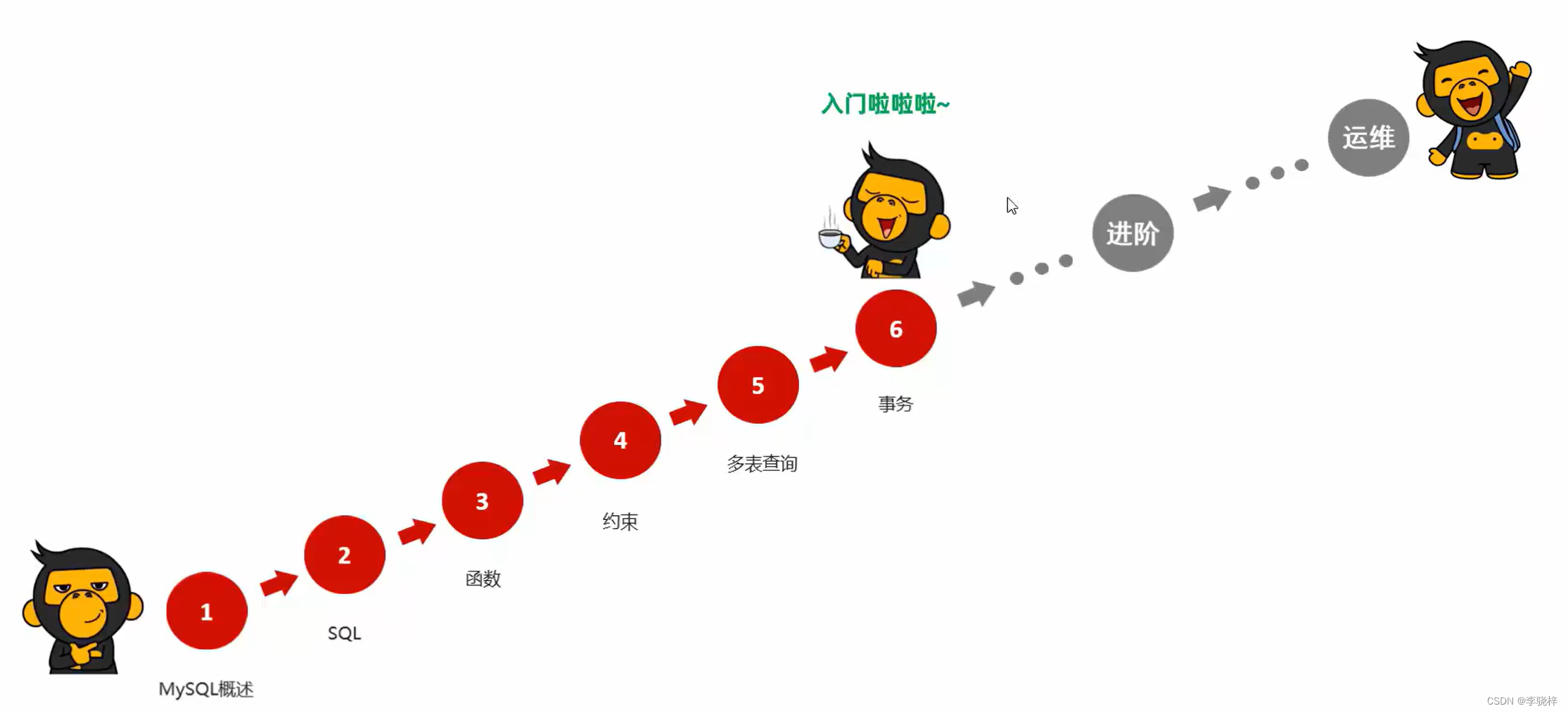
函数
函数 是指一段可以直接被另一段程序调用的程序或代码

-
字符串函数
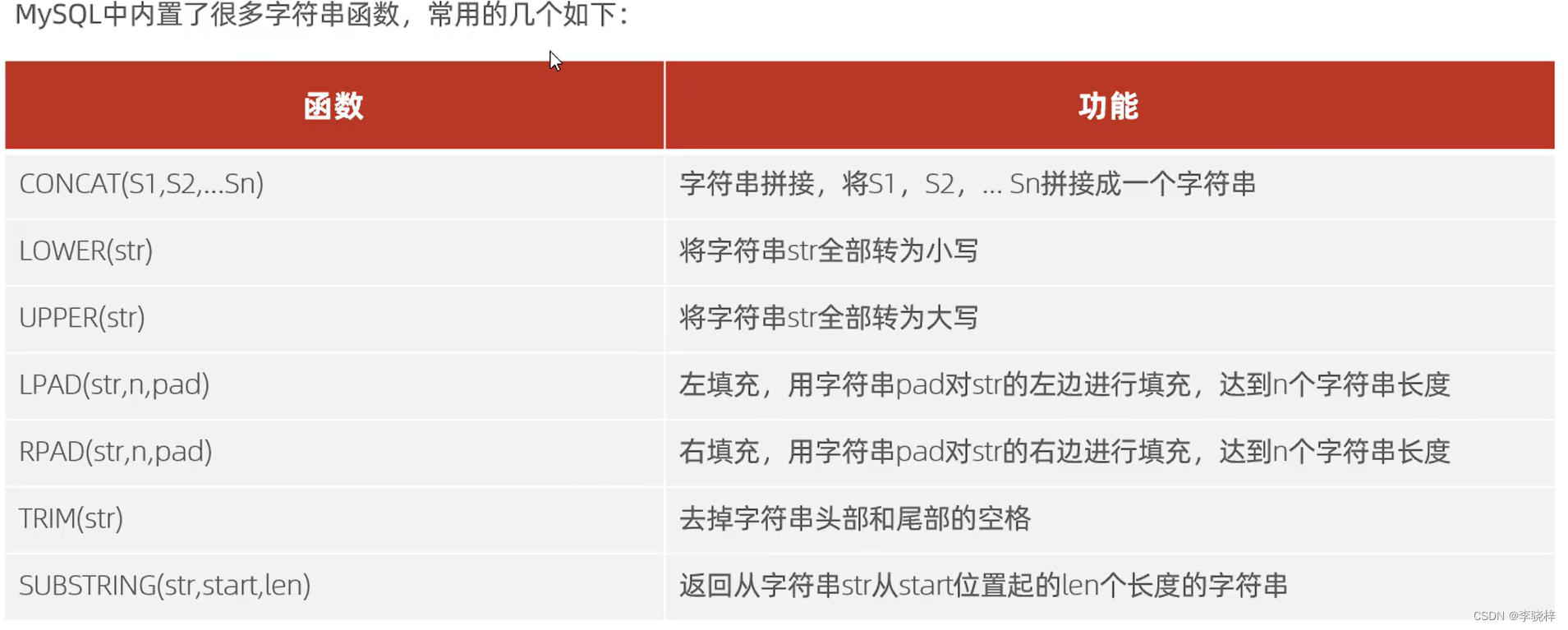
SELECT 函数(参数);
--concat 连接
select concat('Hello' , 'MySQL');
--lower 将所有大写转换为小写
select lower('Hello');
--upper 将所有小写转换为大写
select upper('Hello');
--lpad 左填充
select lpad('01',5,'-');
--rpad 右填充
select rpad('01',5,'-');
--trim 去除左右空格
select trim(' Hello Mysql ');
--substring 字符串截取 索引值是从1开始的
select substring('Hello MySQL',1,5);
--1.由于业务需求变更,企业员工的工号,统一为5位数,目前不足5位数的全部在前面补0。比如: 1号员工的工号应该为00001。 (补0是个更新数据的操作)
update emp set workno = lpad(workno,5,'0');
-
数值函数
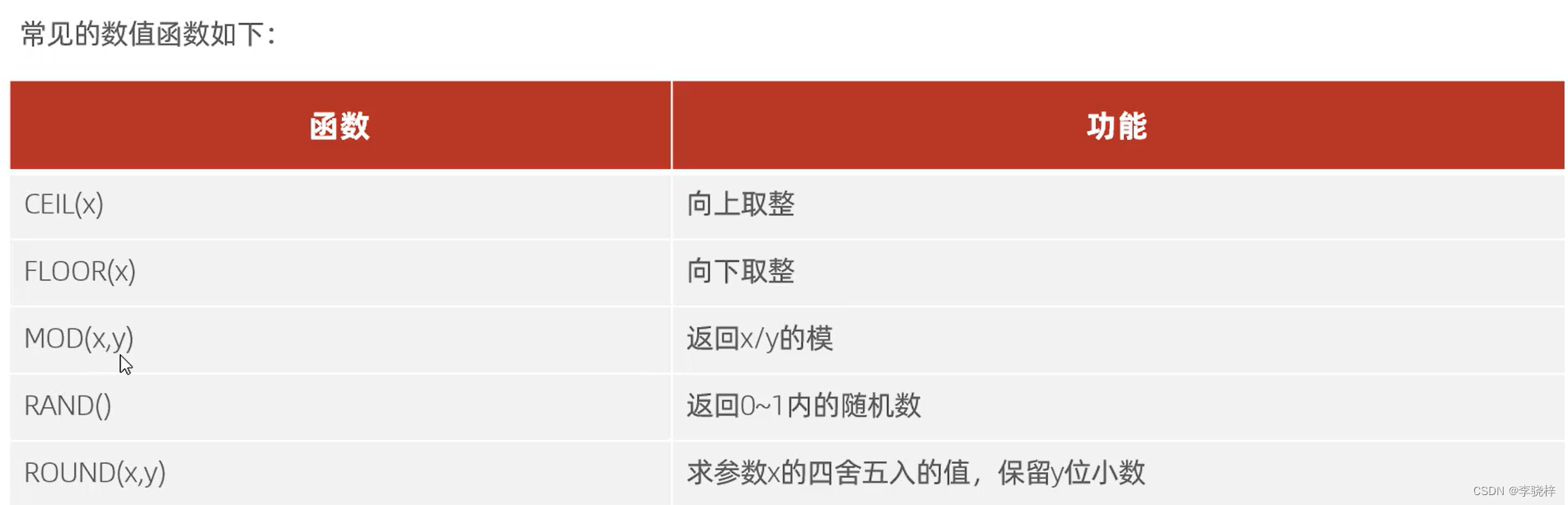
--ceil 向上取整
select ceil(1.1);
--floor 向下取整
select floor(1.9);
--mod 求模运算
select mod(3,4);--3除以4 取余
--rand 求随机数(0~1之间)
select rand();
--round 四舍五入
select round(2.345,2); --对2.345四舍五入保留两位小数--2.通过数据库的函数,生成一个六位数的随机验证码。
select round(rand()*1000000,0);--此时还有bug——0.019344也是
select lpad(round(rand()*1000000,0),6,(rand()*1000000));
select lpad(floor(rand()*1000000),6,'0');-
日期函数
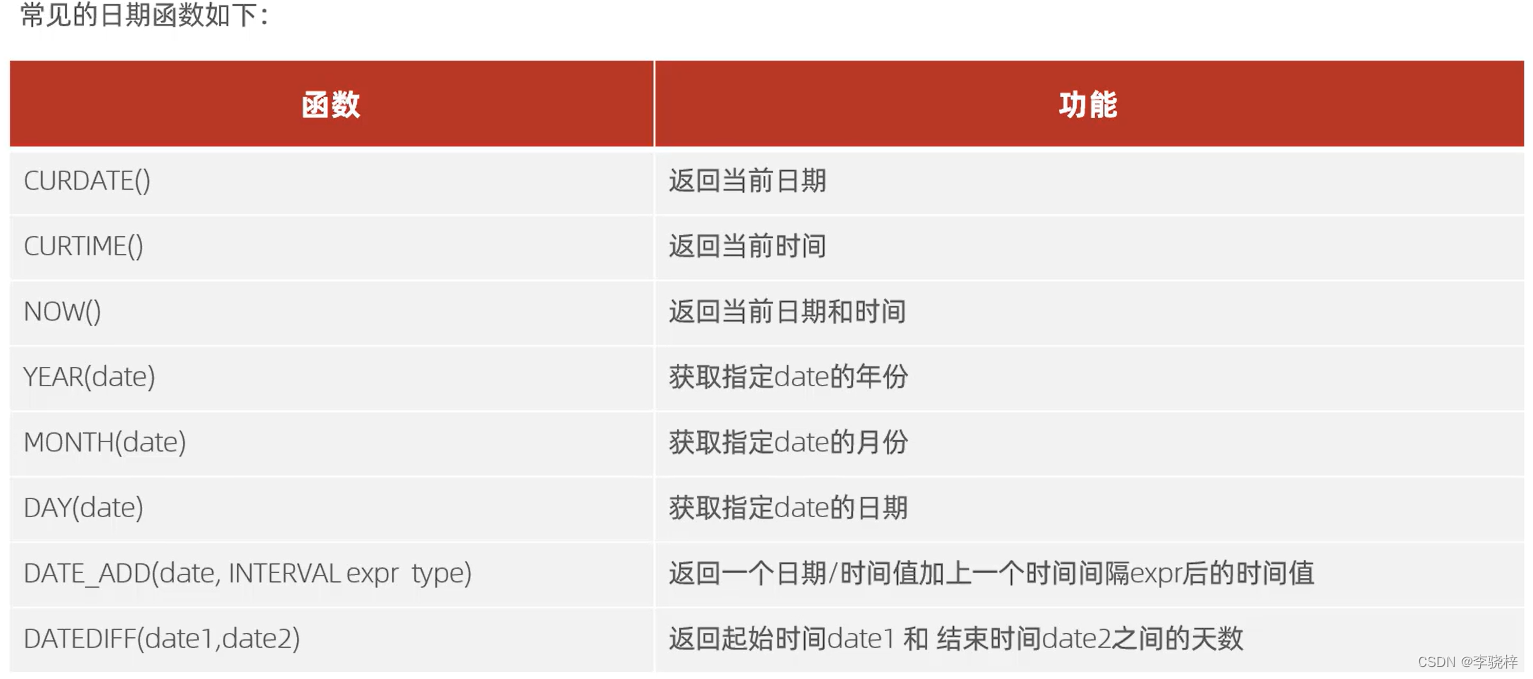
--curdate 返回当前日期
select curdate();
--curtime 返回当前时间
select curtime();
--now 返回当前时间和日期
select now();
--year(date) 获取指定的年份
select year(now());
--month(date) 获取指定的月份
select month(now());
--day(date) 获取指定的日期
select day(now());
--date_add(date,interval expr type) 返回一个日期/时间值加上一个时间间隔express后的时间值
select date_add(now(), interval 99 day);
--datediff(date1,date2) 返回起始时间date1和结束时间date2之间的天数 第一个日期减第二个日期
select datediff(now(),'2019-03-10');
select datediff(curdate(),'2019-03-10');--3.查询所有员工的入职天数,并根据入职天数倒序排序。
select name,datediff(curdate(),entrydate) as 'entrydays' from emp order by entrydays desc;-
