InsectMamba:基于状态空间模型的害虫分类
- 摘要
- Introduction
- Related Work
- Image Classification
- Insect Pest Classification
- Preliminaries
- InsectMamba
- Overall Architecture
InsectMamba: Insect Pest Classification with State Space Model
摘要
害虫分类是农业技术中的关键任务,对于确保食品安全和环境可持续性至关重要。然而,由于害虫具有高度的伪装性和物种多样性等因素,害虫识别的复杂性构成了重大障碍。现有方法在提取区分密切相关的害虫种类的细微特征方面存在困难。尽管近期的研究通过修改网络结构和结合深度学习方法提高了准确性,但由于害虫与其周围环境的相似性,挑战依然存在。
为了解决这个问题,作者引入了InsectMamba,这是一种新颖的方法,它将状态空间模型(SSMs)、卷积神经网络(CNNs)、多头自注意力机制(MSA)和多层感知器(MLPs)整合到混合SSM块中。这种整合利用了每种编码策略的优势,促进了全面视觉特征的提取。同时,还提出了一个选择模块,以自适应地聚合这些特征,增强了模型辨别害虫特征的能力。
InsectMamba在五个害虫分类数据集上与强竞争者进行了评估。结果显示了其卓越的性能,并通过消融研究验证了每个模型组件的重要性。
Introduction
在农业生产中,由于害虫显著影响作物产量,农业技术中害虫的识别和分类对于确保食品安全和可持续性至关重要。害虫分类旨在利用视觉模型来自动识别害虫。这一任务对于维护作物健康,潜在减少农药使用,促进环境可持续的农业实践至关重要。此外,准确识别害虫有利于通过最小化损害和优化产量来管理作物。
由于害虫在其自然栖息地中常常表现出高度的伪装,这使得视觉识别变得困难。这一挑战也展示了害虫分类的复杂性。害虫与周围环境的相似性,加上物种的巨大多样性,给传统图像处理算法带来了重大障碍。此外,为了区分密切相关的害虫物种,需要细粒度的特征提取,这为这一挑战增加了另一层复杂性。最近的研究提出了利用改进的胶囊网络来改善网络结构,从而增强特征的分层次和空间关系,以提高分类准确性。此外,一些研究结合了多个深度网络和多重视角下的互补特征优势,以提高识别率和鲁棒性。然而,由于害虫与周围环境的相似性,这些方法仍面临挑战。
为了准确识别和分类在不同条件下害虫的挑战,不同的视觉编码策略提供了不同的优势。卷积神经网络擅长于局部特征提取,而多头自注意力机制则擅长捕捉全局特征。状态空间模型结构在识别长距离依赖方面特别有效,多层感知器专长于通道感知信息推理。
为了整合不同视觉编码策略的优势,作者提出了一种新颖的方法,InsectMamba,它由混合SSM块组成,整合了SSM、CNN、MSA和MLP,以提取更全面的视觉特征用于害虫分类。此外,作者提出了一种选择模块,以适应性地聚合来自不同编码策略的视觉特征。InsectMamba利用了这些视觉编码策略的互补能力,旨在使视觉模型在捕捉害虫的局部和全局特征方面发挥作用,从而解决伪装和物种多样性的关键挑战。
在实验中,作者在五个害虫分类数据集上评估了InsectMamba和其他强劲的竞争者。为了提高数据集的挑战性,作者重新分割了数据集。实验结果表明,InsectMamba优于其他方法,这证明了InsectMamba的有效性。此外,作者进行了消融研究,以验证InsectMamba中每个模块的重要性。此外,作者对模型设计进行了广泛的分析,以证明其有效性。
本研究的主要贡献如下:
- 作者提出了InsectMamba,这是首次尝试在害虫分类中应用基于SSM的模型。
- 作者提出了混合SSM块,它无缝整合了SSM、CNN、MSA和MLP。这种整合使InsectMamba能够捕捉到用于害虫分类的全面视觉特征。
- 作者提出了一种选择聚合模块,旨在适应性地组合来自不同编码策略的视觉特征。该模块允许模型选择用于分类的相关特征。
