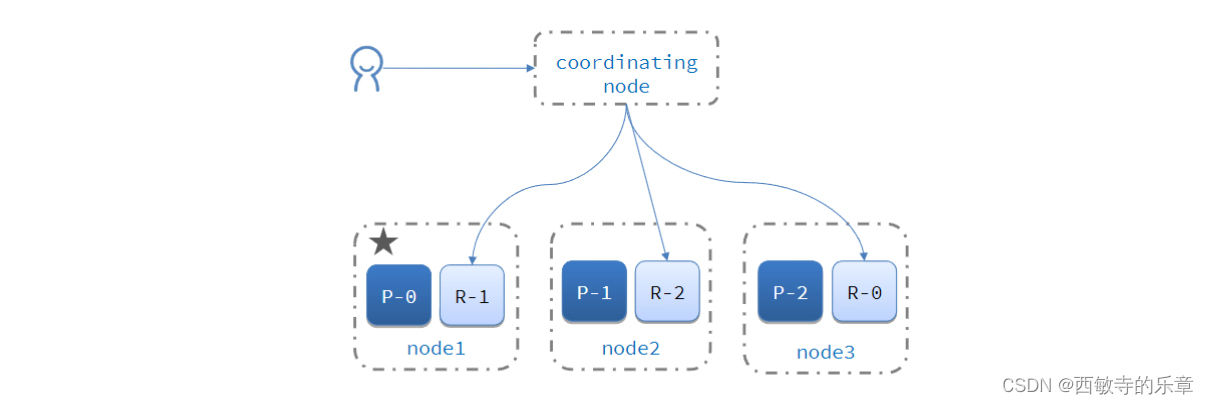
一、说明
IPU 是一种全新的大规模并行处理器,与Poplar® SDK共同设计,旨在加速机器智能。自第一代 Colossus IPU 以来,我们在芯片和系统架构中的计算、通信和内存方面取得了突破性进展,与 MK1 IPU 相比,实际性能提高了 8 倍。 GC200 是世界上最复杂的处理器,得益于 Poplar 软件,它变得易于使用,因此创新者可以实现人工智能突破。
二、图神经网络的硬件化

人与人之间交互的图形通过在时间戳 t₁ 和 t₂ 处获得新边缘而动态变化。
在在这篇文章中,我们探讨了TGN在不同大小的动态图中的应用,并研究了这类模型的计算复杂性。我们使用Graphcore的弓形智能处理单元(IPU)来训练TGN,并演示为什么IPU的架构非常适合解决这些复杂性,在将单个IPU处理器与NVIDIA A100 GPU进行比较时,可以将速度提高一个数量级。
TGN架构,我们在上一篇文章中详细描述过,它由两个主要组件组成:首先,节点嵌入是通过经典的图神经网络架构生成的,这里实现为单层图注意力网络[2]。此外,TGN 还保留了一个内存,总结了每个节点过去的所有交互。该存储通过稀疏读/写操作访问,并使用门控循环网络(GRU)[3]通过新的交互进行更新。

TGN 架构。底行表示具有单个消息传递步骤的 GNN。顶行说明了图形中每个节点的额外内存。
我们专注于通过获得新优势而随时间变化的图表。在这种情况下,给定节点的内存包含以此节点为目标的所有 Edge 及其各自目标节点的信息。通过间接贡献,给定节点的内存还可以保存有关更远节点的信息,从而使图注意力网络中的其他层变得可有可无。
三、应用于小图
我们首先在JODIE Wikipedia数据集[4]上试验TGN,这是一个维基百科文章和用户的二分图,其中用户和文章之间的每条边都代表用户对文章的编辑。该图由 9,227 个节点(8,227 个用户和 1,000 篇文章)和 157,474 条时间戳边组成,这些边用 172 维 LIWC 特征向量 [5] 注释,用于描述编辑。
