ABSTRACT
尽管 Transformer 在自然语言处理和计算机视觉方面取得了巨大成功,但由于两个重要原因,它很难推广到中大规模图数据:(i) 复杂性高。 (ii) 未能捕获复杂且纠缠的结构信息。在图表示学习中,图神经网络(GNN)可以融合图结构和节点属性,但感受野有限。因此,我们质疑是否可以将 Transformer 和 GNN 结合起来,互相帮助?在本文中,我们提出了一种名为 TransGNN 的新模型,其中 Transformer 层和 GNN 层交替使用以相互改进。具体来说,为了扩大感受野并解开边缘的信息聚合,我们建议使用 Transformer 聚合更多相关节点的信息,以改善 GNN 的消息传递。此外,为了捕获图结构信息,我们利用位置编码并利用GNN层将结构融合为节点属性,从而改进了图数据中的Transformer。我们还建议对 Transformer 最相关的节点进行采样,并提出两种有效的样本更新策略以降低复杂性。最后,我们从理论上证明 TransGNN 仅在具有额外的线性复杂度的情况下才比 GNN 更具表现力。在八个数据集上的实验证实了 TransGNN 在节点和图分类任务上的有效性。
关键词 图数据、图神经网络、Transformer
背景
近年来,Transformer在自然语言处理(NLP)和计算机视觉(CV)领域取得了巨大成功。它被公认为最强大的神经网络,并取代了卷积神经网络和循环神经网络,成为语言理解、机器翻译和图像分割等许多任务中新的事实上的标准。尽管 Transformer 在序列数据上已经被证明是成功的,但它还没有很好地推广到图上。图数据在我们的生活中也非常重要,它可以描述实体之间的多种关系,包含很多有用的知识。例如,我们可以通过分析新分子的图结构和节点属性来预测新分子的属性。
在图数据中使用Transformer面临的主要挑战有两方面:
(i)计算每个中心节点对整个图数据的注意力权重会导致O(N2)时间和空间复杂度,从而导致图变大时内存不足的问题。
(ii)虽然Transformer可以全局自适应地聚合信息,但由于其聚合过程完全不依赖于边,因此Transformer很难充分利用图结构信息。
在图表示学习中,图神经网络(GNN)已成为主导选择,各种 GNN 架构在许多基于图的任务中实现了最先进的性能,例如节点分类、链接预测和图分类。尽管 GNN 及其变体已经取得了很大的进步,但仍然存在一些局限性。一方面,消息传递机制依赖边来融合图结构和节点属性,导致很强的偏差和噪声。如果节点之间没有连接,就无法获得一些有用的信息。此外,在真实的图数据中,存在许多连接不相关节点的噪声边。这些由消息传递机制引起的偏差和噪声使得 GNN 学习到的表示包含不完整的信息,从而损害了下游任务的性能。另一方面,由于过度平滑问题,GNN 的感受野也受到限制。事实证明,随着GNNs架构变得更深并达到一定程度,模型将不再对训练数据做出响应,并且这种深度模型获得的节点表示往往会过度平滑,也变得难以区分。这些限制导致 GNN 出现令人沮丧的妥协,其中感受野有限的浅层 GNN 只能聚合邻域内的不完整信息,而深层 GNN 则存在过度平滑问题。
本文提出的问题是,是否可以将 Transformer 和 GNN 结合起来,通过融合各自的优势来相互帮助? 在 Transformer 的帮助下,GNN 的接受场可以扩展到更多相关的节点,这些节点可能远离中心节点。另一方面,GNN 可以帮助 Transformer 捕获复杂图拓扑信息,并有效地从邻域中聚合更多相关节点。
模型框架
TransGNN 的框架如图1所示,该框架由三个重要组成部分组成: (1)注意力采样模块,(2)位置编码模块,(3) TransGNN 模块。首先通过考虑注意力采样模块中的语义相似度和图结构信息,对每个中心节点进行最相关节点的采样。然后在位置编码模块中,计算位置编码以帮助 Transformer 捕获图拓扑信息。在这两个模块之后我们使用 TransGNN 模块,该模块按顺序包含三个子模块: (i) Transformer 层,(ii) GNN 层,(iii)样本更新子模块。其中,Transformer 层用于扩展 GNN 层的接受场,高效地聚合注意力样本信息,而 GNN 层则帮助 Transformer 层感知图结构信息,获取更多邻近节点的相关信息。样本更新子模块用于在新表示时有效地更新注意力样本。

