流式密集视频字幕
- 摘要
- 1 Introduction
- Related Work
- 3 Streaming Dense Video Captioning
Streaming Dense Video Captioning
摘要
对于一个密集视频字幕生成模型,预测在视频中时间上定位的字幕,理想情况下应该能够处理长的输入视频,预测丰富、详细的文本描述,并且在处理完整个视频之前能够生成输出。
然而,目前最先进的模型仅处理固定数量的降采样帧,并且在看完整个视频后做出一次完整的预测。
我们提出了一种流式密集视频字幕生成模型,该模型包含两个创新组件:首先,我们提出了一种新的记忆模块,基于对传入令牌的聚类,该模块能够处理任意长度的视频,因为记忆的大小是固定的。
其次,我们开发了一种流式解码算法,使我们的模型能够在处理完整个视频之前做出预测。 我们的模型实现了这种流式处理能力,并在三个密集视频字幕生成基准测试中显著提高了最先进水平:ActivityNet、YouCook2和ViTT。我们的代码发布在https://github.com/google-research/scenic。
1 Introduction
在现代社会的方方面面,视频迅速成为传输信息最普遍的媒体格式之一。大多数为视频理解设计的计算机视觉模型仅处理少量帧,通常只覆盖几秒钟的时间范围[31, 33, 39, 49, 58],且通常限于将这些短片段分类到固定数量的概念中。
为了实现全面、细粒度的视频理解,我们研究了一种密集视频字幕生成任务——在视频中对事件进行时间上的定位并为之生成字幕。这一目标理想的模型应当能够处理长的输入序列——以推理长时间、未修剪的视频——并且能够处理文本空间中的长输出序列,详细描述视频中的所有事件。
先前的密集视频字幕生成工作并未处理长输入或长输出。对于任何长度的视频,现有最先进模型要么以大步长(例如,6帧[48])采样极少数帧[11, 30, 48](即时间下采样),要么对所有帧保持每帧一个特征[51, 59, 65](即空间下采样)。在长文本输出方面,当前模型完全依赖自回归解码[19]在最后生成多个句子。
