3D-Aware Multi-Class Image-to-Image Translation with NeRFs
利用NeRFs实现3D感知的多类图像到图像的翻译
李森茂 1 范德维杰 2 王亚兴 1
Fahad Shahbaz Khan3,4 Meiqin Liu5 Jian Yang1
法哈德·夏巴兹·汗 3,4 刘梅琴 5 简阳 1
1VCIP,CS, Nankai University, 2Universitat Autònoma de Barcelona
1 VCIP,CS,南开大学, 2 巴塞罗那自治大学
3Mohamed bin Zayed University of AI, 4Linkoping University, 5Beijing Jiaotong University
3 穆罕默德·本·扎耶德艾大学 4 林雪平大学 5 北京交通大学
senmaonk@gmail.com {yaxing,csjyang}@nankai.edu.cn joost@cvc.uab.es
senmaonk@gmail.com {yaxing,csjyang}@ joost@cvc.uab.es
fahad.khan@liu.se mqliu@bjtu.edu.cn
fahad. liu.se mqliu@bjtu.edu.cnThe corresponding author.
通讯作者。
Abstract 摘要
Recent advances in 3D-aware generative models (3D-aware GANs) combined with Neural Radiance Fields (NeRF) have achieved impressive results. However no prior works investigate 3D-aware GANs for 3D consistent multi-class image-to-image (3D-aware I2I) translation. Naively using 2D-I2I translation methods suffers from unrealistic shape/identity change. To perform 3D-aware multi-class I2I translation, we decouple this learning process into a multi-class 3D-aware GAN step and a 3D-aware I2I translation step. In the first step, we propose two novel techniques: a new conditional architecture and an effective training strategy. In the second step, based on the well-trained multi-class 3D-aware GAN architecture, that preserves view-consistency, we construct a 3D-aware I2I translation system. To further reduce the view-consistency problems, we propose several new techniques, including a U-net-like adaptor network design, a hierarchical representation constrain and a relative regularization loss. In extensive experiments on two datasets, quantitative and qualitative results demonstrate that we successfully perform 3D-aware I2I translation with multi-view consistency. Code is available in 3DI2I.
3D感知生成模型(3D感知GAN)与神经辐射场(NeRF)相结合的最新进展取得了令人印象深刻的结果。然而,没有先前的作品研究3D感知GAN用于3D一致的多类图像到图像(3D感知I2 I)转换。天真地使用2D-I2 I转换方法会遭受不切实际的形状/身份改变。为了执行3D感知的多类I2 I翻译,我们将此学习过程解耦为多类3D感知的GAN步骤和3D感知的I2 I翻译步骤。在第一步中,我们提出了两个新的技术:一个新的条件架构和一个有效的训练策略。在第二步中,基于训练良好的多类3D感知GAN架构,保持视图一致性,我们构建了一个3D感知I2 I翻译系统。为了进一步减少视图一致性问题,我们提出了几种新的技术,包括一个U-网一样的适配器网络设计,分层表示约束和相对正则化损失。 在两个数据集上进行的大量实验中,定量和定性结果表明,我们成功地执行了具有多视图一致性的3D感知I2 I翻译。代码在3DI 2 I中可用。
![[Uncaptioned image]](https://img-blog.csdnimg.cn/img_convert/977ff2cd8f427e00efa7e996270b2bfc.png)
Figure 1: 3D-aware I2I translation: given a view-consistent 3D scene (the input), our method maps it into a high-quality target-specific image. Our approach produces consistent results across viewpoints.
图1:3D感知的I2 I转换:给定视图一致的3D场景(输入),我们的方法将其映射到高质量的目标特定图像。我们的方法在不同的视角下产生一致的结果。
1Introduction 一、导言
Neural Radiance Fields (NeRF) have increasingly gained attention with their outstanding capacity to synthesize high-quality view-consistent images [41, 32, 68]. Benefiting from the adversarial mechanism [12], StyleNeRF [13] and concurrent works [46, 5, 9, 71] have successfully synthesized high-quality view-consistent, detailed 3D scenes by combining NeRF with StyleGAN-like generator design [23]. This recent progress in 3D-aware image synthesis has not yet been extended to 3D-aware I2I translation, where the aim is to translate in a 3D-consistent manner from a source scene to a target scene of another class (see Figure 1).
神经辐射场(NeRF)因其合成高质量视图一致图像的出色能力而日益受到关注[ 41,32,68]。受益于对抗机制[ 12],StyleNeRF [ 13]和并发作品[46,5,9,71]通过将NeRF与StyleGAN类生成器设计相结合[ 23],成功合成了高质量的视图一致的详细3D场景。3D感知图像合成的最新进展尚未扩展到3D感知I2I转换,其目标是以3D一致的方式从源场景转换到另一类目标场景(见图1)。
A naive strategy is to use well-designed 2D-I2I translation methods [17, 48, 72, 16, 29, 67, 27, 65]. These methods, however, suffer from unrealistic shape/identity changes when changing the viewpoint, which are especially notable when looking at a video. Main target class characteristics, such as hairs, ears, and noses, are not geometrically realistic, leading to unrealistic results which are especially disturbing when applying I2I to translate videos. Also, these methods typically underestimate the viewpoint change and result in target videos with less viewpoint change than the source video. Another direction is to apply video-to-video synthesis methods [55, 2, 3, 7, 31]. These approaches, however, either rely heavily on labeled data or multi-view frames for each object. In this work, we assume that we only have access to single-view RGB data.
一种简单的策略是使用精心设计的2D-I2 I翻译方法[ 17,48,72,16,29,67,27,65]。然而,这些方法在改变视点时遭受不切实际的形状/身份改变,这在观看视频时尤其显著。主要目标类别特征,如头发、耳朵和鼻子,在几何上并不真实,导致不切实际的结果,这在应用I2 I翻译视频时尤其令人不安。此外,这些方法通常低估了视点变化,并且导致目标视频具有比源视频更少的视点变化。另一个方向是应用视频到视频合成方法[ 55,2,3,7,31]。然而,这些方法严重依赖于标记数据或每个对象的多视图帧。在这项工作中,我们假设我们只能访问单视图RGB数据。
To perform 3D-aware I2I translation, we extend the theory developed for 2D-I2I with recent developments in 3D-aware image synthesis. We decouple the learning process into a multi-class 3D-aware generative model step and a 3D-aware I2I translation step. The former can synthesize view-consistent 3D scenes given a scene label, thereby addressing the 3D inconsistency problems we discussed for 2D-I2I. We will use this 3D-aware generative model to initialize our 3D-aware I2I model. It therefore inherits the capacity of synthesizing 3D consistent images. To train effectively a multi-class 3D-aware generative model (see Figure 2(b)), we provide a new training strategy consisting of: (1) training an unconditional 3D-aware generative model (i.e., StyleNeRF) and (2) partially initializing the multi-class 3D-aware generative model (i.e., multi-class StyleNeRF) with the weights learned from StyleNeRF. In the 3D-aware I2I translation step, we design a 3D-aware I2I translation architecture (Figure 2(f)) adapted from the trained multi-class StyleNeRF network. To be specific, we use the main network of the pretrained discriminator (Figure 2(b)) to initialize the encoder � of the 3D-aware I2I translation model (Figure 2(f)), and correspondingly, the pretrained generator (Figure 2(b)) to initialize the 3D-aware I2I generator (Figure 2(f)). This initialization inherits the capacity of being sensitive to the view information.