流程函数
流程函数也是很常用的一类函数,可以在SQL语句中实现条件筛选,从而提高语句的效率。

--if
select if(true,'ok','error');
--ifnull
select ifnull('ok','default');
select ifnull('','default');
--case when then else end
--需求:查询emp表的员工姓名工作地址(北京/上海 --> 一线城市,其他 --> 二线城市)
select
name,
( case workaddress when '北京' then '一线城市' when '上海' then '一线城市' else '二线城市' end ) as '工作地址'
from emp; -- 案例:统计班级各个学员的成绩,展示的规则如下:
-- >= 85,展示优秀
-- >= 60,展示及格
-- 否则,展示不及格
create table score
(
id int comment 'ID',
name varchar(20) comment '姓名',
math int comment '数学',
english int comment '英语',
chinese int comment '语文'
) comment '学员成绩表';
insert into score(id, name, math, english, chinese)
VALUES (1, 'Tom', 67, 88, 95),
(2, 'Rose', 23, 66, 90),
(3, 'Jack', 56, 98, 76);
select id,
name,
(case when math >= 85 then '优秀' when math >= 60 then '及格' else '不及格' end) '数学',
(case when english >= 85 then '优秀' when english >= 60 then '及格' else '不及格' end) '英语',
(case when chinese >= 85 then '优秀' when chinese >= 60 then '及格' else '不及格' end) '语文'
from score;总结:

约束
-
概述
- 概念:约束是作用于表中字段上的规则,用于限制存储在表中的数据。
- 目的:保证数据库中数据的正确、有效性和完整性。
- 分类:

注意:约束是作用于表中字段上的,可以在创建表/修改表的时候添加约束 。
-
约束演示
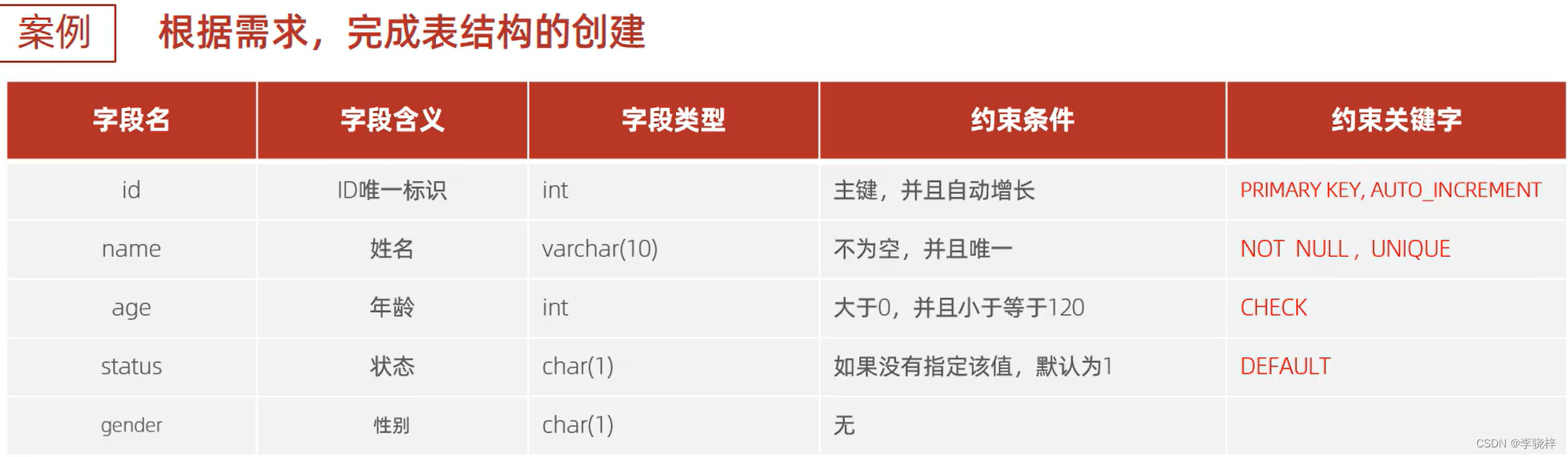
create table user(
id int primary key auto_increment comment '主键',
name varchar(10) not null unique comment '姓名',
age int check ( age > 0 and age <= 120 ) comment '年龄',
status char(1) default '1' comment '状态',
gender char(1) comment '性别'
)comment '用户表';-
外键约束
概念:键用来让两张表的数据之间建立连接,从而保证数据的一致性和完整性
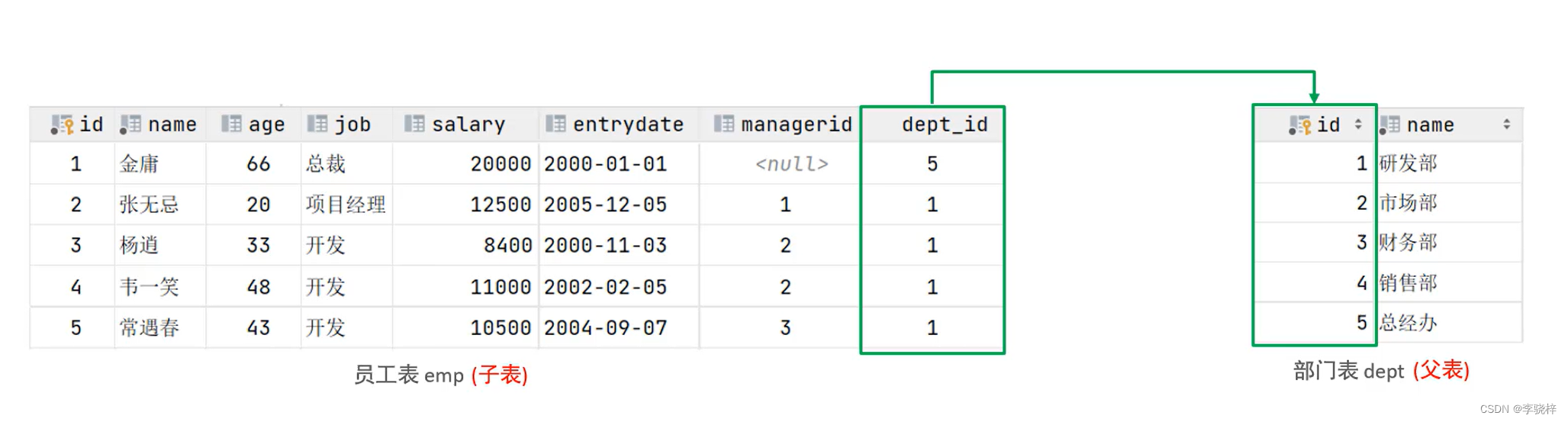
注意:目前上述的两张表,不在数据库层面,并未建立外键关联,所以是无法保证数据的一致性和完整性的。
语法:
-
添加外键
CREATE TABLE 表名(
字段名 数据类型,
...