图 1:TransGNN 的框架。我们首先对中心节点的相关节点进行采样,然后计算位置编码以通过结合结构信息来增强原始属性。在TransGNN模块中,Transformer层和GNN层相互改进,其次是样本更新子模块。
1 注意力采样模块
在图数据中,不需要计算每个节点对整个图的关注,只要考虑最相关的节点就足够了,这不仅降低了复杂性,而且还过滤掉了噪声节点的信息。计算节点属性的语义相似矩阵:

然而,通过 S 只能得到原始的语义相似度,而不考虑结构的影响。邻居节点的偏好对中心节点也有影响,因为在消息传递机制后,信息将被传递到邻居节点。使用以下公式更新相似度矩阵以包含邻居节点的偏好:
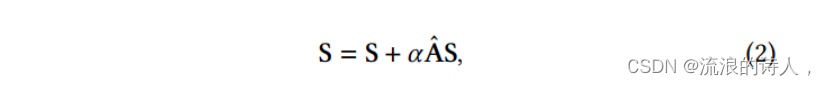
注意力采样:给定输入图 G 及其相似度矩阵 S,对于图中的节点 𝑣𝑖,我们将其注意力样本定义为集合 Smp(𝑣𝑖) = {𝑣𝑗 |𝑣𝑗 ∈ 𝑉 和 𝑆(𝑖, 𝑗) ∈ top-k (𝑆(𝑖, :))} 其中𝑆(𝑖, :) 表示 S 的第 𝑖 行,𝑘 作为超参数,决定应该关注多少个节点。
2 位置编码模块
在图数据中,结构信息对于图表示学习是非常重要的。然而,与类似网格的数据(其中序列顺序可以被 Transformer 轻松捕获)不同,图结构信息更为复杂。为了获取 Transformer 的图结构信息,我们提出了三种位置编码:(i)基于最短路径跳的位置编码。(ii)基于程度的位置编码。(iii)基于位置编码的 PageRank。前两个考虑了拓扑距离和局部结构,最后一个显示了拓扑在中、大型图中决定的重要性。
(1)基于最短路径跳的位置编码:
拓扑距离是图数据中一种重要的结构信息,可以在一定程度上用来描述拓扑相似性。具体地说,将最短路径跳矩阵记为P,对于每个节点𝑣∈V及其注意样本节点𝑣𝑗∈Smp(𝑣),最短路径跳为P(i,𝑗),计算每个注意样本节点𝑣𝑗的基于最短路径跳的位置编码(SPE)为:
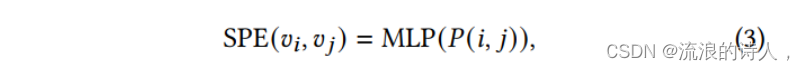
(2)基于度的位置编码:
在图数据中,节点的度可以表示其周围邻居结构的复杂程度,而度越大的节点可能具有更复杂的局部结构。许多真实世界数据中的度分布具有幂律性质,表明中心节点和注意样本的度可能是不同的。对于任意一个度为degi的节点𝑣i,基于度的位置编码(DE)为

