StylizedGS: Controllable Stylization for 3D Gaussian Splatting
StylizedGS:3D高斯溅射的可控样式化
张定西,陈卓勋,袁玉洁,张芳略,何振良,Shiguang Shan,Lin Gao 11 Corresponding Author is Lin Gao (gaolin@ict.ac.cn). Dingxi Zhang and Zhuoxun Chen are with the University of Chinese Academy of Sciences, Beijing, China.
1通讯作者为高林(gaolin@ict.ac.cn)。张定西和陈卓勋来自中国北京中国科学院大学。
E-Mail: {zhangdingxi20a, zhuoxunchen20}@mails.ucas.ac.cn Yu-Jie Yuan and Lin Gao are with the Beijing Key Laboratory of Mobile Computing and Pervasive Device, Institute of Computing Technology, Chinese Academy of Sciences, Beijing, China, and also with the University of Chinese Academy of Sciences, Beijing, China.
电子邮件地址:{zhangdingxi 20 a,zhuoxunchen 20}@mails.ucas.ac.cn Yu-Jie Yuan和Lin Gao来自中国科学院计算技术研究所北京移动的计算与普适设备重点实验室和中国科学院大学。
E-Mail: {yuanyujie, gaolin}@ict.ac.cn Fang-Lue Zhang is with Victoria University of Wellington, New Zealand. Zhenliang He and Shiguang Shan are with the Key Laboratory of Intelligent Information Processing, Institute of Computing Technology, Chinese Academy of Sciences, Beijing, China, and also with the University of Chinese Academy of Sciences, Beijing, China.
E-Mail:{yuanyujie,gaolin}@ict.ac.cn Fang-Lue Zhang来自新西兰惠灵顿的维多利亚大学。Zhenliang He和Shiguang Shan分别就职于中国科学院计算技术研究所智能信息处理重点实验室和中国科学院大学。
E-mail: {hezhenliang, sgshan}@ict.ac.cn
邮箱:{hezhenliang,sgshan}@ict.ac.cn
Abstract 摘要 StylizedGS: Controllable Stylization for 3D Gaussian Splatting
With the rapid development of XR, 3D generation and editing are becoming more and more important, among which, stylization is an important tool of 3D appearance editing. It can achieve consistent 3D artistic stylization given a single reference style image and thus is a user-friendly editing way. However, recent NeRF-based 3D stylization methods face efficiency issues that affect the actual user experience and the implicit nature limits its ability to transfer the geometric pattern styles. Additionally, the ability for artists to exert flexible control over stylized scenes is considered highly desirable, fostering an environment conducive to creative exploration. In this paper, we introduce StylizedGS, a 3D neural style transfer framework with adaptable control over perceptual factors based on 3D Gaussian Splatting (3DGS) representation. The 3DGS brings the benefits of high efficiency. We propose a GS filter to eliminate floaters in the reconstruction which affects the stylization effects before stylization. Then the nearest neighbor-based style loss is introduced to achieve stylization by fine-tuning the geometry and color parameters of 3DGS, while a depth preservation loss with other regularizations is proposed to prevent the tampering of geometry content. Moreover, facilitated by specially designed losses, StylizedGS enables users to control color, stylized scale and regions during the stylization to possess customized capabilities. Our method can attain high-quality stylization results characterized by faithful brushstrokes and geometric consistency with flexible controls. Extensive experiments across various scenes and styles demonstrate the effectiveness and efficiency of our method concerning both stylization quality and inference FPS.
随着XR的快速发展,三维生成和编辑变得越来越重要,其中风格化是三维外观编辑的重要工具。它可以实现一致的3D艺术风格给定一个参考样式的图像,因此是一个用户友好的编辑方式。然而,最近的NeRF为基础的3D风格化方法面临的效率问题,影响实际的用户体验和隐式的性质限制了其传输的几何图案样式的能力。此外,艺术家对程式化场景施加灵活控制的能力被认为是非常可取的,从而培养有利于创造性探索的环境。在本文中,我们介绍了StylizedGS,一个3D神经风格转移框架,具有自适应控制感知因素的基础上3D高斯飞溅(3DGS)表示。3DGS带来了高效率的好处。 我们提出了一个GS滤波器,以消除重建中的浮动,影响风格化之前的风格化效果。然后引入基于最近邻的样式丢失,通过微调3DGS的几何和颜色参数实现样式化,同时提出深度保持丢失和其他正则化,以防止几何内容的篡改。此外,通过专门设计的损失,StylizedGS使用户能够在风格化过程中控制颜色,风格化规模和区域,以拥有定制的能力。我们的方法可以获得高质量的风格化结果,其特点是忠实的笔触和几何一致性与灵活的控制。在各种场景和风格的广泛实验证明了我们的方法的有效性和效率,风格化质量和推理FPS。
Index Terms:
Gaussian Splatting, Style Transfer, Perceptual Control索引词:高斯飞溅,风格转移,知觉控制

Figure 1:Stylization Results. Given a 2D style image, the proposed StylizedGS method can stylize the pre-trained 3D Gaussian Splatting to match the desired style with detailed geometric features and satisfactory visual quality within a few minutes. We also enable users to control several perceptual factors, such as color, the style pattern size (scale), and the stylized regions (spatial), during the stylization to enhance the customization capabilities.
图1:定型结果。给定一个2D样式图像,所提出的StylizedGS方法可以在几分钟内对预训练的3D Gaussian Splatting进行风格化,以匹配具有详细几何特征和令人满意的视觉质量的所需样式。我们还使用户能够控制几个感知因素,如颜色,风格模式的大小(规模),和风格化的区域(空间),在风格化,以提高定制能力。
1Introduction 1引言
Nowadays, the once professionally-dominated domain of artistic content creation has become increasingly accessible to novice users, thanks to recent groundbreaking advancements in visual artistic stylization research. As a pivotal artistic content generation tool in crafting visually engaging and memorable experiences, 3D scene stylization has attracted growing research efforts. Previous methodologies have attempted style transfer by enabling control over diverse explicit representations such as mesh [1, 2, 3], voxel [4, 5], and point cloud [6, 7, 8]. However, the quality of their results is limited by the quality of the geometric reconstructions. The recent 3D stylization methods benefit from the emerging implicit neural representations [9, 10, 11], such as neural radiance field (NeRF) [12, 13, 14, 15, 16], achieving more faithful and consistent stylization within 3D scenes. Nonetheless, NeRF-based methods are computationally intensive to optimize and suffer from the geometry artifacts in the original radiance fields.
如今,由于视觉艺术风格化研究的突破性进展,曾经专业主导的艺术内容创作领域已经越来越多地为新手用户所接受。作为一个关键的艺术内容生成工具,在制作视觉上引人入胜和难忘的经验,3D场景风格化吸引了越来越多的研究工作。先前的方法已经尝试通过启用对诸如网格[ 1,2,3]、体素[ 4,5]和点云[ 6,7,8]等各种显式表示的控制来进行样式转换。然而,他们的结果的质量是有限的几何重建的质量。最近的3D风格化方法受益于新兴的隐式神经表示[9,10,11],例如神经辐射场(NeRF)[12,13,14,15,16],在3D场景中实现更忠实和一致的风格化。 尽管如此,基于NeRF的方法是计算密集型的,以优化并遭受原始辐射场中的几何伪影。
The recently introduced 3D Gaussian Splatting (3DGS) [17], showcasing remarkable 3D reconstruction quality from multi-view images with high efficiency, suggests representing the 3D scene using an array of colored and explicit 3D Gaussians. Given that practical 3D stylization applications often demand a prompt response, we propose using 3DGS as the representation of real-world scenes and conducting 3D stylization on it. Recent 3DGS scene manipulation methods [18, 19, 20, 21] explore the editing and control of 3D Gaussians using text instructions within designated regions of interest or semantic tracing. However, these approaches are constrained by text input and fall short of delivering detailed style transfer capabilities. The methods for performing 3D Gaussian stylization remain less explored in the field.
最近引入的3D高斯溅射(3DGS)[ 17],展示了高效率的多视图图像的卓越3D重建质量,建议使用彩色和显式3D高斯阵列来表示3D场景。考虑到实际的3D风格化应用通常需要快速响应,我们建议使用3DGS作为真实世界场景的表示并对其进行3D风格化。最近的3DGS场景操作方法[18,19,20,21]探索使用指定感兴趣区域或语义跟踪内的文本指令编辑和控制3D高斯。然而,这些方法受到文本输入的限制,并且无法提供详细的样式转换功能。用于执行3D高斯风格化的方法在该领域中仍然较少探索。
In this paper, we introduce the first controllable scene stylization method based on 3DGS, StylizedGS. With a single reference style image, our method can effectively transfer its style features to the entire 3D scene, represented by a set of 3D Gaussians. It facilitates the artistic creation of visually coherent novel views that exhibit transformed and detailed style features in a visually reasonable manner. More importantly, StylizedGS operates at a notable inference speed, ensuring the efficient synthesis of stylized scenes. To address the desire for users to control perceptual factors such as color, scale, and spatial aspects, as in 2D image style transfer [22, 23, 24] and 3D scene style transfer [25], we enhance the flexibility and introduce an advanced level of perceptual controllability in our approach to achieve personalized and diverse characteristics in 3DGS stylization.