[CONSTRAINT] [外键名称] FOREIGN KEY(外键字段名) REFERENCES 主表(主表列名)
);
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY(外键字段名) REFERENCES 主表(主表列名);
-- 添加外键
alter table emp
add constraint fk_emp_dept_id foreign key (dept_id) references dept (id);-
删除外键
ALTER TABLE 表名 DROP FOREIGN KEY 外键名称;
-- 删除外键
alter table emp
drop foreign key fk_emp_dept_id;-
删除/更新行为

ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY(外键字段)
REFERENCES 主表名(主表字段名) ON UPDATE CASCADE ON DELETE CASCADE;
-- 外键的删除和更新行为 cascade
alter table emp
add constraint fk_emp_dept_id foreign key (dept_id) references dept (id) on update cascade on delete cascade;
更新和删除时关联的也会随之删除。
-- 外键的删除和更新行为 set null
alter table emp
add constraint fk_emp_dept_id foreign key (dept_id) references dept (id) on update set null on delete set null;删除掉部门时员工表对应的部门id就为null。
总结:
1.非空约束:NOT NULL
2.唯一约束:UNIQUE
3.主键约束:PRIMARY KEY(自增: AUTO INCREMENT)
4.默认约束:DEFAULT
5.检查约束:CHECK
6.外键约束:FOREIGN KEY
多表查询
-
多表关系
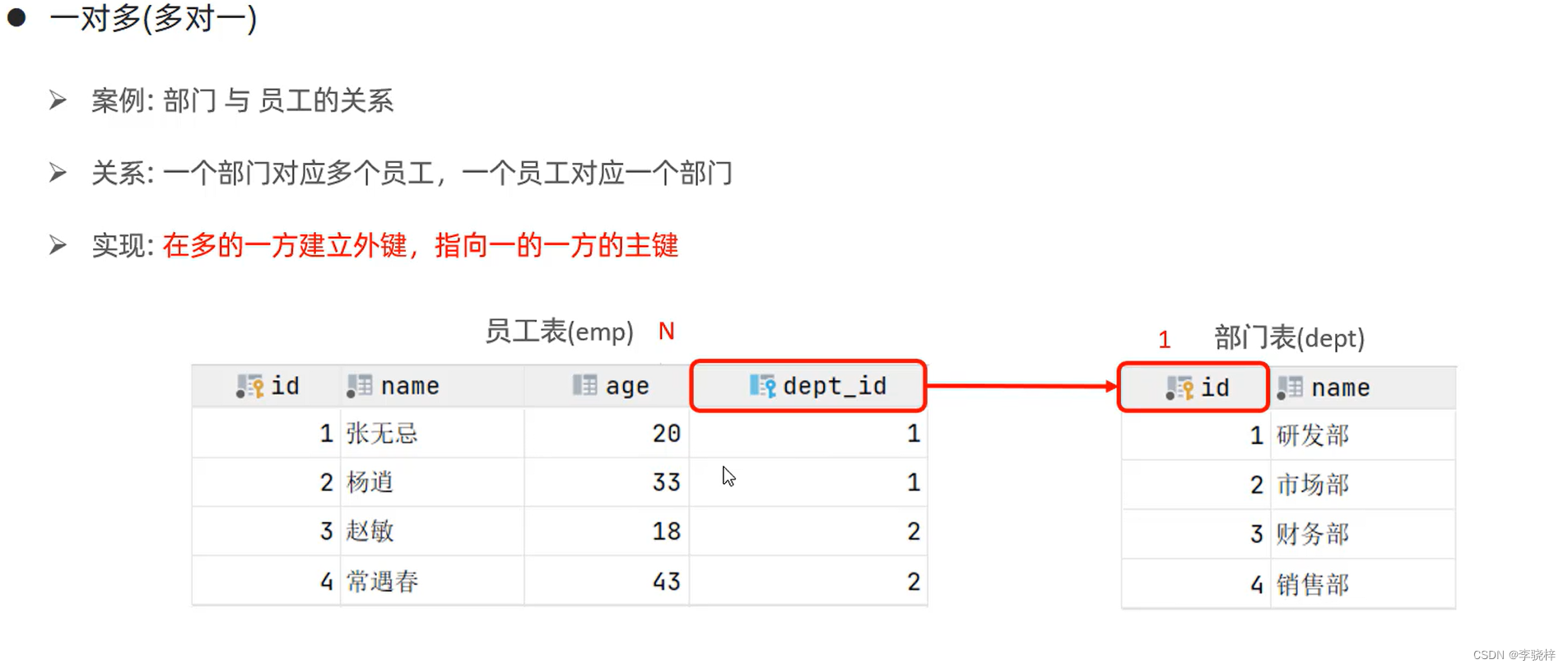
概述:业务模块之间的关系,分析并设计表结构,由于业务之间相互关联,项目开发中,在进行数据库表结构设计时,会根据业务需求及以各个表结构之间也存在着各种联系,基本上分为三种:
- 一对多(多对一)
