人工智能继续改变企业,但这导致企业在数字化转型和组织变革方面面临新的挑战。根据 2023 年福布斯报告,这些挑战可以总结如下:
- 分析技术堆栈围绕分析/批处理工作负载构建的公司需要开始适应实时数据处理(福布斯)。这种变化不仅影响了数据的收集方式,还导致了对新的数据处理和数据分析架构模型的需求。
- AI 法规需要被视为 AI/ML 架构模型的一部分。据《福布斯》报道,“Gartner 预测,到 2025 年,法规将迫使公司专注于人工智能道德、透明度和隐私。因此,这些平台将需要遵守即将出台的标准。
- 必须建立专门的 AI 团队,他们不仅应该能够构建和维护 AI 平台,还应该能够与其他团队合作,通过这些平台支持模型的生命周期。
这些新挑战的答案似乎是 MLOps 或机器学习操作。MLOps 建立在 DevOps 和 DataOps 之上,旨在促进机器学习 (ML) 应用程序,并更好地管理 ML 系统的复杂性。本文旨在系统地概述 MLOps 架构挑战,并演示管理这种复杂性的方法。
MLOps 应用程序:设置用例
在本文中,我们的示例用例是一家多年来一直在进行宏观经济预测和投资风险管理的金融机构。目前,预测过程基于外部宏观经济数据的部分手动加载和后处理,然后根据个人喜好使用各种工具和脚本进行统计建模。
然而,根据该机构管理层的说法,由于最近宣布的银行法规和安全要求,这一过程是不可接受的。此外,与市场上的竞争对手相比,计算结果的交付速度太慢,在财务上是不可接受的。对新的数字解决方案的投资需要充分了解复杂性和预期成本。它应该从收集需求开始,然后构建最小可行产品。
需求收集
对于解决方案架构师来说,设计过程从新体系结构需要解决的问题规范开始,例如:
- 手动数据收集速度慢,容易出错,并且需要大量工作
- 实时数据处理不是当前数据加载方法的一部分
- 没有数据版本控制,因此不支持随时间推移的可重复性
- 模型的代码在本地计算机上手动触发,并不断更新,无需版本控制
- 完全缺少通过通用平台共享数据和代码
- 预测过程不表示为业务流程,所有步骤都是分散的和不同步的,并且大多数步骤都需要手动操作
- 数据和模型的实验不可重现且不可审计
- 在内存消耗增加或占用大量 CPU 的操作的情况下,不支持可伸缩性
- 目前不支持对整个过程进行监控和审计
下图演示了新架构的四个主要组件:监视和审计平台、模型部署平台、模型开发平台和数据管理平台。
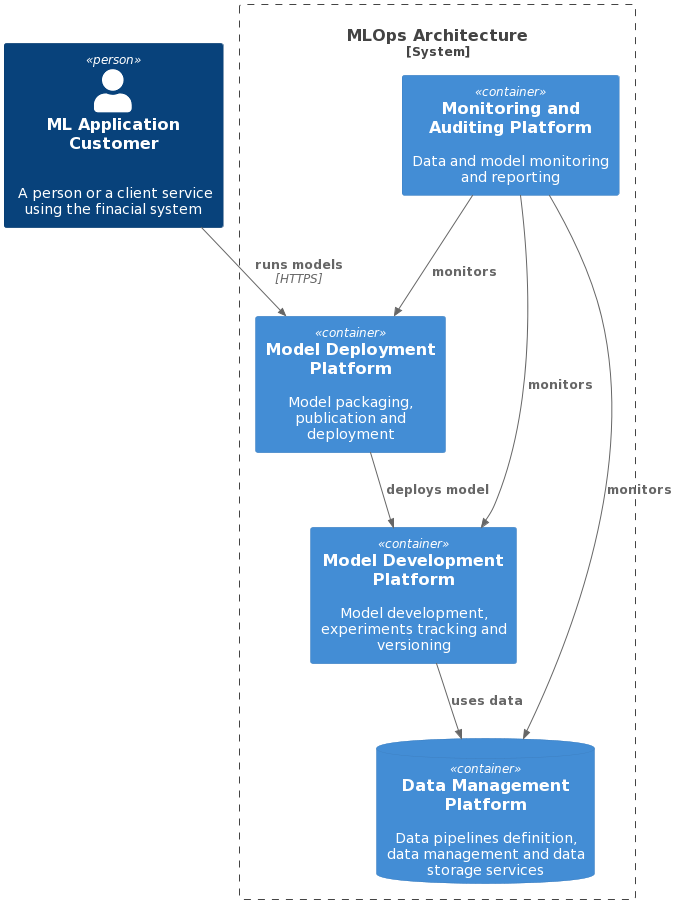
图 1.MLOps 体系结构图
平台设计决策
设计 MLOps 平台时要考虑的两个主要策略是:
- 从头开始开发与选择平台
- 在基于云的、本地或混合模型之间进行选择
从头开始开发与选择完全打包的 MLOps 平台
从头开始构建 MLOps 平台是最灵活的解决方案。它将提供解决公司未来任何需求的可能性,而无需依赖其他公司和服务提供商。如果公司已经拥有所需的专家和训练有素的团队来设计和构建 ML 平台,那将是一个不错的选择。
预打包解决方案是模拟不需要大量自定义的标准 ML 流程的不错选择。一种选择甚至是购买一个预训练的模型(例如,模型即服务),如果市场上有售,并只围绕它构建数据加载、监控和跟踪模块。这种解决方案的缺点是,如果需要添加新功能,可能很难按时完成这些添加。
将平台作为黑匣子购买通常需要围绕它构建额外的组件。选择平台时要考虑的一个重要标准是扩展或自定义它的可能性。
基于云的本地或混合部署模型
基于云的解决方案已经上市,AWS、Google 和 Azure 提供了流行的选项。在没有严格的数据隐私要求和法规的情况下,基于云的解决方案是一个不错的选择,因为模型训练和模型服务的基础设施资源是无限的。对于非常严格的安全要求,或者如果基础结构在公司内部已经可用,则本地解决方案是可以接受的。对于已经构建了部分系统但希望通过其他服务对其进行扩展的公司来说,混合解决方案是一种选择,例如,购买预训练模型并与本地存储的数据集成或合并到现有的业务流程模型中。
MLOps 架构实践