本文介绍了第一种基于3DGS的可控场景风格化方法StylizedGS。对于单个参考样式图像,我们的方法可以有效地将其样式特征转移到由一组3D高斯表示的整个3D场景中。它促进了视觉上连贯的新颖观点的艺术创作,这些观点以视觉上合理的方式展示了转换和详细的风格特征。更重要的是,StylizedGS以显著的推理速度运行,确保高效合成风格化场景。为了满足用户控制感知因素(如颜色,比例和空间方面)的愿望,如2D图像风格转换[22,23,24]和3D场景风格转换[ 25],我们增强了灵活性并在我们的方法中引入了高级感知可控性,以实现3DGS风格化中的个性化和多样化特征。
The proposed 3DGS stylization process is formulated as an optimization problem that optimizes the geometry and color of 3D Gaussians to render images with faithful stylistic features while preserving the semantic content. A trivial solution is directly minimizing both a style loss and a content loss to align the rendered images with the style image and avoid overly strong stylization by fine-tuning the color of 3D Gaussians, respectively. Nevertheless, it poses a challenge in obtaining high-quality results with intricate style details as shown in Fig. 10 (b), as learning only the color alterations cannot effectively capture the overall style pattern. Instead, we propose to learn both the optimal geometry and color parameters of 3D Gaussians to capture the detailed style feature and facilitate the stylization of the entire 3D scene. We propose a 2-step stylization framework with the first step to enhance the fidelity in the stylized scene by the color match and reduce cloudy artifacts and geometry noises by the proposed GS filter. The second step is the optimization for stylization with a nearest neighbor feature match (NNFM) loss. We also introduce a depth preservation loss without the need for additional networks or regulation operations to preserve the overall learned 3D scene geometry. Last, we specially design a set of effective loss functions and optimization schemes to enable flexible perceptual control for users, including color, scale, and spatial regions Our contribution can be summarized as follows:
建议的3DGS风格化过程被制定为一个优化问题,优化的几何形状和颜色的3D高斯渲染图像与忠实的风格特征,同时保留语义内容。一个简单的解决方案是直接最小化样式损失和内容损失,以分别通过微调3D高斯的颜色来将渲染图像与样式图像对齐并避免过于强烈的风格化。然而,它在获得具有复杂风格细节的高质量结果方面提出了挑战,如图10(b)所示,因为仅学习颜色变化不能有效地捕捉整体风格模式。相反,我们建议学习3D高斯的最佳几何和颜色参数,以捕获详细的风格特征,并促进整个3D场景的风格化。 我们提出了一个两步风格化框架,第一步是通过颜色匹配来增强风格化场景的保真度,并通过建议的GS滤波器来减少云状伪影和几何噪声。第二步是在最近邻特征匹配(NNFM)损失的情况下对风格化进行优化。我们还引入了深度保留损失,而不需要额外的网络或调节操作来保留整体学习的3D场景几何。 最后,我们专门设计了一套有效的损失函数和优化方案,为用户提供灵活的感知控制,包括颜色,尺度和空间区域。
- •
We introduce StylizedGS, a novel controllable 3D Gaussian stylization method that organically integrates various modules with proper improvements to transfer detailed style features and produce faithful novel stylized views.
·我们介绍了StylizedGS,一种新型的可控3D高斯风格化方法,通过适当的改进,有机地整合了各个模块,以传递详细的风格特征,并产生忠实的新颖风格化视图。 - •
We empower users with an efficient stylization process and flexible control by specially designed losses, enhancing their creative capabilities.
·我们为用户提供高效的风格化流程,并通过专门设计的损失进行灵活控制,增强他们的创造力。 - •
Our approach achieves significantly reduced training and rendering times while generating high-quality stylized scenes compared with existing 3D stylization methods.
·与现有的3D风格化方法相比,我们的方法在生成高质量的风格化场景的同时,显著减少了训练和渲染时间。
2Related Work 2相关工作
Image Style Transfer. Style transfer aims to generate synthetic images with the artistic style of given images while preserving content. Initially proposed in neural style transfer methods by Gatys et al. [26, 27], this process involves iteratively optimizing the output image using Gram matrix loss and content loss calculated from VGG-Net [28] extracted features. Subsequent works [29, 30, 31, 32] have explored alternative style loss formulations to enhance semantic consistency and capture high-frequency style details such as brushstrokes. Feed-forward transfer methods [33, 34, 35], where neural networks are trained to capture style information from the style image and transfer it to the input image in a single forward pass, ensuring faster stylization. Recent improvements in style loss [31, 32, 13] involve replacing the global Gram matrix with the nearest neighbor feature matrix, improving texture preservation. Some methods adopt patch matching for image generation, like Fast PatchMatch [36] and PatchMatch [37], but are limited to specific views. Combining neural style transfer with novel view synthesis methods without considering 3D geometry may lead to issues like blurriness or view inconsistencies.
图像风格转换。风格转移的目的是生成具有给定图像艺术风格的合成图像,同时保留内容。最初由Gatys等人在神经风格转移方法中提出。[ 26,27],该过程涉及使用从VGG-Net [ 28]提取的特征计算的Gram矩阵损失和内容损失迭代优化输出图像。随后的工作[ 29,30,31,32]探索了替代的风格损失公式,以增强语义一致性并捕获高频风格细节,如笔触。前馈传输方法[ 33,34,35],其中神经网络经过训练,从样式图像中捕获样式信息,并在单次向前传递中将其传输到输入图像,确保更快的风格化。最近在风格损失方面的改进[ 31,32,13]涉及用最近邻特征矩阵替换全局Gram矩阵,改善纹理保留。 一些方法采用补丁匹配来生成图像,如Fast PatchMatch [ 36]和PatchMatch [ 37],但仅限于特定视图。在不考虑3D几何形状的情况下将神经风格转移与新颖的视图合成方法相结合可能会导致模糊或视图不一致等问题。
3D Gaussian Splatting. 3D Gaussian Splatting (3DGS) [17] has emerged as a robust approach for real-time radiance field rendering and 3D scene reconstruction. Recent methods [20, 19, 18, 38] enhance semantic understanding of 3D scenes and enabled efficient text-based editing using pre-trained 2D models. Despite these advancements, existing 3DGS works lack support for image-based 3D scene stylization that faithfully transfers detailed style features while offering flexible control. In this work, leveraging the 3DGS representation, we significantly reduce both training and rendering times for stylization, enabling interactive perceptual control over stylized scenes.
3D高斯散射3D高斯溅射(3DGS)[ 17]已经成为实时辐射场渲染和3D场景重建的鲁棒方法。最近的方法[20,19,18,38]增强了对3D场景的语义理解,并使用预训练的2D模型实现了高效的基于文本的编辑。尽管有这些进步,现有的3DGS作品缺乏对基于图像的3D场景风格化的支持,该风格化忠实地传递详细的风格特征,同时提供灵活的控制。在这项工作中,利用3DGS表示,我们显着减少了风格化的训练和渲染时间,使交互式感知控制风格化的场景。

Figure 2:StylizedGS Pipeline. We first reconstruct a photo-realistic 3DGS ����� from multi-view input. Following this, color matching with the style image is performed, accompanied by the application of 3DGS filters to preemptively address potential artifacts. Throughout optimization, we employ multiple loss terms to capture detailed local style structures and preserve geometric attributes. Users can flexibly control color, scale, and spatial attributes during stylization through customizable loss terms. Once this stylization is done, we can obtain consistent free-viewpoint stylized renderings.
