引言:大数据时代下的ETL挑战
随着大数据时代的到来,数据处理的规模和复杂性不断增加,尤其是在大语言模型(LLMs)的开发中,对海量数据的需求呈指数级增长。这种所谓的“规模化法则”表明,LLM的性能与数据规模直接相关。因此,为了进一步推动LLM的发展,需要更复杂的数据处理管道,即使是简单的操作也需要针对大规模数据处理进行优化。分布式系统和技术如Spark和Slurm已成为处理这些大规模数据工作负载的关键。
GPT-3.5研究测试: https://hujiaoai.cn
GPT-4研究测试: https://higpt4.cn
Claude-3研究测试(全面吊打GPT-4): https://hiclaude3.com
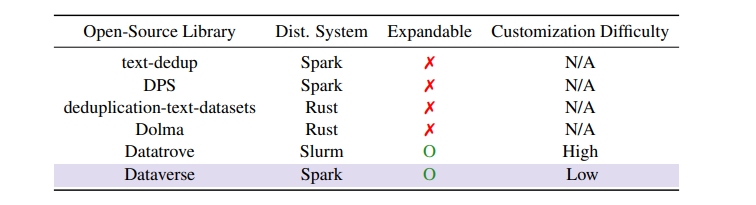
然而,现有的基于分布式系统的开源数据处理工具要么缺乏易于定制的支持,要么缺少多样化的操作。这迫使研究人员不得不经历陡峭的学习曲线,或者从不同来源拼凑工具,这阻碍了效率和用户体验。
为了应对这些限制,本篇研究提出了Dataverse,这是一个统一的开源ETL(提取、转换、加载)管道,具有用户友好的设计,使定制变得简单。Dataverse的设计原则是最小化复杂的继承结构,从而方便添加自定义数据操作。
论文标题: Dataverse: Open-Source ETL (Extract, Transform, Load) Pipeline for Large Language Models
论文链接: https://arxiv.org/pdf/2403.19340.pdf
项目链接 https://github.com/UpstageAI/dataverse
Dataverse的核心设计理念
Dataverse是一个旨在应对大规模数据处理挑战的开源ETL(提取、转换、加载)管道,它的核心设计理念是用户友好性。Dataverse的设计灵感来自Transformers库,它避免了复杂的继承结构,使得自定义数据操作的添加变得简单直观。
Dataverse的ETL管道通过基于块的接口定义,这种设计允许用户通过添加、移除或重新排列块来直观地定制ETL管道。此外,Dataverse天生支持广泛的操作,以满足多样化的数据处理用例。
Dataverse的设计选择允许用户轻松添加自定义数据操作,这是为了应对现有开源数据处理工具缺乏易于定制支持和广泛操作种类的问题。例如,去重(deduplication)、去污染(decontamination)、偏见缓解(bias mitigation)和毒性减少(toxicity reduction)等操作,这些在大规模数据处理中至关重要,但在现有工具中往往不被支持。
Dataverse通过提供一个统一的解决方案,使得用户无需寻找其他工具,即使在非常大的数据规模下也能构建完整的ETL管道。
