文本加载和分块
一、文本加载
文本加载是RAG文本增强检索重要环节。文件有不同类型(excel、word、ppt、pdf、png、html、eps、gif、mp4、zip等),衍生出了很多第三方库。使用python处理文件是各种python开发岗位都需要的操作。主要涉及到的标准库包括io、os、sys、csv等,涉涉及常用的第三方库包括numpy、pandas、openpyxl、xlwt、xlrd、xlsxwriter、reportlab等。RAG文本加载库主要包括open、numpy、Pandas、langchain等,使用案例如下:
1、Python自带库open库
file 对象使用 open 函数来创建
f = open(路径名, ‘r’)
print (f)
d = csv.reader(f)
for line in d:
print (line)
f.close()
2、numpy库
import numpy as np
p = np.loadtxt(路径名, delimiter=‘,’, skiprows=1)
print §
3、Pandas库
import pandas as pd
data = pd.read_csv(路径名) # TV、Radio、Newspaper、Sales
x = data[[‘TV’, ‘Radio’, ‘Newspaper’]]
y = data[‘Sales’]
print (x)
print (y)
4、langchain相关包
langchain提供了很多文档加载的类,以便进行不同的文件加载,这些类都通 过 langchain.document_loaders 引入。例如:UnstructuredFileLoader(txt文件 读取)、UnstructuredFileLoader(word文件读取)、MarkdownTextSplitter(m arkdown文件读取)、UnstructuredPDFLoader(PDF文件读取)。
#加载txt文件
def load_txt_file(txt_file):
loader = UnstructuredFileLoader(os.path.join(work_dir, txt_file))
docs = loader.load()
print(docs[0].page_content[:100])
return docs
#加载pdf文件
def load_pdf_file(pdf_file):
loader = UnstructuredPDFLoader(os.path.join(work_dir, pdf_file))
docs = loader.load()
print(‘pdf:\n’,docs[0].page_content[:100])
return docs
二、文本分块
1、什么是分块
在构建RAG这类基于LLM的应用程序中,分块(chunking)是将大块文本分解成小段的过程。当我们使用LLM embedding内容时,这是一项必要的技术,可以帮助我们优化从向量数据库被召回的内容的准确性。
对于大语言模型,往往单次传入的token长度是有限的。因此在加载完成后,还需要对文件进行分割,这样才能更准确的被模型所理解。分割默认有两个关键参数:chunk_size:每个分割段的最大长度;chunk_overlap:相邻两个分割段之间的重叠token数量。这两个参数可以 根据实际需要来配置。
2、分块算法
2.1、固定大小的分块
这是最常见、最直接的分块方法:我们只需决定一个文本块中的分词数量,以及选择性地决定文本块之间可否进行交叠(overlap)。一般来说,我们希望在文本块块之间保留一些交叠,这样可以防止上下文的语义不会丢失。大多数常见情况下,定长分块是最佳路径。与其他形式的分块相比,定长分块计算成本低且易于使用,因为不需要使用任何NLP库。使用CharacterTextSplitter,一般的设置参数为:chunk_size、 chunk_overlap、separator和strip_whitespace。
text = “…” # your text
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator = “\n\n”,
chunk_size = 256,
chunk_overlap = 20
)
docs = text_splitter.create_documents([text])
2.2“内容感知”分块
朴素切分:最简单的方法是按句点(“.”)和换行符切分句子。虽然这可能既快速又简单,但这种方法不会考虑所有可能的边缘情况。下面是一个非常简单的示例:
text = “…” # your text
docs = text.split(“.”)