图2:StylizedGS管道。我们首先从多视图输入重建照片级逼真的3DGS ����� 。在此之后,执行与样式图像的颜色匹配,伴随着3DGS滤波器的应用以抢先解决潜在的伪影。在整个优化过程中,我们采用多个损失项来捕获详细的局部样式结构并保留几何属性。用户可以灵活地控制颜色,规模和空间属性在风格化通过可定制的损失条款。一旦完成了这种风格化,我们就可以获得一致的自由视点风格化渲染。
3D Style Transfer. 3D scene style transfer aims to transfer the style to the scene with both style fidelity and multi-view consistency. With the increasing demand for 3D content, neural style transfer has been expanded to various 3D representations. Stylization on meshes often utilizes differential rendering to propagate style transfer objectives from rendered images to 3D meshes, enabling geometric or texture transfer [3, 1, 2]. Other works, using point clouds as the 3D proxy, ensure 3D consistency when stylizing novel views. For instance, [7] employs featurized 3D point clouds modulated with the style image, followed by a 2D CNN renderer to generate stylized renderings. However, explicit methods’ performance is constrained by the quality of geometric reconstructions, often leading to noticeable artifacts in complex real-world scenes.
三维样式转换。三维场景风格转换的目标是在风格逼真度和多视图一致性的基础上将风格转换到场景中。随着对3D内容需求的增加,神经风格转移已经扩展到各种3D表示。网格上的样式化通常利用差分渲染将样式转换目标从渲染图像传播到3D网格,从而实现几何或纹理转换[3,1,2]。其他作品,使用点云作为3D代理,确保3D一致性时,风格新颖的意见。例如,[ 7]采用用样式图像调制的特征化3D点云,然后使用2D CNN渲染器来生成风格化渲染。然而,显式方法的性能受到几何重建质量的限制,经常导致在复杂的真实世界场景中出现明显的伪影。
Therefore implicit methods such as NeRF [39] have gained considerable attention for their enhanced capacity to represent complex scenes. Numerous NeRF-based stylization networks incorporate image style transfer losses [26, 13] during training or are supervised a mutually learned image stylization network [12] to optimize color-related parameters based on a reference style. Approaches like [14, 40] support both appearance and geometric stylization to mimic the reference style, achieving consistent results in novel-view stylization. However, these methods involve time-consuming optimization and exhibit slow rendering due to expensive random sampling in volume rendering. They also lack user-level flexible and accurate perceptual control for stylization.
因此,隐式方法(如NeRF [ 39])因其增强的表示复杂场景的能力而获得了相当大的关注。许多基于NeRF的风格化网络在训练过程中包含图像风格传递损失[26,13],或者由相互学习的图像风格化网络[ 12]监督,以基于参考风格优化颜色相关参数。像[14,40]这样的方法支持外观和几何样式化来模仿参考样式,从而在新视图样式化中实现一致的结果。然而,这些方法涉及耗时的优化,并表现出缓慢的渲染,由于昂贵的随机采样体绘制。它们也缺乏用户级灵活和准确的风格化感知控制。
While controlling perceptual factors, such as color, stroke size, and spatial aspects, has been extensively explored in image domain style transfer [22, 23, 24], the application of perceptual control in 3D stylization has not been well utilized. [41, 42] establish semantic correspondence in transferring style across the entire stylized scene but only limited to spatial control and doesn’t allow users to interactively specify arbitrary regions. ARF-plus [25] introduce more perceptual controllability into the stylization of radiance fields, yet the demand for enhanced flexibility and personalized, diverse characteristics in 3D stylization remains unmet.
虽然控制感知因素,如颜色,笔画大小和空间方面,已被广泛探讨在图像域风格转移[ 22,23,24],感知控制在3D风格化的应用尚未得到很好的利用。[ 41,42]在整个风格化场景中建立语义对应,但仅限于空间控制,不允许用户交互式指定任意区域。ARF-plus [ 25]将更多的感知可控性引入辐射场的风格化,但对3D风格化中增强的灵活性和个性化、多样化特征的需求仍未得到满足。
Our approach achieves rapid stylization within a minute of training, ensuring real-time rendering capabilities. It adeptly captures distinctive details from the style image and preserve recognizable scene content with fidelity. Additionally, we empower users with perceptual control over color, scale, and spatial factors for customized stylization.
我们的方法在一分钟的训练内实现了快速风格化,确保了实时渲染能力。它巧妙地捕捉风格图像的独特细节,并保持可识别的场景内容的保真度。此外,我们还为用户提供对颜色、比例和空间因素的感知控制,以实现定制风格化。
3Method 3方法
Given a 3D scene represented by a collection of captured images with corresponding camera parameters, our objective is to efficiently accomplish consistent style transfer from a 2D style image with arbitrary style to the 3D scene. Building on recent advances in 3D Gaussian Splatting (3DGS) [17], we model the 3D scene with the 3DGS and then optimize the 3DGS representation to generate stylized scenes with intricate artistic features and high visual quality. Our stylization process consists of two key steps: 1) We first recolor the 3D scene to align its color statistics with those of the given style image. Simultaneously, a specific 3D Gaussian filter is applied to minimize the impact of floaters in the reconstruction, which is crucial for the final stylization effect. 2) Then in the optimization phase, we exploit nearest-neighbor feature matching style loss to capture detailed local style patterns. Additionally, we incorporate a depth preservation loss, and some regularization terms to preserve geometric contents. Finally, in Sec. 3.3, we introduce how to achieve flexible control over the color, scale, and spatial attributes in our 3DGS stylization. As a result, users can create stylized renderings with customized artistic expression, and explore the consistently stylized scene in a free-view manner.
给定一个3D场景所表示的采集图像与相应的相机参数,我们的目标是有效地完成一致的风格从2D风格的图像与任意风格的3D场景。基于3D高斯溅射(3DGS)[ 17]的最新进展,我们使用3DGS对3D场景进行建模,然后优化3DGS表示以生成具有复杂艺术特征和高视觉质量的风格化场景。我们的风格化过程包括两个关键步骤:1)我们首先对3D场景重新着色,使其颜色统计与给定风格图像的颜色统计一致。同时,应用特定的3D高斯滤波器来最大限度地减少重建过程中漂浮物的影响,这对最终的风格化效果至关重要。2)然后在优化阶段,我们利用最近邻特征匹配风格损失来捕获详细的局部风格模式。 此外,我们将深度保持损失,和一些正则化条款,以保持几何内容。最后,在第3.3介绍了如何在3DGS风格化中实现对颜色、比例和空间属性的灵活控制。因此,用户可以创建具有自定义艺术表达的风格化渲染,并以自由视图的方式探索一贯风格化的场景。
3.1Preliminaries: 3D Gaussian Splatting
3.1分类:3D高斯溅射
Gaussian Splatting [17] encapsulates 3D scene information using a suite of 3D colored Gaussians. This technique exhibits rapid inference speeds and exceptional reconstruction quality compared to NeRF. To represent the scene, each Gaussian is described by a centroid �={�,�,�}∈ℝ3, a 3D vector �∈ℝ3 for scaling, and a quaternion �∈ℝ4 for rotation. Additionally, an opacity value �∈ℝ and a color vector � represented in the coefficients of a spherical harmonic (SH) function of degree three are used for fast alpha-blending during rendering. These trainable parameters are collectively symbolized by ���, where ���=��,��,��,��,��, representing the parameters for the �-th Gaussian. To visualize the 3D Gaussians and supervise their optimization, 3DGS projects them onto the 2D image plane. The implementation leverages differentiable rendering and gradient-based optimization on each pixel for the involved Gaussians. The pixel color �� is determined by blending the colors �� of those ordered Gaussians that overlap the pixel. This process can be formulated as:
高斯飞溅[ 17]使用一套3D彩色高斯来封装3D场景信息。与NeRF相比,该技术具有快速的推理速度和出色的重建质量。为了表示场景,每个高斯由质心 �={�,�,�}∈ℝ3 、用于缩放的3D矢量 �∈ℝ3 和用于旋转的四元数 �∈ℝ4 来描述。另外,在渲染期间,在三次球谐(SH)函数的系数中表示的不透明度值 �∈ℝ 和颜色向量 � 用于快速阿尔法混合。这些可训练参数共同由 ��� 表示,其中 ���=��,��,��,��,�� 表示第 � 高斯的参数。为了可视化3D高斯模型并监督其优化,3DGS将其投影到2D图像平面上。该实现利用可微渲染和基于梯度的优化每个像素的高斯。 像素颜色 �� 通过混合与像素重叠的那些有序高斯的颜色 �� 来确定。 该过程可以表述为:
| ��=∑�∈������� | (1) |
where �� is the accumulated transmittance and �� is the alpha-compositing weight for the �-th Gaussian.
其中 �� 是累积透射率, �� 是第 � 高斯的α合成权重。
3.2Style Transfer to 3D Gaussian Splatting
3.2样式转换到3D高斯溅射
Given a set of multi-view images ℐ�������, we first obtain the reconstructed 3DGS model ����� to represent the original scene. Our goal is to transform ����� to a stylized 3DGS model ����� which matches the detailed style features of a 2D style image ℐ����� and preserve the content of the original scene.