- 作者在五个害虫分类数据集上严格评估了InsectMamba,与现有模型相比,展示了其卓越的性能。
Related Work
Image Classification
计算机视觉技术的快速发展使其在各种领域得到广泛应用,包括人工智能安全、生成检测、生物医学和农业技术。特别地,图像分类作为计算机视觉中许多应用的基本技术,其目的是区分不同类别的图像。一些研究采用卷积神经网络(CNNs)进行图像分类,因为卷积层能够捕捉图像中的局部特征。例如,由五个卷积层和三个全连接层组成的AlexNet在图像分类性能上取得了巨大成功。VGG和ResNet分别通过增加原始网络的深度和整合跳跃连接来进一步提升模型的分类能力。
然而,CNNs在理解全局信息方面存在局限,并且在捕捉全局和长距离依赖时缺乏鲁棒性。Vision Transformer (ViT)利用多头自注意力(MSA)捕捉每个块的环境信息,从而增强了模型捕捉全局依赖的能力。此外,Swin Transformer采用了一种窗口化的自注意力机制和分层结构设计,这不仅保留了MSA的全局建模能力,还增强了局部特征的提取。此外,MLP-Mixer提出了一种基于纯MLP的架构,以捕捉不同的上下文关系并增强视觉表示。此外,VMamb 通过将新颖的序列状态空间(S4)模型与选择机制和扫描计算相结合,改进了视觉分类任务,这一模型被称为Mamba。
Insect Pest Classification
对于昆虫害虫分类任务,它可以帮助人们更好地了解害虫的种群动态和潜在危害,制定有效的害虫管理策略,这对于农业经济和环境科学非常重要。然而,与一般图像相比,昆虫害虫领域的特征差异可能非常微妙,背景更为复杂,这对分类模型提出了更高的要求,需要更准确地提取有效特征。针对这一挑战,一些研究改进了基于CNN的模型,以在复杂背景下捕捉害虫特征。
此外,Faster-PestNet使用MobileNet提取样本属性,并重新设计了改进的Faster-RCNN方法来识别作物害虫。Ung等人[33]提出了一个带有注意力机制的基于CNN的模型,以进一步关注图像中的昆虫;An等人[2]提出了一种特征融合网络,该网络合成来自不同主干模型的表示以增强昆虫图像分类;Anwar和Masood采用深度集成模型方法提高从图像中检测昆虫和害虫的准确性和鲁棒性。此外,Peng和Wang[27]在昆虫领域研究了ViT架构,并将CNNs和自注意力模型聚合起来,以进一步提高昆虫害虫分类的能力。
Preliminaries
卷积神经网络由于其强大的图像特征提取能力,在计算机视觉中得到了广泛应用。它由一组固定大小的可学习参数组成,这些参数被称为滤波器,并通过滑动窗口在输入图像上连续执行卷积计算。
具体来说,对于给定的视觉特征V∈RHxWxC,其中H、W和C分别表示高度、宽度和通道数,作者可以使用尺寸为Fu、Fh、Cn的卷积核u来计算视觉特征中每个通道的像素值,即:
![Vout[i,j,k]= >y-1(>盈d>o' V[i × S + m,jx S+n,lx u[m, n, l,k)+ b[lk](https://img-blog.csdnimg.cn/direct/eec400946b7c473996fe77fa3d2caefd.png)
其中Vout是输出特征图,(i,j, k)是索引,S是步长,b[]是第k个通道的偏置。通过级联结构,CNN可以从原始数据中逐渐从低级到高级学习特征表示,并最终实现有效的分类。
Multi-Head Self-Attention
Vaswani等人提出了多头自注意力(MSA)机制,并被广泛应用于许多自然语言处理任务中。与卷积神经网络不同,MSA允许模型在生成输出表示时对不同的输入标记的重要性进行加权,使模型能够有效地捕捉序列中的全局依赖关系和上下文信息。最近,类似Transformer的架构在计算机视觉领域也展示了强大的建模能力。
对于给定的视觉特征
V
∈
R
H
×
W
×
C
V \in \mathbb{R}^{H \times W \times C}