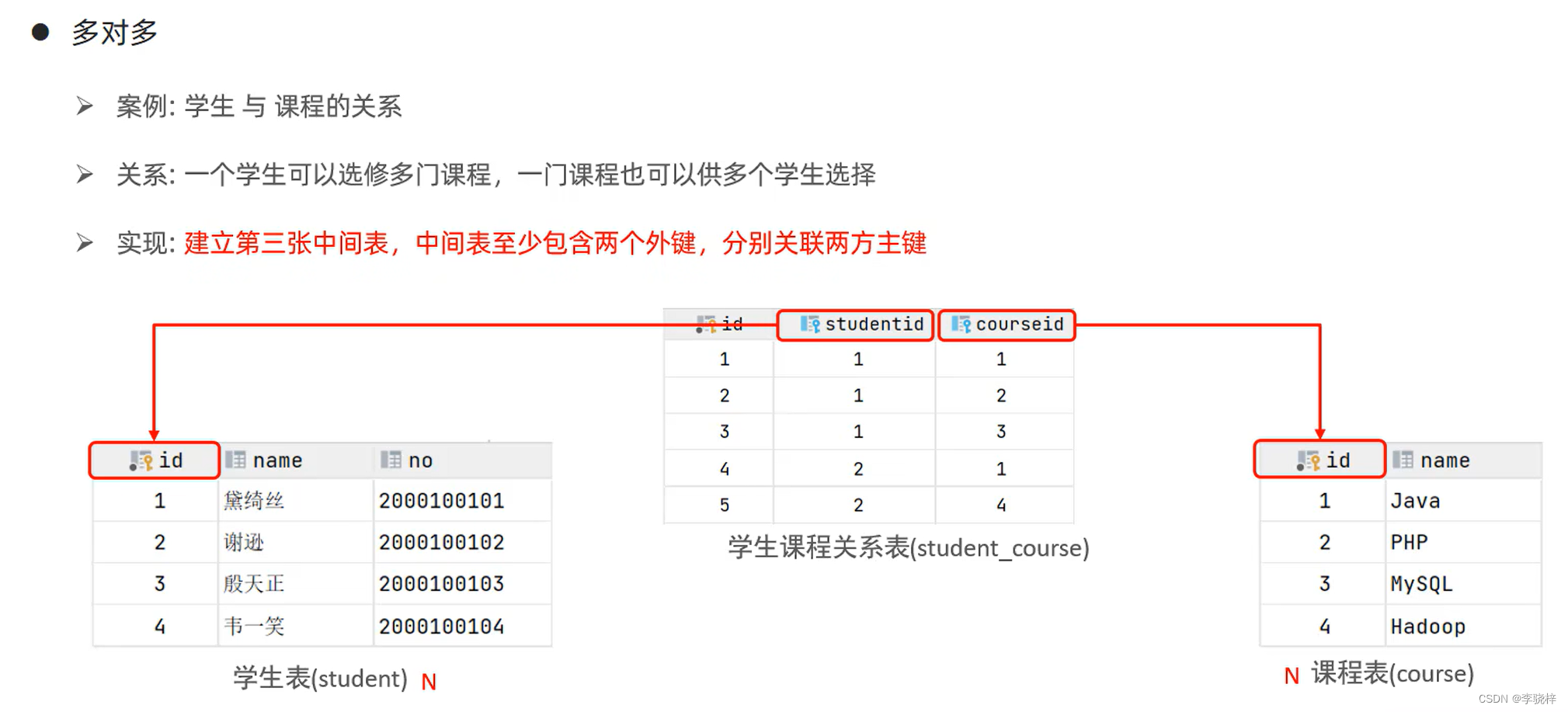
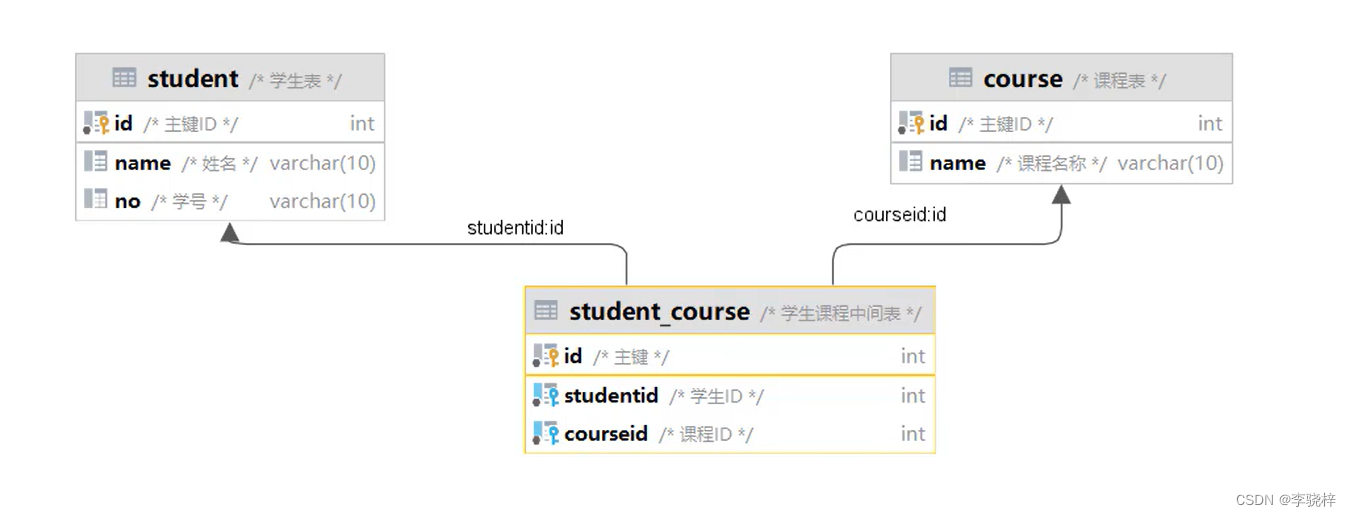
- 多对多
- 一对一
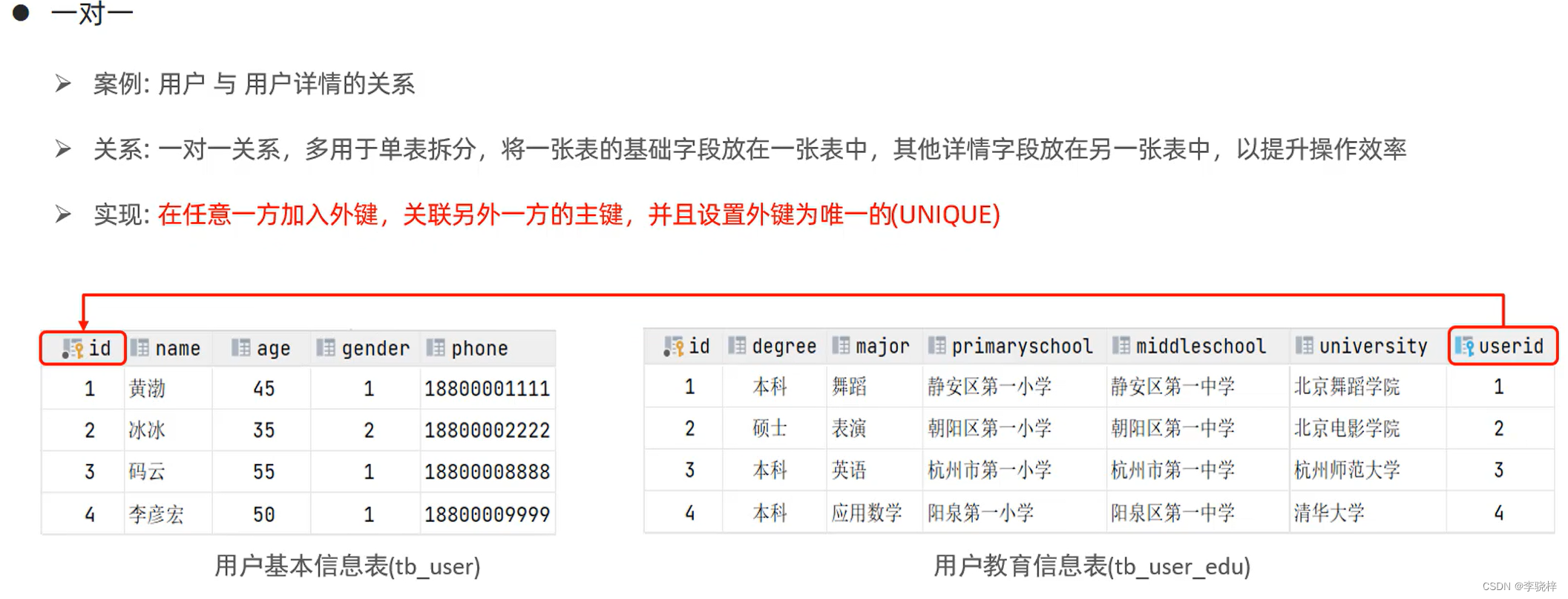
-
多表查询概述
概述:指从多张表中查询数据
笛卡尔积:笛卡尔乘积是指在数学中,两个集合A集合 和 B集合的所有组合情况。(在多表查询时,需要消除无效的笛卡尔积)
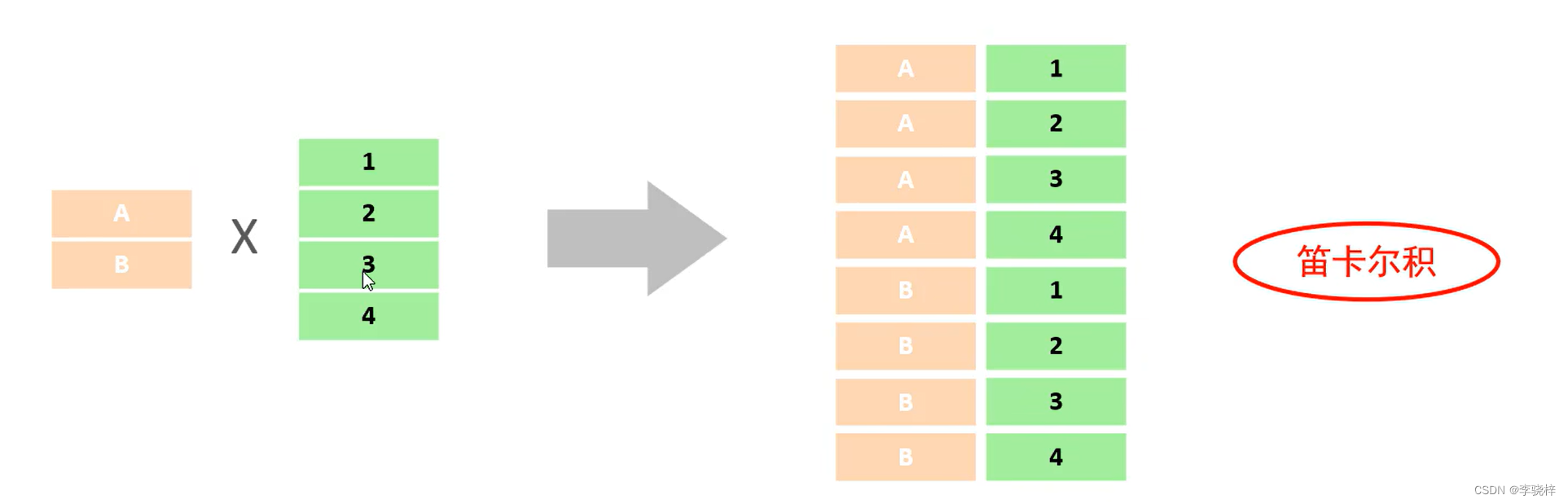 --->
--->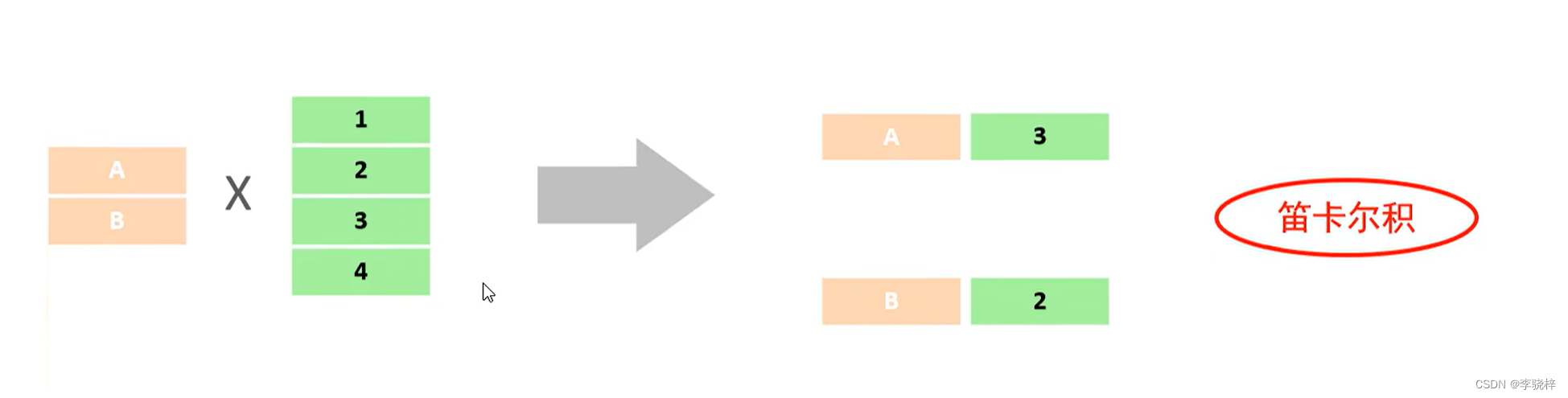
消除无效的笛卡尔积
select * from emp ,dept where emp.dept_id = dept.id;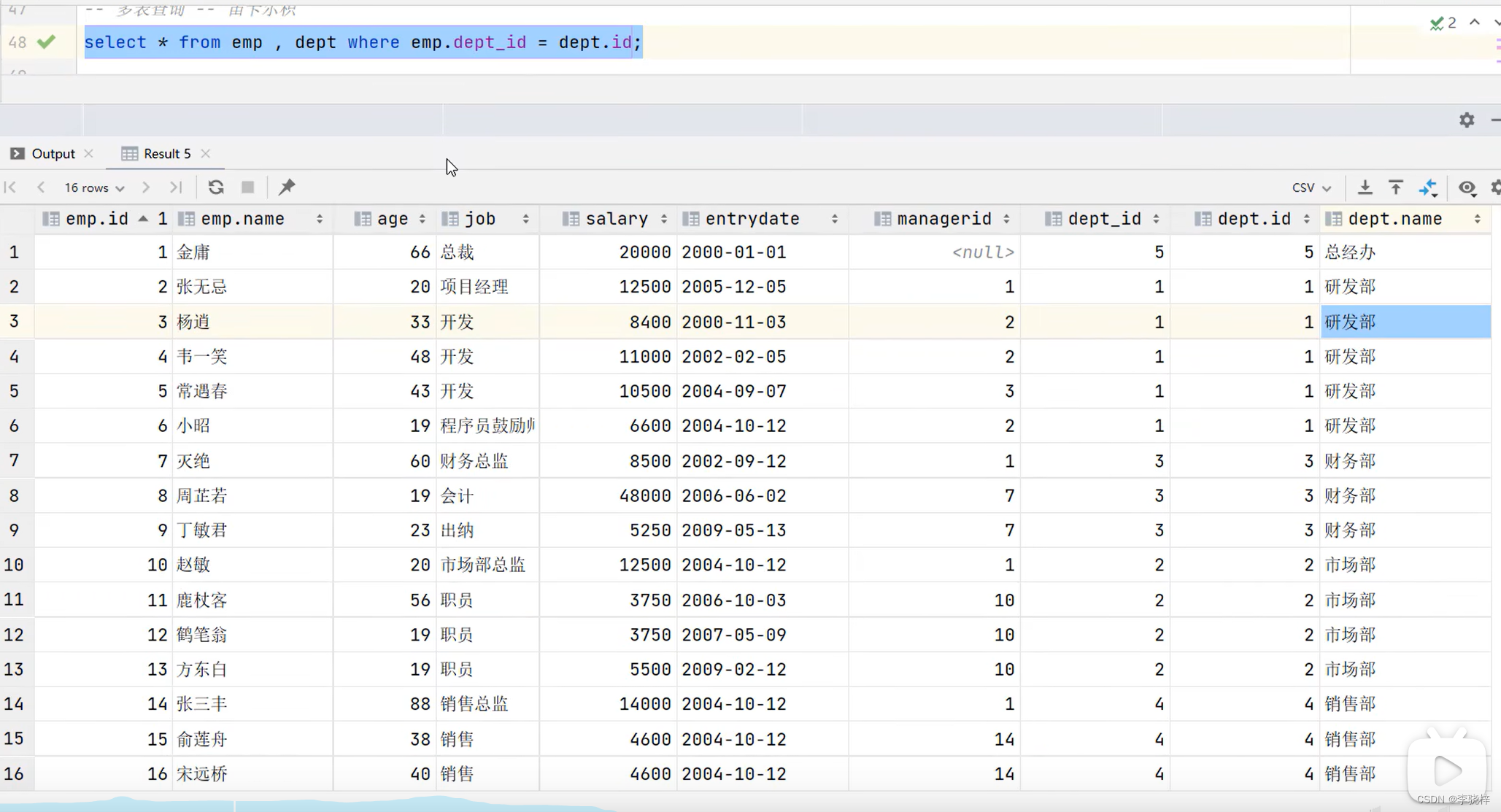
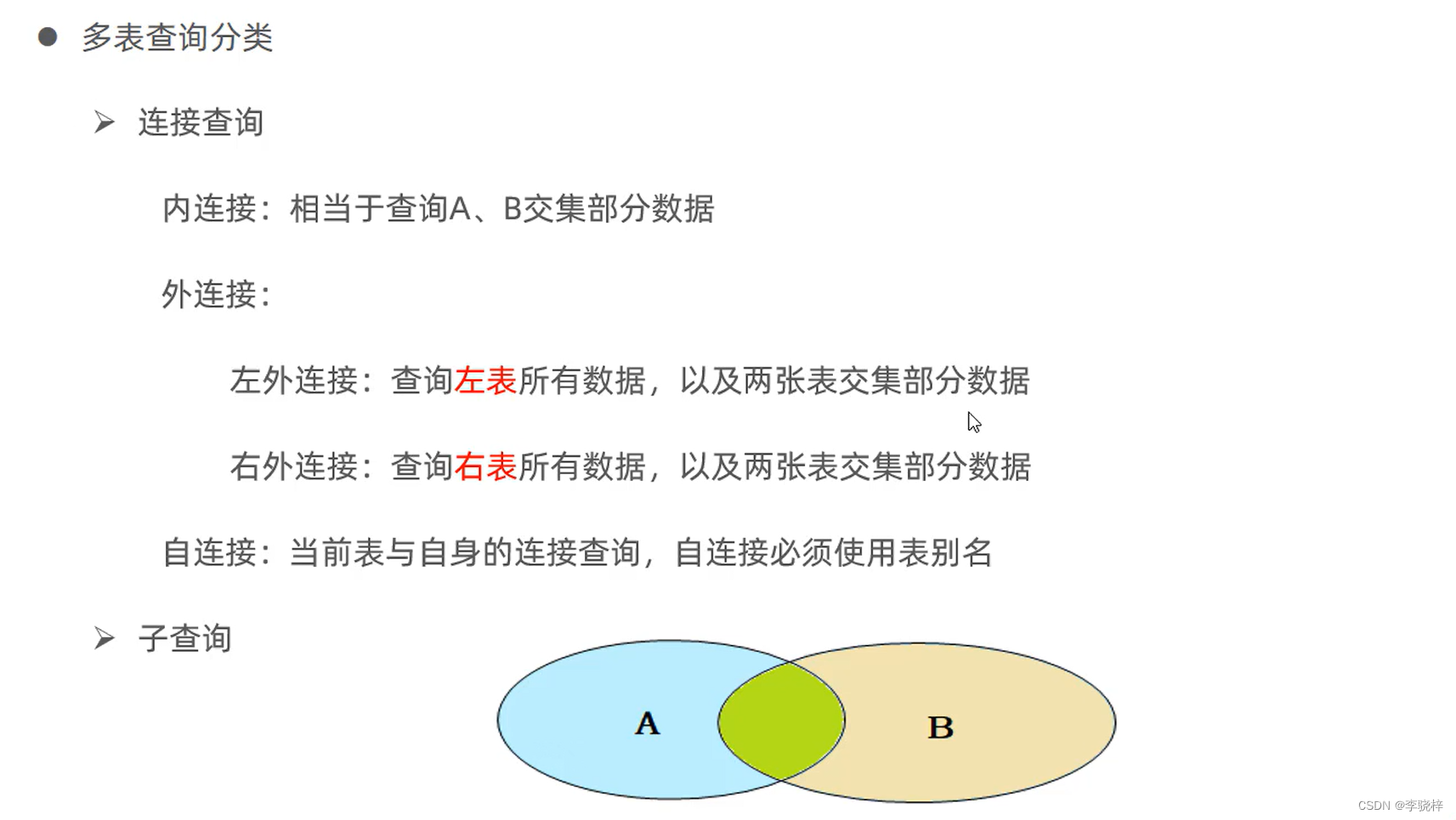
-
内连接
内连接查询语法:
- 隐式内连接
SELECT 字段列表 FROM 表1,表2 WHERE 条件 ...;
- 显式内连接
SELECT 字段列表 FROM 表1 [INNER] JOIN 表2 ON 连接条件 ...;
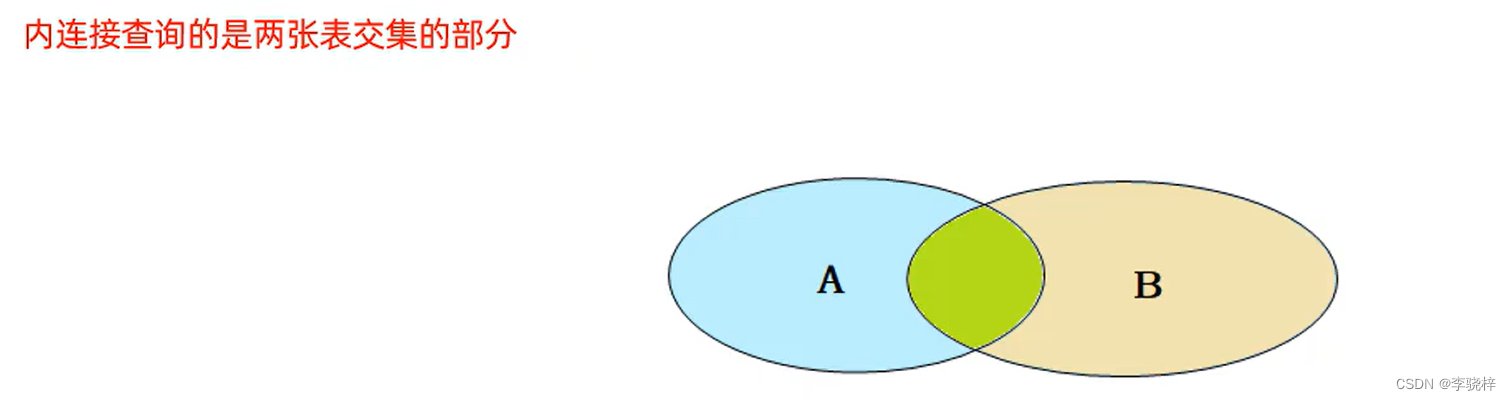
--内连接演示
--1.查询每一个员工的姓名,及关联的部门的名称(隐式内连接实现)
--表结构:emp,dept
--连接条件:emp.dept_id = dept.id
select emp.name,dept.name from emp,dept where emp.dept_id = dept.id;
--起别名
select * from emp e,dept d;
select e.name,d.name from emp e ,dept d where e.dept_id = d.id;
--如果对表起了别名就不能再直接用表名来限定字段,因为SQL语句先执行的是from,就已经使用了表名了
--2.查询每一个员工的姓名及关联的部门的名称(显式内连接实现)inner ... join ... on ...(on后接条件)
select e.name,d.name from emp e inner join dept d on e.dept_id = d.id;
select e.name,d.name from emp e join dept d on e.dept_id = d.id;-