给定一组多视点图像 ℐ������� ,我们首先获得重建的3DGS模型 ����� 以表示原始场景。我们的目标是将 ����� 转换为风格化的3DGS模型 ����� ,该模型与2D样式图像 ℐ����� 的详细样式特征相匹配,并保留原始场景的内容。
Color Match. To enhance the alignment of hues with the style image and achieve flexible color control in the stylized results, we initially recolor the 3DGS ����� through color transfer from the style image. Drawing inspiration from [22], we employ a linear transformation of colors in RGB space, followed by a color histogram matching procedure between the style images and training views. Let {���} be the set of all pixels in the style image, {���} be the set of all pixels in the content image to be recolored, then we solve the following linear transformation to align the mean and covariance of color distributions between the content image set and the style image:
颜色匹配。为了增强色调与样式图像的对齐并在风格化结果中实现灵活的颜色控制,我们最初通过从样式图像的颜色转移来对3DGS ����� 重新着色。从[ 22]中汲取灵感,我们在RGB空间中采用颜色的线性变换,然后在样式图像和训练视图之间进行颜色直方图匹配过程。假设 {���} 是样式图像中的所有像素的集合, {���} 是要重新着色的内容图像中的所有像素的集合,然后我们求解以下线性变换以对齐内容图像集合和样式图像之间的颜色分布的均值和协方差:
| ����=𝐀��+�,���=𝐀�+� | ||
| �.�.�[����]=�[��],���[����]=���[��] |
where 𝐀∈ℝ3×3 and �∈ℝ3 are the solution to the linear transformation, ���� is the the recolored pixels of the content images. The color parameter � of 3DGS ����� is transformed to the recolored color parameter ���. Please refer to the supplementary document for the mathematical derivation.
其中 𝐀∈ℝ3×3 和 �∈ℝ3 是线性变换的解, ���� 是内容图像的重新着色的像素。将3DGS ����� 的颜色参数 � 变换为重新着色的颜色参数 ��� 。数学推导请参见补充文件。
Consequently, this alignment process ensures that the recolored training images ℐ��������� and the color attributes of 3DGS ���, are consistent with the color palette of the style reference. However, some floaters in the original 3DGS will also be colored during this process, significantly affecting the quality of the stylization, as shown in Fig. 11. These colored floaters often result from Gaussians with excessively large scales or improper opacity values. To address this issue, we propose applying a 3DGS filter to exclude these floaters before the stylization process. After filtering certain 3D Gaussians, we fine-tune ����� to minimize the impact on the overall scene reconstruction quality and enhance color correspondence. During fine-tuning, we incorporate the reconstruction loss from [17]:
因此,该对齐过程确保了重新着色的训练图像 ℐ��������� 和3DGS ��� 的颜色属性与样式参考的调色板一致。然而,原始3DGS中的一些漂浮物也将在此过程中着色,从而显著影响风格化的质量,如图11所示。这些彩色飞蚊症往往是由于高斯与过大的规模或不适当的不透明度值。为了解决这个问题,我们建议在风格化过程之前应用3DGS过滤器来排除这些漂浮物。在过滤某些3D高斯后,我们微调 ����� 以最大限度地减少对整体场景重建质量的影响并增强颜色对应性。在微调过程中,我们结合了来自[ 17]的重建损失:
| ℒ���=(1−����)ℒ1(ℐ���������,ℐ������)+����ℒ�−���� | (2) |
Stylization. After matching the color and filtering possible artifacts from 3DGS reconstruction, an intuitive and effective strategy for 3D scene stylization is to leverage features extracted by a pre-trained convolutional neural network (e.g., VGG [28]) and calculate a set of loss functions between training views and the style image. To transfer detailed high-frequency style features from a 2D style image to a 3D scene, we exploit the nearest neighbor feature matching concept inspired by [13, 43], where we minimize the cosine distance between the feature map of rendered images and its nearest neighbor in the style feature map. As illustrated in Fig. 2, we extract the VGG feature maps ������, ��������, and ������� for ℐ�����, ℐ���������, and the rendered images ℐ������, respectively. The nearest neighbor feature match loss is formulated as:
风格化。在匹配颜色并从3DGS重建中过滤可能的伪影之后,用于3D场景风格化的直观且有效的策略是利用由预训练的卷积神经网络(例如,VGG [ 28])并计算训练视图和样式图像之间的一组损失函数。为了将详细的高频样式特征从2D样式图像转移到3D场景,我们利用了受[13,43]启发的最近邻特征匹配概念,其中我们最小化渲染图像的特征图与样式特征图中的最近邻之间的余弦距离。如图2所示,我们分别为 ℐ����� 、 ℐ��������� 和渲染图像 ℐ������ 提取VGG特征图 ������ 、 �������� 和 ������� 。最近邻特征匹配损失被公式化为:
| ℒ�����(�������,������)=1�∑�,���(�������(�,�),������(�*,�*)) | (3) | ||
| where, (�*,�*)=argmin�′,�′�(�������(�,�),������(�′,�′)) | (4) |
Here, �(�,�) is the cosine distance between two feature vectors � and �. To preserve the original content structure during the stylization, we additionally minimize the mean squared distance between the content feature �������� and the stylized feature �������:
这里, �(�,�) 是两个特征向量 � 和 � 之间的余弦距离。为了在风格化过程中保留原始内容结构,我们还最小化了内容特征 �������� 和风格化特征 ������� 之间的均方距离:
| ℒ�������=1�×�‖��������−�������‖2 | (5) |
where � and � represent the size of rendered images. While the content loss ℒ������� mitigates the risk of excessive stylization, optimizations applied to 3DGS geometric parameters can still induce changes in scene geometry. To address this, we introduce a depth preservation loss to maintain general geometric consistency without relying on an additional depth estimator. Therefore, there exists a trade-off between geometric optimization and depth preservation loss, enabling our stylization to effectively transfer style patterns while mitigating substantial detriment to geometric content. Specifically, in the color match stage, we initially generate the original depth map ������� by employing the alpha-blending method of 3DGS. The alpha-blended depth �� of each pixel is calculated as follows:
其中 � 和 � 表示渲染图像的大小。虽然内容丢失 ℒ������� 减轻了过度风格化的风险,但应用于3DGS几何参数的优化仍可能引起场景几何的变化。为了解决这个问题,我们引入了一个深度保持损失,以保持一般的几何一致性,而不依赖于一个额外的深度估计。因此,在几何优化和深度保留损失之间存在权衡,使我们的风格化能够有效地转移样式模式,同时减轻对几何内容的实质性损害。具体而言,在颜色匹配阶段,我们首先通过采用3DGS的阿尔法混合方法来生成原始深度图 ������� 。每个像素的阿尔法混合深度 �� 计算如下:
| ��=∑������� | (6) |
where �� is the depth value for �-th Gaussian. During the stylization, we minimize the �2 loss between the rendered depth map ������� and the original one �������:
其中 �� 是第#1阶高斯的深度值。在风格化过程中,我们最小化渲染深度图 ������� 和原始深度图 ������� 之间的 �2 损失:
| ℒ����ℎ=1�×�‖�������−�������‖2 | (7) |
We also add some regularization terms that perform on the changes of scale � and opacity � value in �����:
我们还添加了一些正则化项,用于对 ����� 中的scale Δ� 和opacity Δ� 值的变化进行处理:
| ℒ�����=1�‖Δ�‖,ℒ�����=1�‖Δ�‖ | (8) |
Finally, a total variation loss ℒ�� is used to smooth the rendered images in the 2D domain. The total loss during the stylization phase is:
最后,使用总变化损失 ℒ�� 来平滑2D域中的渲染图像。风格化阶段的总损失为:
| ℒ=����ℒ�����+����ℒ�������+����ℒ����ℎ | (9) | ||
| +����ℒ�����+����ℒ�����+���ℒ�� |
where �* is the corresponding loss weight.
其中 �* 是相应的失重。

Figure 3:Color control Results. Our approach facilitates versatile color management in stylized outputs, allowing users to either retain the scene’s original hues or apply distinct color schemes from alternative style images. Users have the autonomy to transfer the entire style, the pattern style only, or mixed arbitrary pattern and color styles.
图三:色彩控制结果:我们的方法有助于风格化输出中的多功能色彩管理,允许用户保留场景的原始色调或应用与替代风格图像不同的配色方案。用户可以自主地调用整个样式、只调用图案样式、或混合任意图案和颜色样式。
3.3Perceptual Control 3.3感知控制
With the previous components of our approach, we can achieve both rapid and detailed style transfer while preserving the original content. Here, we attempt to address the challenge users encounter in customizing the stylization process. Drawing inspiration from [22], we propose a series of strategies and loss functions for 3DGS stylization to control various perceptual factors, including color, scale, and spatial areas, aiming to enhance the customization capability of our approach.