(3)基于Page Rank 的位置编码:
在现实图中,不同的节点由于拓扑结构的不同而具有不同的重要性。Page Rank算法可以根据节点在图数据中的结构角色对其重要性进行标注,其中重要性越高的节点将被标记为页面Rank值越高的节点。对于节点𝑣i,将其页面秩值表示为Pr(𝑣i),基于页面秩的位置编码(PRE)为:
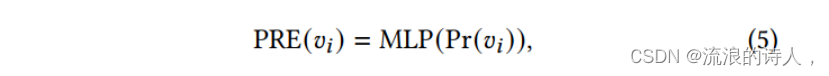
基于上面定义的位置编码,Transformer 可以捕获许多不同类型的图结构信息,方法是将它们聚合到原始节点属性中。具体来说,对于中心节点𝑣和它的注意力样本Smp(𝑣),通过以下方式对位置编码进行聚合:
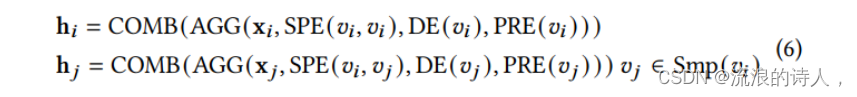
3 TransGNN模块
GNN 的感受野有限,因为它们的消息传递机制只聚集邻居内的信息,但深度 GNN 存在过度平滑问题。在图中,相关节点可能远离中心节点,并且在邻居内的节点也可能包含噪声。这损害了 GNN 的有效性。然而,虽然 Transformer 可以聚合远距离的相关信息,但是 Transformer 很难充分利用结构信息,并且复杂性也是重要的问题。在本模块中,将 Transformer 和 GNN 相结合,使其优势互补,其中包含三个子模块:(i) Transformer 层,(ii) GNN 层,(iii) samples 更新子模块。
(1)Transformer 层:
使用 Transformer 层来改进 GNN 层,将感受野扩展到更相关的节点,这些节点可能远离邻域。
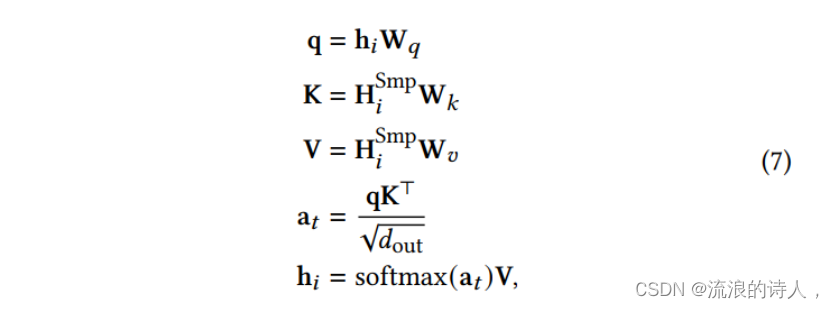
多头的注意力

(2)GNN 层:
利用 GNN 层融合表示和图结构,帮助 Transformer 层更好地利用图结构。
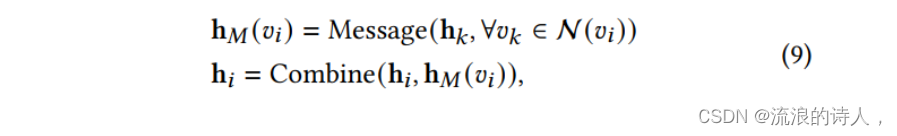
(3)样本更新子模块:
在 Transformer 层和 GNN 层之后,注意力样本应该根据新的表示进行更新。然而,计算相似矩阵将导致𝑂(N2)复杂度。
基于随机游走的更新:考虑到图数据的局域性,相似节点更有可能包含在邻域中,通过探索注意力样本邻域来更新注意力样本,以找到可能的新的相关节点。使用随机漫步策略来探索每个采样节点的局部邻域。具体而言,根据相似度计算随机游走的转移概率为:
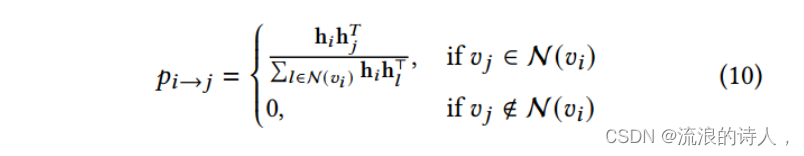
基于消息传递的更新:基于随机游动的更新策略有额外的开销。我们提出了另一种更新策略,利用GNN层的消息传递来更新样本,而没有额外的开销。具体来说,我们在GNN层的消息传递过程中,对每个中心节点的邻居节点的注意力样本进行聚合。这背后的直觉是,邻居的注意力样本也可能是中心节点的相关注意力样本。我们将相邻节点的关注样本集表示为关注消息,其定义如下:

理论分析
(1)定理1:TransGNN 至少具有 GNN 的表达能力,任何 GNN 都可以被 TransGNN 表达。

虚线表示Transformer层的感受野,颜色表示相似关系。
(2)定理2:TransGNN 比 1-WL Test 更具表达性。
实验

结果
节点分类

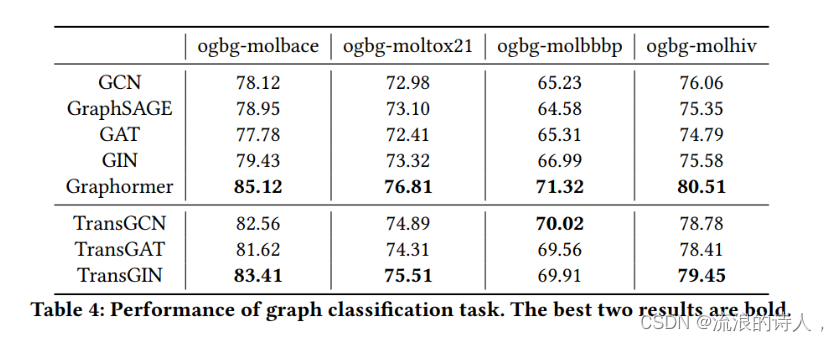
图分类

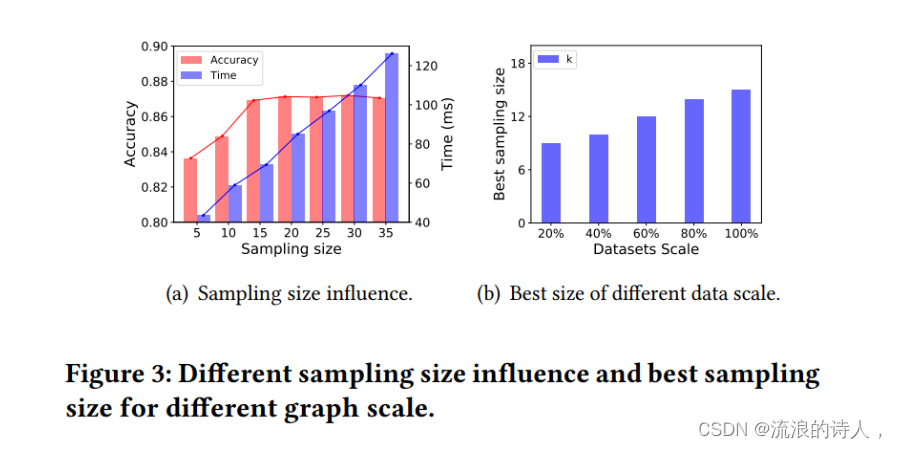
注意力采样

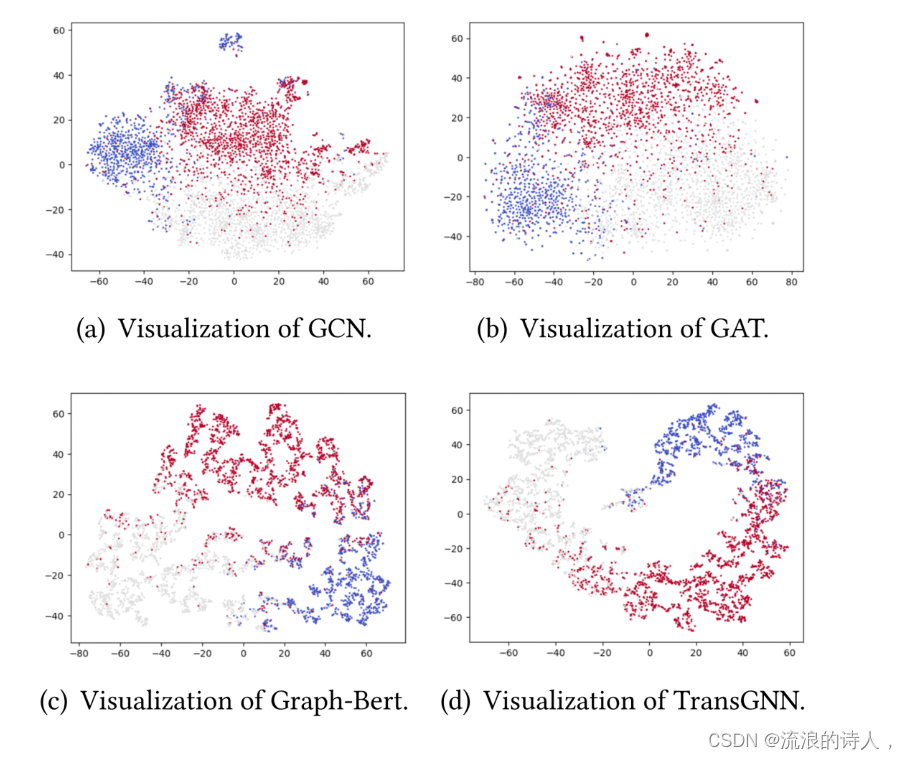
可视化