外连接
外连接查询语法:
- 左外连接
SELECT 字段列表 FROM 表1 LEFT [OUTER] JOIN 表2 ON 条件 ...;
相当于查询表1(左表)的所有数据 包含 表1和表2交集部分的数据
- 右外连接
SELECT 字段列表 FROM 表1 RIGHT [OUTER] JOIN 表2 ON 条件 ...;
相当于查询表1(右表)的所有数据 包含 表1和表2交集部分的数据
--外连接演示
--1.查询emp表的所有数据,和对应的部门信息(左外连接)
表结构:emp,dept
连接条件:emp.dept_id = dept.id
select e.*,d.name from emp e left outer join dept d on e.dept_id = d.id;
select e.*,d.name from emp e left join dept d on e.dept_id = d.id;
--2.查询dept表的所有数据,和对应的员工信息(右外连接)
select d.*,e.* from emp e right outer join dept d on e.dept_id = d.id;
--左外用的多因为右可以改为左
select d.*,e.* from dept d left outer join emp e on e.dept_id = d.id;-
自连接
自连接查询语法:
SELECT 字段列表 FROM 表A 别名A JOIN 表A 别名B ON 条件 ...;
自连接查询,可以是内连接查询,也可以是外连接查询

将emp表看作是两张表。
--自连接
--1.查询员工及其所属领导的名字
--表结构:emp
select a.name ,b.name from emp a ,emp b where a.managerid = b.id;
--2.查询所有员工emp及其领导的名字emp,如果员工没有领导,也需要查询出来
--此时需要用到外连接,外连接才会包括左表或者右表的数据
select a.name '员工',b.name '领导' from emp a left join emp b on a.manangerid = b.id;
联合查询—union(查询后的结果去重),union all (直接合并)
对于union查询,就是把多次查询的结果合并起来,形成一个新的查询结果集。
SELECT 字段列表 FROM 表A ...