在训练过程中,将边逐批插入到最初断开连接的节点集中,同时使用真实边和随机采样的负边的对比损失来训练模型。验证结果报告为在随机采样的负边上识别真实边的概率。
直观地说,大批量对训练和推理都有不利影响:节点内存和图形连接都只有在处理完整个批处理后才会更新。因此,一个批次中的后续事件可能依赖于过时的信息,因为它们不知道批处理中的早期事件。事实上,我们观察到大批量对任务性能的不利影响,如下图所示:
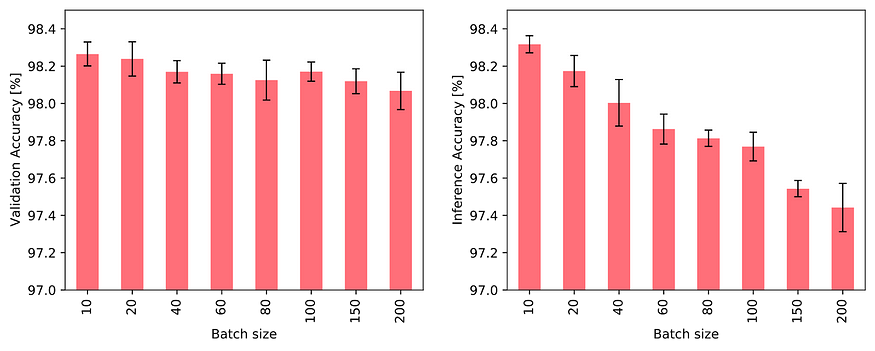
当使用不同的批量大小进行训练并使用固定的批量大小 10 进行验证(左)以及使用固定的批量大小 10 进行训练并使用不同的批量大小进行验证(右)时,TGN 对 JODIE/Wikipedia 数据的准确性。
H尽管如此,小批量的使用强调了快速内存访问对于在训练和推理期间实现高吞吐量的重要性。因此,与具有较小批量大小的GPU相比,具有大处理器内存的IPU表现出越来越大的吞吐量优势,如下图所示。特别是,当使用10个TGN的批量时,在IPU上训练的速度大约快11倍,即使使用200个大批量的训练,在IPU上训练的速度仍然快3倍左右。
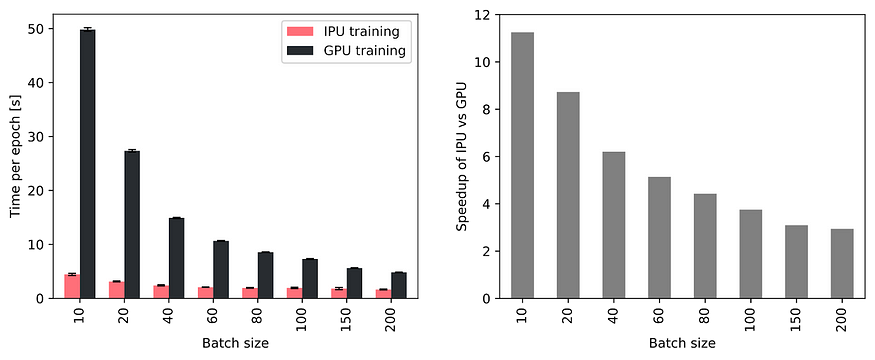
与NVIDIA A100 GPU相比,使用Bow2000 IPU系统中的单个IPU时,不同批量大小的吞吐量有所提高。
自为了更好地理解TGN在Graphcore的IPU上训练的吞吐量的提高,我们调查了不同硬件平台在TGN的关键操作上所花费的时间。我们发现,花在GPU上的时间主要由Attention模块和GRU,这两个操作在IPU上执行效率更高。此外,在所有操作中,IPU可以更有效地处理小批量。
特别是,我们观察到IPU的优势随着更小和更碎片化的内存操作而增长。更一般地说,我们得出的结论是,当计算和内存访问非常异构时,IPU架构比GPU具有显着优势。

TGN在IPU和GPU上不同批量大小的关键操作的时间比较。
四、缩放到大型图形
虽然默认配置下的TGN模型相对轻量级,大约有260,000个参数,但当将模型应用于大型图形时,大部分IPU处理器内存都由节点内存使用。但是,由于它的访问稀疏,因此可以将该张量移动到片外存储器中,在这种情况下,处理器内存利用率与图形的大小无关。