使用我们方法的前面的组件,我们可以在保留原始内容的同时实现快速和详细的样式转换。在这里,我们试图解决用户在定制风格化过程中遇到的挑战。从[ 22]中汲取灵感,我们提出了一系列用于3DGS风格化的策略和损失函数,以控制各种感知因素,包括颜色,比例和空间区域,旨在增强我们方法的定制能力。
Color Control. The color information within an image is a crucial perceptual aspect of its style. Unlike other stylistic elements such as brush strokes or dominant geometric shapes, color is largely independent and stands out as a distinct characteristic. As illustrated in Fig. 3, users may seek to preserve the original color scheme by only transferring the pattern style, or combine the pattern style of one style image with the color style of another. Consequently, our method provides users with independent control over color style during the stylization process. To achieve this, in our color transfer step, we can pre-color 3D scenes to align with any user-desired hues. Similar to the luminance-only algorithm proposed in [44], we then utilize the YIQ color space to separate the learning of luminance and color information. As shown in the definition of color style loss ℒ���������� in Eq. 10, we extract the luminance channel in the rendered view ℐ������� and the style image ℐ������ for the luminance-only style loss ��������� calculation. Meanwhile, the RGB channels are retained for the content loss ℒ������� calculation.
颜色控制。图像中的颜色信息是其风格的重要感知方面。与其他风格元素,如笔触或占主导地位的几何形状不同,颜色在很大程度上是独立的,并作为一个独特的特征脱颖而出。如图3所示,用户可以通过仅转移图案风格或将一个风格图像的图案风格与另一个风格图像的颜色风格联合收割机组合来寻求保留原始配色方案。因此,我们的方法为用户提供了独立的控制风格化过程中的颜色风格。为了实现这一点,在我们的颜色转移步骤中,我们可以对3D场景进行预着色,以与任何用户想要的色调对齐。与[ 44]中提出的仅亮度算法类似,然后我们利用YIQ颜色空间来分离亮度和颜色信息的学习。如等式10中的颜色风格损失 ℒ���������� 的定义所示, 在图10中,我们提取渲染视图 ℐ������� 和样式图像 ℐ������ 中的亮度通道用于仅亮度样式损失 ��������� 计算。同时,RGB通道被保留用于内容损失 ℒ������� 计算。
| ℒ����������=ℒ�����(�(ℐ�������),�(ℐ������)) | (10) |
Figure 4:Scale Control Results. Our method supports users to flexibly control the scale of the basic style elements, such as increasing or decreasing the density of Lego blocks in the example of last row.
图四:缩放控制结果。我们的方法支持用户灵活地控制基本样式元素的缩放,例如增加或减少最后一行示例中乐高积木的密度。
Scale Control. The style scale, such as the thickness of brushstrokes or the density of the basic grains (as depicted in Fig. 4), is a foundational style element and plays a vital role in defining visual aesthetics. The stroke size, as a typical example of the style scale, is influenced by two factors: the receptive field of the convolution in the VGG network and the size of the style image input to the VGG network, as identified by [23]. Our exploration reveals that simply adjusting the receptive field is efficient for achieving scale-controllable stylization in 3DGS. We modulate the size of the receptive field by manipulating the selection of layers in the VGG network and adjusting the weights for each layer during the computation of the scale style loss ℒ����������. As shown in Eq. 11, the style losses from different layer blocks are amalgamated to form ℒ����������.
比例控制。风格尺度,如笔触的粗细或基本纹理的密度(如图4所示),是基本的风格元素,在定义视觉美学方面起着至关重要的作用。作为风格尺度的典型示例,笔画大小受两个因素的影响:VGG网络中卷积的感受野和输入到VGG网络的风格图像的大小,如[ 23]所述。我们的探索表明,简单地调整感受野是有效的实现规模可控的风格化在3DGS。我们通过操纵VGG网络中的层的选择并在尺度风格损失 ℒ���������� 的计算期间调整每个层的权重来调节感受野的大小。如Eq. 11,来自不同层块的样式损失被合并以形成 ℒ���������� 。
| ℒ����������=∑�∈����⋅ℒ�����(��(ℐ������),��(ℐ�����)) | (11) |
Here, �� represents the feature map at the �-th layer within the �-th VGG-16 block ��, and �� controls the corresponding weights at the �-th layer.
这里, �� 表示第 � 个VGG-16块 �� 内的第 � 层处的特征图,并且 �� 控制第 � 层处的对应权重。

Figure 5:Spatial Control Results. By specifying regions in a single view and the corresponding style images for different regions, users can transfer different styles to desired regions within a scene. The users can specify some points (in blue) to generate region masks (in black).
图5:空间控制结果。通过在单个视图中指定区域以及针对不同区域的对应样式图像,用户可以将不同样式传递到场景内的期望区域。用户可以指定一些点(蓝色)来生成区域遮罩(黑色)。
Spatial Control. Traditional 3D style transfer methods typically apply a single style uniformly across the entire scene, resulting in the same stylization across the composition. However, there are scenarios where it becomes necessary to transfer distinct styles to different areas or objects. Users may also want to specify region-to-region constraints for their preferred style distribution within a scene, as illustrated in Fig. 5. Users only need to specify some points in the desired region of a single view and then our method utilizes SAM [45] to extract masks with those specified points to ease the interaction burden. Similarly, users can also specify certain areas in the style image to delineate style regions for partial style transfer. Additionally, we introduce a mask-tracking strategy that dynamically adjusts the position of input points based on area thresholds, ensuring the consistent generation of masks across various training views. More details can be found in the supplementary document.
空间控制。传统的3D样式转换方法通常在整个场景中统一应用单个样式,从而在整个合成中实现相同的样式化。但是,在某些情况下,需要将不同的样式传递到不同的区域或对象。用户还可能想要为他们在场景内的偏好样式分布指定区域到区域约束,如图5所示。用户只需要在单个视图的期望区域中指定一些点,然后我们的方法利用SAM [ 45]来提取具有这些指定点的掩码以减轻交互负担。同样,用户也可以指定样式图像中的某些区域来描绘用于部分样式传输的样式区域。此外,我们还引入了一种掩码跟踪策略,该策略根据面积阈值动态调整输入点的位置,确保在各种训练视图中一致地生成掩码。 更多细节可以在补充文件中找到。
To provide spatial guidance during the stylization process, we introduce a spatial style loss, denoted as ℒ������������. Assuming the user specifies � regions in a single view of a scene to be matched with � style regions, our ℒ������������ is formulated as follows:
为了在风格化过程中提供空间指导,我们引入了空间风格损失,表示为 ℒ������������ 。假设用户指定场景的单个视图中的 � 区域与 � 样式区域匹配,我们的 ℒ������������ 公式化如下:
| ℒ������������=∑���⋅ℒ�����(���(���∘ℐ������),���(���∘ℐ������)) | (12) |
Here, ��� and ��� represent the binary spatial masks on the rendered views and the �-th style image, respectively. Additionally, during the color match step, we transform the color information in the region of the style image to the corresponding masked area of the content image to improve color correspondence.
这里, ��� 和 ��� 分别表示渲染视图和第 � 样式图像上的二进制空间掩模。此外,在颜色匹配步骤中,我们将样式图像区域中的颜色信息转换到内容图像的对应掩蔽区域,以提高颜色对应性。

Figure 6:Sequential control results. Given multiple control conditions, we can achieve a sequence of controllable stylization. We first show a stylization result and then, from left to right, progressively implement controls that preserve the color of the original scene, increase the scale of the pattern style, and adopt spatial control to apply two styles.
图6:顺序控制结果。给定多个控制条件,我们可以实现一系列可控的风格化。我们首先显示一个样式化结果,然后从左到右,逐步实现保留原始场景颜色的控件,增加图案样式的比例,并采用空间控件来应用两种样式。

Figure 7:Qualitative comparisons with the baseline methods on LLFF and T&T datasets. It can be seen that our method has better results which faithfully capture both the color styles and pattern styles across different views.
图7:在LLFF和T&T数据集上与基线方法进行了定性比较。可以看出,我们的方法具有更好的结果,可以忠实地捕获不同视图的颜色风格和模式风格。

Figure 8:Qualitative comparisons with baselines on LLFF dataset. Compared to other methods, our method excels in learning intricate and accurate geometric patterns while effectively preserving the semantic content of the original scene.