UNION [ ALL ]
SELECT 字段列表 FROM 表B…;
--union all,union
--1.将薪资低于 5000 的员工,和年龄大于 50 岁的员工全部査询出来
select * from emp where salary < 5000
union all
select * from emp where age > 50;--此时只是将两次查询合并,但是有重复的信息
--去重 删除all
select * from emp where salary < 5000
union
select * from emp where age > 50;对于联合查询的多张表的列数必须保持一致,字段类型也需要保持一致。
union all 会将全部的数据直接合并在一起,union 会对合并之后的数据去重。
-
子查询
概念:SQL语句中嵌套SELECT语句,称为嵌套查询,又称子查询。
SELECT * FROM t1 WHERE column1 = (SELECT column1 FROM t2);
子查询外部的语句可以是 INSERT / UPDATE / DELETE / SELECT 的任何一个。
根据子查询结果不同,分为:
- 标量子查询(子查询结果为单个值)
子查询返回的结果是单个值(数字、字符串、日期等),最简单的形式,这种子查询成为标量子查询
常用的操作符: = <> > >= < <=
--标量子查询
--1.查询“销售部”的所有员工信息
--a.查询“销售部”部门ID
select id from dept where name = '销售部';
--b.根据销售部部门id查询员工信息
select * from emp where dept_id = 4;
--子查询!!!
select * from emp where dept_id = (select id from dept where name = '销售部');
--2.查询在“方东白”入职之后的员工信息
--a.查询 方东白 的入职日期
select entrydate from emp where name = '方东白';
--b.查询指定入职日期之后入职的员工信息
select * from emp where entrydate > '2009-02-12';
select * from emp where entrydate > (select entrydate from emp where name = '方东白');- 列子查询(子查询结果为一列)
子查询返回的结果是一列(可以是多行),这种子查询称为列子查询。
常用的操作符:IN、NOT IN、ANY、SOME、ALL

--列子查询
--1.查询“销售部”和“市场部”的所有员工信息
--a.查询“销售部”和“市场部”的部门ID
select id from dept where name = '销售部' or name = '市场部';
--b.根据部门ID,查询员工信息
select * from emp where dept_id in (2,4);
select * from emp where dept_id in (select id from dept where name = '销售部' or name = '市场部');
--2.查询比财务部所有人工资都高的员工信息
--a.查询所有 财务部 人员工资
select id from dept where name = '财务部';
select salary from emp where dept_id = (select id from dept where name = '财务部');
--b.比财务部'所有人'工资都高的员工信息(要大于所有值所以前面加一个all——子查询返回回来的结果都要满足)
select * from emp where salary > all (select salary from emp where dept_id = (select id from dept where name = '财务部'));
--3.查询比研发部其中' 任意一人 '工资高的员工信息
select id from dept where name = '研发部';
select salary from emp where dept_id = (select id from dept where name = '研发部');
select * from emp where salary > any (select salary from emp where dept_id = (select id from dept where name = '研发部'));
select * from emp where salary > some (select salary from emp where dept_id = (select id from dept where name = '研发部'));
- 行子查询(子查询结果为一行)
子查询返回的结果是一行(可以是多列),这种子查询称为行子查询
常用的操作符: = 、 <> 、 IN 、 NOT IN
--行子查询
--1.查询与“张无忌”的薪资及直属领导相同的员工信息
--a.查询“张无忌”的薪资及直属领导
select salary , managerid from emp where name = '张无忌';
--b.查询与“张无忌”的薪资及直属领导相同的员工信息
select * from emp where salary = 12500 and managerid = 1;
select * from emp where (salary,managerid) = (12500,1);
--______________________________________________________________
select * from emp where (salary,managerid) = (select salary , managerid from emp where name = '张无忌');
表子查询(子查询结果为多行多列)
子查询返回的结果是多行多列,这种子查询称为表子查询
常用的操作符:IN
--表子查询
--1.查询与“鹿杖客"“宋远桥”的职位和薪资相同的员工信息
--a.查询“鹿杖客""宋远桥”的职位和薪资
select job,salary from emp where name = '鹿杖客' or name = '宋远桥';
--b.查询与“鹿杖客"“宋远桥”的职位和薪资相同的员工信息
select * from emp where (job,salary) in (select job,salary from emp where name = '鹿杖客' or name = '宋远桥')
2.查询入职日期是“2006-01-01”之后的员工信息及其部门信息
--a.查询入职日期是“2006-01-01”之后的员工信息
select * from emp where entrydate > '2006-01-01';
--b.查询这些员工其部门信息
select e.*,d.* from (select * from emp where entrydate > '2006-01-01') e left join dept d on e.dept_id = d.id;
根据子查询位置,分为:WHERE之后、FROM之后、SELECT之后。
-
多表查询案例

create table salgrade(
grade int,
losal int,
hisal int
)comment'薪资等级表';
insert into salgrade values(1,0,3000);
insert into salgrade values(2,3001,5000);
insert into salgrade values(3,5001,8000);
insert into salgrade values(4,8001,10000);
insert into salgrade values(5,10001 ,15000);
insert into salgrade values(6,15001,20000);
insert into salgrade values(7,20001,25000);
insert into salgrade values(8,25001,30000);
--1.查询员工的姓名、年龄、职位、部门信息。(隐式)
select e.name,e.age,e.job,d.name from emp e,dept d where e.dept_id = d.id;
--2.查询年龄小于30岁的员工姓名、年龄、职位、部门信息。(显式内连接)
select e.name,e.age,e.job,d.name from emp e join dept d on e.dept_id = d.id where e.age > 30;
--3.查询拥有员工的部门ID、部门名称。(交集——内连接)distinct 去重
select distinct d.* from emp e ,dept d where e.dept_id = d.id;
select distinct d.* from emp e join dept d on e.dept_id = d.id ;
--4.查询所有年龄大于40岁的员工,及其归属的部门名称;如果员工没有分配部门,也需要展示出来。(外连接)
select e.name,d.name from emp e left join dept d on e.dept_id = d.id where e.age > 40;
--5.查询所有员工的工资等级。(内连接)
select e.name,e.salary,s.grade from emp e,salgrade s where e.salary >= s.losal and e.salary <= s.hisal;
select e.name,e.salary,s.grade from emp e,salgrade s where e.salary between s.losal and s.hisal;
--6.查询"研发部"所有员工的信息及工资等级。(有n张表就会有n-1个连接条件)
-- 表:emp,salgrade ,dept
-- 连接条件 : emp.salary between salgrade.losal and salgrade.hisal ,emp.dept_id = dept.id
-- 查询条件:dept.name ='研发部'
select e.*,s.grade from emp e,dept d,salgrade s where e.dept_id = d.id and (e.salary between s.losal and s.hisal) and d.name = '研发部';
select e.*,s.grade from emp e,dept d join salgrade s on d.name = '研发部' where e.dept_id = d.id and (e.salary between s.losal and s.hisal);
--7.查询"研发部"员工的平均工资。
select avg(e.salary) from emp e,dept d where e.dept_id = d.id and d.name = '研发部';
--8.查询工资比"灭绝"高的员工信息。(标量子查询)
select * from emp where salary > (select salary from emp where name = '灭绝');
--9.查询比平均薪资高的员工信息。
select * from emp where salary > (select avg(salary) from emp);
--!!!10.查询低于本部门平均工资的员工信息。!!!
--a.查询指定部门的平均薪资
select avg(e1.salary) from emp e1 where e1.dept_id = 1;
--b.查询低于本部门的平均工资的员工信息 !!!
select * from emp e2 where e2.salary < (select avg(e1.salary) from emp e1 where e1.dept_id = e2.dept_id);
select *,(select avg(e1.salary) from emp e1 where e1.dept_id = e2.dept_id) '平均薪资' from emp e2 where e2.salary < (select avg(e1.salary) from emp e1 where e1.dept_id = e2.dept_id);
--11.查询所有的部门信息,并统计部门的员工人数。
select id,name, id from dept;
select count(*) from emp where dept_id = 1;
select d.id,d.name,(select count(*) from emp e where e.dept_id = d.id) '员工人数' from dept d;
--12.查询所有学生的选课情况, 展示出学生名称,学号,课程名称(多对多)
-- 表:student,course,student_course
-- 连接条件:student.id = student_course.studentid ,course.id = student_course.courseid
select s.name,s.no,s.course from student s,student_course sc,course c where s.id = sc.studentid and c.id = sc.course.id;总结:
事务
-
事务简介
事务 是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
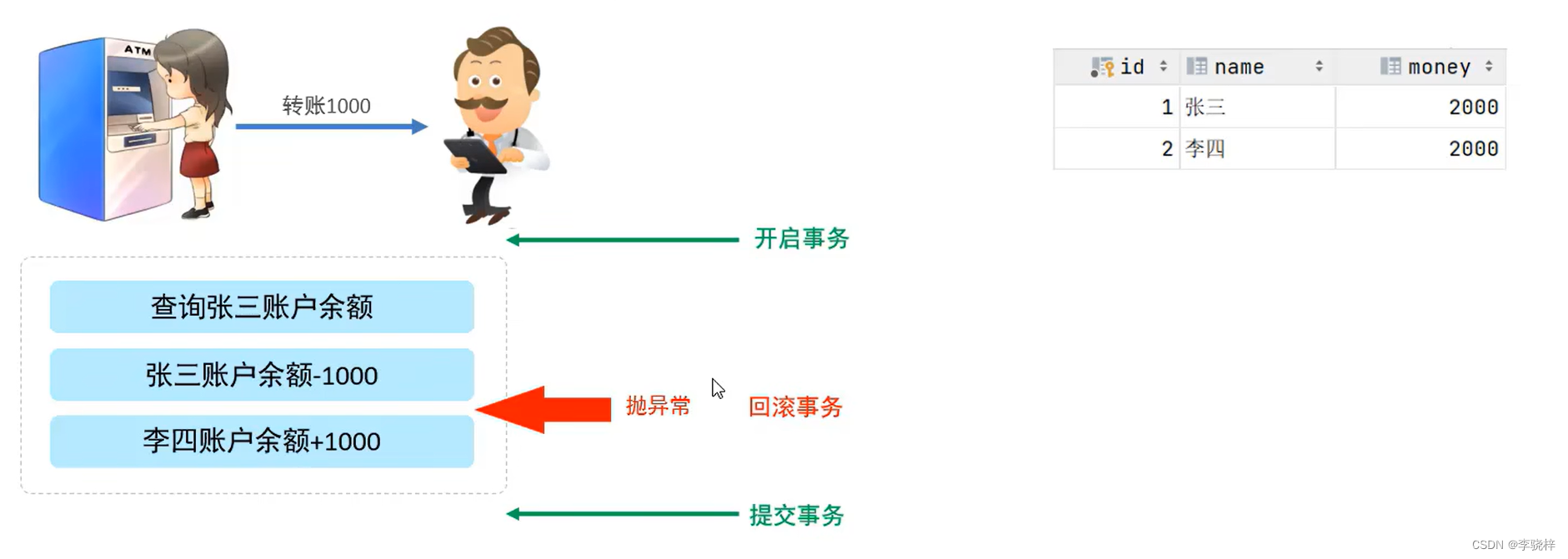
默认MySQL的事务是自动提交的,也就是说,当执行一条DML语句,MySQL会立即隐式的提交事务。
-
事务操作
- 查看/设置事务提交方式
SELECT @@auto commit;
SET @@autocommit = 0;(手动提交)
- 提交事务
COMMIT;
- 回滚事务
ROLLBACK;
- 开启事务
START TRANSACTION 或 BEGIN;
-- 方式一
select @@autocommit;
set @@autocommit = 1; -- (手动提交)会话参数 只针对当前窗口有效
-- 方式二
start transaction; -- 开启事务
-- 转账操作
-- 1.先查询张三账户的余额
select * from account where name = '张三';
-- 2.将张三的余额-1000
update account set money = money - 1000 where name ='张三';
程序抛出异常...
