说明:仅供学习使用,请勿用于非法用途,若有侵权,请联系博主删除
作者:zhu6201976
一、需求背景
App在Facebook、Google等巨头进行广告投放,想要拿到实时广告投放效果数据,如曝光、点击、花费、触达等核心指标并进行分析,可对接官方API实现。因对接过程十分复杂,此处以Facebook为例,进行简单记录。
二、对接流程
1.文档地址
https://developers.facebook.com/docs/marketing-api/insights
2. access_token获取
a. 创建App https://developers.facebook.com/apps
b. 添加产品
-
点击进入某个App --> Add products to your app --> Marketing API --> Set up

-
点击左下角Marketing API --> Tools --> 勾选token权限 --> Get Token 即可生成一个长效token,有效期2个月,过期后需要重新生成 步骤相同
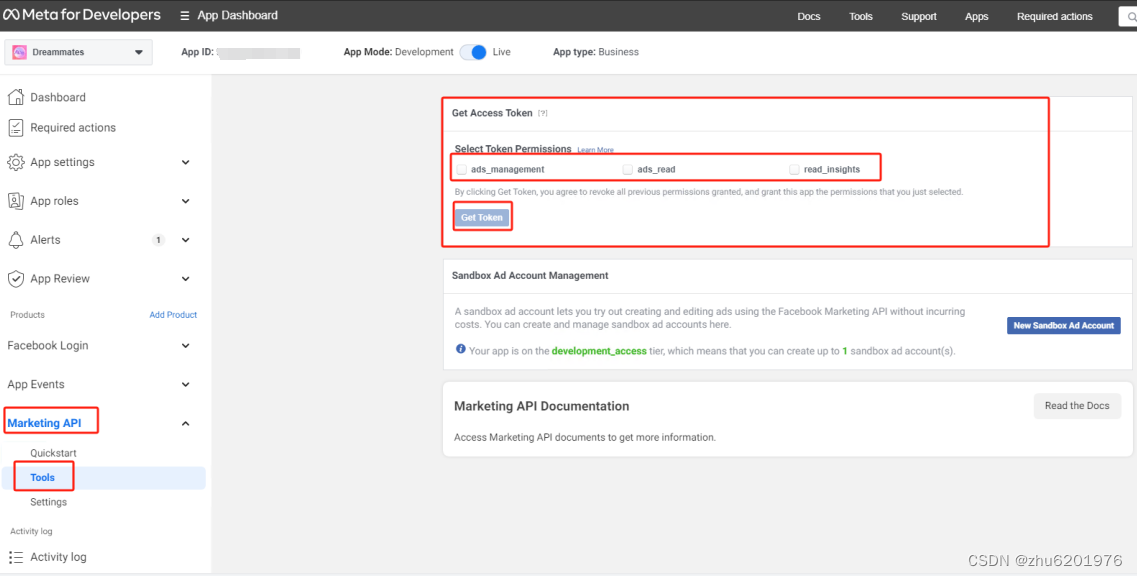
c. 查看access_token有效期(可选)
复制保存步骤2生成的token,查看有效期。
地址:https://developers.facebook.com/tools/debug/accesstoken
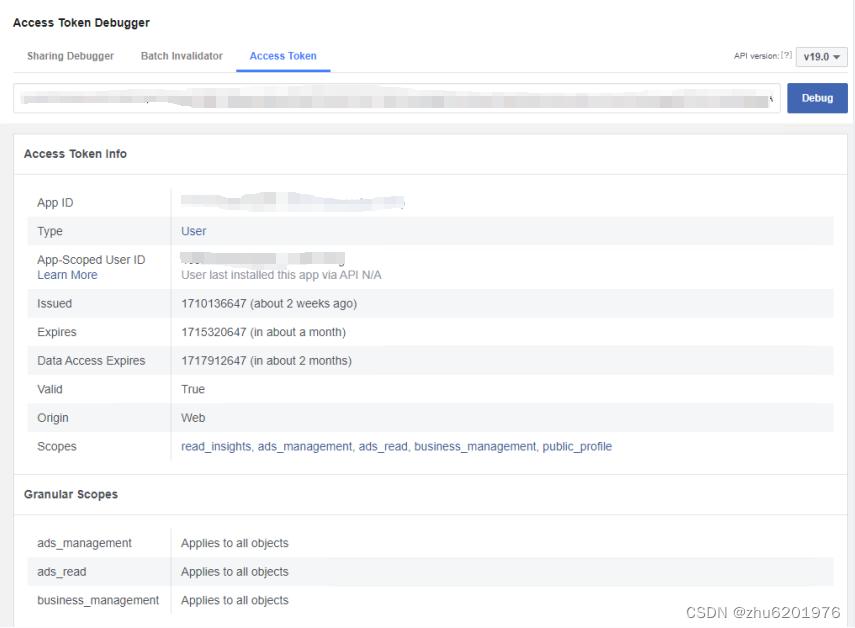
如图所示,通过此种方式,可以获取到一个有效期2个月的长效access_token。
三、示例代码
获取到长效access_token后,我们可以开始请求广告数据了。
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.api_url = 'https://graph.facebook.com'
self.api_version = 'v19.0'1. 获取所有广告账号adaccount
def start_requests(self):
page = 1
url = f'{self.api_url}/{self.api_version}/me/adaccounts?'