图8:LLFF数据集与基线的定性比较。与其他方法相比,我们的方法擅长学习复杂和准确的几何图案,同时有效地保留原始场景的语义内容。
4Experiments 4个实验
Datasets. We conduct extensive experiments on multiple real-world scenes from LLFF [46] which contains forward-facing scenes and Tanks & Temples (T&T) dataset [47] which includes unbounded 360∘ large outdoor scenes. The scene data is also employed to train photo-realistic 3DGS representation before stylization with official configuration. Furthermore, our experiments involve a diverse set of style images from [13], allowing us to assess our method’s capability to handle a wide range of stylistic exemplars.
数据集。我们对LLFF [ 46]中的多个真实世界场景进行了广泛的实验,其中包含面向前方的场景和Tanks & Temples(T&T)数据集[ 47],其中包括无限的360 ∘ 大型户外场景。场景数据也被用来训练真实感的3DGS表示之前,风格化与官方配置。此外,我们的实验涉及[ 13]中的一组不同的风格图像,使我们能够评估我们的方法处理各种风格样本的能力。
Baseline. We compare our method with the state-of-the-art 3D stylization methods, ARF [13], Stylescene [7], StyleRF [48] and Ref-NPR [42] based on different 3D representations. Specifically, Stylescene [7] adopts point clouds featured by VGG features averaged across views as a scene representation and transforms the point-wise features by modulating them with the encoding vector of a style image for stylization. ARF [13] is a NeRF-based approach that performs nearest neighbor feature matching on VGG feature maps along with deferred back propagation to memorize efficiently optimized parameters. StyleRF [48] implements style transfer within the feature space of radiance fields in a zero-shot manner. Ref-NPR [42] facilitates controllable scene stylization utilizing radiance fields to stylize a 3D scene, with a single stylized 2D view taken as reference. For all methods, we use their released code and pre-trained models. As Ref-NPR is a reference-based method, we use AdaIN [49] to obtain a stylized reference view according to its paper.
基线。我们将我们的方法与基于不同3D表示的最先进的3D风格化方法ARF [ 13],Stylescene [ 7],StyleRF [ 48]和Ref-NPR [ 42]进行了比较。具体而言,Stylescene [ 7]采用由跨视图平均的VGG特征所表征的点云作为场景表示,并通过使用样式图像的编码向量对其进行调制来转换逐点特征以进行样式化。ARF [ 13]是一种基于NeRF的方法,它在VGG特征图上执行最近邻特征匹配,沿着延迟反向传播以有效地记住优化的参数。StyleRF [ 48]以零拍摄方式在辐射场的特征空间内实现风格转移。Ref-NPR [ 42]促进了可控场景风格化,利用辐射场对3D场景进行风格化,其中单个风格化的2D视图作为参考。对于所有方法,我们使用他们发布的代码和预训练的模型。 由于Ref-NPR是一种基于参考的方法,我们使用AdaIN [ 49]根据其论文获得风格化的参考视图。
Implementation Details. We implement StylizedGS based on 3DGS representation [17]. In the color match step, we fix the density component of the initial 3DGS and optimize it using ℒ��� for 200 iterations. During the stylization process, we fine-tune all parameters of ����� over 800 iterations, while disabling adaptive density control of 3DGS. We adopt a pretrained VGG-16 network [28] to extract feature maps �������, ������, and �������� used in Eq. 3. The network consists of 5 convolution blocks and we use the ‘conv2’ and ‘conv3’ blocks as the feature extractors empirically.
实施细节。我们基于3DGS表示实现StylizedGS [ 17]。在颜色匹配步骤中,我们固定初始3DGS的密度分量,并使用 ℒ��� 进行200次迭代优化。在风格化过程中,我们在800次迭代中微调 ����� 的所有参数,同时禁用3DGS的自适应密度控制。我们采用预训练的VGG-16网络[ 28]来提取等式中使用的特征图 ������� , ������ 和 �������� 。3.该网络由5个卷积块组成,我们根据经验使用'conv 2'和'conv 3'块作为特征提取器。
The loss weights (����,����,����,����,����,���) are respectively set to (0.2,2,0.005,0.05,0.05,0.02). The depth preservation loss weight ���� is set to 0.01 for all forward-facing captures and 0.05 for all 360∘ captures. At each stylization training iteration, we render an image from a sampled view different from all the training views to compute losses. The Adam optimizer [50] is adopted with a learning rate exponentially decayed from 1�−1 to 1�−2.
将损失权重 (����,����,����,����,����,���) 分别设置为 (0.2,2,0.005,0.05,0.05,0.02) 。对于所有前向捕获,深度保持损失权重 ���� 被设置为 0.01 ,对于所有360 ∘ 捕获,深度保持损失权重 0.05 被设置为 0.05 。在每次风格化训练迭代中,我们从与所有训练视图不同的采样视图中渲染图像以计算损失。采用Adam优化器[ 50],学习率从 1�−1 到 1�−2 呈指数衰减。
4.1Qualitative Comparisons
4.1定性比较
We show visual comparisons with Stylescene and ARF methods in Fig. 7. We can see that our method exhibits a better style match to the style image compared to the others. For instance, Stylescene tends to generate over-smoothed results and lacks intricate structures in the Truck scene, while ARF struggles with propagating the style consistently across the entire scene and exhibits deficiencies in color correspondence. In contrast, our method faithfully captures both the color tones and brushstrokes of “The Scream” throughout the entire scene, demonstrating a superior style matching compared to the baselines.
我们在图7中显示了与Stylescene和ARF方法的视觉比较。我们可以看到,我们的方法表现出更好的风格匹配的风格图像相比,其他。例如,Stylescene倾向于生成过度平滑的结果,并且在卡车场景中缺乏复杂的结构,而ARF则难以在整个场景中一致地传播风格,并且在颜色对应方面表现出不足。相比之下,我们的方法忠实地捕捉整个场景的色调和笔触的“尖叫”,展示了一个上级风格匹配相比,基线。
Fig. 8 presents additional comparison results between ARF, StyleRF, Ref-NPR, and our method on LLFF datasets. By jointly optimizing the density and color components, our method excels in learning intricate geometric patterns and meso-structure. Specifically, in the orchids scene with a Lego style, other methods captures only the color style or a basic square pattern, whereas our approach successfully illustrates the detailed structure of Lego blocks, clearly showing even the small cylindrical patterns. This is also evident in the horns scene featuring a snow style, where our method produces more visually pleasant results that faithfully match the style of the hexagonal snowflake structure. Our method also preserves more semantic information in the stylized scene as we utilize the depth map to keep the spatial distribution in an image.
图8显示了ARF、StyleRF、Ref-NPR和我们的方法在LLFF数据集上的其他比较结果。通过联合优化密度和颜色分量,我们的方法在学习复杂的几何图案和介观结构方面表现出色。具体来说,在具有乐高风格的兰花场景中,其他方法仅捕获颜色风格或基本方形图案,而我们的方法成功地说明了乐高积木的详细结构,甚至清楚地显示了小圆柱形图案。这在具有雪风格的喇叭场景中也很明显,其中我们的方法产生更视觉上令人愉快的结果,忠实地匹配六边形雪花结构的风格。我们的方法还保留了更多的语义信息,在风格化的场景,因为我们利用深度图,以保持在图像中的空间分布。
TABLE I:Quantitative comparisons on stylization under novel views. We report ArtFID, SSIM, average training time (Avg. train), and average rendering FPS (Avg. FPS) for our method and other baselines. ‘-’ denotes StyleRF does not require individual stylization training.
表一:小说视角下风格化的定量比较。我们报告了ArtFID,SSIM,平均培训时间(Avg.训练)和平均渲染FPS(Avg. FPS)用于我们的方法和其他基线。'-'表示StyleRF不需要单独的风格化培训。
| Metrics 度量 | ArtFID(↓) ArtFID( ↓ ) | SSIM(↑) SSIM( ↑ ) | Avg. train(↓) Avg.列车( ↓ ) | Avg. FPS(↑) Avg. FPS( ↑ ) |
| Stylescene 花柱 | 52.75 | 0.13 | 6.37 min | 0.71 |
| StyleRF | 40.61 | 0.41 | - | 5.8 |
| ARF | 35.73 | 0.29 | 1.78 min | 8.2 |
| Ref-NPR 参考NPR | 33.56 | 0.31 | 2.31 min | 7.3 |
| Ours 我们 | 28.29 | 0.55 | 0.87 min | 153 |
4.2Quantitative Comparisons
4.2定量比较
Another significant advantage of the 3DGS representation is that it can produce high-quality renderings in real time and greatly reduce training time. Therefore, we conducted quantitative comparisons with other methods to demonstrate both the high fidelity and efficiency of our approach. As the optimization time during the stylization process is notably influenced by the resolution, we randomly selected 50 stylized scenes with consistent resolution from the LLFF dataset and evaluated the average times. For the stylization metrics, we choose ArtFID [51] to measure the quality of stylization following [52] and SSIM (Structural Similarity Index Measure) between the content and stylized images to measure the performance of detail preservation following [33]. As shown in Tab. I, our method excels in both stylized visual quality and content preservation. Regarding efficiency, our method has significant advantages in average rendering FPS (Avg. FPS) and can achieve real-time free-view synthesis. At the same time, it also outperforms other optimization-based stylization methods in terms of average training time (Avg. train) for stylization and can achieve per scene stylization within 1 minute on a single NVIDIA RTX 4090 GPU. Note that StyleRF is a zero-shot method and does not require individual stylization training for each case, but its rendering efficiency is worse and cannot be viewed in real time.