为了执行3D感知I2 I翻译,我们扩展了为2D-I2 I开发的理论,其中包括3D感知图像合成的最新发展。我们将学习过程解耦为多类3D感知生成模型步骤和3D感知I2 I翻译步骤。前者可以在给定场景标签的情况下合成视图一致的3D场景,从而解决我们针对2D-I2 I讨论的3D不一致问题。我们将使用此3D感知生成模型来初始化我们的3D感知I2 I模型。因此,它继承了合成3D一致图像的能力。为了有效地训练多类3D感知生成模型(参见图2(B)),我们提供了一种新的训练策略,包括:(1)训练无条件3D感知生成模型(即,StyleNeRF)和(2)部分地初始化多类3D感知生成模型(即,多类StyleNeRF),其权重从StyleNeRF学习。 在3D感知I2I转换步骤中,我们设计了一个3D感知I2I转换架构(图2(f)),该架构改编自经过训练的多类StyleNeRF网络。具体来说,我们使用预训练的I2I的主网络(图2(b))来初始化3D感知I2I转换模型的编码器 � (图2(f)),相应地,使用预训练的生成器(图2(b))来初始化3D感知I2I生成器(图2(f))。这种初始化继承了对视图信息敏感的能力。
Directly using the constructed 3D-aware I2I translation model (Figure 2(f)), there still exists some view-consistency problem. This is because of the lack of multi-view consistency regularization, and the usage of the single-view image. Therefore, to address these problems we introduce several techniques, including a U-net-like adaptor network design, a hierarchical representation constrain and a relative regularization loss.
直接使用构建的3D感知I2I转换模型(图2(f)),仍然存在一些视图一致性问题。这是因为缺乏多视点一致性正则化,以及使用了单视点图像。因此,为了解决这些问题,我们引入了几种技术,包括一个U型网络的适配器网络设计,分层表示约束和相对正则化损失。
In sum, our work makes the following contributions:
总之,我们的工作作出了以下贡献:
- •
We are the first to explore 3D-aware multi-class I2I translation, which allows generating 3D consistent videos.
·我们是第一个探索3D感知的多类I2 I翻译的公司,它允许生成3D一致的视频。 - •
We decouple 3D-aware I2I translation into two steps. First, we propose a multi-class StyleNeRF. To train this multi-class StyleNeRF effectively, we provide a new training strategy. The second step is the proposal of a 3D-aware I2I translation architecture.
·我们将3D感知的I2 I转换解耦为两个步骤。首先,我们提出了一个多类的StyleNeRF。为了有效地训练这种多类StyleNeRF,我们提供了一种新的训练策略。第二步是提出一个3D感知的I2 I转换架构。 - •
To further address the view-inconsistency problem of 3D-aware I2I translation, we propose several techniques: a U-net-like adaptor, a hierarchical representation constraint and a relative regularization loss.
·为了进一步解决3D感知I2 I翻译的视图不一致问题,我们提出了几种技术:U形网络适配器,分层表示约束和相对正则化损失。 - •
On extensive experiments, we considerably outperform existing 2D-I2I systems with our 3D-aware I2I method when evaluating temporal consistency.
·在广泛的实验中,我们在评估时间一致性时,使用3D感知I2 I方法大大优于现有的2D-I2 I系统。
2Related Works 2相关作品
Neural Implicit Fields. Using neural implicit fields to represent 3D scenes has shown unprecedented quality. [40, 39, 47, 50, 53, 45] use 3D supervision to predict neural implicit fields. Recently, NeRF has shown powerful performance to neural implicit representations. NeRF and its variants [41, 32, 68] utilize a volume rendering technique for reconstructing a 3D scene as a combination of neural radiance and density fields to synthesize novel views.
神经隐式场使用神经隐式场来表示3D场景已经显示出前所未有的质量。[40,39,47,50,53,45]使用3D监督来预测神经内隐场。最近,NeRF已经显示出强大的性能,神经隐式表示。NeRF及其变体[41,32,68]利用体绘制技术重建3D场景,作为神经辐射和密度场的组合,以合成新视图。
3D-aware GANs Recent approaches [42, 6, 44, 43, 36, 14, 10, 20, 64, 70, 54] learn neural implicit representations without 3D or multi-view supervisions. Combined with the adversarial loss, these methods typically randomly sample viewpoints, render photorealistic 2D images, and finally optimize their 3D representations. StyleNeRF [13] and concurrent works [46, 5, 9, 71] have successfully synthesized high-quality view-consistent, detailed 3D scenes with StyleGAN-like generator design [23]. In this paper, we investigate 3D-aware image-to-image (3D-aware I2I) translation, where the aim is to translate in a 3D-consistent manner from a source scene to a target scene of another class. We combine transfer learning of GANs [62, 57].
最近的方法[ 42,6,44,43,36,14,10,20,64,70,54]在没有3D或多视图监督的情况下学习神经隐式表示。结合对抗性损失,这些方法通常随机采样视点,渲染逼真的2D图像,并最终优化其3D表示。StyleNeRF [ 13]和并发作品[46,5,9,71]已经成功地合成了高质量的视图一致性,详细的3D场景与StyleGAN类似的生成器设计[ 23]。在本文中,我们研究3D感知图像到图像(3D感知I2I)的翻译,其目的是在3D一致的方式从源场景到另一类的目标场景翻译。我们结合了GAN的联合收割机迁移学习[62,57]。
I2I translation. I2I translation with GAN [17, 61, 63, 59] has increasingly gained attention in computer vision. Based on the differences of the I2I translation task, recent works focus on paired I2I translation [11, 17, 73], unpaired I2I translation [25, 33, 38, 48, 66, 72, 65, 52, 1, 19, 58, 60, 28], diverse I2I translation [25, 33, 38, 48, 66, 72] and scalable I2I translation [8, 30, 67].