NLTKopen in new window:自然语言工具包(NLTK)是一个流行的Python库,用于处理人类语言数据。它提供了一个句子分词器,可以将文本切分为句子,帮助创建更有意义的块。例如,要将NLTK与LangChain一起使用,您可以执行以下操作:
text = “…” # your text
from langchain.text_splitter import NLTKTextSplitter
text_splitter = NLTKTextSplitter()
docs = text_splitter.split_text(text)
spaCyopen in new window:spaCy是另一个强大的Python库,用于NLP任务。它提供了复杂的分句功能,可以有效地将文本划分为单独的句子,从而在生成的块中更好地保留上下文。例如,要将spaCy与LangChain一起使用,您可以执行以下操作:
text = “…” # your text
from langchain.text_splitter import SpacyTextSplitter
text_splitter = SpaCyTextSplitter()
docs = text_splitter.split_text(text)
2.3、递归分块
递归分块使用一组分隔符以分层和迭代方式将输入文本划分为较小的块。如果拆分文本的初始尝试未生成所需大小或结构的块,则该方法会使用不同的分隔符或条件递归调用生成的块,直到达到所需的块大小或结构。这意味着,虽然块的大小不会完全相同,但它们仍然追求具有相似的大小。下面是如何在 LangChain 中使用递归分块的示例:
text = “…” # your text
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter
Set a really small chunk size, just to show.
chunk_size = 256,
chunk_overlap = 20
2.4、专用分块