params = {
'fields': 'id,name',
'access_token': self.access_token
}
url = f'{url}{urlencode(params)}'
yield scrapy.Request(url, meta={'page': page}, priority=1, callback=self.parse_adaccounts)通过该API,可以获取到所有广告账号,分页返回,每页25条。fields字段控制返回的字段,此处为account_id、account_name。
后续翻页控制代码:
resp_str = resp.body.decode('utf-8', 'ignore')
resp_dict = json.loads(resp_str)
next_url = resp_dict.get('paging', {}).get('next')
if next_url:
page += 1
yield scrapy.Request(next_url, meta={'page': page}, priority=1, callback=self.parse_adaccounts)2. 获取广告账号广告量
为什么要获取广告账号广告量?因为如果某个广告账号下根本没有投放广告,则无需后续请求,提高效率,减少请求次数。
def get_adaccount_ads_volume_req(self, ad_account_id, ad_account_name):
"""
构造账号广告量查询请求
https://developers.facebook.com/docs/marketing-api/insights-api/ads-volume
:param ad_account_id:
:return:
"""
url = f'{self.api_url}/{self.api_version}/{ad_account_id}/ads_volume?'
params = {
'access_token': self.access_token
}
url = f'{url}{urlencode(params)}'
return scrapy.Request(url,
meta={'ad_account_id': ad_account_id,
'ad_account_name': ad_account_name},
priority=2,
callback=self.parse_adaccount_ads_volume)解析账号广告量响应代码:
resp_str = resp.body.decode('utf-8', 'ignore')
resp_dict = json.loads(resp_str)
# self.logger.info(f'{method_name} {ad_account_id} {resp_dict}')
ads_volume = resp_dict.get('data', [])
self.logger.info(f'{method_name} {ad_account_id} 提取到 {len(ads_volume)} ads_volume')
for volume in ads_volume:
ads_running_or_in_review_count = volume.get('ads_running_or_in_review_count', 0)
if ads_running_or_in_review_count > 0:
yield self.get_campaigns_req(ad_account_id, ad_account_name, page=1)3. 获取广告账号所有campaign
def get_campaigns_req(self, ad_account_id, ad_account_name, page):
"""
构造启动campaigns请求
:param ad_account_id:
:param ad_account_name:
:param page:
:return:
"""
url = f'{self.api_url}/{self.api_version}/{ad_account_id}/campaigns?'
params = {
'effective_status': "['ACTIVE', 'PAUSED']",
'fields': 'id,name',
'access_token': self.access_token,
}
url = f'{url}{urlencode(params)}'
return scrapy.Request(url,
meta={'ad_account_id': ad_account_id,
'ad_account_name': ad_account_name,
'page': page},
priority=2,
callback=self.parse_get_campaigns)4. 对campaign聚合获取所有广告
该步骤非常重要,我们无需通过完整路径:adaccount --> campaign --> adset --> ads 获取到广告数据,可以利用API的level进行聚合,直接在campaign层级获取到所有广告投放数据。如下所示:
def ad_insights_req(self, ad_account_id, ad_account_name, ad_campaign_id, ad_campaign_name, d_str, page):
url = f'{self.api_url}/{self.api_version}/{ad_campaign_id}/insights?'
params = {
'level': 'ad',
'fields': 'adset_id,adset_name,ad_id,ad_name,impressions,clicks,unique_clicks,spend,reach,cpc,cpm,cpp,ctr,' +
'date_start,date_stop,actions,action_values',
# 'date_preset': 'today', # today,yesterday,last_7d,last_30d,...
'time_range': '{"since":' + f'"{d_str}"' + "," + '"until":' + f'"{d_str}"' + "}",
'access_token': self.access_token,
}
url = f'{url}{urlencode(params)}'
return scrapy.Request(url,
meta={'ad_account_id': ad_account_id,
'ad_account_name': ad_account_name,
'ad_campaign_id': ad_campaign_id,
'ad_campaign_name': ad_campaign_name,
'd_str': d_str,
'page': page},
priority=3,
callback=self.parse_ad_insights)5. 解析广告数据
for ad in ads:
ad_insights_item = FbAdInsightsItem()
ad_insights_item['ad_account_id'] = ad_account_id
ad_insights_item['ad_account_name'] = ad_account_name
ad_insights_item['ad_campaign_id'] = ad_campaign_id
ad_insights_item['ad_campaign_name'] = ad_campaign_name
ad_insights_item['ad_set_id'] = ad.get('adset_id', '')
ad_insights_item['ad_set_name'] = ad.get('adset_name', '')
ad_insights_item['ad_id'] = ad.get('ad_id', '')
ad_insights_item['ad_name'] = ad.get('ad_name', '')
ad_insights_item['impressions'] = ad.get('impressions', '')
ad_insights_item['clicks'] = ad.get('clicks', '')
ad_insights_item['unique_clicks'] = ad.get('unique_clicks', '')
ad_insights_item['spend'] = ad.get('spend', '')
ad_insights_item['reach'] = ad.get('reach', '')
ad_insights_item['cpc'] = ad.get('cpc', '')
ad_insights_item['cpm'] = ad.get('cpm', '')
ad_insights_item['cpp'] = ad.get('cpp', '')
ad_insights_item['ctr'] = ad.get('ctr', '')
ad_insights_item['date_start'] = ad.get('date_start', '')
ad_insights_item['date_stop'] = ad.get('date_stop', '')一键三连,有需要的请私聊获取详细源码。