I2I翻译。使用GAN的I2I翻译[17,61,63,59]在计算机视觉中越来越受到关注。基于I2I翻译任务的差异,最近的工作集中在配对I2I翻译[ 11,17,73],非配对I2I翻译[ 25,33,38,48,66,72,65,52,1,19,58,60,28],多样I2I翻译[ 25,33,38,48,66,72]和可扩展的I2I转换[8,30,67]。
However, none of these approaches addresses the problem of 3D-aware I2I. For the 3D scenes represented by neural implicit fields, directly using these methods suffers from view-inconsistency.
然而,这些方法都没有解决3D感知I2I的问题。对于用神经隐场表示的三维场景,直接使用这些方法会产生视图不一致性。
3Method 3方法
Problem setting. Our goal is to achieve 3D consistent multi-class I2I translation trained on single-view data only. The system is designed to translate a viewpoint-video consisting of multiple images (source domain) into a new, photorealistic viewpoint-video scene of a target class. Furthermore, the system should be able to handle multi-class target domains. We decouple our learning into a multi-class 3D-aware generative model step and a multi-class 3D-aware I2I translation step.
问题设置。我们的目标是实现仅在单视图数据上训练的3D一致的多类I2I翻译。该系统的目的是将由多个图像(源域)组成的视点视频转换为目标类的新的、照片级逼真的视点视频场景。此外,系统应该能够处理多类目标域。我们将学习解耦为多类3D感知生成模型步骤和多类3D感知I2I翻译步骤。
3.1Multi-class 3D-aware generative model
3.1多类3D感知生成模型
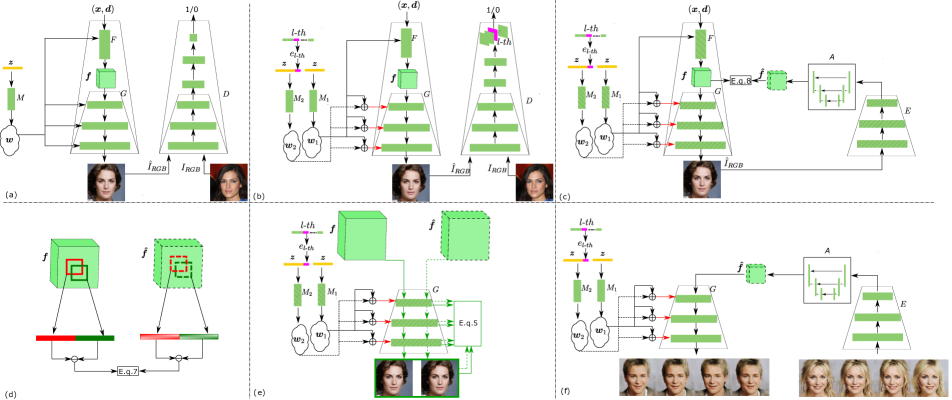
Figure 2:Overview of our method. (a) We first train a 3D-aware generative mode (i.e., StyleNeRF) with single-view photos. (b) We extend StyleNerf to multi-class StyleNerf. We introduce an effective training strategy: initializing multi-class StyleNeRF with StyleNeRF. (c) The training of the proposed 3D-aware I2I translation. It consists of the encoder �, the adaptor �, the generator � and two mapping networks �1 and �2. We freeze all networks except for training the adaptor �. The encoder is initialized by the main networks of the pretrained discriminator. We introduce several techniques to address the view-consistency problems: including a U-net-like adaptor �, (d) relative regularization loss and (e) hierarchical representation constrain. (f) Usage of proposed model at inference time.
图2:我们的方法概述。(a)我们首先训练3D感知生成模式(即,StyleNeRF)与单视图照片。(b)我们将StyleNerf扩展为多类StyleNerf。我们介绍了一种有效的训练策略:使用StyleNeRF初始化多类StyleNeRF。(c)建议的3D感知I2 I翻译的培训。它由编码器 � 、适配器 � 、生成器 � 和两个映射网络 �1 和 �2 组成。我们冻结所有网络,除了训练适配器 � 。编码器由预训练的编码器的主网络初始化。我们介绍了几种技术来解决视图一致性问题:包括一个U-网一样的适配器 � ,(d)相对正则化损失和(e)分层表示约束。(f)在推理时使用所提出的模型。
Let ℐℛ𝒢ℬ∈ℝ�×�×3 be in the image domain. In this work, we aim to map a source image into a target sample conditioned on the target domain label 𝒍∈{1,…,�} and a random noise vector 𝐳∈ℝ𝐙. Let vector 𝒙 and 𝒅 be 3D location and 2D viewing direction, respectively.
让 ℐℛ𝒢ℬ∈ℝ�×�×3 在图像域中。在这项工作中,我们的目标是将源图像映射到以目标域标签 𝒍∈{1,…,�} 和随机噪声向量 𝐳∈ℝ𝐙 为条件的目标样本。假设矢量 𝒙 和 𝒅 分别是3D位置和2D观看方向。
Unconditional 3D-aware generative model. StyleNeRF [13] introduces a 5D function (3D location 𝒙 and 2D viewing direction 𝒅) to predict the volume density � and RGB color 𝒄. Both � and 𝒄 are further used to render an image. As shown on Figure 2(a) StyleNeRF consists of four subnetworks: a mapping network �, a fully connected layer �, a generator � and a discriminator �. The mapping network � takes random noise 𝒛 as input, and outputs latent code 𝒘, which is further fed into both the fully connected layer � and generator �. Given the 3D location 𝒙, the 2D viewing direction 𝒅 and latent code 𝒘, StyleNeRF renders the feature map 𝒇:
无条件3D感知生成模型。StyleNeRF [ 13]引入了5D函数(3D位置 𝒙 和2D观察方向 𝒅 )来预测体积密度 � 和RGB颜色 𝒄 。 � 和 𝒄 都进一步用于渲染图像。如图2(a)所示,StyleNeRF由四个子网组成:映射网络 � ,全连接层 � ,生成器 � 和路由器 � 。映射网络 � 将随机噪声 𝒛 作为输入,并且输出潜码 𝒘 ,潜码 𝒘 被进一步馈送到全连接层 � 和生成器 � 两者。给定3D位置 𝒙 、2D观看方向 𝒅 和潜在代码 𝒘 ,StyleNeRF呈现特征图 𝒇 :
| 𝒇(𝒓)=∫0∞�(�)𝒄(𝒓(�),𝒅)𝑑� | (1) | |||
| �(�)=exp(−∫0��(𝒓(�))𝑑�)⋅�𝒘(𝒓(�)) | ||||
| 𝒄,�=�(𝒙,𝒅,𝒘), |
where 𝒓(�)=𝒐+�𝒅 (𝒐 is the camera origin) is a camera ray for each feature representation position. Generator � takes as an input the representation 𝒇 and the latent code 𝒘, and outputs view-consistent photo-realistic novel result �^���. The discriminator � is to distinguish real images ���� from generated images �^���.
