本文首发于公众号:机器感知
StoryImager、Face Morph、Hash3D、DreamView、Magic-Boost、SmartControl
Eagle and Finch: RWKV with Matrix-Valued States and Dynamic Recurrence
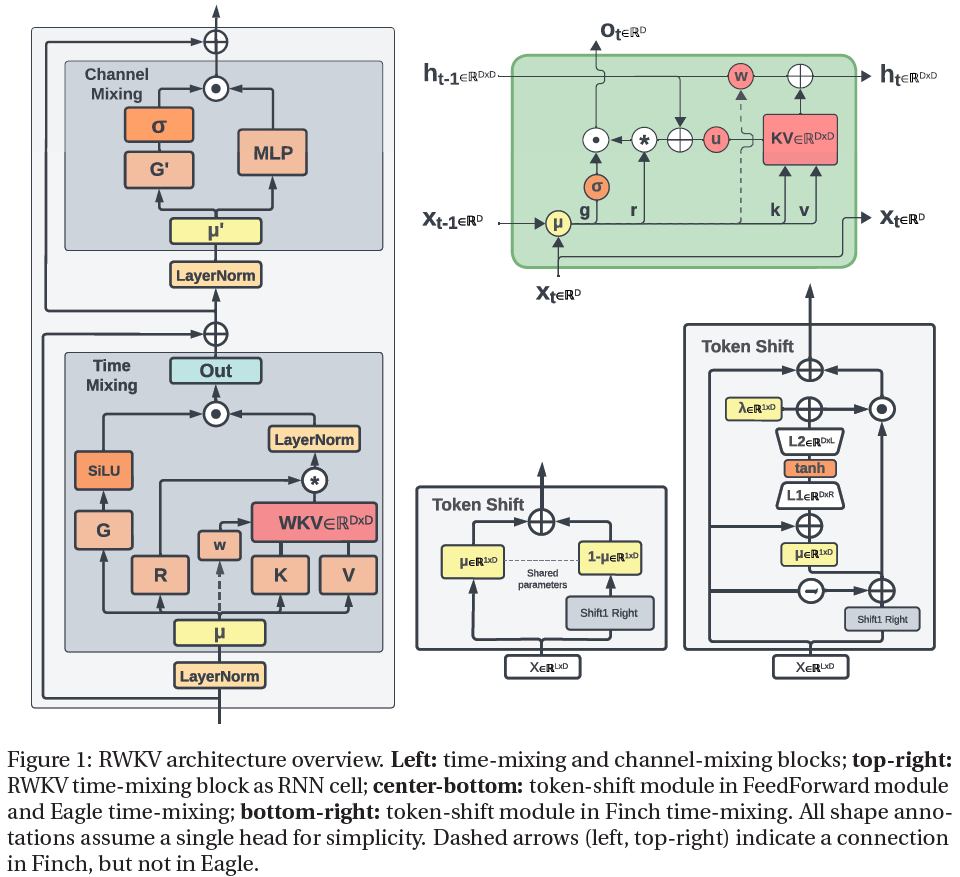
We present Eagle (RWKV-5) and Finch (RWKV-6), sequence models improving upon the RWKV (RWKV-4) architecture. Our architectural design advancements include multi-headed matrix-valued states and a dynamic recurrence mechanism that improve expressivity while maintaining the inference efficiency characteristics of RNNs. We introduce a new multilingual corpus with 1.12 trillion tokens and a fast tokenizer based on greedy matching for enhanced multilinguality. We trained four Eagle models, ranging from 0.46 to 7.5 billion parameters, and two Finch models with 1.6 and 3.1 billion parameters and find that they achieve competitive performance across a wide variety of benchmarks. We release all our models on HuggingFace under the Apache 2.0 license. Models at: https://huggingface.co/RWKV Training code at: https://github.com/RWKV/RWKV-LM Inference code at: https://github.com/RWKV/ChatRWKV Time-parallel training code at: https://github.com/RWKV/RWKV-infctx-trainer ......
StoryImager: A Unified and Efficient Framework for Coherent Story Visualization and Completion

Story visualization aims to generate a series of realistic and coherent images based on a storyline. Current models adopt a frame-by-frame architecture by transforming the pre-trained text-to-image model into an auto-regressive manner. Although these models have shown notable progress, there are still three flaws. 1) The unidirectional generation of auto-regressive manner restricts the usability in many scenarios. 2) The additional introduced story history encoders bring an extremely high computational cost. 3) The story visualization and continuation models are trained and inferred independently, which is not user-friendly. To these ends, we propose a bidirectional, unified, and efficient framework, namely StoryImager. The StoryImager enhances the storyboard generative ability inherited from the pre-trained text-to-image model for a bidirectional generation. Specifically, we introduce a Target Frame Masking Strategy to extend and unify different story image generation tasks.......
Greedy-DiM: Greedy Algorithms for Unreasonably Effective Face Morphs