Dataverse的关键特性
1、用户友好设计:Dataverse的用户友好设计考虑到了多个方面。
-
首先,为了构建完整的ETL管道,各种必要的工具都经过优化和统一,使得用户可以将Dataverse作为构建自定义ETL管道的独立解决方案。
-
其次,为了支持ETL管道的简单定制,Dataverse采用了通过Python装饰器添加自定义数据处理函数的简单方法。
-
此外,Dataverse支持通过Jupyter笔记本进行本地测试,这使得用户可以在扩展之前检查他们的ETL管道的各个阶段。
2、通过Spark和AWS集成的可扩展性:为了有效地扩展ETL管道,Dataverse利用了Apache Spark,实现了分布式处理能力。此外,它与亚马逊网络服务(AWS)进行了本地集成,以便更好地扩展。目前,Dataverse支持AWS S3用于云存储和Elastic MapReduce(EMR)用于数据处理。这种集成确保了没有足够本地计算资源的用户可以有效地管理他们的数据,而不会遇到严重的限制。
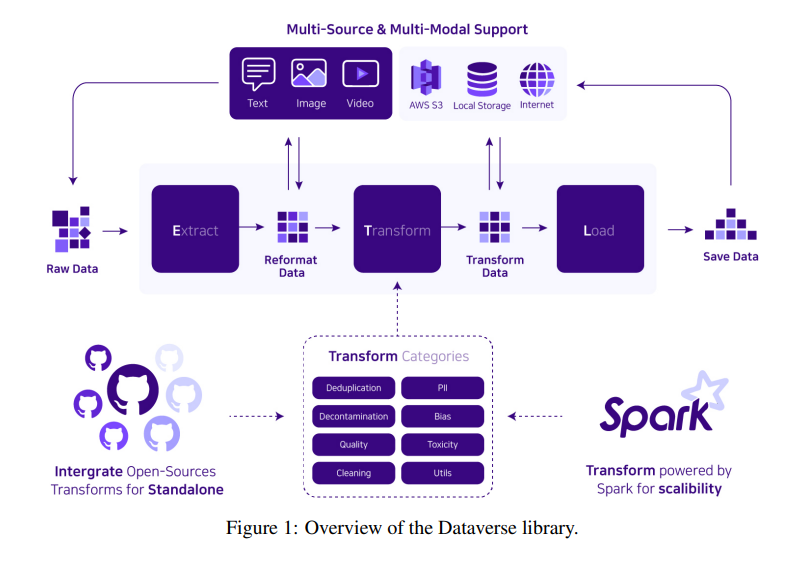
3、系统架构:Dataverse的ETL管道是用户的主要接口,它便于与配置、注册表、应用程序编程接口(API)和实用程序等各种模块进行通信。其主要目标是确保ETL管道的无缝创建和操作,有效管理数据处理任务。
此外,该接口通过简单地将“True”值传递给“emr”选项,提供了AWS EMR集成,这种直接的方法使用户能够利用云计算的可扩展性,而不需要学习分布式系统管理的陡峭曲线。
Dataverse的这些关键特性,结合其核心设计理念,使其成为一个对于快速开发大语言模型(LLM)至关重要的工具。通过开放整个库以欢迎社区贡献,Dataverse有望成为LLM数据处理的中心枢纽,促进协作、知识交流,并最终加速该领域的进步。
系统架构详解
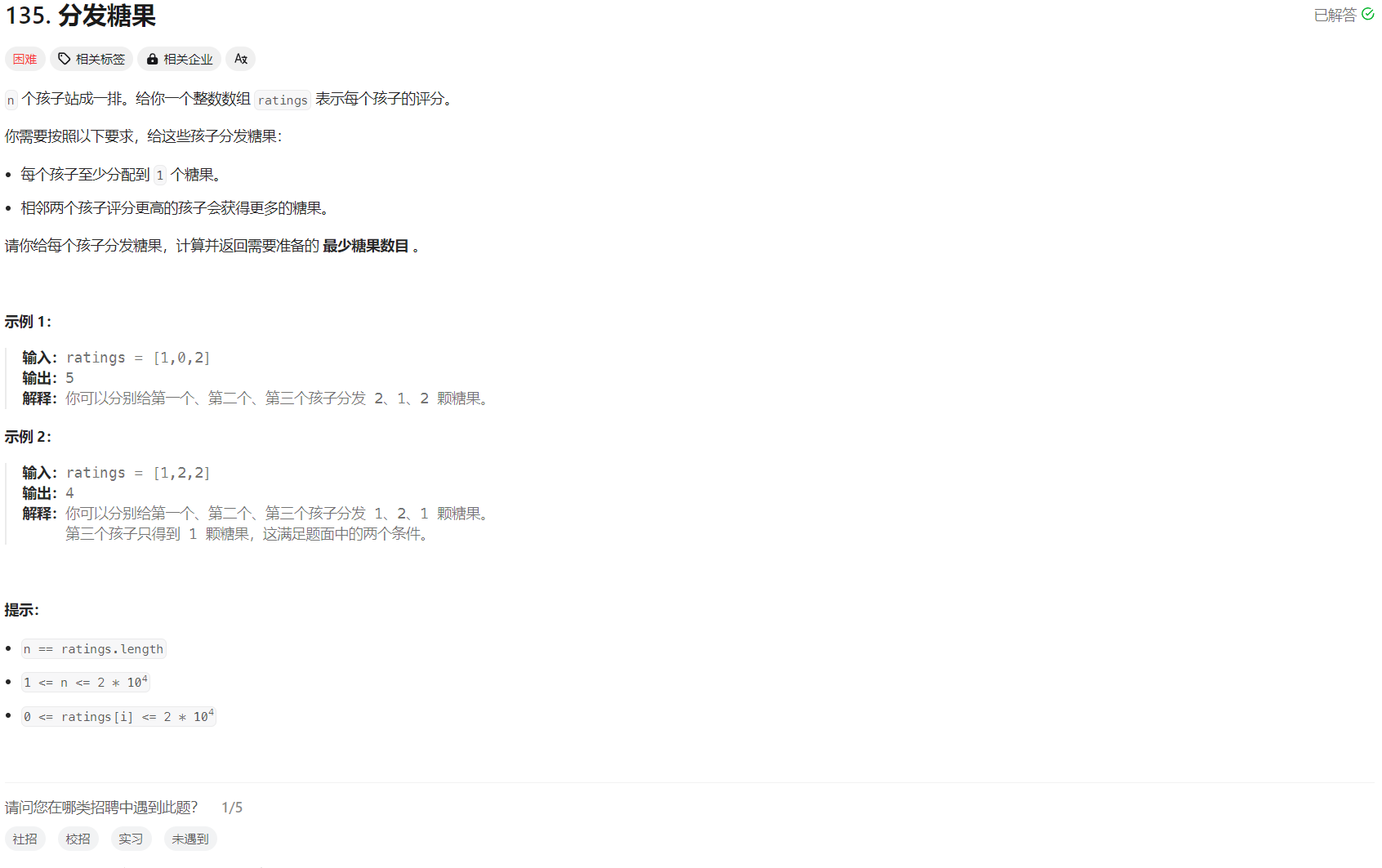
ETL是一种数据处理过程,它涉及从多个数据源提取数据,对数据进行转换处理,然后将其加载到目标存储系统中。Dataverse正是围绕这一核心过程设计的。
1. ETL管道
Dataverse的ETL管道是用户与系统交互的主要接口。它负责协调配置、注册表、应用程序编程接口(API)和实用程序等各个模块之间的通信,确保ETL管道的顺利创建和运行。此外,该接口还提供了AWS EMR集成,用户只需将“emr”选项设置为“True”,即可利用云计算的可扩展性,而无需深入了解分布式系统的管理。
2. 配置
用户需要准备一个配置对象,其中包含执行ETL管道所需的所有关键信息。配置对象的作用是设置Apache Spark的规格,并选择要使用的数据处理器。
3. 配置管理器