其中 𝒓(�)=𝒐+�𝒅 ( 𝒐 是相机原点)是用于每个特征表示位置的相机射线。生成器 � 将表示 𝒇 和潜在码 𝒘 作为输入,并输出视图一致的照片般真实的小说结果 �^��� 。图像 � 用于区分真实的图像 ���� 和生成的图像 �^��� 。
The fully objective of StyleNeRF is as following:
StyleNeRF的全部目标如下:
| ℒ�=𝔼𝒛∼𝒵,𝒑∼𝒫[�(�(�(�(𝒛,𝒙,𝒅),�(𝒛)))] | (2) | |||
| +𝔼����∼�data[�(−�(����)+�‖∇�(����)‖2)] | ||||
| +�⋅ℒNeRF-path |
where �(�)=−log(1+exp(−�)), and �data is the data distribution. ℒNeRF-path is NeRF path regularization used in StyleNeRF. We also set �=0.2 and �=0.5 following StyleNeRF.
其中 �(�)=−log(1+exp(−�)) 和 �data 是数据分布。 ℒNeRF-path 是StyleNeRF中使用的NeRF路径正则化。我们还在StyleNeRF之后设置了 �=0.2 和 �=0.5 。
Conditional 3D-aware generative model.
条件3D感知生成模型。
Figure 2(b) shows the proposed multi-class 3D-aware generative model (i.e., multi-class StyleNeRF). Compared to the StyleNeRF architecture (Figure 2(a)), we introduce two mapping networks: �1 and �2. The mapping network �1 outputs the latent code 𝒘1. While the mapping network �2 takes as input the concatenated noise 𝒛 and class embedding �𝒍-�ℎ, and outputs the latent code 𝒘2. The second mapping network �2 aims to guide the generator � to synthesize a class-specific image. Here we do not feed the latent code 𝒘2 into NeRF’s fully connected layer �, since we expect � to learn a class-agnostic feature representation, which contributes to perform multi-class 3D-aware I2I translation.
图2(B)示出了所提出的多类3D感知生成模型(即,多类StyleNeRF)。与StyleNeRF架构(图2(a))相比,我们引入了两个映射网络: �1 和 �2 。映射网络 �1 输出潜在码 𝒘1 。而映射网络 �2 将级联噪声 𝒛 和类嵌入 �𝒍-�ℎ 作为输入,并输出潜码 𝒘2 。第二映射网络 �2 旨在引导生成器 � 合成类特定图像。在这里,我们没有将潜在代码 𝒘2 馈送到NeRF的全连接层 � 中,因为我们期望 � 学习类不可知的特征表示,这有助于执行多类3D感知I2I转换。
To be able to train multi-class StyleNeRF we adapt the loss function. We require � to address multiple adversarial classification tasks simultaneously, as in [34]. Specifically, given output �∈ℝ�, we locate the 𝒍-�ℎ class response.
为了能够训练多类StyleNeRF,我们调整了损失函数。我们需要 � 同时处理多个对抗分类任务,如[ 34]所示。具体来说,给定输出 �∈ℝ� ,我们定位 𝒍-�ℎ 类响应。
Using the response for the 𝒍-�ℎ class, we compute the adversarial loss and back-propagate gradients:
使用 𝒍-�ℎ 类的响应,我们计算对抗损失和反向传播梯度:
| ℒ��=𝔼𝒛∼𝒵,𝒙∼𝒫�,𝒅∼𝒫�[�(�(�(�^���))𝒍-�ℎ] | (3) | |||
| +𝔼����∼�data[�(−�(����)𝒍-�ℎ+�‖∇�(����)��ℎ‖2)] | ||||
| +�⋅ℒNeRF-path. |
We initialize the multi-class StyleNeRF with the weights learned with the unconditional StyleNeRF (E.q. LABEL:eq:uncon_nerf), since the training from scratch fails to convergence. Results of this are show in Figs. 7. To be specific, we directly copy the weights from the one learned from StyleNeRF for �1, � and � with the same parameter size. For the mapping network �2, we duplicate the weight from � except for the first layer, which is trained from scratch because of the different parameter sizes. The discriminator is similarly initialized except for the last layer, which is a new convolution layer with � output channels. Using the proposed initialization method, we successfully generate class-specific photorealistic high-resolution result.
我们用用无条件StyleNeRF学习的权重初始化多类StyleNeRF(E.q. LABEL:eq:uncon_nerf),因为从头开始的训练无法收敛。其结果示于图1A和1B中。7.具体来说,我们直接从StyleNeRF中学习的权重中复制 �1 , � 和 � 的权重,参数大小相同。对于映射网络 �2 ,我们从 � 复制权重,除了第一层,由于参数大小不同,第一层是从头开始训练的。除了最后一层之外,卷积层的初始化类似,最后一层是具有 � 输出通道的新卷积层。使用所提出的初始化方法,我们成功地产生类特定的真实感高分辨率的结果。
3.23D-aware I2I translation
3. 23D感知的I2I翻译
Figure 2 (f) shows the 3D-aware I2I translation network at inference time. It consists of the encoder �, the generator � and two mapping networks �1 and �2. Inspired by DeepI2I [63], we use the pretrained discriminator (Figure 2(b)) to initialize the encoder � of the 3D-aware I2I translation model (Figure 2(f)), and correspondingly, the pretrained generator (Figure 2(b)) to initialize the 3D-aware I2I generator. To align the encoder with the generator, [63] introduces a Resnet-like adaptor network to communicate the encoder and decoder. The adaptor is trained without any real data. However, directly using these techniques for 3D-aware I2I translation still suffers from some view-consistency problems. Therefore, in the following, we introduce several designs to address this problem: a U-net-like adaptor network design, a hierarchical representation constrain and a relative regularization loss.
图2(f)显示了推理时的3D感知I2I转换网络。它由编码器 � 、生成器 � 和两个映射网络 �1 和 �2 组成。受DeepI2I [ 63]的启发,我们使用预训练的I2I(图2(b))来初始化3D感知I2I转换模型(图2(f))的编码器 � ,相应地,预训练的生成器(图2(b))来初始化3D感知I2I生成器。为了使编码器与生成器对齐,[ 63]引入了一个类似Resnet的适配器网络来通信编码器和解码器。适配器在没有任何真实的数据的情况下进行训练。然而,直接将这些技术用于3D感知的I2I转换仍然存在一些视图一致性问题。因此,在下文中,我们介绍了几种设计来解决这个问题:一个U型网络适配器网络设计,层次表示约束和相对正则化损失。
U-net-like adaptor. As shown in Figure 2(c), to overcome 3D-inconsistency in the results, we propose a U-net-like adaptor �. This design contributes to preserve the spatial structure of the input feature. This has been used before for semantic segmentation tasks and label to image translation [18]. In this paper, we experimentally demonstrate that the U-net-like adaptor is effective to reduce the inconsistency.
U形网状适配器。如图2(c)所示,为了克服结果中的3D不一致性,我们提出了一个类似U形网的适配器 � 。这种设计有助于保持输入特征的空间结构。这之前已经用于语义分割任务和标签到图像的转换[ 18]。在本文中,我们通过实验证明了U-网适配器是有效的,以减少不一致性。
Hierarchical representation constrain.
层次表示约束。
As shown in Figure 2(e), given the noise 𝒛, 3D location 𝒙 and 2D viewing direction 𝒅 the fully connected layer � renders the 3D-consistent feature map 𝒇=�(𝒙,𝒅,𝒘1)=�(𝒙,𝒅,�1(𝒛)). We further extract the hierarchical representation {�(𝒇,𝒘1,𝒘2)�} as well as the synthesized image �^���=�(𝒇,𝒘1,𝒘2). Here �(𝒇,𝒘1,𝒘2)� is the �-�ℎ(�=�,…,�,(�>�)) ResBlock 11After each ResBlock the feature resolution is half of the previous one in the encoder, and two times in generator. In the generator, the last output is image.
每次ResBlock之后,特征分辨率在编码器中是前一个的一半,在生成器中是前一个的两倍。在生成器中,最后一个输出是图像。
如图2(e)所示,给定噪声 𝒛 、3D位置 𝒙 和2D观看方向 𝒅 ,全连接层 � 渲染3D一致的特征图 𝒇=�(𝒙,𝒅,𝒘1)=�(𝒙,𝒅,�1(𝒛)) 。我们进一步提取分层表示 {�(𝒇,𝒘1,𝒘2)�} 以及合成图像 �^���=�(𝒇,𝒘1,𝒘2) 。这里的 �(𝒇,𝒘1,𝒘2)� 是 �-�ℎ(�=�,…,�,(�>�)) ResBlock 1 output of the generator �. We then take the generated image �^��� as input for the encoder �: �(�^���), which is fed into the adaptor network �, that is 𝒇^=�(�(�^���)). In this step, our loss is
发生器 � 的输出。然后,我们将生成的图像 �^��� 作为编码器 � : �(�^���) 的输入,其被馈送到适配器网络 � ,即 𝒇^=�(�(�^���)) 。在这一步中,我们的损失是
| ℒ�=‖𝒇−𝒇^‖1. | (4) |
For the intermediate layers, we propose a hierarchical representation constrain. Given the output 𝒇^ and the latent codes (i.e., 𝒘1 and 𝒘2) 22Both 𝒘1 and 𝒘2 are the ones used when generating image �^���
𝒘1 和 𝒘2 都是生成图像 �^��� 时使用的图像
对于中间层,我们提出了一个分层表示约束。给定输出 𝒇^ 和潜在代码(即, 𝒘1 和 𝒘2 ) 2, we similarly collect the hierarchical feature {�(𝒇^,𝒘1,𝒘2)�}. The objective is
,我们类似地收集分层特征 {�(𝒇^,𝒘1,𝒘2)�} 。目标是
| ℒ�=∑�‖�(𝒇,𝒘1,𝒘2)�−�(𝒇^,𝒘1,𝒘2)�‖1. | (5) |
In this step, we freeze every network except for the U-net-like adaptor which is learned. Note that we do not access to any real data to train the adaptor, since we utilize the generated image with from the trained generator (Figure 2(b)).
在这一步中,我们冻结了除了学习到的U-net适配器之外的所有网络。请注意,我们不访问任何真实的数据来训练适配器,因为我们使用来自训练生成器的生成图像(图2(B))。
Relative regularization loss. We expect to input the consistency of the translated 3D scene with single-image regularization 33More precisely, that is the feature map in this paper.
更准确地说,这就是本文的特征图。
相对正则化损失。我们期望输入具有单图像正则化 3 的转换的3D场景的一致性 instead of the images from the consecutive views. We propose a relative regularization loss based on neighboring patches. We assume that neighboring patches are equivalent to that on corresponding patches of two consecutive views. For example, when inputting multi-view consistent scene images, the position of eyes are consistently moving. The fully connected layers (i.e., NeRF mode) � renders the view-consistent feature map 𝒇, which finally decides the view-consistent reconstructed 3D scene. Thus, we expect the output 𝒇^ of the adaptor � to obtain the view-consistent property of the feature map 𝒇.
而不是来自连续视图的图像。我们提出了一种基于相邻补丁的相对正则化损失。我们假设相邻的补丁是等价的,在相应的补丁的两个连续的意见。例如,当输入多视图一致场景图像时,眼睛的位置一致地移动。完全连接的层(即,NeRF模式) � 渲染视图一致的特征图 𝒇 ,其最终决定视图一致的重建3D场景。因此,我们期望适配器 � 的输出 𝒇^ 获得特征图 𝒇 的视图一致性属性。
We randomly sample one vector from the feature map 𝒇 (e.g., red square in (Figure 2(d))), denoted as 𝒇�. Then we sample the eight nearest neighboring vectors of 𝒇� (dark green square in Figure 2(d))), denoted by 𝒇�,� where �=1,⋯,8 is the neighbor index. Similarly, we sample vectors 𝒇^� and 𝒇^�,� from the feature map 𝒇^ (red and dark green dash square in Figure 2(d))). We then compute the patch difference:
我们从特征图 𝒇 中随机采样一个向量(例如,(图2(d)中的红色方块),表示为 𝒇� 。然后,我们对 𝒇� 的八个最近的相邻向量(图2(d)中的深绿色正方形)进行采样,由 𝒇�,� 表示,其中 �=1,⋯,8 是相邻索引。类似地,我们从特征图 𝒇^ 中采样向量 𝒇^� 和 𝒇^�,� (图2(d)中的红色和深绿色虚线正方形)。然后我们计算补丁差异:
| �𝒇�,�=𝒇�⊖𝒇�,� | ,�𝒇^�,�=𝒇^�⊖𝒇^�,�, | (6) |
where ⊖ represents vector subtraction. In order to preserve the consistency, we force these patch differences to be small:
其中 ⊖ 表示向量减法。为了保持一致性,我们强制这些补丁差异很小:
| ℒ�=‖�𝒇�,�−�𝒇^�,�‖1. | (7) |
The underlying intuition is straightforward: the difference vectors of the same location should be most relevant in the latent space compared to other random pairs.
基本的直觉是直接的:与其他随机对相比,相同位置的差异向量在潜在空间中应该是最相关的。
The final objective is
最终目的是
| ℒ=ℒ�+ℒ�+ℒ�. | (8) |
| MethodDataset | CelebA-HQ | AFHQ | ||
| TC↓ TC编号0# | FID↓ FID编号0# | TC↓ TC编号0# | FID↓ FID编号0# | |
| *MUNIT * 单位 | 30.240 | 31.4 | 28.497 | 41.5 |
| *DRIT | 35.452 | 52.1 | 25.341 | 95.6 |
| *MSGAN | 31.641 | 33.1 | 34.236 | 61.4 |
| StarGANv2 | 10.250 | 13.6 | 3.025 | 16.1 |
| Ours (3D) 我们的(3D) | 3.743 | 22.3 | 2.067 | 15.3 |
| TC↓ TC编号0# | (unc)FID↓ (unc)FID ↓ | TC↓ TC编号0# | (unc)FID↓ (unc)FID ↓ | |
| †Liu et al. [35] † Liu等人[ 35] | 13.315 | 17.8 | 3.462 | 20.0 |
| StarGANv2 | 10.250 | 12.2 | 3.025 | 9.9 |
| †Kunhee et al. [24] † Kunhee等人[ 24] | 10.462 | 6.7 | 3.241 | 10.0 |
| Ours (3D) 我们的(3D) | 3.743 | 18.7 | 2.067 | 11.4 |
Table 1:Comparison with baselines on TC and FID metrics.* denotes that we used the results provided by StarGANv2. † means that we used the pre-trained networks provided by authors.
表1:与TC和FID指标基线的比较。表示我们使用了StarGANv 2提供的结果。 † 意味着我们使用了作者提供的预训练网络。
| Ini. | Ada. | Hrc. | Rrl. | TC↓ | FID↓ |
|---|---|---|---|---|---|
| Y | N | N | N | 2.612 | 23.8 |
| Y | Y | N | N | 2.324 | 23.1 |
| Y | Y | Y | N | 2.204 | 16.1 |
| Y | Y | Y | Y | 2.067 | 15.3 |
Table 2:Impact of several components in the performance on AFHQ. The second row is the case where the 3D-aware I2I translation model is initialized by weights learned from the multi-class StylyNeRF. Then it is trained with a Resnet-based adaptor and �1 loss between the representations 𝒇 and 𝒇^. The proposed techniques continuously improve the consistency and performance. Ini.: initialization method for multi-class StyleNeRF, Ada.: U-net-like adaptor, Hrc.: Hierarchical representation constrain, Rrl: Relative regularization loss.
表2:几个组件对AFHQ性能的影响。第二行是通过从多类StylyNeRF学习的权重初始化3D感知I2 I转换模型的情况。然后使用基于Resnet的适配器和表示 𝒇 和 𝒇^ 之间的 �1 损失来训练它。所提出的技术不断提高的一致性和性能。Ini.:多类StyleNeRF的初始化方法,Ada.:U-net-like adapter,Hrc.:分层表示约束,Rrl:相对正则化损失。

Figure 3: (Top) Using a single mapping network which takes as input the concatenated class embedding and the noise. We find it fails to generate target-specific realistic image. (Bottom) we use two mapping networks without concatenating their outputs like the proposed method. This design fails to generate 3D-aware results.
图3:(上)使用单个映射网络,将级联类嵌入和噪声作为输入。我们发现它无法生成目标特定的真实感图像。(下)我们使用两个映射网络,而不像所提出的方法那样连接它们的输出。该设计无法生成3D感知结果。

Figure 4:Comparative results between the proposed method and StarGANv2. We observe that StarGANv2 suffers from underestimating viewpoint changes when changing the input viewpoint ( first column). It also leads to identity change (third and fourth columns), and a geometrically unrealistic ear (last two columns).
图4:所提出的方法和StarGANv2之间的比较结果。我们观察到StarGANv2在改变输入视点(第一列)时低估了视点的变化。它还导致了身份的改变(第三和第四列),以及一个几何上不现实的耳朵(最后两列)。

Figure 5:The generated images of (top) �(𝒇,𝒘1,𝒘2) and (bottom) �(𝒇^,𝒘1,𝒘2), which show that we correctly align the outputs of both the NeRF mode � and the adaptor �.
图5:生成的图像(顶部) �(𝒇,𝒘1,𝒘2) 和(底部) �(𝒇^,𝒘1,𝒘2) ,表明我们正确对齐NeRF模式 � 和适配器 � 的输出。
4Experiments 4实验
4.1Experimental setup 4.1实验装置
Training details. We use the trained StyleNeRF to partially initialize our multi-class StyleNeRF architecture. We adapt the structure of the multi-class StyleNeRF to the 3D-aware I2I architecture. The proposed method is implemented in Pytorch [49]. We use Adam [26] with a batch size of 64, using a learning rate of 0.0002. We use 2× Quadro RTX 3090 GPUs (24 GB VRAM) to conduct all our experiments. We show the network details and more results on Supp. Mat..
训练细节。我们使用经过训练的StyleNeRF来部分初始化我们的多类StyleNeRF架构。我们将多类StyleNeRF的结构适应于3D感知I2 I架构。所提出的方法在Pytorch中实现[ 49]。我们使用Adam [ 26],批量大小为64,学习率为0.0002。我们使用 2× Quadro RTX 3090 GPU(24 GB VRAM)进行所有实验。我们在Supp上显示网络详细信息和更多结果。垫..
Datasets. Our experiments are conducted on the Animal Faces (AFHQ) [8] and CelebA-HQ [22] datasets. AFHQ contains 3 classes, each one has about 5000 images. In CelebA-HQ, we use gender as a class, with ∼10k(10057) male and ∼18k(17943) female images in the training set. In this paper, all images are resized to 256×256.
数据集。我们的实验是在动物面孔(AFHQ)[ 8]和CelebA-HQ [ 22]数据集上进行的。AFHQ包含3个类,每个类大约有5000个图像。在CelebA-HQ中,我们使用性别作为一个类,训练集中有 ∼ 10k(10057)男性和 ∼ 18k(17943)女性图像。在本文中,所有图像的大小都调整为 256×256 。
Baselines. We compare to MUNIT [16], DRIT [29], MSGAN [21], StarGANv2 [8], [24] and [35], all of which perform image-to-image translation.
基线。我们比较MUNIT [ 16],DRIT [ 29],MSGAN [ 21],StarGANv 2 [ 8],[ 24]和[ 35],所有这些都执行图像到图像的转换。
Evaluation Measures. We employ the widely used metric for evaluation, namely Fréchet Inception Distance (FID) [15]. We also propose a new measure in which we combine two metrics, one which measures the consistency between neighboring frames (which we want to be low), and another that measures the diversity over the whole video (which we would like to be high). We adopt a modified temporal loss (TL) [56]. This temporal loss computes the Frobenius difference between two frames to evaluate the video consistency. Only considering this measure would lead to high scores when neighboring frames in the generated video are all the same. For successful 3D-aware I2I translation, we expect the system to be sensitive to view changes in the source video and therefore combine low consecutive frame changes with high diversity over the video. Therefore, we propose to compute LPIPS [69] for each video (vLPIPS), which indicates the diversity of the generated video sequence. To evaluate both the consistency and the sensitiveness of the generated video, we propose a new temporal consistency metric (TC):
评估措施。我们采用广泛使用的度量进行评估,即Fréchet Inception Distance(FID)[ 15]。我们还提出了一种新的测量方法,其中我们结合了联合收割机两个度量,一个度量相邻帧之间的一致性(我们希望低),另一个度量整个视频的多样性(我们希望高)。我们采用修改的时间损失(TL)[ 56]。这种时间损失计算两帧之间的Frobenius差来评估视频一致性。当生成的视频中的相邻帧都相同时,仅考虑该度量将导致高分。对于成功的3D感知I2I转换,我们期望系统对源视频中的视图变化敏感,因此将视频上的联合收割机低连续帧变化与高多样性相结合。因此,我们建议为每个视频(vLPIPS)计算LPIPS [ 69],这表明生成的视频序列的多样性。 为了评估生成视频的一致性和敏感性,我们提出了一个新的时间一致性度量(TC):
| ��=��/������. | (9) |
Due to the small changes between two consecutive views, for each video we use frame interval 1, 2 and 4 in between to evaluate view-consistency. Note that a lower TC value is better.
由于两个连续视图之间的微小变化,对于每个视频,我们使用帧间隔1,2和4来评估视图一致性。请注意,TC值越低越好。
Figure 6:Interpolation between the dog and wildlife classes.
图6:狗和野生动物类之间的插值。 Figure 7:Qualitative results of multi-class StyleNeRF training from scratch (up) and from the proposed strategy (bottom).
图7:从头开始(上)和建议策略(下)的多类StyleNeRF训练的定性结果。
4.2Quantitative and qualitative results.
4.2定量和定性结果。
We evaluate the performance of the proposed method on both the AFHQ animal and CelebA human face dataset. As reported in Table 1, in terms of TC the proposed method achieves the best score on two datasets. For example, we have 3.743 TC on CelebA-HQ, which is better than StarGANv2 (10.250 TC). This indicates that our method dramatically improves consistency. As reported in Table 1 (up), across both datasets, the proposed method consistently outperforms the baselines with significant gains in terms of FID and LPIPS, except for StarGANv2 which obtains superior results. However, on AFHQ we achieve better FID score than StarGANv2. Kunhee et al. [24] reports the unconditional FID ((unc)FID) value which is computed between synthesized images and training samples instead of each class. As reported in Table 1 (bottom), We are able to achieve completing results on uncFID metrics. Note that while 2D I2I translation (e.g., StarGANv2) can obtain high-quality for each image, they cannot synthesize images of the same scene with 3D consistency, and suffers from unrealistic shape/identity changes when changing the viewpoint, which are especially notable when looking at a video.
我们评估了所提出的方法在AFHQ动物和CelebA人脸数据集上的性能。如表1所示,就TC而言,所提出的方法在两个数据集上获得了最佳分数。例如,我们在CelebA-HQ上有3.743 TC,比StarGANv 2(10.250 TC)好。这表明我们的方法大大提高了一致性。如表1(上图)所示,在两个数据集上,所提出的方法在FID和LPIPS方面始终优于基线,具有显著的增益,除了StarGANv 2获得了上级结果。然而,在AFHQ上,我们获得了比StarGANv 2更好的FID分数。Kunhee等人。[ 24]报告了在合成图像和训练样本之间计算的无条件FID((unc)FID)值,而不是每个类别。如表1(底部)所示,我们能够在uncFID指标上取得完整的结果。注意,虽然2D I2 I平移(例如,,StarGANv 2)可以为每个图像获得高质量,它们无法合成具有3D一致性的同一场景的图像,并且在改变视点时会出现不切实际的形状/身份变化,这在观看视频时尤其明显。
In Figures 1,4, we perform 3D-aware I2I translation. When changing the input viewpoint (Figure 4 (first two columns)), the outputs of StarGANv2 do not maintain the correct head pose, and underestimate the pose changes with respect to the frontal view. To estimate that this is actually the case, we also compute the diversity (i.e., vLPIPS) in a single video sequence. For example, both StarGANv2 and our method are 0.032 and 0.101 on CelebA-HQ. This confirms that the diversity (due to pose changes) is lowest for StarGANv2. More clearly showing the limitations of standard I2I methods for 3D-aware I2I, we observe that StarGANv2 suffers from unrealistic changes when changing the viewpoint. For example, when translating the class cat to wildlife, the generated images changes from wolf to leopard when varying the viewpoint (Figure 4 (third and fourth columns)). . Also, the main target class characteristics, such as ears, are not geometrically realistic, leading to unrealistic 3D scene videos. Our method, however, eliminates these shortcomings and performs efficient high-resolution image translation with high 3D-consistency, which preserves the input image pose and changes the style of the output images. We show high-resolution images (1024×1024) on Supp. Mat..
在图1和图4中,我们执行3D感知I2 I转换。当改变输入视点时(图4(前两列)),StarGANv 2的输出不能保持正确的头部姿势,并且低估了相对于正视图的姿势变化。为了估计实际上是这种情况,我们还计算多样性(即,vLPIPS)。例如,StarGANv 2和我们的方法在CelebA-HQ上都是0.032和0.101。这证实了StarGANv 2的多样性(由于姿势变化)最低。更清楚地显示了3D感知I2 I的标准I2 I方法的局限性,我们观察到StarGANv 2在改变视点时会发生不切实际的变化。例如,当将类别cat转换为wildlife时,当改变视点时,生成的图像会从wolf变为leopard(图4(第三和第四列))。.此外,主要目标类别特征(例如耳朵)在几何上不真实,从而导致不真实的3D场景视频。 然而,我们的方法,消除了这些缺点,并执行高效的高分辨率图像翻译与高3D一致性,保留输入图像的姿态,并改变输出图像的风格。我们在Supp上显示高分辨率图像( 1024×1024 )。垫..