-- 3.将李四余额+1000
update account set money = money + 1000 where name ='李四';
-- 提交事务
commit;
-- 回滚事务
rollback;-
事务四大特性
- 原子性(Atomicity):事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
- 一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。
- 隔离性(lsolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
- 持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
-
并发事务问题

脏读:![]() 不可重复读:
不可重复读:![]() 幻读:
幻读:![]()
-
事务隔离级别
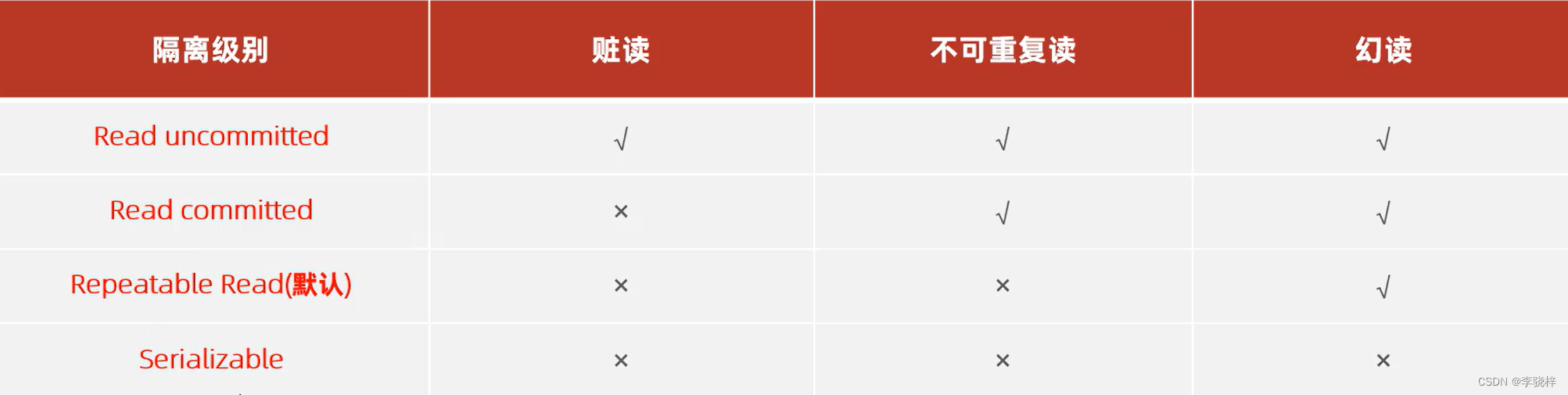
查看事务隔离级别
SELECT @@TRANSACTION_ISOLATION;
设置事务隔离级别
SET [SESSION | GLOBAL] TRANSACTION ISOLATION LEVEL {READ UNCOMMITTED | READ COMMITTED | REPFATABLE READ I SERIALZABLE }
-- 查看事务隔离级别
select @@transaction_isolation;
-- 设置隔离级别
set session transaction isolation level read uncommitted ;
-- 改回默认
set session transaction isolation level repeatable read ;Read uncommitted