Markdown和LaTeX是您可能会遇到的结构化和格式化内容的两个例子。在这些情况下,您可以使用专门的分块方法在分块过程中保留内容的原始结构。
Markdownopen in new window:Markdown 是一种轻量级标记语言,通常用于格式化文本。通过识别 Markdown 语法(例如,标题、列表和代码块),您可以根据内容的结构和层次结构智能地划分内容,从而产生语义上更一致的块。例如:
from langchain.text_splitter import MarkdownTextSplitter
markdown_text = “…”
markdown_splitter = MarkdownTextSplitter(chunk_size=100, chunk_overlap=0)
docs = markdown_splitter.create_documents([markdown_text])
LaTexopen in new window:LaTeX是一种文档准备系统和标记语言,通常用于学术论文和技术文档。通过解析 LaTeX 命令和环境,您可以创建尊重内容逻辑组织(例如,部分、子部分和公式)的块,从而获得更准确和上下文相关的结果。例如:
from langchain.text_splitter import LatexTextSplitter
latex_text = “…”
latex_splitter = LatexTextSplitter(chunk_size=100, chunk_overlap=0)
docs = latex_splitter.create_documents([latex_text])
2.5、语义分块
我们是否觉得为块大小设置一个全局常量很奇怪?我们的普通分块机制是否更奇怪,因为它们没有考虑实际内容?嵌入表示了字符串的语义含义。它们本身并没有太多作用,但是当与其他文本的嵌入进行比较时,您可以开始推断块之间的关系。利用这个特性,探索使用嵌入来找到语义上相似的文本聚类。假设是语义上相似的块应该放在一起。
2.6、LLM 分块