3DGS表示的另一个显著优点是它可以在真实的时间内生成高质量的渲染,并大大减少训练时间。因此,我们与其他方法进行了定量比较,以证明我们的方法的高保真度和效率。由于风格化过程中的优化时间受到分辨率的显著影响,我们从LLFF数据集中随机选择了50个分辨率一致的风格化场景,并评估了平均时间。对于风格化指标,我们选择ArtFID [ 51]来衡量风格化的质量[ 52]和内容和风格化图像之间的SSIM(结构相似性指数度量)来衡量细节保留的性能[ 33]。如Tab中所示。,我们的方法在风格化的视觉质量和内容保存方面都很出色。在效率方面,我们的方法在平均渲染FPS(Avg. FPS),并能实现实时自由视点合成。同时,它在平均训练时间(Avg. train)进行风格化处理,并可在单个NVIDIA RTX 4090 GPU上在1分钟内完成每个场景的风格化处理。需要注意的是,StyleRF是一种zero-shot方法,不需要针对每种情况进行单独的风格化训练,但其渲染效率较差,无法真实的实时查看。
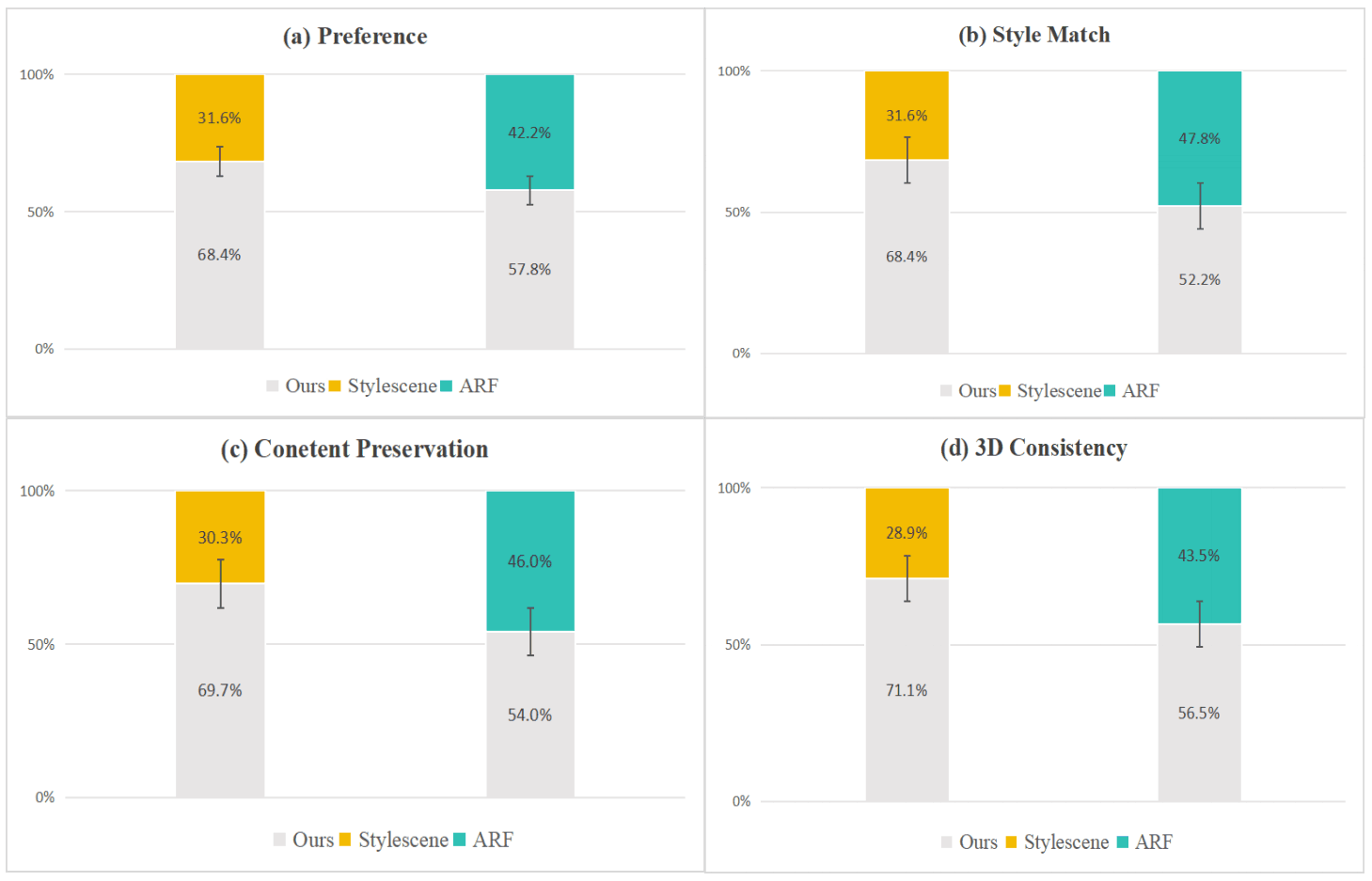
Figure 9:User Study. We record the user preference in the form of a boxplot. Our results obtain more preferences in visual preference, style match level, content preservation level, and 3D consistency quality than other state-of-the-art stylization methods.
图9:用户研究。我们以箱形图的形式记录用户偏好。我们的结果获得更多的偏好,在视觉偏好,风格匹配水平,内容保存水平,和3D一致性质量比其他国家的最先进的风格化方法。
User Study We also perform a user study among our method and other comparison methods. We randomly chose 20 sets of stylized views of the 3D scenes from both the LLFF and T&T datasets processed by different methods and invited 25 participants (including 15 males and 10 females, aged from 18 to 50). Our questionnaire was thoughtfully designed to encompass diverse participants across various professions and age groups, minimizing the risk of echo chamber effects. Participants were granted ample time for unbiased evaluation, ensuring a comprehensive and fair assessment. First, we presented the participants with a style image, the original scene, as well as two stylized videos generated by our method and a random comparison method. Then we asked the participants to vote on the video based on four evaluation indicators: visual preference, style match level, content preservation level, and 3D consistency quality. We collected 1000 votes for all evaluating indicators and presented the result in Fig. 9 in the form of boxplot. Our method, StylizedGS, outperforms those of other methods across all evaluation indicators, resulting in visually preferable and consistent results. A p-value of 0.005 indicates the statistical significance of the obtained results.
用户研究我们还对我们的方法和其他比较方法进行了用户研究。我们从LLFF和T&T数据集中随机选择了20组经过不同方法处理的3D场景的风格化视图,邀请了25名参与者(包括15名男性和10名女性,年龄从18岁到50岁)。我们的调查问卷经过精心设计,涵盖了不同职业和年龄组的不同参与者,最大限度地降低了回声室效应的风险。与会者有充分的时间进行公正的评价,以确保全面和公平的评估。首先,我们向参与者展示了一个风格图像,原始场景,以及通过我们的方法和随机比较方法生成的两个风格化视频。然后,我们要求参与者根据四个评估指标对视频进行投票:视觉偏好,风格匹配水平,内容保留水平和3D一致性质量。 我们收集了所有评价指标的1000张选票,并以箱形图的形式将结果呈现在图9中。我们的方法StylizedGS在所有评估指标上都优于其他方法,从而获得视觉上更好和一致的结果。p值0.005表示所得结果具有统计学显著性。

Figure 10:Ablation Study about density and color control. ‘w/o density’ presents the stylized scene without density component fine-tuning in 3DGS. ‘w/o recolor’ displays the stylized results without applying recoloring while ‘w/o depth’ shows the results without incorporating depth loss, leading to the disappearance of original geometry and semantic content.
图10:关于密度和颜色控制的消融研究。“w/o density”表示3DGS中没有密度分量微调的风格化场景。“w/o recolor”显示风格化的结果而不应用着色,而“w/o depth”显示结果而不结合深度损失,导致原始几何和语义内容的消失。

Figure 11:Ablation study about 3D Gaussian filter. The filter effectively helps eliminate artifacts.