配置管理器负责管理来自指定路径(本地、AWS S3)的各种配置,或处理多种类型(Python Dict、YAML、OmegaConf)的配置数据。它将这些配置转换为与Dataverse兼容的统一格式,以便在系统中使用。
4. 注册表
注册表是存储所有数据处理器函数的仓库。配置中指定的数据处理器将从注册表中检索出来,以组装所需的ETL管道。值得注意的是,用户可以通过使用@register_etl装饰器简单地添加自定义数据处理器。注册表中原生支持的数据处理器包括数据摄取、数据保存、去重、数据清洗、个人身份信息(PII)移除、数据质量提升、偏见缓解和毒性内容移除等。
5. 实用程序
实用程序模块是内部辅助工具集。其核心特性之一是API实用程序,它简化了AWS EMR等外部API的使用。通过设置AWS凭证,Dataverse自动处理EMR集群的配置和管理,简化了研究人员对云基础设施的复杂操作。
6. Dataverse API
Dataverse API是用户的入口。目前,Dataverse支持Python命令行界面(CLI),并且正在开发Bash CLI。
实现大规模数据处理的技术
在大数据时代,处理海量数据带来了巨大的挑战。随着大型语言模型(LLMs)的出现,对大规模数据集的需求日益增长,这使得分布式处理成为了不可或缺的需求。Dataverse采用了开源工具如Slurm和Spark来实现多节点和多进程环境,以应对巨大的计算需求。
1. 分布式处理
Dataverse利用Apache Spark实现分布式处理能力,允许数据处理工作负载在多个节点之间分配。此外,Dataverse还与亚马逊网络服务(AWS)集成,通过AWS S3进行云存储,通过Elastic MapReduce(EMR)进行数据处理,从而实现更大的可扩展性。这些特性可以通过简单地更改配置或在运行ETL管道时添加参数来启用。
2. 数据质量控制
在大规模数据处理中,确保数据质量是一项艰巨的任务。Dataverse实现了一系列数据质量提升策略,其中去重尤为关键。即使使用高质量的数据集,也可能遇到重复数据的问题,因为可能会合并多个来源的数据。
此外,去除数据集中意外包含的基准测试或其他非预期数据(称为去污染),以及删除过短或过长的句子,对于保持数据完整性也至关重要。
3. ETL(提取、转换、加载)
Dataverse的ETL步骤包括从多个来源提取原始数据(提取),通过去重和清洗等过程对数据进行处理(转换),最后将处理后的数据传输到所选的存储目的地(加载)。这些步骤共同实现了从多源数据的端到端处理。
在大规模数据的背景下,Dataverse仍然依赖于批处理,因为在准备LLM数据时,准确性和质量比速度更为重要。通过全局评估,包括去重和确保平衡视角以避免偏见,Dataverse旨在提供高质量和可靠的数据,而不是仅仅利用数据的大量涌入。