1.
2.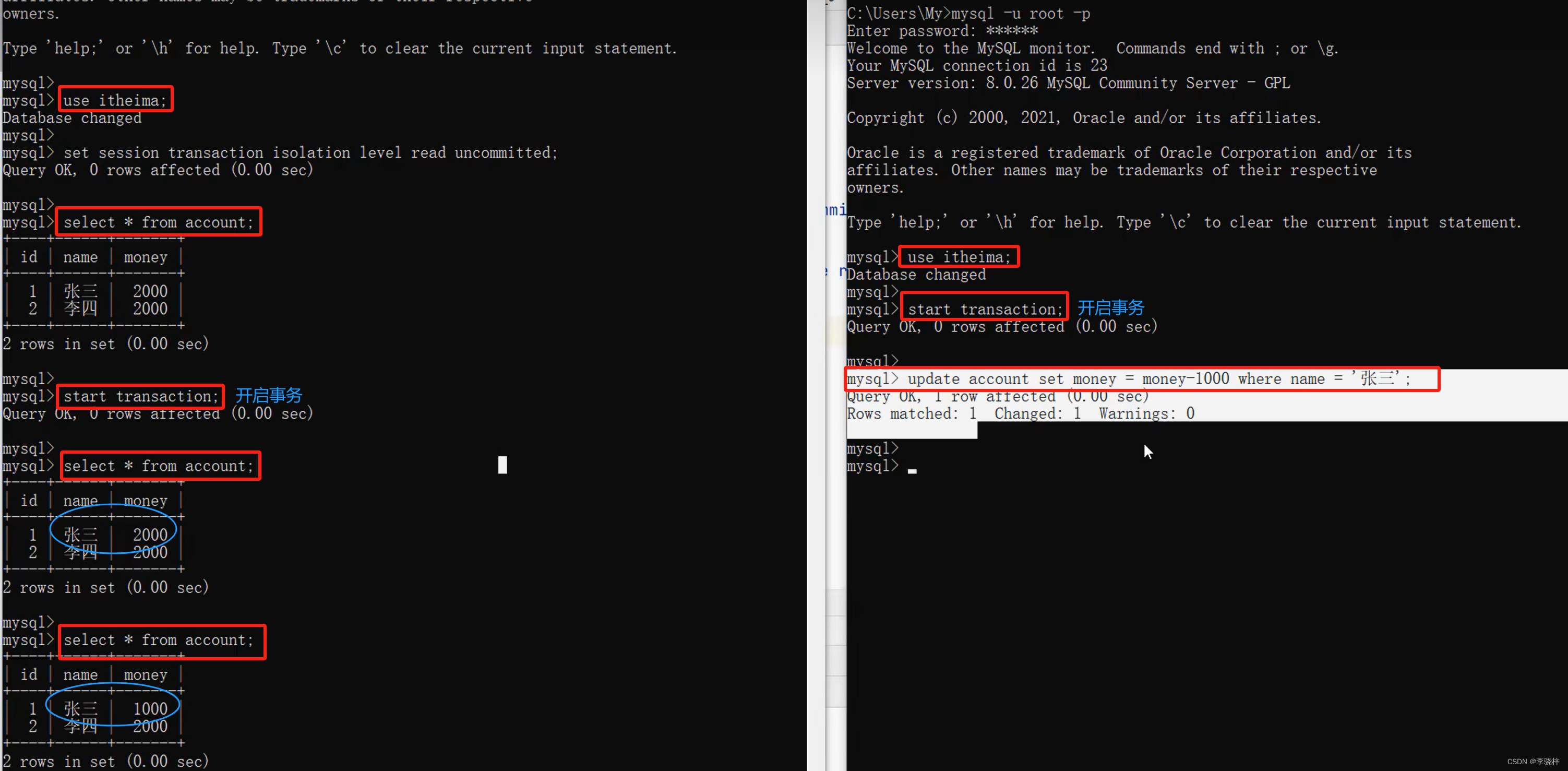
此时右侧还未提交事务,但左侧已经读到右侧修改后的数据,产生了脏读问题。
Read committed
1.![]()
2.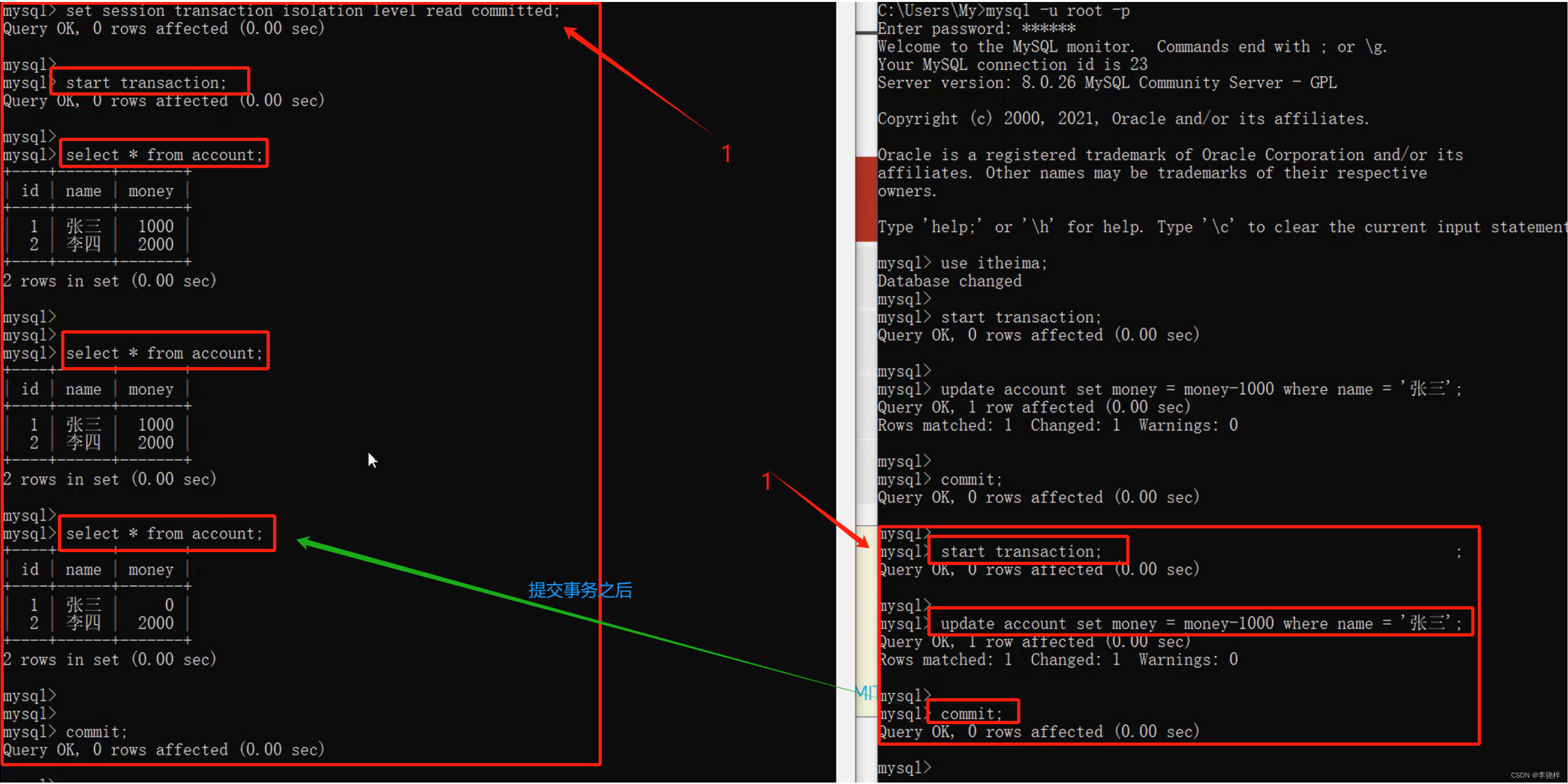 read uncommited 解决了脏读问题。再commit提交事务之后才会更改信息。
read uncommited 解决了脏读问题。再commit提交事务之后才会更改信息。
3.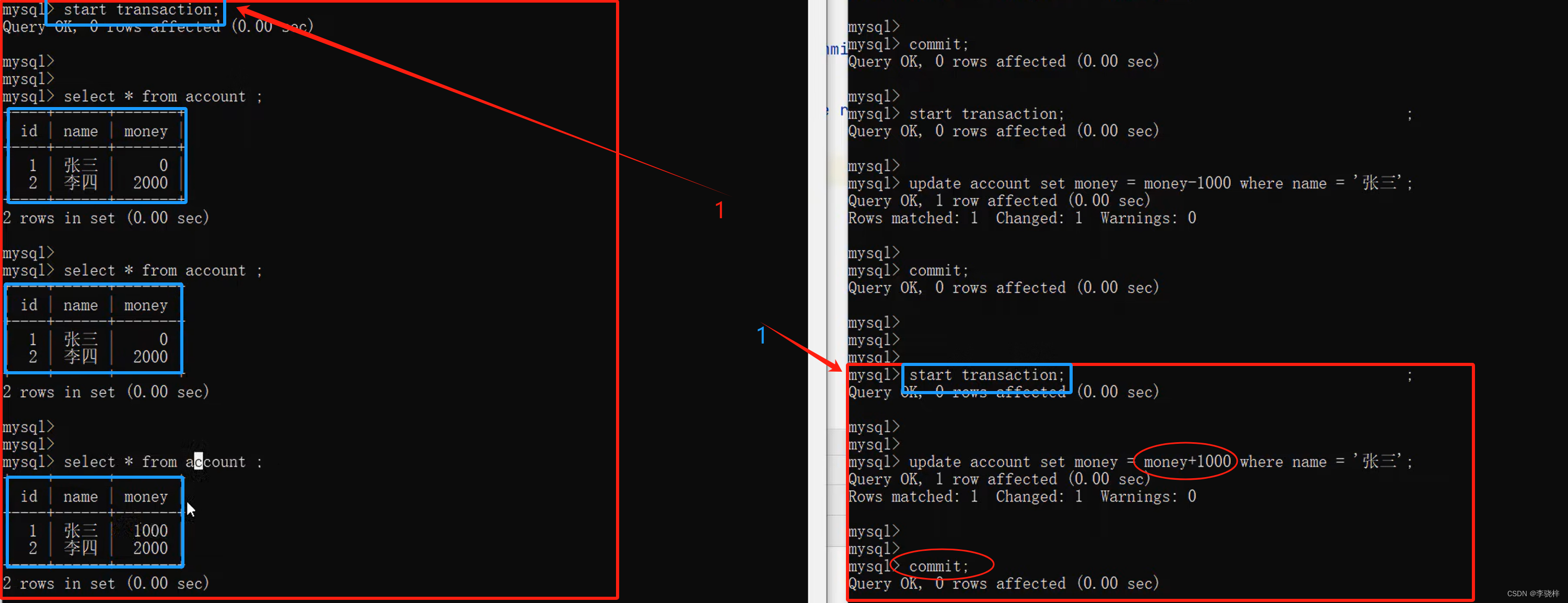
同样的SQL在同一个事务中,左侧却查询的数据却不一样,出现了不可重复读问题。
Repeatable Read(MySQL默认)
1.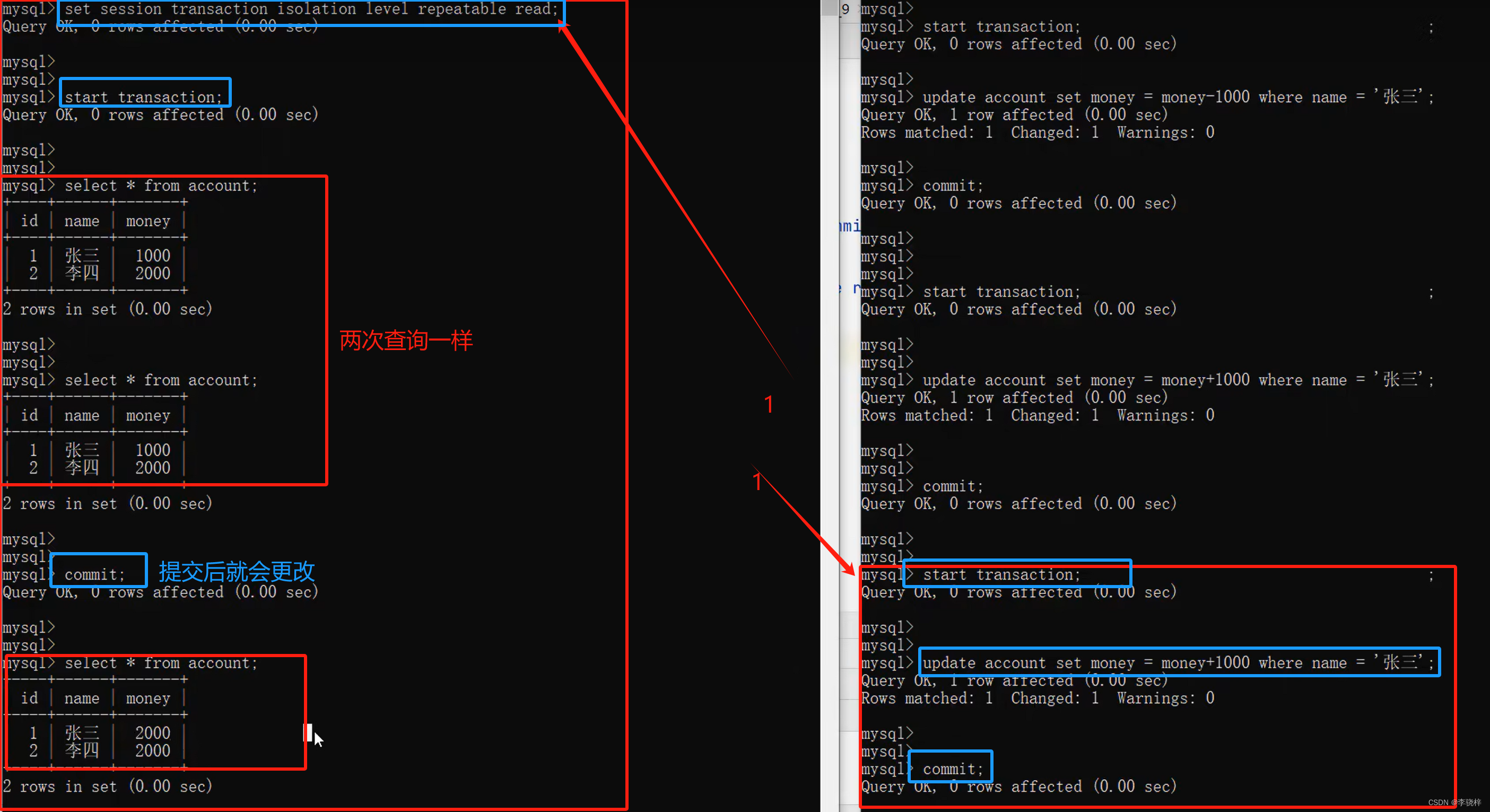
左侧提交之后才看到最新的数据,repeatable read是可重复读的,不会出现不可重复的问题。
2.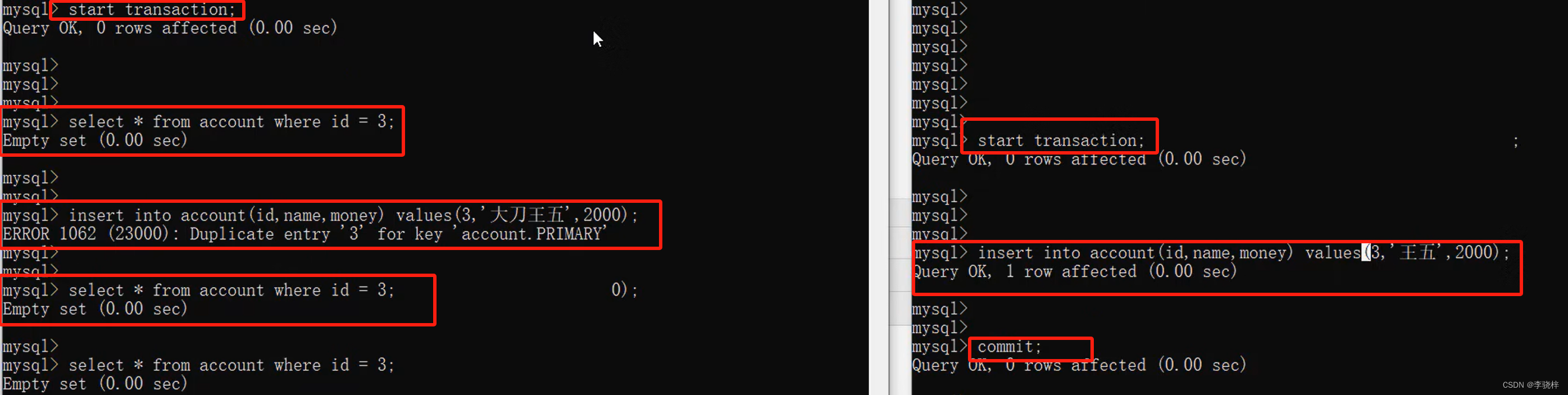
左侧查的时候没有,插入的时候又有,出现了幻读现象。
Serializable
1.
右侧添加数据时光标一直闪,代表他阻塞了,因为左侧的事务正在操作,右侧的事务就得等,等到左侧的事务执行完成之后把事务提交了,他才可以进行操作。(所以左侧查询出来之后他去插入没有问题,接着提交。之后右边才能执行,此时执行时候就会报错id为4的已经存在了)这样就规避了幻读的问题了。这就是串行化——在进行并发事务操作的时候只允许一次一个事务来操作,a事务操作的时候b事务等;a事务完成之后b事务才能操作。
注意:事务隔离级别越高,数据越安全,但是性能越低。
总结:
数据库基础总结: