↑↑↑请在文章开头处下载测试项目源代码↑↑↑
文章目录
- 前言
- 4.9 好友关注
- 4.9.1 关注和取消关注
- 4.9.1.1 创建表是实体类
- 4.9.1.2 实现关注和取消关注
- 4.9.2 共同关注
- 4.9.2.1 改造关注和取消关注功能
- 4.9.2.2 实现查询共同关注好友功能
- 4.9.3 Feed流
- 4.9.3.1 Feed流介绍及其实现模式
- 4.9.3.2 Timeline模式的实现方案
- 4.9.3.3 实现推动到粉丝邮件箱功能
- 4.9.3.4 实现分页查询收件箱功能
前言
Redis实战系列文章:
Redis从入门到精通(四)Redis实战(一)短信登录
Redis从入门到精通(五)Redis实战(二)商户查询缓存
Redis从入门到精通(六)Redis实战(三)优惠券秒杀
Redis从入门到精通(七)Redis实战(四)库存超卖、一人一单与Redis分布式锁
Redis从入门到精通(八)Redis实战(五)分布式锁误删与原子性问题、Redisson
Redis从入门到精通(九)Redis实战(六)基于Redis队列实现异步秒杀下单
Redis从入门到精通(十)Redis实战(七)达人探店、点赞与点赞排行榜
4.9 好友关注
4.9.1 关注和取消关注
4.9.1.1 创建表是实体类
好友关注功能涉及的表有1个:
CREATE TABLE `tb_follow` (
`id` BIGINT(20) NOT NULL AUTO_INCREMENT COMMENT '主键',
`user_id` BIGINT(20) UNSIGNED NOT NULL COMMENT '用户id',
`follow_user_id` BIGINT(20) UNSIGNED NOT NULL COMMENT '关注的用户id',
`create_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = INNODB AUTO_INCREMENT = 1 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = COMPACT;
表对应的实体类如下:
// com.star.redis.dzdp.pojo.Follow
@Data
@EqualsAndHashCode(callSuper = false)
@TableName("tb_follow")
public class Follow implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 主键
*/
@TableId(value = "id", type = IdType.AUTO)
private Long id;
/**
* 用户id
*/
private Long userId;
/**
* 关注的用户id
*/
private Long followUserId;
/**
* 创建时间
*/
private Date createTime;
}
4.9.1.2 实现关注和取消关注
创建实体类Follow对应的FollowController类-IFollowService接口-FollowServiceImpl实现类-FollowMapper类。详见测试项目代码。
在FollowController类中创建一个follow()方法,用于实现关注和取消关注功能。其接口文档及代码如下:
| 项目 | 说明 |
|---|---|
| 请求方法 | POST |
| 请求路径 | /follow/{id}/{isFollow} |
| 请求参数 | id,Long,要关注的用户ID isFollow,boolean,=true时表示关注,=false时表示取消关注 |
| 返回值 | 无 |
// com.star.redis.dzdp.controller.FollowController
@Slf4j
@RestController
@RequestMapping("/follow")
public class FollowController {
@Resource
private IFollowService followService;
/**
* 关注或者取消关注
* @author hsgx
* @since 2024/4/8 14:27
* @param id 被关注的用户ID
* @param isFollow true-关注 false-取消关注
* @param request
* @return com.star.redis.dzdp.pojo.BaseResult
*/
@PostMapping("/{id}/{isFollow}")
public BaseResult follow(@PathVariable("id") Long id,
@PathVariable("isFollow") Boolean isFollow,
HttpServletRequest request) {
return followService.follow(id, isFollow, (Long)request.getAttribute("userId"));
}
}
接着在IFollowService接口中定义一个follow()方法,并在FollowServiceImpl实现类中具体实现,用于关注/取消关注用户:
// com.star.redis.dzdp.service.impl.FollowServiceImpl
@Slf4j
@Service
@Transactional(rollbackFor = Exception.class)
public class FollowServiceImpl extends ServiceImpl<FollowMapper, Follow> implements IFollowService {
@Override
public BaseResult follow(Long followUserId, Boolean isFollow, Long userId) {
log.info("userId = {}, followUserId = {}, idFollow = {}",
userId, followUserId, isFollow);
// 1.判断是关注还是取关
if(isFollow) {
// 2.关注,新增数据
Follow follow = new Follow();
follow.setUserId(userId);
follow.setFollowUserId(followUserId);
save(follow);
log.info("add follow done.");
} else {
// 3.取关,删除数据
remove(new QueryWrapper<Follow>().eq("user_id", userId).eq("follow_user_id", followUserId));
log.info("remove follow done.");
}
return BaseResult.setOk();
}
}
最后进行功能测试。调用/follow/1/true接口关注ID=1的用户:
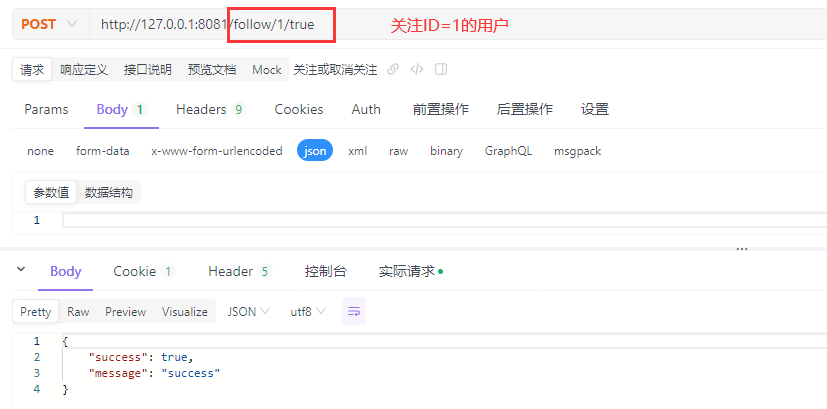
[http-nio-8081-exec-4] userId = 1012, followUserId = 1, idFollow = true
[http-nio-8081-exec-4] ==> Preparing: INSERT INTO tb_follow ( user_id, follow_user_id ) VALUES ( ?, ? )
[http-nio-8081-exec-4] ==> Parameters: 1012(Long), 1(Long)
[http-nio-8081-exec-4] <== Updates: 1
[http-nio-8081-exec-4] add follow done.
再次调用/follow/1/false接口取消关注ID=1的用户:
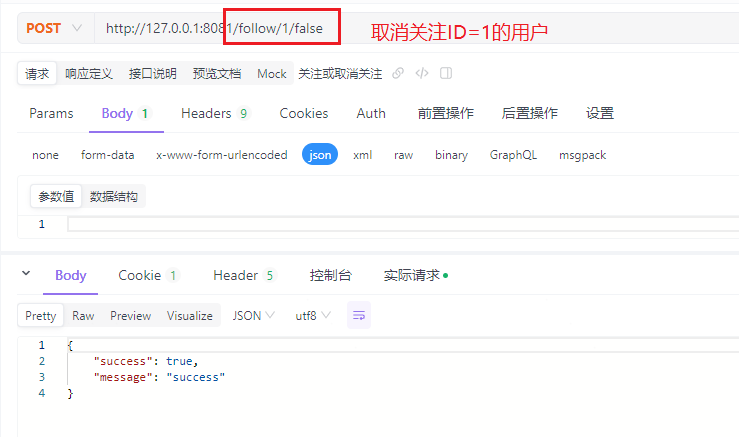
[http-nio-8081-exec-6] userId = 1012, followUserId = 1, idFollow = false
[http-nio-8081-exec-6] ==> Preparing: DELETE FROM tb_follow WHERE (user_id = ? AND follow_user_id = ?)
[http-nio-8081-exec-6] ==> Parameters: 1012(Long), 1(Long)
[http-nio-8081-exec-6] <== Updates: 1
[http-nio-8081-exec-6] remove follow done.
4.9.2 共同关注
要实现共同关注好友功能,可以利用Redis的Set集合:把用户1关注的人放在Key为follow:user:{id1}的Set集合中,把用户2关注的人放在Key为follow:user:{id2}的Set集合中,那么两个Set集合的交集就是两个用户共同关注的好友。
4.9.2.1 改造关注和取消关注功能
首先对FollowServiceImpl类的关注和取消关注方法follow()进行改造:新增关注时,除了写数据库,还要把关注用户的ID放入Redis的Set集合中;取消关注时,除了删数据库,还要把关注用户的ID从Set集合移除。
// com.star.redis.dzdp.service.impl.FollowServiceImpl
@Resource
private StringRedisTemplate stringRedisTemplate;
@Override
public BaseResult follow(Long followUserId, Boolean isFollow, Long userId) {
log.info("userId = {}, followUserId = {}, idFollow = {}",
userId, followUserId, isFollow);
// 1.判断是关注还是取关
if(isFollow) {
// 2.关注,新增数据
Follow follow = new Follow();
follow.setUserId(userId);
follow.setFollowUserId(followUserId);
boolean save = save(follow);
// 把关注用户的ID放入Set集合
if(save) {
stringRedisTemplate.opsForSet().add("follow:user:" + userId, followUserId.toString());
log.info("add follow done.");
return BaseResult.setOk("关注成功!");
}
} else {
// 3.取关,删除数据
boolean remove = remove(new QueryWrapper<Follow>().eq("user_id", userId)
.eq("follow_user_id", followUserId));
// 把关注用户的ID从Set集合移除
if(remove) {
stringRedisTemplate.opsForSet().remove("follow:user:" + userId, followUserId.toString());
log.info("remove follow done.");
return BaseResult.setOk("取消关注成功!");
}
}
return BaseResult.setFail("操作失败!");
}
功能测试:
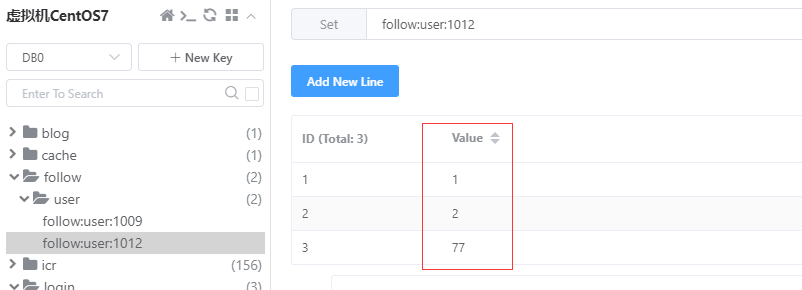
调用接口使当前用户(ID=1012)关注ID=[1,2,77]的三个用户:

此时Redis中的数据:
4.9.2.2 实现查询共同关注好友功能
在FollowController类中编写一个commons()方法,用于查询共同关注好友。其接口文档和代码如下:
| 项目 | 说明 |
|---|---|
| 请求方法 | GET |
| 请求路径 | /follow/commons/{id} |
| 请求参数 | id,Long,与当前用户有共同关注好友的用户ID |
| 返回值 | List<User>,共同关注好友列表 |
// com.star.redis.dzdp.controller.FollowController
/**
* 查询共同关注好友
* @author hsgx
* @since 2024/4/8 17:15
* @param id 与当前用户有共同关注好友的用户ID
* @param request
* @return com.star.redis.dzdp.pojo.BaseResult<java.util.List<com.star.redis.dzdp.pojo.User>>
*/
@GetMapping("/commons/{id}")
public BaseResult<List<User>> commons(@PathVariable("id") Long id, HttpServletRequest request) {
return followService.queryCommonFollows(id, (Long)request.getAttribute("userId"));
}
然后在IFollowService接口定义一个queryCommonFollows()方法,并在FollowServiceImpl实现类中具体实现:
// com.star.redis.dzdp.service.impl.FollowServiceImpl
@Override
public BaseResult<List<User>> queryCommonFollows(Long followUserId, Long userId) {
log.info("queryCommonFollows, followUserId = {}, userId = {}",
followUserId, userId);
// 1.求两个Set集合之间的交集
String key1 = "follow:user:" + userId;
String key2 = "follow:user:" + followUserId;
Set<String> intersect = stringRedisTemplate.opsForSet().intersect(key1, key2);
// 2.判断有无交集
if(intersect == null || intersect.isEmpty()) {
log.info("获取两个Set集合的交集:key1 = {}, key2 = {}, 结果为空", key1, key2);
return BaseResult.setOkWithData(Collections.emptyList());
}
// 3.有交集,解析ID集合
List<Long> ids = intersect.stream().map(Long::valueOf).collect(Collectors.toList());
log.info("获取两个Set集合的交集:key1 = {}, key2 = {}, 结果为:{}", key1, key2, ids);
// 4.查询用户列表
List<User> userList = userService.listByIds(ids);
return BaseResult.setOkWithData(userList);
}
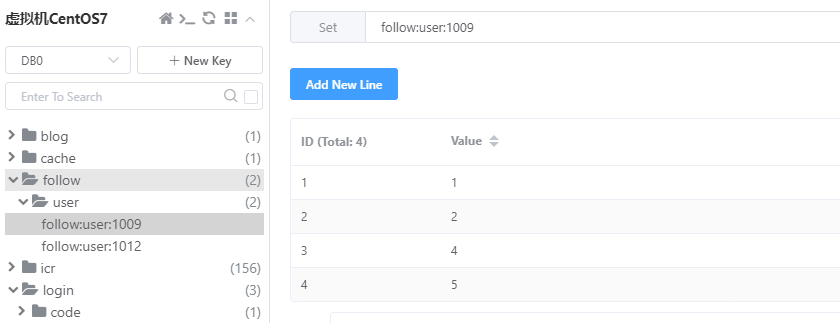
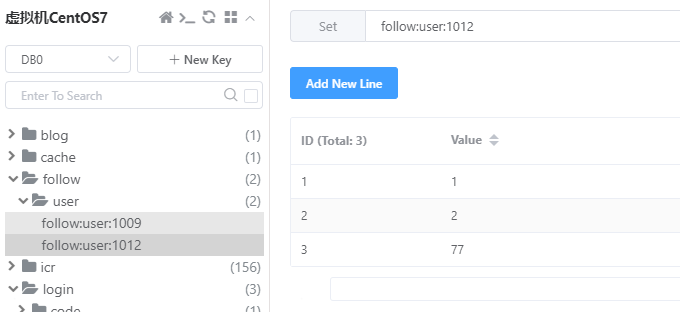
功能测试:
当前在Redis中,ID=1009的用户关注了ID=[1,2,4,5]的用户,ID=1012的用户关注了ID=[1,2,77]的用户,两者的共同好友ID=[1,2]:
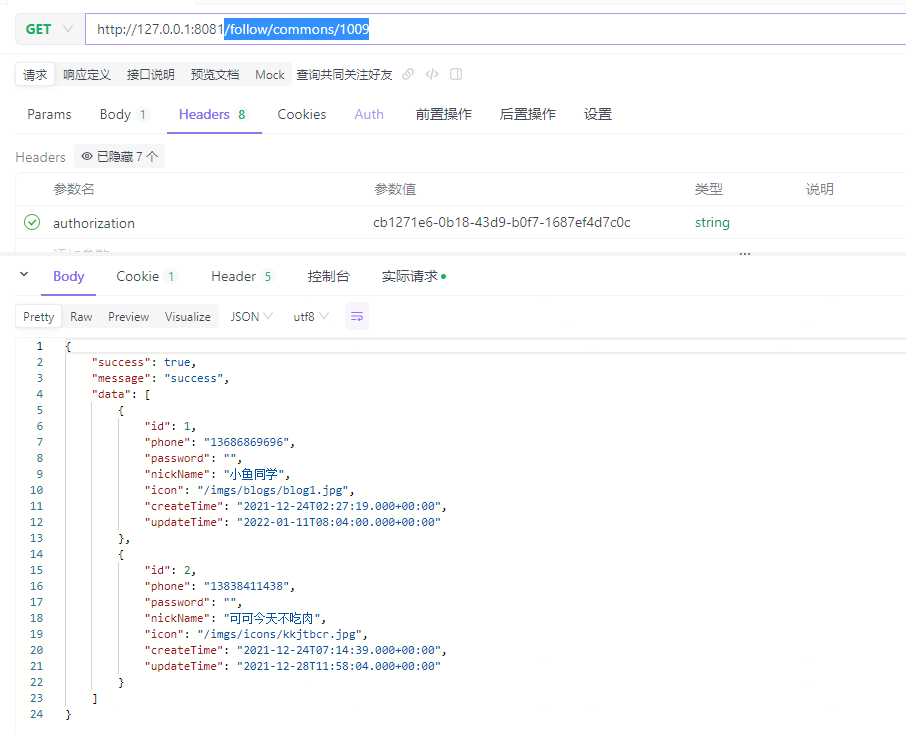
调用/follow/commons/1009接口查询ID为1009和1012的用户之间的共同关注好友:
[http-nio-8081-exec-3] queryCommonFollows, followUserId = 1009, userId = 1012
[http-nio-8081-exec-3] 获取两个Set集合的交集:key1 = follow:user:1012, key2 = follow:user:1009, 结果为:[1, 2]
[http-nio-8081-exec-3] ==> Preparing: SELECT id,phone,password,nick_name,icon,create_time,update_time FROM tb_user WHERE id IN ( ? , ? )
[http-nio-8081-exec-3] ==> Parameters: 1(Long), 2(Long)
[http-nio-8081-exec-3] <== Total: 2
4.9.3 Feed流
4.9.3.1 Feed流介绍及其实现模式
所谓Feed流,直译过来叫“投喂”,也就是当我们关注了某个用户后,一旦这个用户发了动态,我们就能收到推送过来的数据。 例如微信订阅号的消息推送、小红书关注栏目的笔记推送等。
对于传统的模式,需要用户通过搜索引擎或者其他方式去查找想看的内容,例如百度;而对于新型的Feed流,不需要用户再去搜索,而是系统分析用户到底想看到什么,然后直接把相关内容推送给用户,从而节约用户的时间。
Feed流的实现有两种模式:
-
1)Timeline
不做内容筛选,简单地按照内容发布时间排序,例如朋友圈。 这种模式的优点在于,信息全面不会有缺失,并且实现相对简单;缺点在于,信息噪音较多,用户不一定感兴趣(例如朋友圈的营销号、微商等),内容获取效率低。
-
2)智能排序
利用智能算法屏蔽掉违规的、用户不感兴趣的内容,只推送用户感兴趣的内容来吸引用户。 这种模式的优点在于,投喂用户感兴趣的信息,用户粘度高;缺点在于,如果算法不够精准,可能起到反作用,而足够精准时容易让用户沉迷。
4.9.3.2 Timeline模式的实现方案
在本案例中,采用Timeline模式,只需要拿到关注的用户信息,再按照时间排序展示这些用户发布的动态信息。
Timeline模式的实现方案有三种:
-
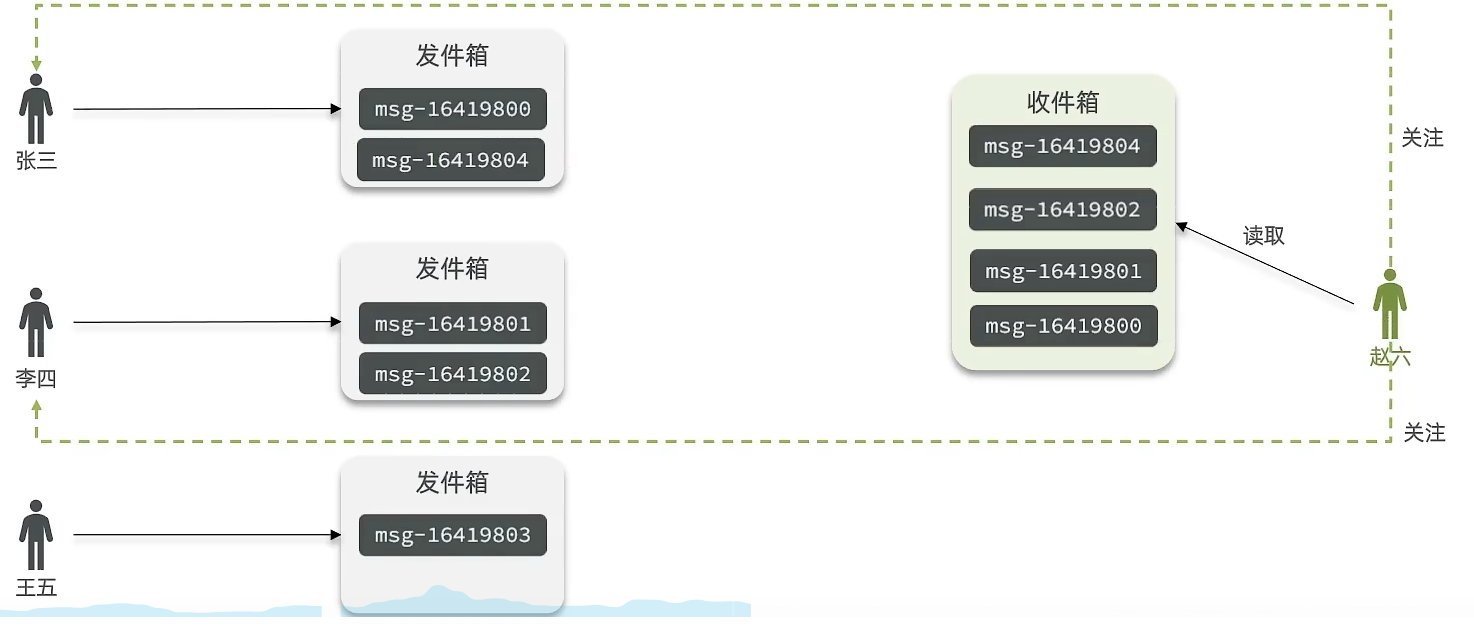
1)拉模式(读扩散)
含义:当张三、李四和王五发了消息后,都会保存在自己的邮箱中。假设赵六关注了这三位,要读取信息时,他会读取自己的收件箱,此时系统会把他关注的人所发的信息全部都进行拉取,然后在进行排序。
优点:比较节约空间,因为赵六在读信息时,并没有重复读取,而且读取完之后可以进行清除。
缺点:比较延迟,当用户要读取数据时才去关注的人里边读取数据,假设用户关注了大量的用户,那么此时就会拉取海量的内容,对服务器压力巨大。
-
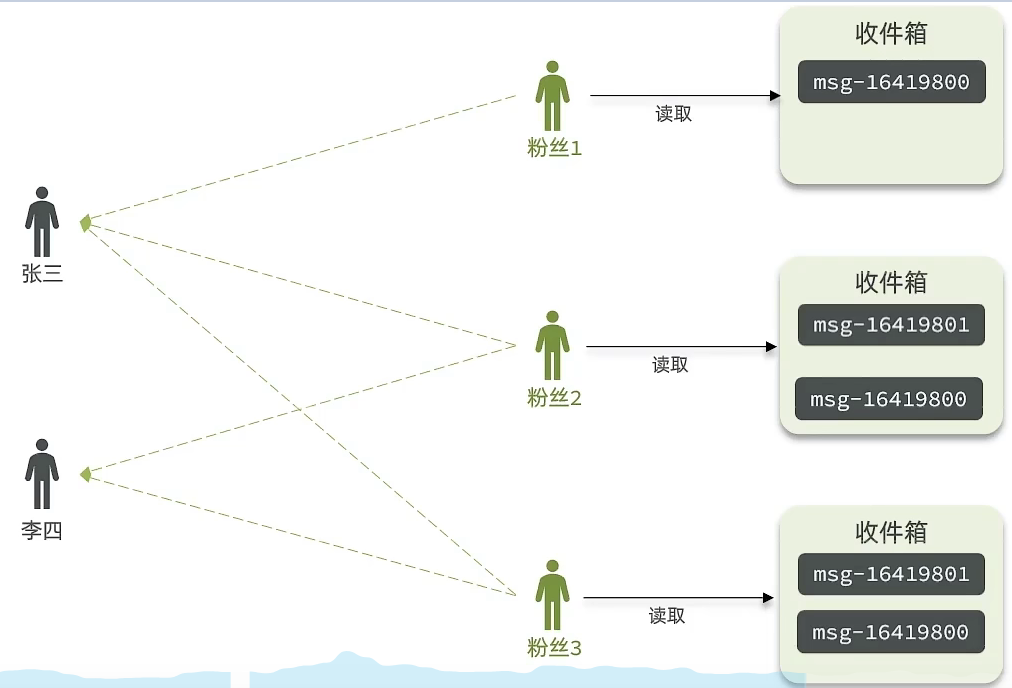
2)推模式(写扩散)
含义:推模式是没有写邮箱的。当张三发了一个消息,系统会主动地把张三发的内容推送到他的粉丝收件箱中去。假设他的粉丝李四要读取消息,只需要读取自己地收件箱,而不用再去临时拉取。
优点:时效快,不用临时拉取。
缺点:内存压力大,假设一个大V发消息,很多人关注他,就会写很多分数据到粉丝那边去。
-
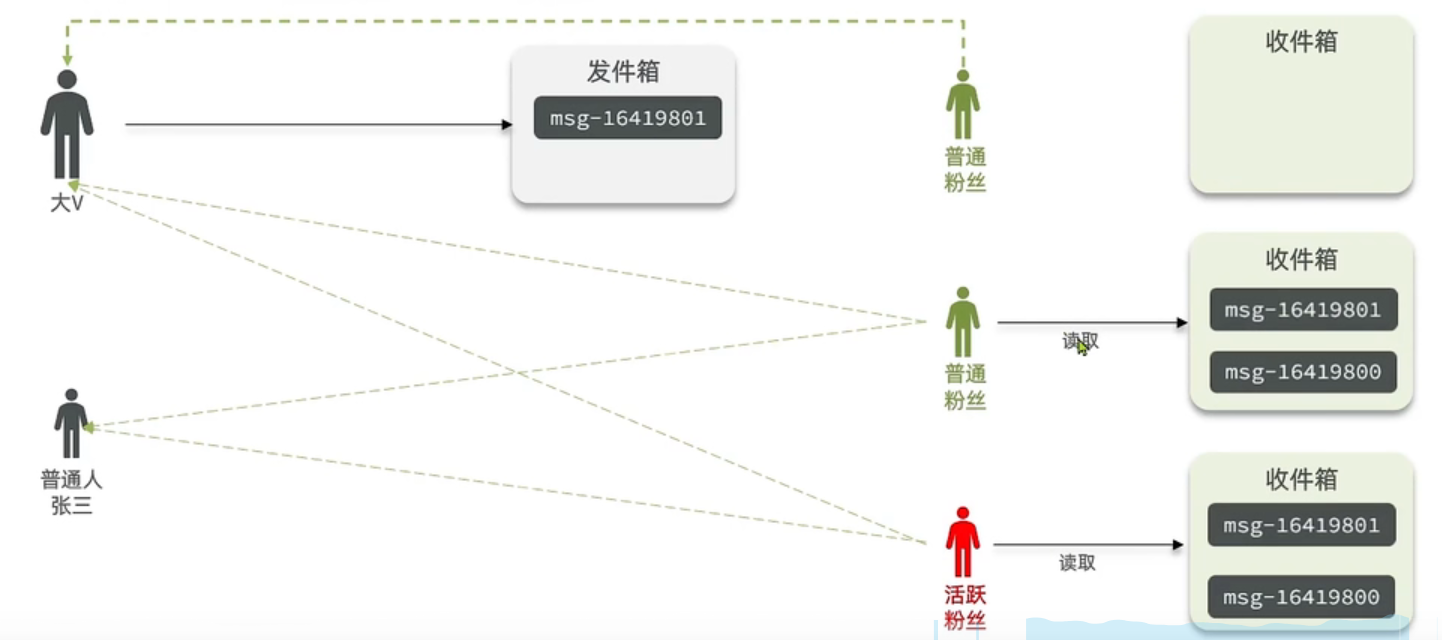
3)推拉结合(读写混合)
含义:推拉模式是一个折中的方案,兼具推和拉两种模式的优点。
站在发消息这一端:如果是个普通的用户,那么就采用推模式,直接把消息写入到他的粉丝中去,因为普通用户的粉丝关注量比较小,所以这样做没有压力;如果是大V,则直接将消息写到自己的发件箱,然后再写一份到活跃粉丝收件箱里边去。
站在收消息这一端:如果是活跃粉丝,那么大V和普通的用户发的消息都会直接写入到自己收件箱里边来;而如果是普通粉丝,由于上线不是很频繁,所以等上线时再从关注用户的收件箱里边去拉取信息。
4.9.3.3 实现推动到粉丝邮件箱功能
- 1)需求分析
新增探店笔记时,在保存Blog到数据库的同时,推送到粉丝的收件箱。收件箱可以根据时间戳排序,使用Redis的SortedSet数据结构实现。
- 2)代码实现
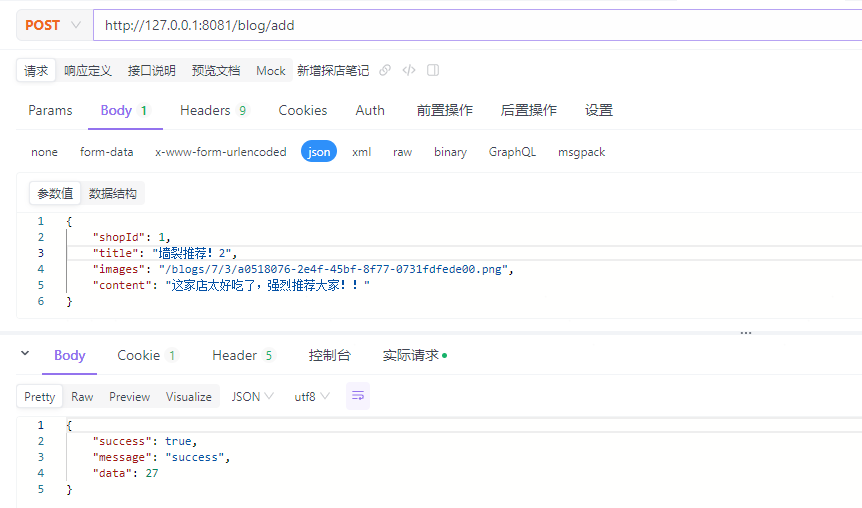
改造BlogController类的add()方法:
// com.star.redis.dzdp.controller.BlogController
@PostMapping("/add")
public BaseResult<Long> add(@RequestBody Blog blog, HttpServletRequest request) {
log.info("add {}", blog.toString());
// 1.设置探店笔记为登录用户的笔记
Long userId = (Long) request.getAttribute("userId");
blog.setUserId(userId);
// // 2.保存探店笔记
// blogService.save(blog);
// // 3.返回
// return BaseResult.setOkWithData(blog.getId());
return blogService.addBlog(blog);
}
在IBlogService接口定义一个addBlog()方法,并在BlogServiceImpl实现类中具体实现:
// com.star.redis.dzdp.service.impl.BlogServiceImpl
@Override
public BaseResult<Long> addBlog(Blog blog) {
log.info("addBlog: {}", blog.toString());
// 1.保存探店笔记
boolean save = save(blog);
if(!save) {
return BaseResult.setFail("发表失败!");
}
// 2.查询用户的所有粉丝 select * from t_follow where follow_user_id = ?
List<Follow> followList = followService.query().eq("follow_user_id", blog.getUserId()).list();
// 3.推送笔记ID给所有粉丝
if(followList != null && !followList.isEmpty()) {
log.info("当前用户粉丝数:{}", followList.size() );
for (Follow follow : followList) {
String key = "blog:feed:" + follow.getFollowUserId();
long score = System.currentTimeMillis();
stringRedisTemplate.opsForZSet().add(key, blog.getId().toString(), score);
log.info("add to ZSet: {} {} {}", key, score, blog.getId());
}
} else {
log.info("当前用户粉丝数:0");
}
// 4.返回ID
return BaseResult.setOkWithData(blog.getId());
}
- 3)功能测试
此时Redis中保存了数据:
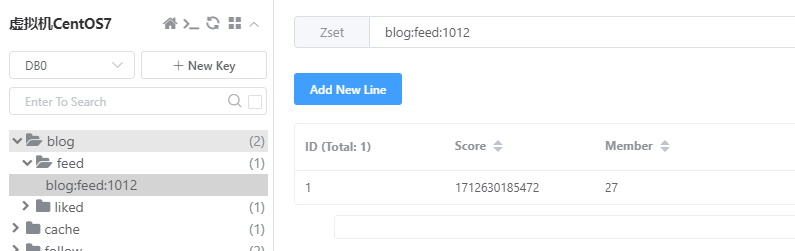
4.9.3.4 实现分页查询收件箱功能
- 1)需求分析
Feed流中的数据会不断更新,数据的下标也在不断变化,因此不能采用传统的分页模式。
传统方案:
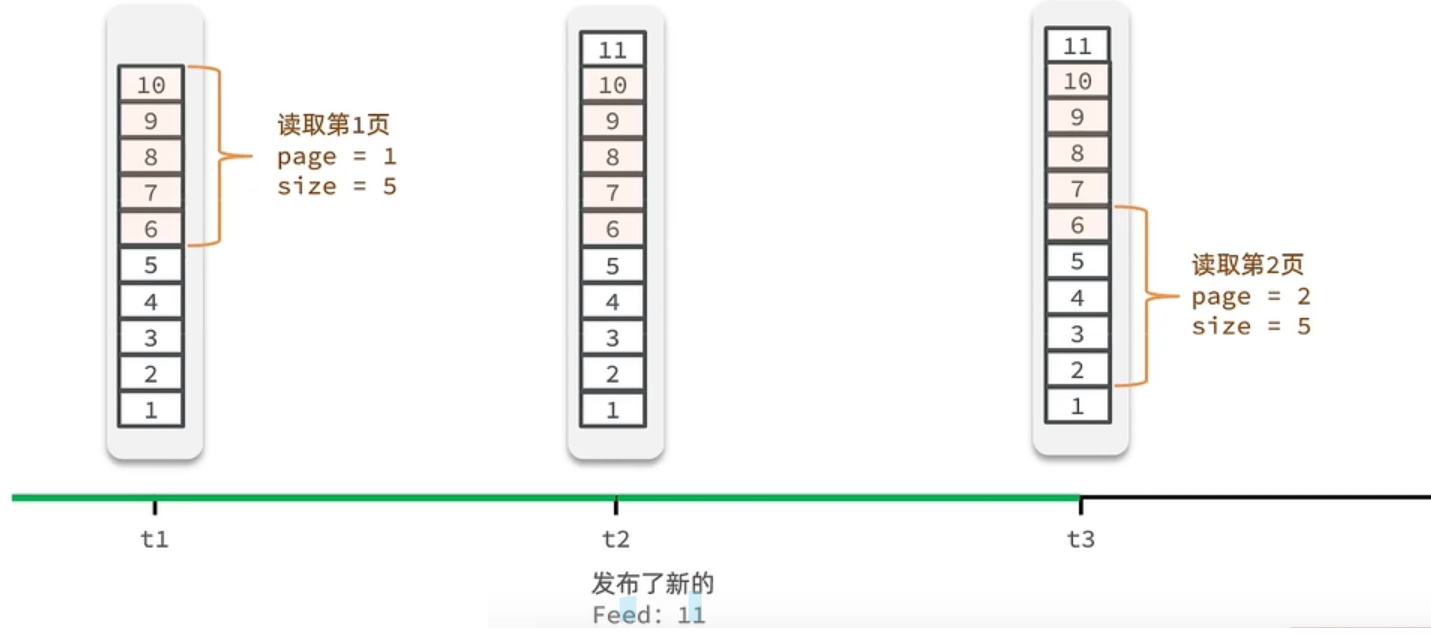
如上图所示,假设在t1时刻读取第一页,此时page=1,size=5,那么拿到的就是10~6这几条记录;
假设t2时刻又发布了一条记录,在t3时刻读取第二页,传入的参数是page=2,size=5,那么读取到的第二页实际上是6~2。
因此,使用传统方案读取到了重复的数据。
Feed流的滚动分页:
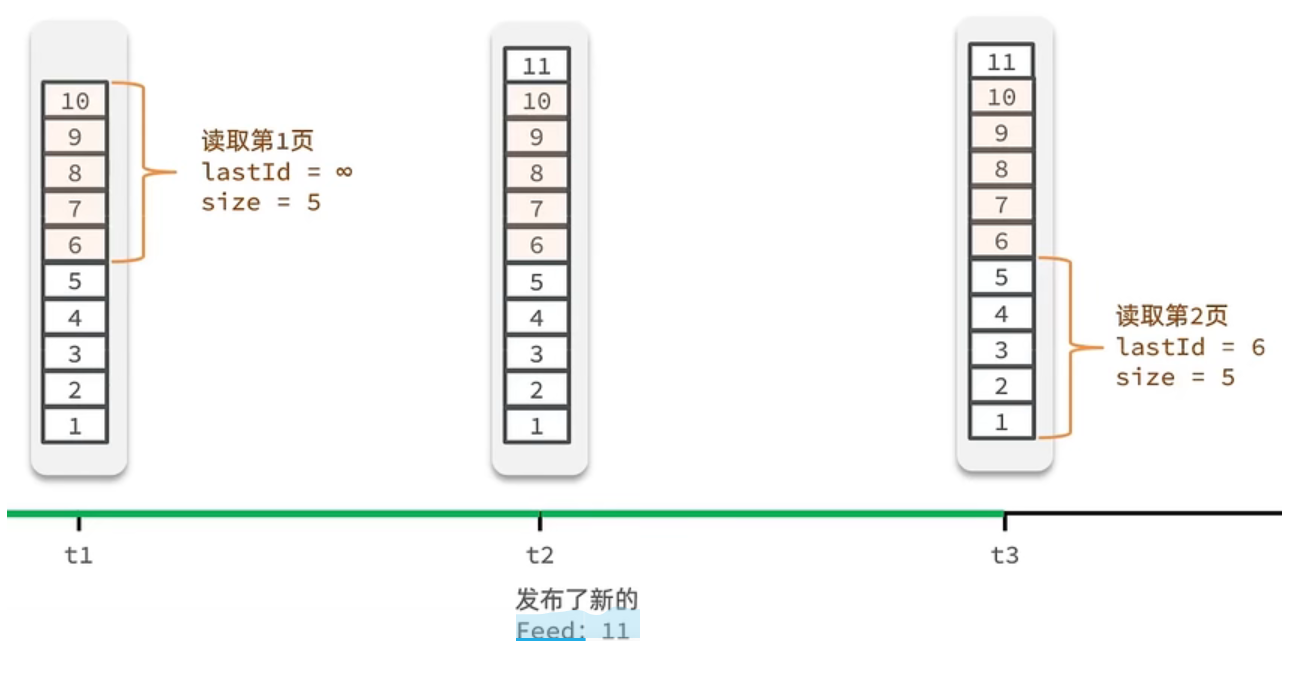
如上图所示,Feed流的滚动分页需要记录每次操作后的最后一条数据的下标。
假设在t1时刻读取第一页,此时lastId=10, size=5,那么拿到的就是10-6这几条记录,此时将lastId赋值为6;
假设t2时刻又发布了一条记录,在t3时刻读取第二页,传入的参数是lastId=6,size=5,那么读取到的第二页实际上是5~1。
综上,可以总结出分页查询收件箱的逻辑:
-
第一次查询时,由前端指定lastId和size参数,后续查询则使用后台返回结果作为条件;
-
根据lastId和size参数查询数据,并找出这组数据中的最小ID,赋值给lastId并返回前端。
-
在BlogServiceImpl类的
addBlog()方法中,将当前时间戳作为score存入SortedSet中,因此这里的lastId就是最小时间戳。 -
2)代码实现
接口文档如下:
| 项目 | 说明 |
|---|---|
| 请求方法 | GET |
| 请求路径 | /blog/feed |
| 请求参数 | minTime:Long类型,上一次查询时的最小时间戳 size:Integer类型,每页条数 |
| 返回值 | List<Blog>:小于指定时间戳的笔记集合 minTime:本次查询的最小时间戳 size:每页条数 |
根据接口文档,首先定义一个实体类用于接收数据:
// com.star.redis.dzdp.pojo.BlogFeed
@Data
@EqualsAndHashCode(callSuper = false)
public class BlogFeed implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 小于指定时间戳的笔记集合
*/
private List<Blog> blogList;
/**
* 本次查询的最小时间戳
*/
private Long minTime;
/**
* 每页条数
*/
private Integer size;
}
接着在BlogController类中创建一个feed()方法,用于实现分页查询关注用户的探店笔记列表:
// com.star.redis.dzdp.controller.BlogController
/**
* 分页查询关注用户的探店笔记列表
* @author hsgx
* @since 2024/4/9 10:14
* @param minTime 上一次查询的最小时间戳
* @param size 每页条数
* @param request
* @return com.star.redis.dzdp.pojo.BaseResult<com.star.redis.dzdp.pojo.BlogFeed>
*/
@GetMapping("/feed")
public BaseResult<BlogFeed> feed(Long minTime, Integer size, HttpServletRequest request) {
Long userId = (Long) request.getAttribute("userId");
return blogService.queryBlogFeed(minTime, size, userId);
}
然后在IBlogService接口定义一个queryBlogFeed()方法,并在BlogServiceImpl实现类中具体实现:
// com.star.redis.dzdp.service.impl.BlogServiceImpl
@Override
public BaseResult<BlogFeed> queryBlogFeed(Long minTime, Integer size, Long userId) {
log.info("queryBlogFeed: minTime = {}, size = {}, userId = {}",
minTime, size, userId);
// 1.查询收件箱 ZREVRANGEBYSCORE key max min LIMIT offset count
String key = "blog:feed:" + userId;
Set<ZSetOperations.TypedTuple<String>> typedTuples =
