🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/

在深度神经网络中,网络权重的初始化非常关键,因为它对网络的训练速度、收敛能力以及最终的性能都有重大影响。具体来说,权重初始化的重要性主要体现在以下几个方面:
-
避免对称性破坏:如果所有权重都初始化为相同的值,这会导致网络无法打破对称性,所有神经元学到相同的特征。合理的初始化可以打破这种对称性,使得每个神经元可以学习到不同的特征。
-
梯度消失 / {/} /爆炸问题:深度神经网络在反向传播时容易遇到梯度消失或者梯度爆炸的问题。如果权重初始化得太小,信号可能会在通过每层时逐渐衰减,导致梯度消失;相反,如果权重初始化得太大,则信号可能会随着传播变得越来越大,导致梯度爆炸。合理的初始化方法可以缓解这些问题,确保梯度在合适的范围内。
-
加快收敛速度:适当的权重初始化可以帮助模型更快地收敛。如果权重初始化得太远离最优解,模型需要更多时间来调整这些权重以达到最佳性能。而一个好的初始化策略可以使权重开始时就更接近最优解,从而加快训练过程。
-
影响模型性能:不恰当的初始化可能导致模型陷入局部最小值或鞍点,尤其是在复杂的非凸优化问题中。一个好的初始化方法可以提高找到全局最小值或更好局部最小值的机会。
为了解决上述问题和挑战,研究者们提出了多种权重初始化方法。例如:
-
Xavier/Glorot 初始化:考虑到前向传播和反向传播时权重梯度的方差,保持输入和输出的方差一致。
-
Kaiming 初始化:针对 ReLU 激活函数进行了优化,考虑到 ReLU 在正区间内梯度为常数。
-
正态分布和均匀分布随机初始化:随机设置权重值,可以打破对称性。简单但效果依赖于具体任务和网络架构。
-
正交初始化:权重矩阵的行或列是正交的。通常用于 RNN。
-
稀疏初始化:保持大部分权重为零,只有少数非零初始值。
总之,合理选择和调整深度学习模型中的权重初始化方法是确保模型良好训练行为和高性能表现的关键步骤之一。
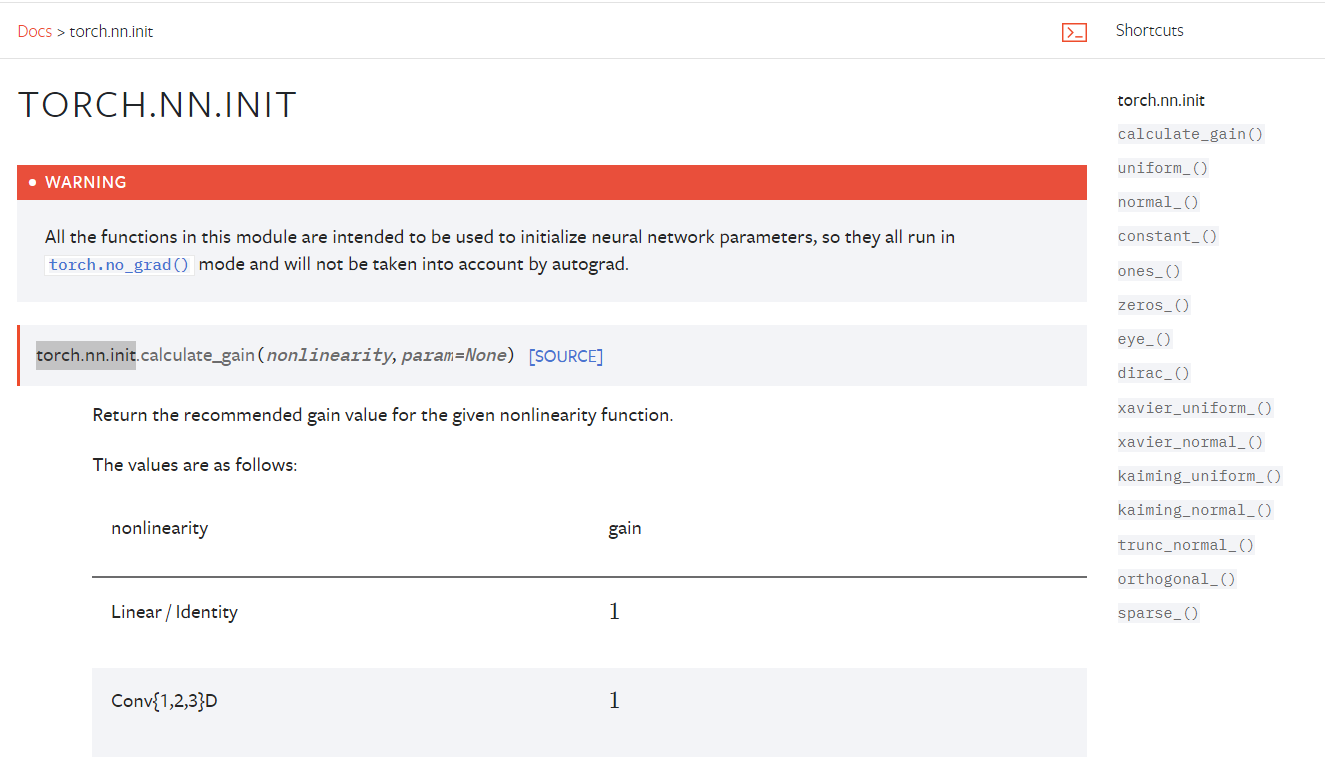
值得注意的是,PyTorch 的 torch.nn.init 模块中的所有函数都旨在用于初始化神经网络参数,因此它们都在 torch.no_grad() 模式下运行,不会被自动求导考虑在内。函数包括为给定的非线性函数返回推荐增益值(如 ReLU、Sigmoid、Tanh 等)、用均匀分布或正态分布填充张量、将张量填充为常数值、单位矩阵、Dirac 函数、使用 Xavier 或 Kaiming 方法进行初始化,以及使用截断正态分布和正交方法进行初始化。此外,还提供了稀疏初始化方法。这些初始化方法对于确保神经网络的有效训练非常关键。