自在大型图上测试TGN架构,我们将其应用于包含1550万Twitter用户之间的2.61亿关注者的匿名图[6]。边缘分配了 728 个不同的时间戳,这些时间戳尊重日期顺序,但在发生以下事件时不提供有关实际日期的任何信息。由于此数据集中不存在节点或边缘特征,因此该模型完全依赖于图拓扑和时间演变来预测新链接。
由于与单个负样本相比,大量数据使得识别正边的任务过于简单,因此我们使用 1000 个随机采样的负边中真实边的平均倒数秩 (MRR) 作为验证指标。此外,我们发现,当增加数据集大小时,模型性能受益于更大的隐藏大小。对于给定的数据,我们将潜在大小 256 确定为准确性和吞吐量之间的最佳点。
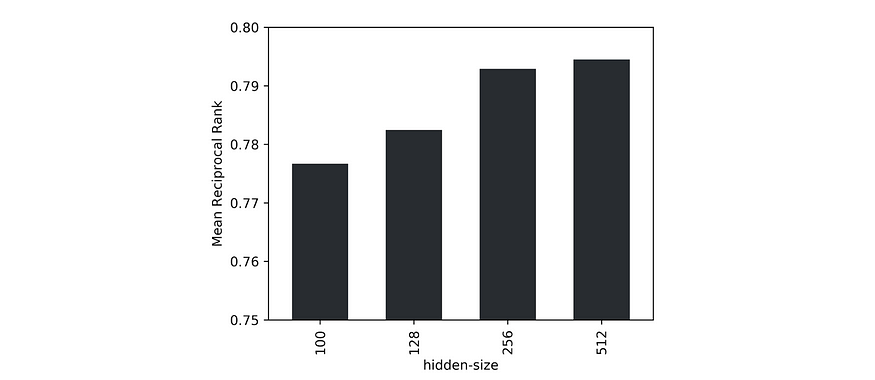
模型不同隐藏大小的 1000 个负样本之间的平均倒数排名。
U节点内存的单片外存储器可将吞吐量降低约两倍。然而,使用不同大小的诱导子图以及具有 10×Twitter 图节点数和随机连通性的合成数据集,我们证明了吞吐量几乎与图的大小无关(见下表)。在IPU上使用这种技术,TGN可以应用于几乎任意的图形大小,仅受可用主机内存量的限制,同时在训练和推理期间保持非常高的吞吐量。
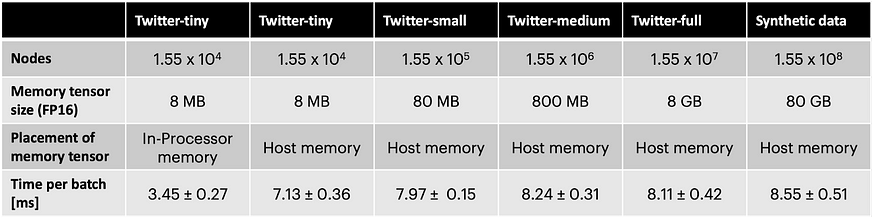
每批大小 256 在不同图形大小上训练具有隐藏大小 256 的 TGN 的时间。Twitter-tiny 的大小与 JODIE/Wikipedia 数据集相似。
如我们之前已经反复指出,选择硬件来实现 Graph ML 模型是一个关键但经常被忽视的问题。特别是在研究界,云计算服务的可用性抽象出底层硬件,导致这方面有一定的“懒惰”。但是,当涉及到在具有实时延迟要求的大规模数据集上实现系统时,硬件考虑不再容易。我们希望我们的研究能够引起人们对这一重要课题的更多关注,并为未来更高效的Graph ML应用算法和硬件架构铺平道路。






![[react] useState的一些小细节](https://img-blog.csdnimg.cn/direct/418e7951b9b94d9fa62d5f54724c8eae.png)