4.3Ablation study 4.3消融研究
Conditional 3D-aware generative architecture In this experiment, we verify our network design by comparing it with two alternative network designs. As shown in Figure 3(up), we explore a naive strategy: using one mapping which takes as input the concatenated class embedding and the noise. In this way, the fully connected network � outputs the class-specific latent code 𝒘, which is fed into the fully connected network � to output theclass-specific representation 𝒇. Here, both the latent code 𝒘 and the representation 𝒇 are decided by the same class. However, when handling 3D-aware multi-class I2I translation task, the feature representation 𝒇^ is combined with the latent code 𝒘 from varying class embeddings, which leads to unrealistic image generation (Figure. 3(up)).
在这个实验中,我们通过将我们的网络设计与两种替代网络设计进行比较来验证我们的网络设计。如图3(上图)所示,我们探索了一种简单的策略:使用一个映射,该映射将连接的类嵌入和噪声作为输入。以这种方式,全连接网络 � 输出类特定潜码 𝒘 ,其被馈送到全连接网络 � 以输出类特定表示 𝒇 。这里,潜在码 𝒘 和表示 𝒇 都由相同的类决定。然而,当处理3D感知的多类I2I转换任务时,特征表示 𝒇^ 与来自不同类嵌入的潜在代码 𝒘 相结合,这导致不切实际的图像生成(图1)。3(向上))。
As shown in Figure 3(bottom), we utilize two mapping networks without concatenating their outputs like the proposed method. This design guarantees that the output of the fully connected layers � are class-agnostic. We experimentally observe that this model fails to handle 3D-aware generation.
如图3(底部)所示,我们使用两个映射网络,而不像所提出的方法那样连接它们的输出。这种设计保证了全连接层 � 的输出是类不可知的。我们通过实验观察到,该模型无法处理3D感知生成。
Effective training strategy for multi-class 3D-aware generative model. We evaluate the proposed training strategy on AFHQ and CelebA-HQ datasets. We initialize the proposed multi-class 3D I2I architecture from scratch and the proposed method, respectively. As shown on Figure 7 (up), the model trained from scratch synthesizes unrealistic faces on CelebA-HQ dataset, and low quality cats on AFHQ. This is due to the style-based conditional generator which is hard to be optimized and causes mode collapse directly [51]. The proposed training strategy, however, manages to synthesize photo-realistic high-resolution images with high multi-view consistency. This training strategy first performs unconditional learning, which leads to satisfactory generative ability. Thus, we relax the difficulty of directly training the conditional model.
多类3D感知生成模型的有效训练策略。我们在AFHQ和CelebA-HQ数据集上评估了所提出的训练策略。我们从零开始和所提出的方法,分别初始化所提出的多类3D I2 I架构。如图7(上图)所示,从头开始训练的模型在CelebA-HQ数据集上合成了不真实的面孔,在AFHQ上合成了低质量的猫。这是由于基于样式的条件生成器难以优化并直接导致模式崩溃[ 51]。然而,所提出的训练策略,设法合成照片般逼真的高分辨率图像具有高的多视图一致性。这种训练策略首先执行无条件学习,这导致令人满意的生成能力。因此,我们放松了直接训练条件模型的难度。
Alignment and interpolation. Figure 5 exhibits the outputs of the generator when taking as input the feature representation 𝒇 and 𝒇^. This confirms that the proposed method successfully aligns the outputs of the fully connected layers � and the adaptor �. Figure 6 reports interpolation by freezing the input images while interpolating the class embedding between two classes. Our model still manages to preserve the view-consistency, and generate high quantity images with even given never seen class embeddings.
对齐和插值。图5展示了当将特征表示 𝒇 和 𝒇^ 作为输入时生成器的输出。这证实了所提出的方法成功地对准了全连接层 � 和适配器 � 的输出。图6报告了在两个类之间插入类嵌入时冻结输入图像的插值。我们的模型仍然能够保持视图的一致性,并生成高质量的图像,即使给定从未见过的类嵌入。
Techniques for improving the view-consistency. We perform an ablation study on the impact of several design elements on the overall performance of the system, which includes the proposed initialization 3D-aware I2I translation model (Ini.), U-net-like adaptor (Ada.), hierarchical representation constrain (Hrc.) and relative regularization loss (Rrl.). We evaluate these four factors in Table 2. The results show that only using the proposed initialization (the second row of the Table 2) has already improved the view-consistency comparing to StarGANv2 (Table 1). Utilizing either U-net-like adaptor (Ada.) or hierarchical representation constrain (Hrc.) further leads to performance gains. Finally we are able to get the best score when further adding relative regularization loss (Rrl.) to the 3D-aware I2I translation model.
提高视图一致性的技术。我们对几个设计元素对系统整体性能的影响进行了消融研究,其中包括提出的初始化3D感知I2I转换模型(Ini.),U形网状适配器(Ada.),层次表示约束和相对正则化损失(Rrl.)。我们在表2中评估了这四个因素。结果表明,与StarGANv2(表1)相比,仅使用建议的初始化(表2的第二行)已经提高了视图一致性。利用U形网状适配器(Ada.)或分层表示约束(Hrc.)进一步导致性能增益。最后,当进一步添加相对正则化损失(Rrl)时,我们能够获得最佳分数。3D感知的I2I转换模型。
5Conclusion 5结论
In this paper we first explore 3D-aware I2I translation. We decouple the learning process into a multi-class 3D-aware generative model step and a 3D-aware I2I translation step. In the first step, we propose a new multi-class StyleNeRF architecture, and an effective training strategy. We design the 3D-aware I2I translation model with the well-optimized multi-class StyleNeRF model. It inherits the capacity of synthesizing 3D consistent images. In the second step, we propose several techniques to further reduce the view-consistency of the 3D-aware I2I translation.
在本文中,我们首先探讨3D感知的I2 I翻译。我们将学习过程解耦为多类3D感知生成模型步骤和3D感知I2 I翻译步骤。在第一步中,我们提出了一个新的多类StyleNeRF架构,和一个有效的训练策略。我们使用优化的多类StyleNeRF模型设计了3D感知的I2 I翻译模型。它继承了合成3D一致图像的能力。在第二步中,我们提出了几种技术来进一步降低3D感知I2 I翻译的视图一致性。
Acknowledgement. We acknowledge the support from the Key Laboratory of Advanced Information Science and Network Technology of Beijing (XDXX2202), and the project supported by Youth Foundation (62202243). We acknowledge the Spanish Government funding for projects PID2019-104174GB-I00, TED2021-132513B-I00.
致谢。感谢北京市高等信息科学与网络技术重点实验室(XDXX 2202)和青年基金会(62202243)对本课题的支持。我们感谢西班牙政府对项目PID 2019 - 104174 GB-I 00、TED 2021 - 132513 B-I 00的资助。