ETL过程的三个步骤
1. 提取(Extract)
提取步骤是ETL过程的起点,它涉及从多个来源获取原始数据并准备进行处理。在Dataverse中,这一步骤的实现是通过数据摄取模块完成的,它支持从不同的数据源(例如Huggingface Hub、本地存储中的parquet/csv/arrow格式数据)加载数据,并将其转换成所需的格式。这一步骤的关键在于能够高效地处理和转换原始数据,为后续的转换和加载步骤打下基础。
2. 转换(Transform)
转换步骤是ETL过程中的核心,它涉及对数据进行一系列的处理操作,以提高数据的质量和可用性。Dataverse支持多种数据处理操作,包括数据去重、数据清洗、去除个人身份信息(PII)、数据质量提升、偏见缓解和毒性内容移除等。这些操作有助于确保数据集的准确性、一致性和可靠性,从而为大语言模型(LLMs)提供高质量的训练数据。
3. 加载(Load)
加载步骤是ETL过程的最后一步,它负责将处理后的数据传输到选择的存储目的地。Dataverse中的数据保存模块支持将处理后的数据持久化到数据湖或数据库等目的地。这一步骤确保了数据可以被有效地存储和检索,为数据的进一步使用和分析提供了便利。
Dataverse的实际应用案例
Dataverse作为一个开源的ETL管道库,它的设计核心是用户友好性,使得用户可以轻松地定制自己的ETL管道。Dataverse的实际应用案例包括:
-
数据去重: Dataverse提供了数据去重功能,可以在数据集之间或跨多个数据集全局地消除重复数据,这对于维护数据集的完整性和减少冗余至关重要。
-
数据清洗: 通过移除数据中的无关、冗余或噪声信息,例如停用词或特殊字符,Dataverse帮助用户清洗数据,提升数据的质量。
-
PII移除: Dataverse能够确保从数据集中移除敏感信息,如个人身份信息,这对于遵守隐私保护法规和减少数据泄露风险非常重要。
-
数据质量提升: Dataverse支持从准确性、一致性和可靠性的角度提高数据质量,这对于LLMs的训练至关重要。
-
偏见缓解: 通过减少数据中的偏见,特别是对LLMs加强刻板印象的数据,Dataverse有助于创建更公正和无偏见的数据集。
-
毒性内容移除: Dataverse能够识别并消除数据中的有害、攻击性或不当内容,这对于创建安全和健康的数据环境至关重要。
Dataverse通过其模块化和可扩展的设计,使得用户可以根据自己的需求添加、移除或重新排列数据处理模块,从而轻松地构建和测试定制的ETL管道。此外,Dataverse的分布式处理能力和与AWS的集成,使得它能够有效地处理大规模数据集,满足不同规模用户的需求。
面向未来的Dataverse
