langchian 使用已经下载到本地的模型,我们使用通义千问
显存:24G
模型:qwen1.5-7B-Chat,qwen-7B-Chat
先使用 qwen-7B-Chat,会报错用不了:
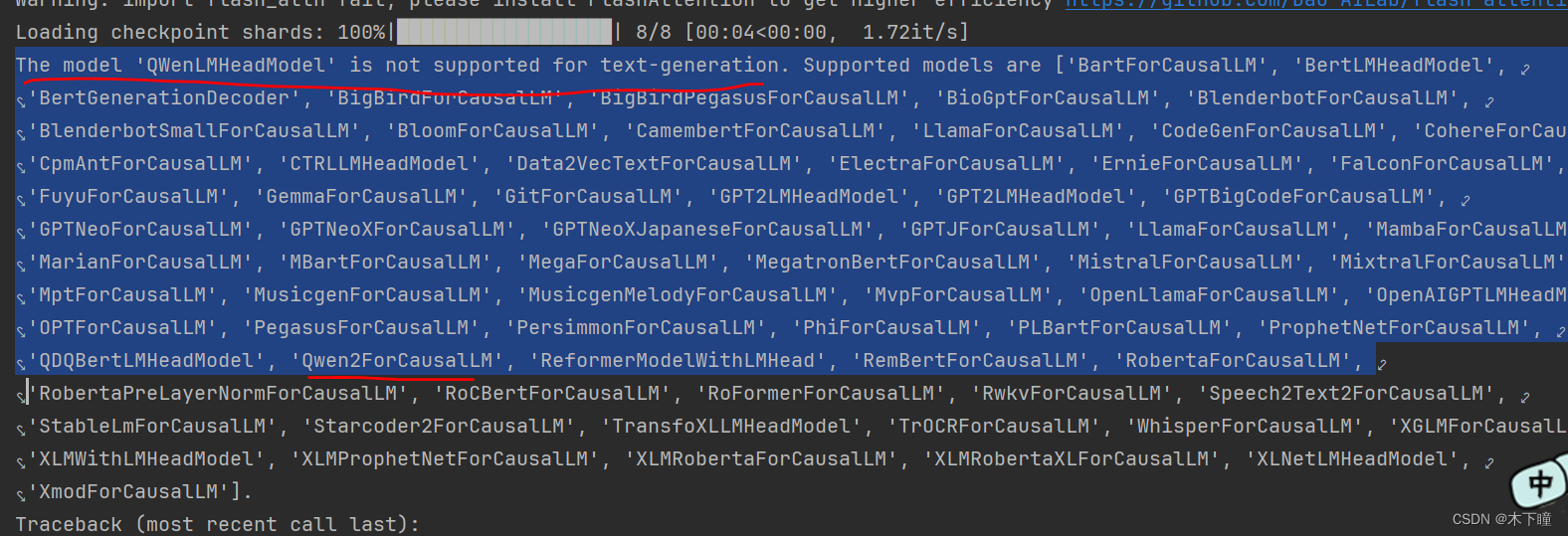
看了下是不支持这中模型,但看列表中有一个 Qwen 字样,想着应该是支持的,就去 hugging face 搜了下这个东西 “Qwen2”找到了对应的 qwen1.5-7B-Chat 模型
https://huggingface.co/Qwen/Qwen1.5-7B-Chat
 其实也就是一种公测版本,,所以总结来说目前直接导入本地 通义千问 langchaing 支持不是很好,可以使用 ollama,但这个下载非常慢,还会失败
其实也就是一种公测版本,,所以总结来说目前直接导入本地 通义千问 langchaing 支持不是很好,可以使用 ollama,但这个下载非常慢,还会失败
qwen1.5-7B-Chat 我们用这个模型,是可以加载成功的,并输出的,但是非常非常慢
from transformers import AutoTokenizer, AutoModelForCausalLM
from transformers import pipeline
from langchain import HuggingFacePipeline
from langchain_core.prompts import ChatPromptTemplate
model_path = "/root/autodl-tmp/Qwen1___5-7B-Chat"
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map='auto',
trust_remote_code=True
).eval()
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
# max_length=4096,
# max_tokens=4096,
max_new_tokens=512,
top_p=1,
repetition_penalty=1.15
)
llama_model = HuggingFacePipeline(pipeline=pipe)
prompt = ChatPromptTemplate.from_template("请编写一篇关于{topic}的中文小故事,不超过100字")
chain = prompt | llama_model
res = chain.invoke({"topic": "小白兔"})
print(res)