stringRedisTemplate.opsForZSet().reverseRangeByScoreWithScores(key, 0, minTime, 1, size);
log.info("=> ZREVRANGEBYSCORE {} {} 0 LIMIT 1 {}", key, minTime, size);
// 2.判断查询结果
if(typedTuples == null || typedTuples.isEmpty()) {
return BaseResult.setOk("查询结果为空");
}
// 3.解析数据
List<Long> ids = new ArrayList<>(typedTuples.size());
long newMinTime = 0;
for (ZSetOperations.TypedTuple<String> typedTuple : typedTuples) {
// 获取ID
ids.add(Long.valueOf(typedTuple.getValue()));
// 一直往下寻找最小时间
newMinTime = typedTuple.getScore().longValue();
}
// 4.根据ID查询探店笔记
String idStr = StrUtil.join(",", ids);
List<Blog> blogList = query().in("id", ids).last("ORDER BY FIELD(id," + idStr + ")").list();
// 5.封装并返回
BlogFeed blogFeed = new BlogFeed();
blogFeed.setBlogList(blogList);
blogFeed.setMinTime(newMinTime);
blogFeed.setSize(size);
return BaseResult.setOkWithData(blogFeed);
}
- 3)功能测试
目前用户收件箱有10条数据:
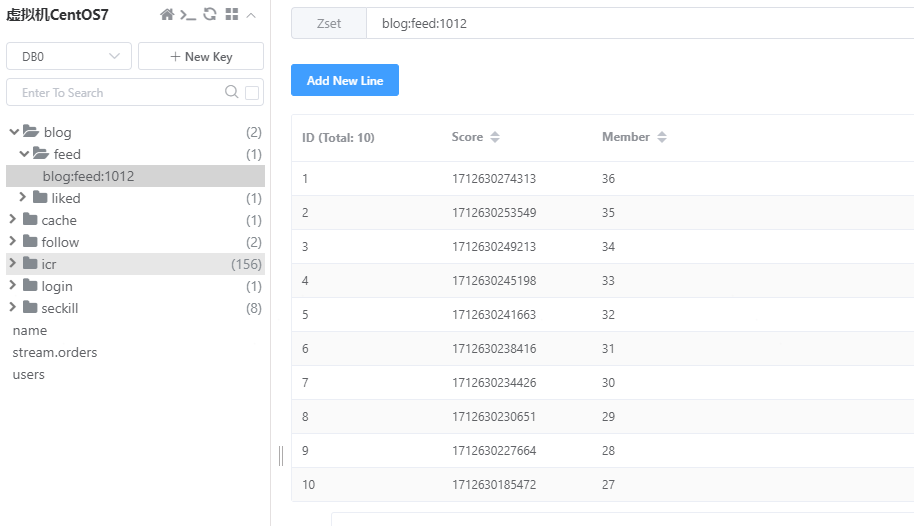
调用/blog/feed?minTime=1712630253549&size=2接口,预计可以查询出id为[34,33]的两条笔记,实际返回结果如下:
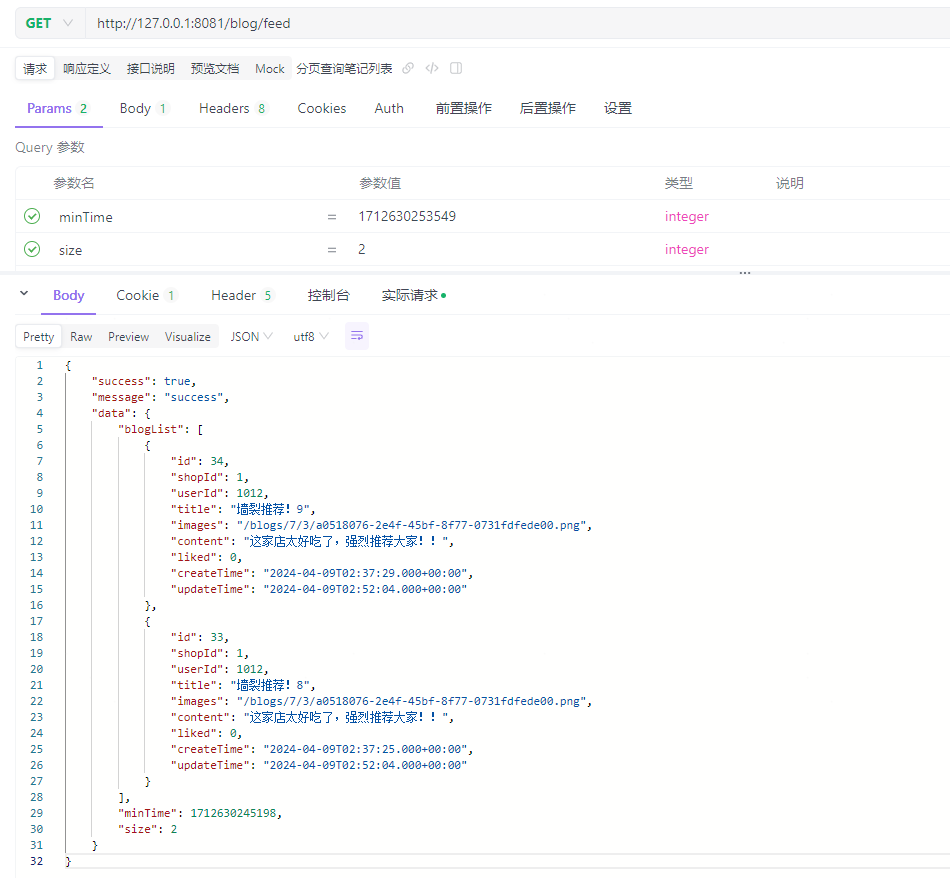
再以上面返回结果为参数,调用/blog/feed?minTime=1712630245198&size=2接口,预计可以查询出id为[32,31]的两条笔记,实际返回结果如下:
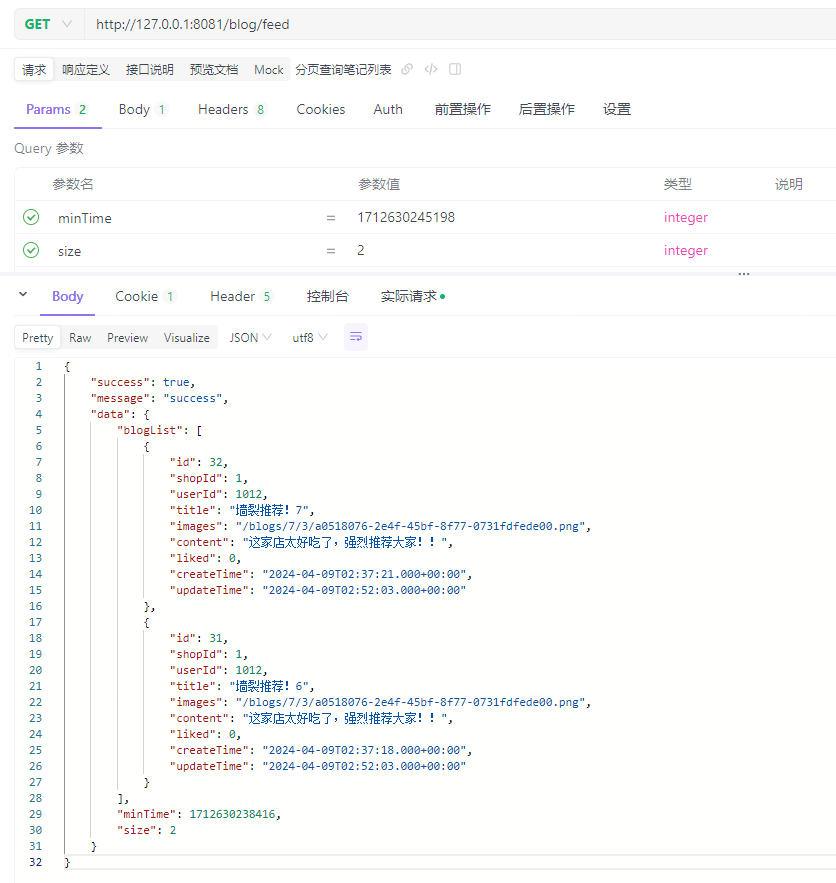
可见,分页查询关注用户的探店笔记列表完成。
…
本节完,更多内容请查阅分类专栏:Redis从入门到精通
感兴趣的读者还可以查阅我的另外几个专栏:
- SpringBoot源码解读与原理分析(已完结)
- MyBatis3源码深度解析(已完结)
- 再探Java为面试赋能(持续更新中…)





![HTML+CSS+JS实现京东首页[web课设代码+模块说明+效果图]](https://img-blog.csdnimg.cn/direct/52fb6ac94e07422199452723bc76d7dc.png)