在大数据处理的挑战中,Dataverse作为一个统一的开源ETL(提取、转换、加载)管道,为大语言模型(LLMs)的开发提供了一个用户友好的设计核心。Dataverse的区块化界面使得用户可以轻松、高效地添加自定义处理器,以构建他们自己的ETL管道。
1. 分布式处理与未来的可扩展性
Dataverse利用Spark实现了数据处理工作负载的分布式处理,仅需通过设置必要的配置即可。此外,Dataverse还支持多源数据摄取,包括本地存储、云平台和网络抓取,使用户能够轻松地从各种来源转换原始数据。这些特性驱动了Dataverse成为一个有用的工具,用于轻松构建大规模的定制ETL管道,以快速开发LLM。
2. 社区贡献与持续改进
Dataverse鼓励社区参与,提供了指导和流程以确保库的适应性和时效性。通过这种方式,Dataverse不仅是一个静态的库,而是一个设计上能够随时间成长和适应的动态、进化的库。Dataverse的设计原则是最小化复杂的继承结构,从而使添加自定义数据操作变得容易。
3. 未来的发展方向
尽管Dataverse目前的实现已经支持文本数据,但我们计划在未来的版本中加入对图像和视频的支持,以保持与新兴研究趋势和不断变化的需求一致。此外,我们还计划增加一个自动配置功能,以合理地最大化Spark的性能和可扩展性。我们还承认,LLMs可能会反映其训练数据中存在的偏见,因此Dataverse纳入了偏见缓解技术,但仍需要持续监控和改进。
论文总结与未来展望
Dataverse作为一个开源的ETL管道库,旨在应对因LLMs的流行而激增的大规模数据处理需求。它以用户友好的区块化界面设计,使用户能够轻松添加自定义数据处理功能,同时也原生支持广泛使用的数据操作。此外,Dataverse通过与Spark和AWS EMR的无缝集成,提供了可扩展的解决方案,使用户能够处理不同规模的数据工作负载。我们设想Dataverse将成为LLM数据处理的中心枢纽,促进合作、知识交流,并最终加速该领域的进步。
1. 优化和性能调整
Dataverse基于Spark的架构需要经验丰富的数据工程师进行调优和优化,以实现最佳性能和可扩展性。虽然已经实现了合理的默认设置,但当前版本可能还没有完全释放Spark的潜力。
2. 应对偏见和隐私问题
认识到LLMs可能会在其训练数据中反映出的偏见,可能会产生关于种族、性别和年龄等方面的偏斜结果。尽管Dataverse纳入了偏见缓解技术,但仍需要持续监控和改进。此外,收集大量数据集也引发了隐私和版权问题。Dataverse旨在通过匿名化和过滤最大限度地减少这些风险,但在整个数据获取和处理管道中仍需保持警惕。
3. 伦理挑战和社会风险
研究者们深知在开发Dataverse时面临的伦理挑战。我们致力于不断增强Dataverse的能力,以解决偏见、隐私和潜在滥用问题。目标是提供一个强大的工具,以推进语言AI的发展,同时坚持强有力的伦理原则,并尽可能减少社会风险。