从我们的用例来看,金融机构没有足够的专家从头开始构建专业的 MLOps 平台,但由于法规和额外的财务限制,它也不想投资端到端托管的 MLOps 平台。该机构的架构委员会已决定采用开源方法,仅在需要时购买工具。架构概念是围绕开发简约组件和可组合系统的想法构建的。总体思路是围绕微服务构建的,这些微服务涵盖了可伸缩性和可用性等非功能性需求。为了最大限度地简化系统,对系统组件做出了以下决定。
数据管理平台
数据收集过程将完全自动化。由于外部数据提供程序的异构性,每个数据源都将有一个单独的数据加载组件。在写入实时数据和读取大量数据时,数据库选择至关重要。由于宏观经济数据的基于时间的性质以及该机构已有的关系数据库专家,他们选择使用开源数据库TimescaleDB。
使用标准关系数据库 GUI 客户端提供基于 SQL 的标准 API、执行数据分析和执行数据转换的可能性将减少交付平台第一个原型的时间。可以跟踪数据版本和转换并将其保存到单独的数据版本或表中。
模型开发平台
模型开发过程包括四个步骤:
- 数据读取和转换
- 模型训练
- 模型序列化
- 模型包装
训练模型后,参数化和训练的实例通常存储为打包工件。代码存储和版本控制最常见的解决方案是 Git。此外,该金融机构已经配备了像 GitHub 这样的解决方案,提供定义用于构建、打包和发布代码的管道的功能。基于 Git 的系统的体系结构通常依赖于一组执行管道的分布式工作器计算机。该选项将用作简约的 MLOps 架构原型的一部分,以训练模型。
训练模型后,下一步是将其作为已发布和版本控制的项目存储在模型存储库中。在该阶段,将模型作为二进制文件、共享文件系统甚至工件存储库存储在数据库中都是可以接受的选项。稍后,可以将模型注册表或 Blob 存储服务合并到管道中。模型的 API 微服务将公开模型的宏观经济预测功能。
模型部署平台
使 MLOps 原型尽可能简单的决定也适用于部署阶段。部署模型基于微服务体系结构。每个模型都可以使用 Docker 容器作为无状态服务进行部署,并按需扩展。该原则也适用于数据加载组件。一旦完成了第一个部署步骤,并明确了所有微服务的依赖关系,就可能需要一个工作流引擎来编排已建立的业务流程。
模型监控和审计平台
传统的微服务架构已经配备了用于收集、存储和监控日志数据的工具。Prometheus、Kibana 和 ElasticSearch 等工具足够灵活,可以生成特定的审计和性能报告。
开源 MLOps 平台
简约的 MLOps 架构是公司初始数字化转型的良好开端。但是,并行跟踪可用的 MLOps 工具对于下一个设计阶段至关重要。下表提供了一些最流行的开源工具的摘要。
表 1.用于初始数字化转型的开源 MLOps 工具
| 工具 | 描述 | 职能领域 |
| Kubeflow | 使 Kubernetes 上的 ML 工作流部署变得简单、可移植且可扩展 | 跟踪和版本控制、管道编排和模型部署 |
| MLflow(机器学习流) | 一个用于管理端到端 ML 生命周期的开源平台 | 跟踪和版本控制 |
| BentoML系列 | 用于 AI 应用和推理管道的开放标准和 SDK;提供自动生成 API 服务器、REST API、gRPC 和长时间运行的推理作业等功能;并提供自动生成 Docker 容器映像的功能 | 跟踪和版本控制、管道编排、模型开发和模型部署 |
| TensorFlow 扩展 (TFX) | 一个生产就绪的平台;专为部署和管理 ML 管道而设计;包括用于数据验证、转换、模型分析和服务的组件 | 模型开发、管道编排和模型部署 |
| Apache Airflow, Apache Beam | 一个灵活的框架,用于定义和调度复杂的工作流,尤其是数据工作流,包括 ML | 管道编排 |
总结
MLOps 通常被称为机器学习的 DevOps,它本质上是 ML 应用程序的一组架构模式。然而,尽管与许多知名体系结构有相似之处,但 MLOps 方法给 MLOps 架构师带来了一些新的挑战。一方面,重点必须放在 MLOps 服务的兼容性和组成上。另一方面,人工智能法规将迫使现有系统和服务不断适应新的监管规则和标准。我怀疑,随着 MLOps 领域的不断发展,一种提供 AI 道德和监管分析的新型服务将很快成为 ML 领域企业关注的焦点。