一、状态转换
map()
只适用于一对一的转换,即对每个进入算子的流元素,map() 将仅输出一个转换后的元素。
flatmap()
可以输出任意数量的元素,也可以一个都不发。
二、Keyed Streams
keyBy()
相当于 sql 中的 group by,通过 shuffle 来为数据流进行重新分区。
.keyBy(object -> object.key)能做作为 keyBy 的条件:
- 结果是确定的;
- 实现了 hashCode 和 equals 方法
因此,元组和 POJO 来组成键,只要他们的元素遵循上述条件。
三、有状态的转换
1)Flink 管理状态的优势
- 本地性: Flink 状态是存储在使用它的机器本地的,并且可以以内存访问速度来获取
- 持久性: Flink 状态是容错的,例如,它可以自动按一定的时间间隔产生 checkpoint,并且在任务失败后进行恢复
- 纵向可扩展性: Flink 状态可以存储在集成的 RocksDB 实例中,这种方式下可以通过增加本地磁盘来扩展空间
- 横向可扩展性: Flink 状态可以随着集群的扩缩容重新分布
2)valueState
对于每个键 ,Flink 将存储一个单一的对象
open() 方法通过定义 ValueStateDescriptor<?> 建立了管理状态的使用。构造器的参数定义了这个状态的名字(“name”),并且为如何序列化这些对象提供了信息.
3)清理状态
在无限增长的键中,必须要清除不再使用的状态。
使用 key.clear()清理状态。
4)connected Streams
额外增加一组控制流,来控制某些转换,例如数据流的阈值、规则或者其他参数等。
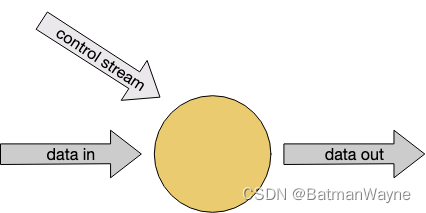
要求:两个流的键一致,即以相同的方式进行分区。