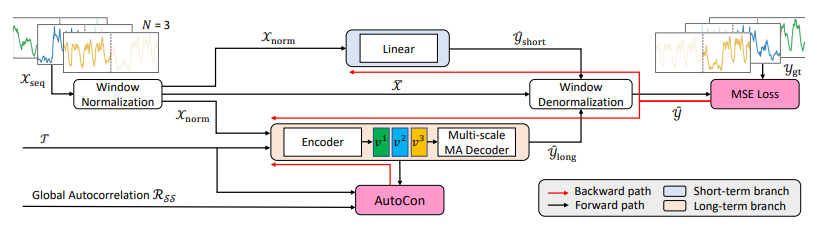
创新点:
-
提出了AutoCon对比损失函数,用于学习长期依赖关系。该损失函数通过构建正负样本对来自整个时间序列的远距离窗口之间的关系,能够有效地捕捉到长期变化。这是首次在时间序列预测中采用对比学习方法来捕捉全局自相关性。
-
重新设计了分解网络结构,使得长期分支具有足够的容量来学习来自AutoCon的长期表示。这种重新设计的分解架构能够更好地学习长期模式,并在长期预测任务中取得了显著的性能提升。
Semi-Supervised End-To-End Contrastive Learning For Time Series Classification
方法:论文提出了一种名为SLOTS(Semi-supervised Learning fOr Time clasSification)的端到端模型,用于半监督时间序列分类。该模型通过一个编码器将半标记数据集映射到嵌入空间,并计算无监督对比损失和有监督对比损失。同时,利用可用的真实标签计算分类损失。通过联合使用无监督对比损失、有监督对比损失和分类损失来优化编码器和分类器。
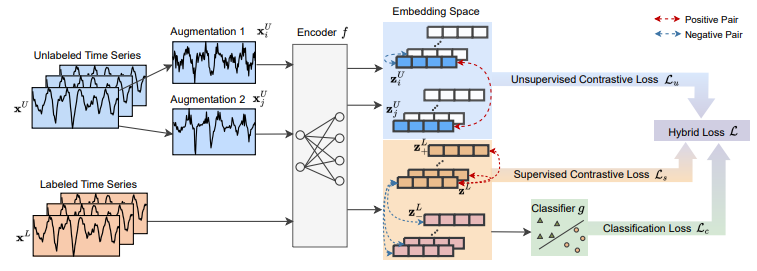
创新点:
-
提出了一种新颖的半监督框架,能够在最小标记样本的情况下实现最佳性能,并且可以无缝集成到各种架构中。
-
通过系统地结合无监督对比损失、有监督对比损失和分类损失来共同更新模型,最大限度地利用数据中的信息。
-
SLOTS模型可以同时训练编码器和分类器,通过统一模型优化、减少中间计算资源和学习任务特定特征,实现端到端训练。
-
SLOTS模型不仅计算无监督对比损失和有监督分类损失,还引入了有监督对比损失,利用可用的真实标签进行计算,以充分利用有价值的真实信息。
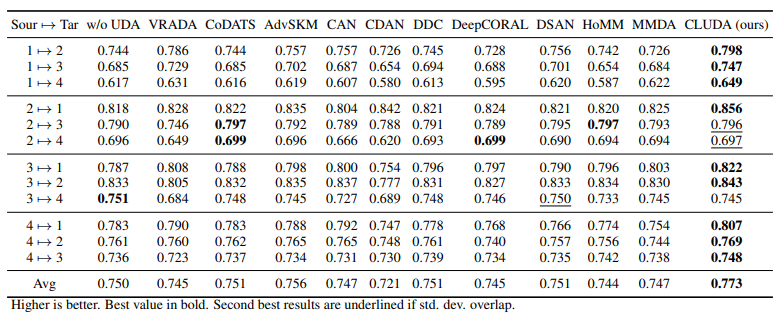
CONTRASTIVE LEARNING FOR UNSUPERVISED DOMAIN ADAPTATION OF TIME SERIES
方法:论文介绍了一种用于时间序列无监督领域适应(UDA)的新框架,名为CLUDA。该框架利用对比学习来捕捉多元时间序列中的上下文表示,以保留标签信息用于预测任务。CLUDA进一步通过自定义的最近邻对比学习来捕捉和对齐源领域和目标领域之间的上下文表示。它是第一个为时间序列的UDA学习领域构建的学习域不变的上下文表示的框架,并且在时间序列UDA方面实现了最先进的性能。
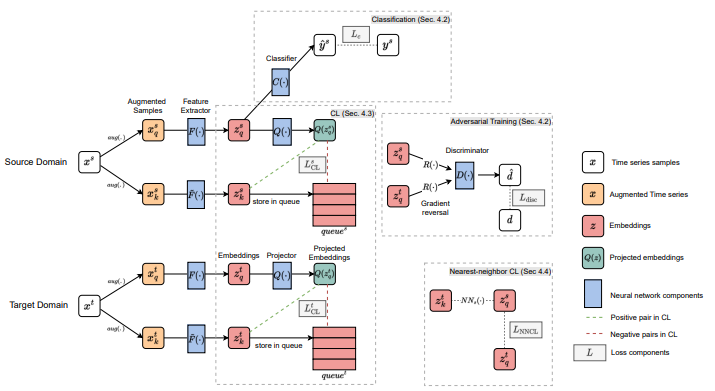
创新点:
-
作者提出了一种名为CLUDA的新颖框架,用于时序数据的无监督领域自适应。该框架利用对比学习来学习多变量时序数据的上下文表示,以保留标签信息以用于预测任务。
-
作者通过自定义的最近邻对比学习进一步捕捉源域和目标域之间上下文表示的差异。这是第一个用于时序数据领域自适应的最近邻对比学习方法。
-
作者通过广泛的实验验证了我们的框架的有效性,并展示了它在时序数据领域自适应中的最先进性能。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“对比时序”获取全部论文+代码
码字不易,欢迎大家点赞评论收藏