Morphing attacks are an emerging threat to state-of-the-art Face Recognition (FR) systems, which aim to create a single image that contains the biometric information of multiple identities. Diffusion Morphs (DiM) are a recently proposed morphing attack that has achieved state-of-the-art performance for representation-based morphing attacks. However, none of the existing research on DiMs have leveraged the iterative nature of DiMs and left the DiM model as a black box, treating it no differently than one would a Generative Adversarial Network (GAN) or Varational AutoEncoder (VAE). We propose a greedy strategy on the iterative sampling process of DiM models which searches for an optimal step guided by an identity-based heuristic function. We compare our proposed algorithm against ten other state-of-the-art morphing algorithms using the open-source SYN-MAD 2022 competition dataset. We find that our proposed algorithm is unreasonably effective, fooling all of the tested FR system......
Hash3D: Training-free Acceleration for 3D Generation

The evolution of 3D generative modeling has been notably propelled by the adoption of 2D diffusion models. Despite this progress, the cumbersome optimization process per se presents a critical hurdle to efficiency. In this paper, we introduce Hash3D, a universal acceleration for 3D generation without model training. Central to Hash3D is the insight that feature-map redundancy is prevalent in images rendered from camera positions and diffusion time-steps in close proximity. By effectively hashing and reusing these feature maps across neighboring timesteps and camera angles, Hash3D substantially prevents redundant calculations, thus accelerating the diffusion model's inference in 3D generation tasks. We achieve this through an adaptive grid-based hashing. Surprisingly, this feature-sharing mechanism not only speed up the generation but also enhances the smoothness and view consistency of the synthesized 3D objects. Our experiments covering 5 text-to-3D and 3 image-to-3D models,......
DreamView: Injecting View-specific Text Guidance into Text-to-3D Generation

Text-to-3D generation, which synthesizes 3D assets according to an overall text description, has significantly progressed. However, a challenge arises when the specific appearances need customizing at designated viewpoints but referring solely to the overall description for generating 3D objects. For instance, ambiguity easily occurs when producing a T-shirt with distinct patterns on its front and back using a single overall text guidance. In this work, we propose DreamView, a text-to-image approach enabling multi-view customization while maintaining overall consistency by adaptively injecting the view-specific and overall text guidance through a collaborative text guidance injection module, which can also be lifted to 3D generation via score distillation sampling. DreamView is trained with large-scale rendered multi-view images and their corresponding view-specific texts to learn to balance the separate content manipulation in each view and the global consistency of the over......
3D Geometry-aware Deformable Gaussian Splatting for Dynamic View Synthesis
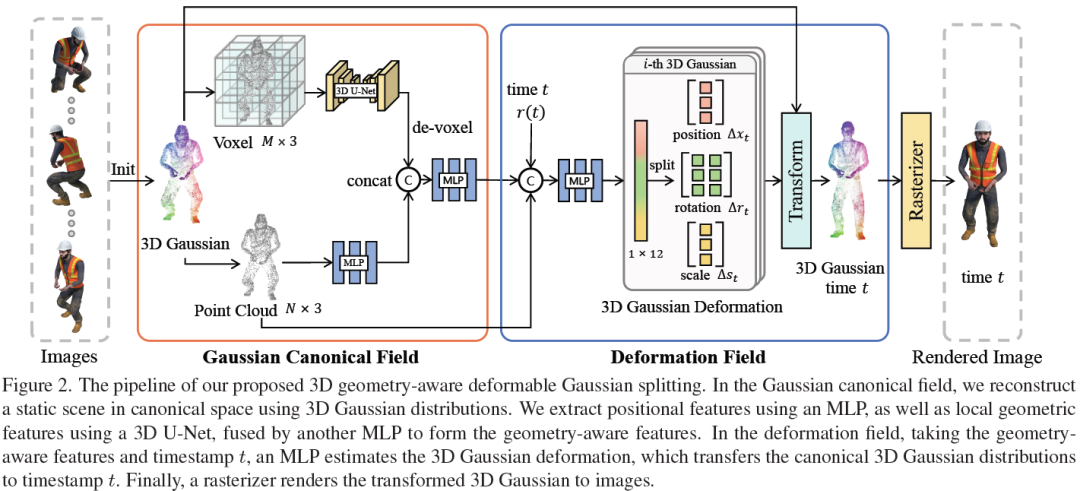
In this paper, we propose a 3D geometry-aware deformable Gaussian Splatting method for dynamic view synthesis. Existing neural radiance fields (NeRF) based solutions learn the deformation in an implicit manner, which cannot incorporate 3D scene geometry. Therefore, the learned deformation is not necessarily geometrically coherent, which results in unsatisfactory dynamic view synthesis and 3D dynamic reconstruction. Recently, 3D Gaussian Splatting provides a new representation of the 3D scene, building upon which the 3D geometry could be exploited in learning the complex 3D deformation. Specifically, the scenes are represented as a collection of 3D Gaussian, where each 3D Gaussian is optimized to move and rotate over time to model the deformation. To enforce the 3D scene geometry constraint during deformation, we explicitly extract 3D geometry features and integrate them in learning the 3D deformation. In this way, our solution achieves 3D geometry-aware deformation modeling, ......
Policy-Guided Diffusion
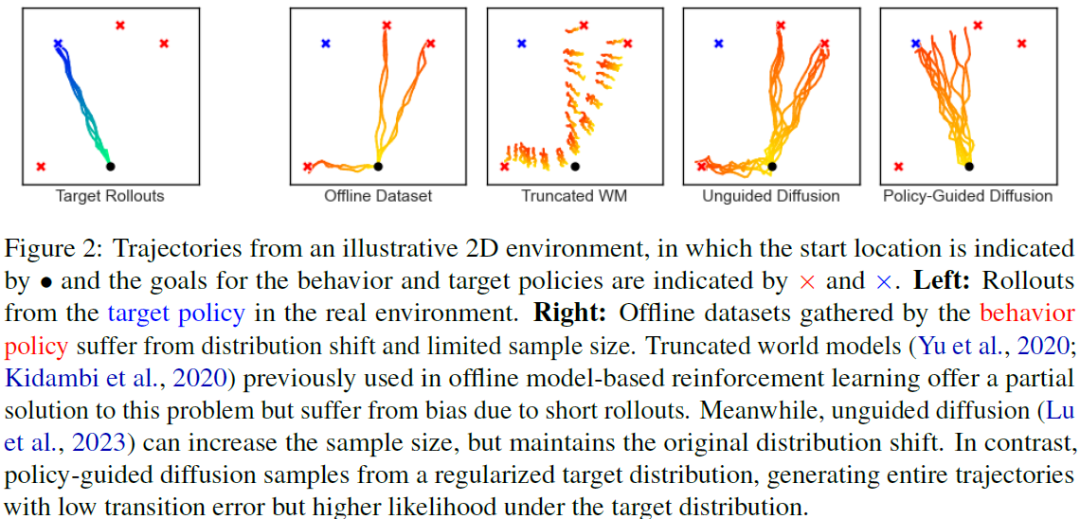
In many real-world settings, agents must learn from an offline dataset gathered by some prior behavior policy. Such a setting naturally leads to distribution shift between the behavior policy and the target policy being trained - requiring policy conservatism to avoid instability and overestimation bias. Autoregressive world models offer a different solution to this by generating synthetic, on-policy experience. However, in practice, model rollouts must be severely truncated to avoid compounding error. As an alternative, we propose policy-guided diffusion. Our method uses diffusion models to generate entire trajectories under the behavior distribution, applying guidance from the target policy to move synthetic experience further on-policy. We show that policy-guided diffusion models a regularized form of the target distribution that balances action likelihood under both the target and behavior policies, leading to plausible trajectories with high target policy probability, wh......
ZeST: Zero-Shot Material Transfer from a Single Image