我们是否可以命令LLM执行此任务?人类是如何进行分块的呢?我们会如何将文档分块成具有语义相似性的离散部分?我会准备一张草稿纸或记事本。我会从文章的顶部开始,假设第一部分将是一个块(因为我们还没有任何块)。然后,我会继续阅读文章,评估新的句子或文章片段是否应该成为第一个块的一部分,如果不是,就创建一个新的块。
3、分块策略选择
3.1、考虑分块大小
在语义搜索中,我们索引一个文档语料库,每个文档包含一个特定主题的有价值的信息。通过使用有效的分块策略,我们可以确保搜索结果准确地捕获用户查询的需求本质。如果我们的块太小或太大,可能会导致不精确的搜索结果或错过展示相关内容的机会。根据经验,如果文本块尽量是语义独立的,也就是没有对上下文很强的依赖,这样子对语言模型来说是最易于理解的。因此,为语料库中的文档找到最佳块大小对于确保搜索结果的准确性和相关性至关重要。另一个例子是会话Agent。我们使用embedding的块为基于知识库的会话agent构建上下文,该知识库将代理置于可信信息中。在这种情况下,对分块策略做出正确的选择很重要,原因有两个:
- 首先,它将决定上下文是否与我们的prompt相关。
- 其次,考虑到我们可以为每个请求发送的tokens数量的限制,它将决定我们是否能够在将检索到的文本合并到prompt中发送到大模型(如OpenAI)。
参考:https://zhuanlan.zhihu.com/p/676979306
找出最适合应用程序的块大小:
预处理数据 - 在确定应用程序的最佳块大小之前,你需要首先预处理数据以确保质量。 例如,如果你的数据是从网络检索的,可能需要删除 HTML 标签或只会增加噪音的特定元素。
选择块大小范围 - 数据经过预处理后,下一步是选择要测试的潜在块大小范围。 如前所述,选择应考虑内容的性质(例如,短消息或冗长的文档)、你将使用的嵌入模型及其功能(例如,令牌限制)。 目标是在保留上下文和保持准确性之间找到平衡。 首先探索各种块大小,包括用于捕获更细粒度语义信息的较小块(例如,128 或 256 个标记)和用于保留更多上下文的较大块(例如,512 或 1024 个标记)。
评估每个块大小的性能 - 为了测试各种块大小,你可以使用多个索引或具有多个命名空间的单个索引。 使用代表性数据集,为要测试的块大小创建嵌入并将它们保存在索引中。 然后,可以运行一系列查询,可以评估其质量,并比较不同块大小的性能。 这很可能是一个迭代过程,你可以针对不同的查询测试不同的块大小,直到可以确定内容和预期查询的最佳性能块大小。