图11:关于3D高斯滤波器的消融研究。滤波器有效地帮助消除伪影。
4.3Controllable Stylization Results
4.3可控的风格化结果
Our method enables users to control stylization in three ways, including color, scale, and spatial region. The corresponding controllable stylization results are shown in Figs. 3, 4 and 5, respectively. Fig. 6 further demonstrates our method’s sequential control capability, enabling precise and flexible adjustments across different conceptual factors. In addition to the direct stylization result, we apply different controls sequentially from left to right: preserving the color of the original scene, increasing the scale of the pattern style, and adopting spatial control to apply two styles. This flexibility allows for refined modifications of key parameters or stylistic attributes, tailored to specific aesthetic preferences or artistic requirements. This empowers users to achieve finely tailored adjustments, fostering enhanced artistic expression and creative exploration.
我们的方法使用户能够控制风格化的三种方式,包括颜色,规模和空间区域。相应的可控风格化结果示于图1A和1B中。分别为3、4和5。图6进一步展示了我们的方法的顺序控制能力,能够在不同的概念因素之间进行精确和灵活的调整。除了直接的样式化结果,我们从左到右依次应用不同的控制:保留原始场景的颜色,增加图案样式的比例,并采用空间控制来应用两种样式。这种灵活性允许根据特定的审美偏好或艺术要求对关键参数或风格属性进行精细修改。这使用户能够实现精心定制的调整,促进增强的艺术表现力和创造性探索。
TABLE II:Quantitative ablation study results. We report ArtFID and SSIM for our method and other ablation studies over 50 randomly chosen stylized cases.
表II:定量消融研究结果。我们报告了ArtFID和SSIM的方法和其他消融研究超过50个随机选择的程式化病例。
| Metrics 度量 | w/o recolor 无重新着色 | w/o density w/o密度 | w/o depth 无深度 | w/o GS filter 无GS滤波器 | Ours 我们 |
| ArtFID (↓) ArtFID( ↓ ) | 31.57 | 38.54 | 31.20 | 30.02 | 28.29 |
| SSIM (↑) SSIM( ↑ ) | 0.54 | 0.53 | 0.35 | 0.39 | 0.55 |
4.4Ablation Study 4.4消融研究
We perform ablation studies to validate our design choices. The original scene and input style image are presented in Fig. 10 (a). Without applying the recoloring procedure, the stylized scene in (b) shows inferior color correspondence with the style image. In Fig. 10 (d)(e), we illustrate the importance of our depth preservation loss in preserving the original scene’s geometry. Without applying depth loss, the background of the Horse scene disappears, and the Trex’s skeleton becomes blurrier. The heatmap in the top left corner depicts the difference between the rendered depth maps and ground truth depth maps. The significant disparities in the heatmap of (d) also underscore the effectiveness of our depth preservation loss. In Fig. 10 (c), we highlight the importance of fine-tuning both the color and density components in 3DGS, which is crucial for learning intricate style patterns. Neglecting the optimization of the density makes it challenging to capture stroke details in the sketch and shape patterns in the texture style. Therefore, a delicate equilibrium is established wherein fine-tuning the density component harmonizes with the depth preservation loss, thereby facilitating the transfer of intricate style details while safeguarding the integrity of the original geometry. The quantitative results of ablation studies are presented in Tab. II which also validate the significant impact of each component on the performance of our proposed method.
我们进行消融研究以验证我们的设计选择。原始场景和输入样式图像在图10(a)中呈现。在不应用该修饰过程的情况下,(B)中的风格化场景显示出与风格图像的较差的颜色对应。在图10(d)(e)中,我们说明了我们的深度保持损失在保持原始场景的几何结构中的重要性。如果不应用深度损失,马场景的背景将消失,Trex的骨架将变得更加模糊。左上角的热图描绘了渲染深度图和地面实况深度图之间的差异。(d)热图中的显著差异也强调了我们深度保存损失的有效性。在图10(c)中,我们强调了在3DGS中微调颜色和密度分量的重要性,这对于学习复杂的样式模式至关重要。 忽略密度的优化使得在草图中捕获笔划细节和在纹理样式中捕获形状图案变得具有挑战性。因此,建立了一种微妙的平衡,其中微调密度分量与深度保持损失相协调,从而促进了复杂风格细节的转移,同时保护了原始几何形状的完整性。消融研究的定量结果见表1。这也验证了每个组件对我们提出的方法的性能的显着影响。
Additionally, we explore the impact of the 3DGS filter, addressing potential floaters in the reconstructed scenes. The floaters become more noticeable after the style transfer process. To mitigate this, we introduce a pre-filtering process. Specifically, we filter out 3D Gaussians with opacity below a certain threshold before we perform the style transfer fine-tuning process. Without the pre-filtering process, the empty space will be given textures. Fig. 11 shows the comparisons and we highlight some noticeable local areas with red bounding boxes. The first row presents results without pre-filtering, where the stone’s and leaves’ textures extend into the air around the objects. In the second row, after pre-filtering and training, the scene exhibits enhanced clarity, with fewer visible colored floaters. Tab. II shows the quantitative results of the ablation studies which demonstrate that all components contribute to our proposed method.
此外,我们探讨了3DGS过滤器的影响,解决了重建场景中潜在的漂浮物。在风格转换过程后,飞蚊症变得更加明显。为了减轻这种情况,我们引入了预过滤过程。具体来说,我们过滤掉不透明度低于某个阈值的3D高斯模型,然后再执行样式转换微调过程。如果没有预过滤过程,空的空间将被赋予纹理。图11显示了比较,我们用红色边界框突出显示了一些明显的局部区域。第一行显示没有预过滤的结果,其中石头和树叶的纹理延伸到对象周围的空气中。在第二行中,经过预过滤和训练后,场景显示出增强的清晰度,可见的彩色漂浮物更少。选项卡. II示出了消融研究的定量结果,其证明了所有组件都有助于我们提出的方法。
5Discussion and Conclusion
5讨论与结论
Limitations. Although our method achieves efficient and controllable 3DGS stylization, it still has some limitations. First, the geometric artifacts from the original 3DGS reconstruction may impact the quality of the final stylized scenes. Although our 3DGS filter can eliminate some floaters, it cannot eliminate all geometric artifacts. This can rely on some improved 3DGS reconstruction methods that add geometric constraints, such as SuGaR [53]. Another point is that our optimization-based method cannot achieve instant stylization. However, this does not compromise our method’s stylization effect and practical application as the optimization time is controlled at about 1 minute.
局限性。虽然我们的方法实现了高效和可控的3DGS风格化,它仍然有一些局限性。首先,来自原始3DGS重建的几何伪影可能影响最终风格化场景的质量。虽然我们的3DGS过滤器可以消除一些浮动,它不能消除所有的几何文物。这可以依赖于一些添加几何约束的改进的3DGS重建方法,例如SuGaR [ 53]。另一点是,我们基于优化的方法不能实现即时风格化。然而,这并不影响我们的方法的风格化效果和实际应用,因为优化时间控制在1分钟左右。
In this paper, we propose StylizedGS, the first controllable 3D scene stylization method based on 3D Gaussian Splatting representation. After the 3DGS reconstruction, the proposed GS filter minimizes the impact of floaters in the reconstruction, which is crucial for the final stylization effect. Then we propose to adopt the nearest-neighbor feature matching style loss to optimize both geometry and color parameters of 3D Gaussians to capture the detailed style feature and facilitate the stylization of the 3D scene. We further introduce a depth preservation loss for regularization to preserve the overall structure during the stylization. Moreover, we design controllable ways for three perceptual factors: color, stylization scale, and spatial regions, so our method supports specific and diverse user control. Qualitative and quantitative experiments demonstrate that our method outperforms existing 3D stylization methods in terms of effectiveness and efficiency.
在本文中,我们提出了StylizedGS,第一个可控的三维场景风格化方法的基础上的三维高斯飞溅表示。在3DGS重建后,所提出的GS滤波器最大限度地减少了重建中漂浮物的影响,这对最终的风格化效果至关重要。然后,我们提出了采用最近邻特征匹配风格损失来优化三维高斯的几何和颜色参数,以捕获详细的风格特征,促进三维场景的风格化。我们进一步引入了深度保持损失的正则化,以保持整体结构在风格化。此外,我们设计了三个感知因素的可控方式:颜色,风格化规模,和空间区域,所以我们的方法支持特定的和多样化的用户控制。定性和定量的实验表明,我们的方法优于现有的3D风格化方法的有效性和效率。