We propose ZeST, a method for zero-shot material transfer to an object in the input image given a material exemplar image. ZeST leverages existing diffusion adapters to extract implicit material representation from the exemplar image. This representation is used to transfer the material using pre-trained inpainting diffusion model on the object in the input image using depth estimates as geometry cue and grayscale object shading as illumination cues. The method works on real images without any training resulting a zero-shot approach. Both qualitative and quantitative results on real and synthetic datasets demonstrate that ZeST outputs photorealistic images with transferred materials. We also show the application of ZeST to perform multiple edits and robust material assignment under different illuminations. Project Page: https://ttchengab.github.io/zest ......
Magic-Boost: Boost 3D Generation with Mutli-View Conditioned Diffusion

Benefiting from the rapid development of 2D diffusion models, 3D content creation has made significant progress recently. One promising solution involves the fine-tuning of pre-trained 2D diffusion models to harness their capacity for producing multi-view images, which are then lifted into accurate 3D models via methods like fast-NeRFs or large reconstruction models. However, as inconsistency still exists and limited generated resolution, the generation results of such methods still lack intricate textures and complex geometries. To solve this problem, we propose Magic-Boost, a multi-view conditioned diffusion model that significantly refines coarse generative results through a brief period of SDS optimization ($\sim15$min). Compared to the previous text or single image based diffusion models, Magic-Boost exhibits a robust capability to generate images with high consistency from pseudo synthesized multi-view images. It provides precise SDS guidance that well aligns with the i......
SmartControl: Enhancing ControlNet for Handling Rough Visual Conditions

Human visual imagination usually begins with analogies or rough sketches. For example, given an image with a girl playing guitar before a building, one may analogously imagine how it seems like if Iron Man playing guitar before Pyramid in Egypt. Nonetheless, visual condition may not be precisely aligned with the imaginary result indicated by text prompt, and existing layout-controllable text-to-image (T2I) generation models is prone to producing degraded generated results with obvious artifacts. To address this issue, we present a novel T2I generation method dubbed SmartControl, which is designed to modify the rough visual conditions for adapting to text prompt. The key idea of our SmartControl is to relax the visual condition on the areas that are conflicted with text prompts. In specific, a Control Scale Predictor (CSP) is designed to identify the conflict regions and predict the local control scales, while a dataset with text prompts and rough visual conditions is construc......