3.2分块方法选择
比较适合的方法如下:
方法1:固定大小块分割 - 简单的静态字符数据块
方法2:递归字符文本分割 - 基于分隔符列表的递归分块
方法3:特定文档分割 - 针对不同文档类型(PDF、Python、Markdown)的各种分块方法
方法4:语义分割 - 基于嵌入式遍历的分块
方法5:LLM 分割 - 使用类似代理系统的实验性文本分割方法。
方法相关试例:
方法1:固定大小块分割
字符分割是将文本分割的最基本形式。它是简单地将文本分割成N个字符大小的块,而不考虑其内容或形式。
优点:简单易行
缺点:非常刻板,不考虑文本的结构
方法2:递归字符文本分割
方法1的问题在于完全不考虑文档的结构。只是按照固定数量的字符进行分割。递归字符文本分割器可以解决这个问题。通过它,我们将指定一系列分隔符来分割文档。例如 LangChain的默认分隔符:“\n\n” - 换行、“\n” - 换行、" " - 空格、“” - 空字符等,这是快速搭建应用程序时的首选。如果您不知道从哪个分割器开始,这是一个不错的首选。
方法3:特定文档分割
除了普通文本文件之外的其他文档类型。比如图片、PDF、代码片段等等。前两个方法对于这些情况并不适用,所以需要找到不同的策略。Markdown、Python和JS的分割器基本上与递归字符分割器类似,只是使用不同的分隔符。例如 Markdown 分隔符:\n#{1,6} - 标题、```\n -代码块等。
方法4:语义分块
我们是否觉得为块大小设置一个全局常量很奇怪?我们的普通分块机制是否更奇怪,因为它们没有考虑实际内容?嵌入表示了字符串的语义含义。它们本身并没有太多作用,但是当与其他文本的嵌入进行比较时,您可以开始推断块之间的关系。利用这个特性,探索使用嵌入来找到语义上相似的文本聚类。假设是语义上相似的块应该放在一起。
方法5:LLM 分块