V∈RH×W×C,视觉特征的多头自注意力建模可以定义为:
Attn = softmax ( Q K T d k ) , 其中 Q = W q ⋅ V , K h = W k ⋅ V , \text{Attn} = \text{softmax}(\frac{QK^T}{\sqrt{d_k}}), \quad \text{其中} \quad Q = W_q \cdot V, \quad K_h = W_k \cdot V, Attn=softmax(dkQKT),其中Q=Wq⋅V,Kh=Wk⋅V,
其中, W q ∈ R D × d W_q \in \mathbb{R}^{D \times d} Wq∈RD×d 和 W k ∈ R D × d W_k \in \mathbb{R}^{D \times d} Wk∈RD×d 是线性投影,它们将 D D D 维输入向量投影到查询(Query) Q ∈ R N × d Q \in \mathbb{R}^{N \times d} Q∈RN×d 和键(Key) K ∈ R N × d K \in \mathbb{R}^{N \times d} K∈RN×d。每个注意力矩阵 Attn \text{Attn} Attn 用于乘以值(Value)以获得融合了全局信息的更新表示,即:
V : = Attn ⋅ V , 其中 V h = W v ⋅ V . V := \text{Attn} \cdot V, \quad \text{其中} \quad V_h = W_v \cdot V. V:=Attn⋅V,其中Vh=Wv⋅V.
在视觉任务中,多头自注意力(MSA)需要在大规模数据集上进行预训练,以弥补其在CNN中的归纳偏差不足,例如平移不变性和局部性。这样的预训练有助于模型学习到更好的特征表示,从而提高模型在各种视觉任务上的性能。
Multi-Layer Perceptron
多层感知机(MLP)是用于许多任务中常见的神经网络层。MLP主要包含N个线性层,每个层都有可学习的权重和偏置参数以及激活函数。激活函数用于映射输入和输出之间的非线性关系。
对于给定的视觉特征
V
∈
R
H
×
W
×
C
V \in \mathbb{R}^{H \times W \times C}
V∈RH×W×C,仅与通道相关的 MLP(多层感知机),将每个通道映射到一个
D
D
D 维隐藏向量
h
i
h_i
hi,具体如下:
h i = Activation ( ∑ j = 1 C ( W i j ∗ c j ) + b i ) , W ∈ R C × D , b ∈ R D , h_i = \text{Activation}(\sum_{j=1}^{C} (W_{ij} * c_j) + b_i), \quad W \in \mathbb{R}^{C \times D}, \quad b \in \mathbb{R}^D, hi=Activation(j=1∑C(Wij∗cj)+bi),W∈RC×D,b∈RD,
其中 h i h_i hi 是 H H H 的第 i i i 维,通过加权 C C C 个通道和权重矩阵 W W W 的第 i i i 列中的可学习参数得到。Activation 是一个激活函数,它通过非线性变换调整输出。
在这个公式中,首先对输入的每个通道
c
j
c_j
cj 和权重矩阵
W
W
W 的第
i
i
i 列进行点乘操作,然后将所有点乘的结果求和。接着加上偏置项
b
i
b_i
bi,最后通过激活函数 Activation 进行非线性变换,得到隐藏向量
h
i
h_i
hi。整个过程可以理解为对输入特征的每个通道进行了特征提取和加权求和,并通过激活函数引入了非线性变换,从而得到了隐藏向量。
State Space Models
状态空间模型(SSMs)引入了一种新颖的跨扫描模块(CSM),以提高方向敏感性和计算效率。SSMs在通过描述时间演化和观测生成的方程来模拟视觉系统动态方面至关重要。观测函数如下:
在给定的系统动态模型中,我们有以下方程:
在给定的系统动态模型中,我们有以下方程:
系统状态更新方程:
[
x
t
+
1
=
A
⋅
x
t
+
B
⋅
u
t
+
W
t
]
[ x_{t+1} = A \cdot x_t + B \cdot u_t + W_t ]
[xt+1=A⋅xt+B⋅ut+Wt]
观测更新方程:
[
y
t
=
C
⋅
x
t
+
D
⋅
u
t
+
V
t
]
[ y_t = C \cdot x_t + D \cdot u_t + V_t ]
[yt=C⋅xt+D⋅ut+Vt]
其中:
- ( x_t ) 表示时间 ( t ) 的系统状态,
- ( u_t ) 代表控制输入,
- ( W_t ) 是过程噪声,表示状态转换中的不确定性,
- ( y_t ) 是时间 ( t ) 的观测,
- ( V_t ) 是观测噪声,突显了模型观测与实际观测之间的差异,
- 矩阵 ( A )、( B )、( C ) 和 ( D ) 定义了系统的动态,将状态转换与观测联系起来。
此外,跨扫描模块(CSM)可以进一步处理方向敏感性,将视觉特征结构化为有序的 Patch 序列。其过程如下:
[ CSM(V) = Order(Traverse(V)) ]
其中 ( V ) 是视觉特征输入。这个过程允许有效地处理空间信息,并提高模型的动态处理能力。
InsectMamba
详细阐述了作者的InsectMamba模型架构,这是一种用于害虫分类的新颖视觉模型。InsectMamba的基础是Mix-SSM块,旨在融合来自各种视觉编码策略的特征。最后,作者引入了作者提出的选择性模块,它可以自适应地整合来自不同视觉编码策略的表示。
Overall Architecture
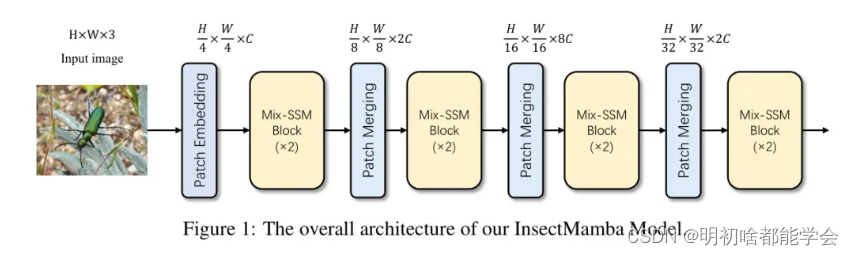
对不起,让我重新翻译第一段文字:
在图1所示的过程中,给定一张图像 ( I \in \mathbb{R}^{H \times W \times 3} ),图像首先被分割成多个不重叠的 ( 4 \times 4 ) 图块。然后,使用图块嵌入层将这些图块转换到低维潜在空间中,得到尺寸为 ( H’ \times W’ \times C ) 的特征张量,其中 ( C ) 表示潜在空间中的通道数,即:
V = PatchEmbed ( I ) , V ∈ R H ′ × W ′ × C V = \text{PatchEmbed}(I), \quad V \in \mathbb{R}^{H' \times W' \times C} V=PatchEmbed(I),V∈RH′×W′×C
接下来,作者将特征 ( V ) 传递到 Mix-SSM 块中进行特征提取,并通过 Patch Merging 操作实现降维,即:
V = PatchMerging ( Mix-SSM-Block ( V ) ) V = \text{PatchMerging}(\text{Mix-SSM-Block}(V)) V=PatchMerging(Mix-SSM-Block(V))
在经过多次 Mix-SSM 块和 Patch Merging 操作的迭代后,得到图像的最终视觉表示 ( v \in \mathbb{R}^5 )。最后, ( v ) 通过一个线性层 ( \text{Linear} ) 转换其维度到类别数,即:
h = Linear ( v ) , p = softmax ( h ) h = \text{Linear}(v), \quad p = \text{softmax}(h) h=Linear(v),p=softmax(h)
其中 softmax 将隐藏特征 ( h ) 转换为每个类别 ( p ) 的概率分布。



![[lesson15]类与封装的概念](https://img-blog.csdnimg.cn/direct/7fc714c15b05423fbaaf654a970dd75c.png#pic_center)