我们是否可以命令LLM执行此任务?人类是如何进行分块的呢?我们会如何将文档分块成具有语义相似性的离散部分?我会准备一张草稿纸或记事本。我会从文章的顶部开始,假设第一部分将是一个块(因为我们还没有任何块)。然后,我会继续阅读文章,评估新的句子或文章片段是否应该成为第一个块的一部分,如果不是,就创建一个新的块。然后一直这样做,直到读完整篇文章。
4、分块实现代码
4.1、langchain相关实现
链接:文本分割器# – LangChain中文网
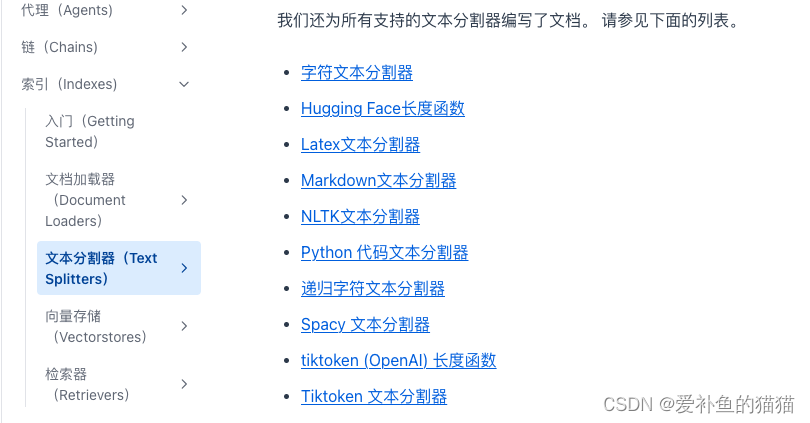
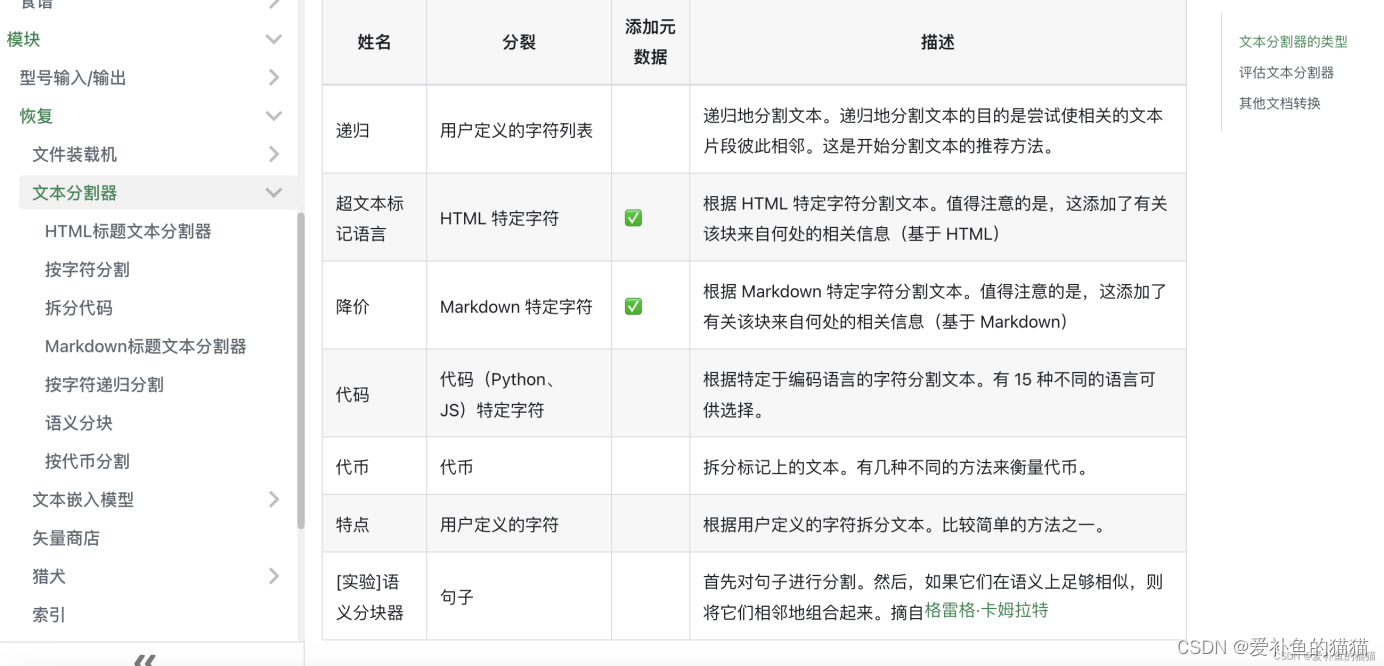
4.2上面五种方法的实现
链接1:https://github.com/FullStackRetrieval-com/RetrievalTutorials/blob/main/5_Levels_Of_Text_Splitting.ipynb
链接2:https://python.langchain.com/docs/modules/data_connection/document_transformers/semantic-chunker
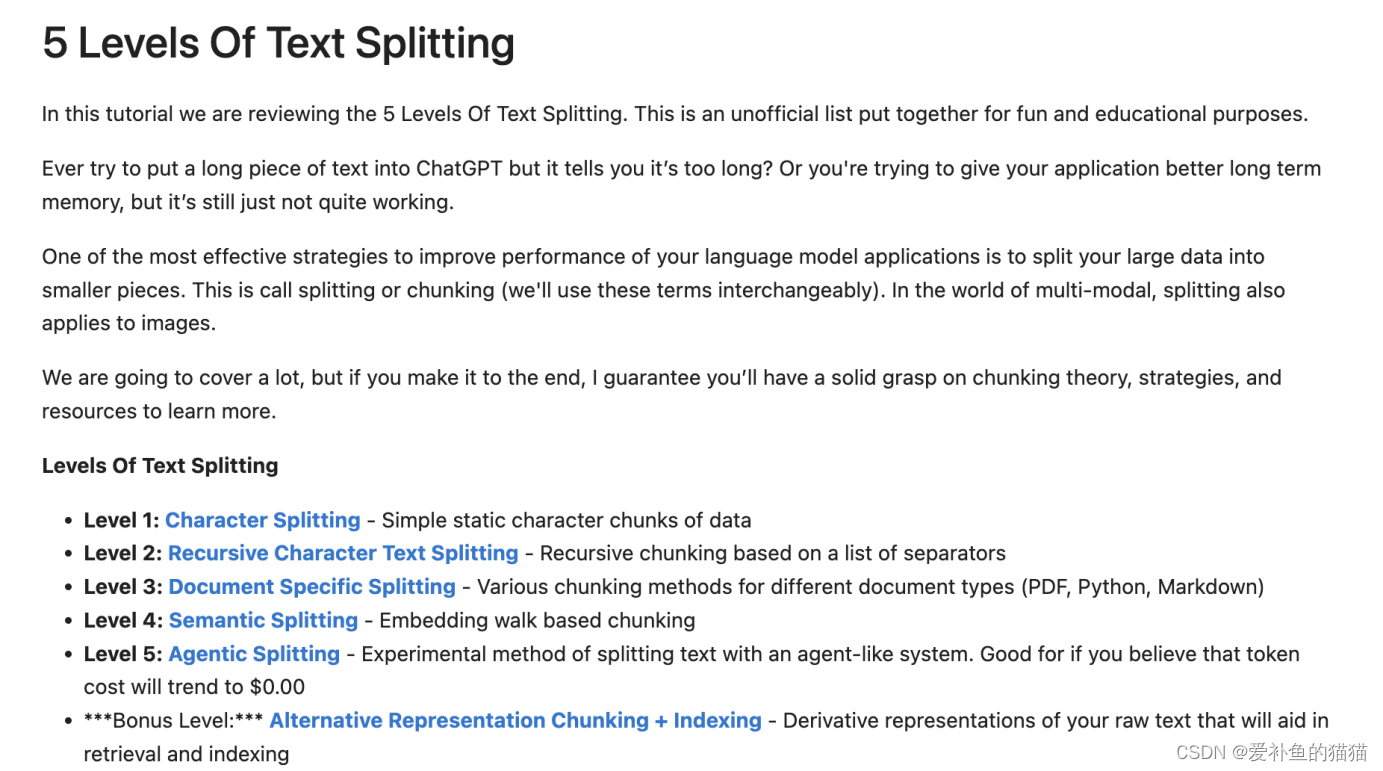
5、评估
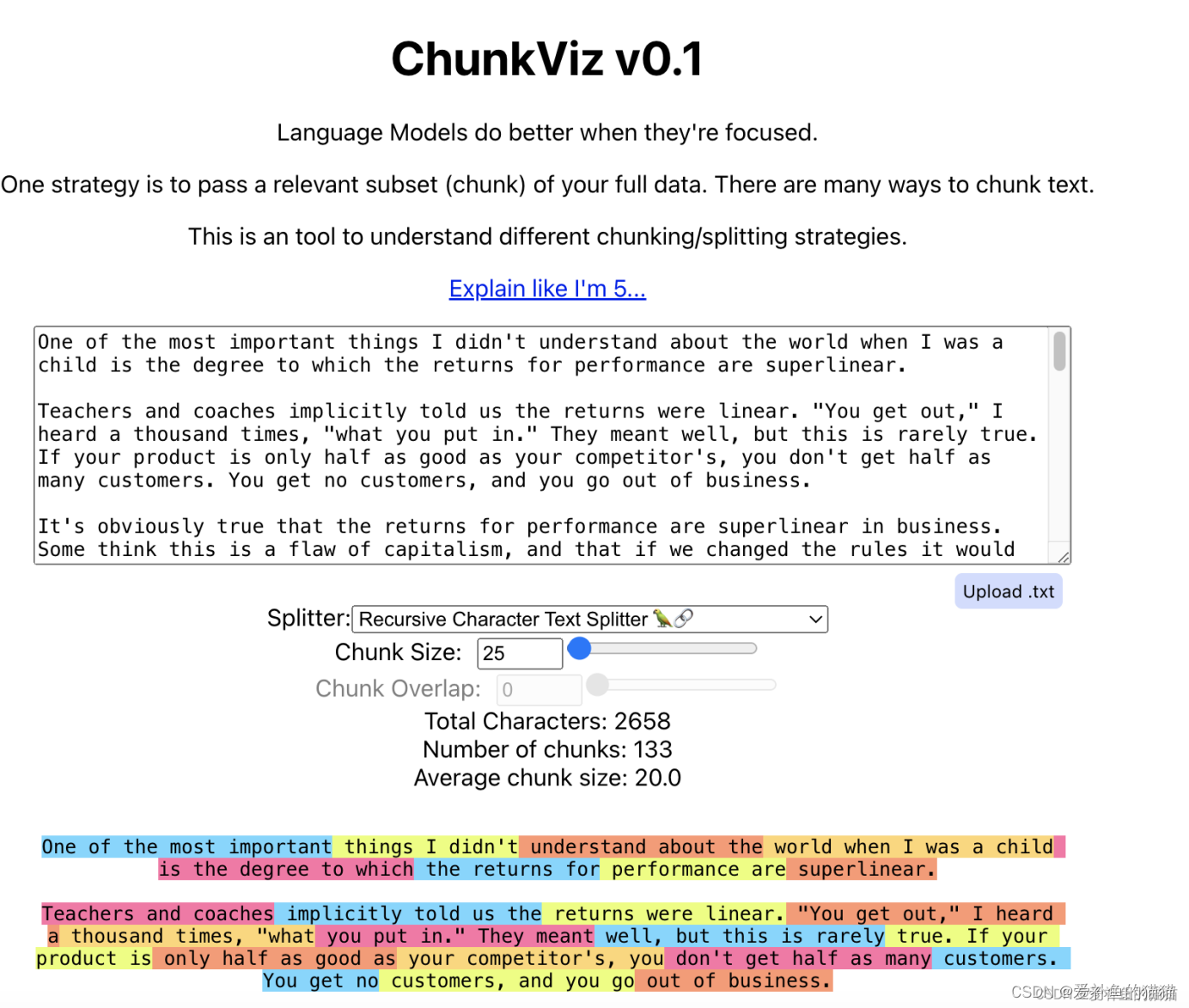
langchain评估链接:https://chunkviz.up.railway.app/
可以使用创建的Chunkviz 实用程序Greg Kamradt来评估文本拆分器。Chunkviz是一个很好的工具,可以直观地显示文本拆分器的工作情况。它将向您显示文本是如何分割的,并帮助调整分割参数。
ragas评估链接:github.com/explodinggradients/ragas
Ragas是一个帮助您评估检索增强生成(RAG)pipelines。Ragas提供基于最新研究的工具,用于评估LLM生成的文本,以帮助您了解RAG pipelines的情况。








![[C语言]——柔性数组](https://img-blog.csdnimg.cn/direct/521b330c86b04340acc704ef78aab17a.png)