在这项工作中,我们设计了一个如图1所示的密集视频字幕生成的“流式”模型。我们的流式模型由于拥有记忆机制,不需要同时访问所有输入帧就能处理视频。此外,我们的模型可以在不处理整个输入序列的情况下因果性地产生输出,这得益于一种新的流式解码算法。像我们的这类流式模型本质上适合处理长视频——因为它们一次只摄取一帧。而且,由于输出是流式的,因此在处理完整视频之前就会产生中间预测。这一特性意味着流式模型理论上可以应用于处理实时视频流,正如视频会议、安全和持续监控等应用所需。
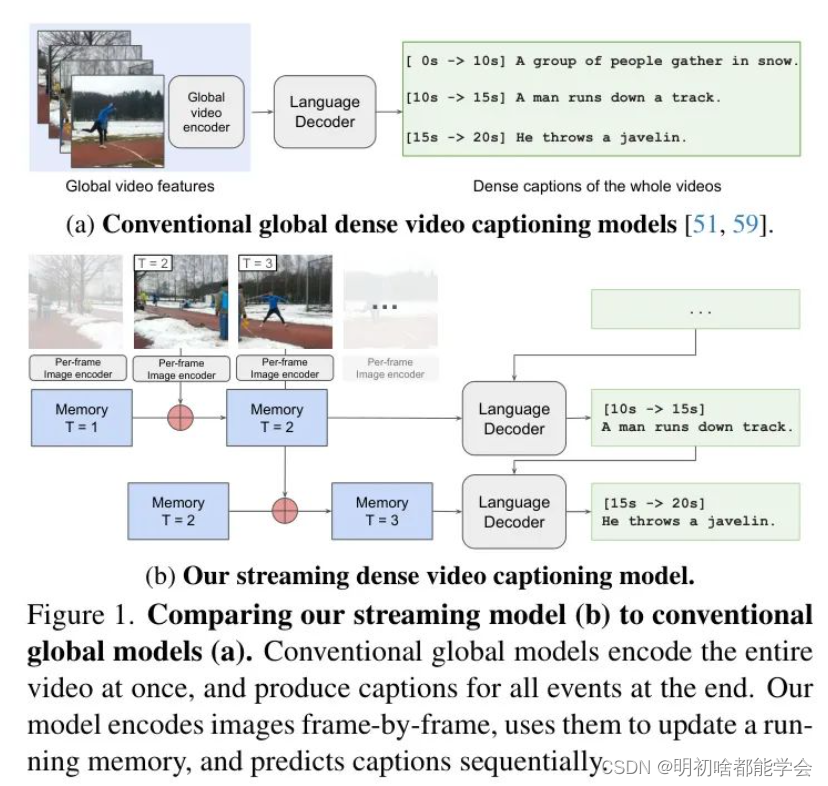
图1:将我们的流式模型(b)与传统的全局模型(a)进行比较。传统的全局模型一次编码整个视频,并在最后为所有事件产生字幕。我们的模型逐帧编码图像,使用它们更新运行中的记忆,并顺序预测字幕。
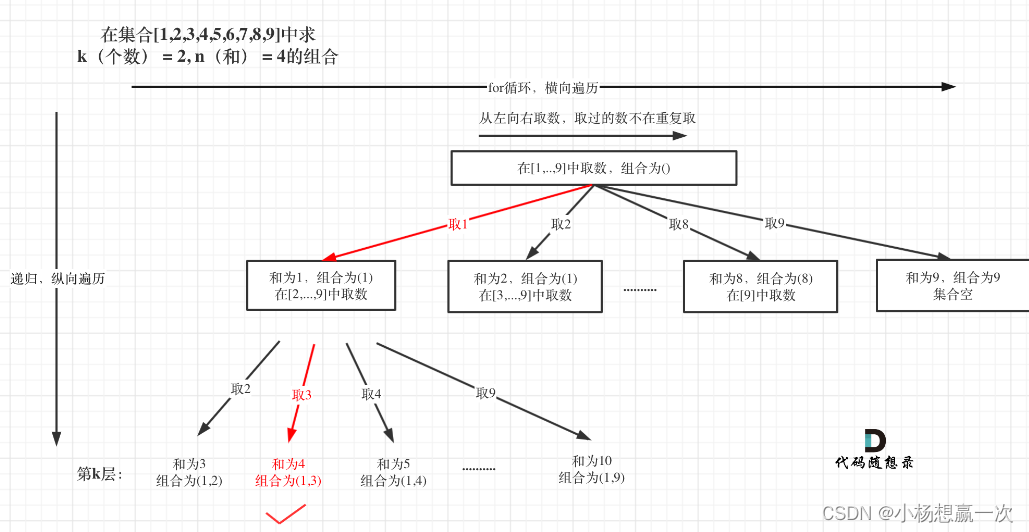
我们首先提出了一个新颖的记忆机制,一次接收一帧。记忆模型基于K-means聚类,并使用固定数量的簇中心标记在每个时间戳上表示视频。我们展示了这种方法简单而有效,可以处理可变数量的帧,并且在解码时具有固定的计算预算。
为了开发我们的流式模型,我们还提出了一种流式解码算法,并训练我们的网络,使其在特定时间戳的“解码点”(图2)上,根据该时间戳的记忆特征预测在此之前结束的所有事件字幕。因此,我们的网络被训练成在任何视频时间戳上做出预测,而不仅仅是视频结束处,如传统非流式模型那样。此外,我们将早期解码点的预测作为后来解码点的上下文。这一上下文避免了预测重复的事件,并可以作为自然语言总结早期视频的“显式”记忆。我们的流式输出还源于这样一个事实:随着视频长度的增长,我们的记忆将不可避免地在时间上失去信息,因为其大小是有限的。我们通过在处理整个视频之前进行预测来避免这个问题,并通过语言上下文保持早期信息。

图2:我们的框架说明。 每个帧一次通过图像编码器。基于聚类的记忆模型从开始到当前帧维持压缩的视觉特征。
在特定的帧上,即“解码点”,我们从记忆中解码出字幕和时间戳。如果有的话,早期的文本预测也会作为后续解码
点的语言解码器的前缀传递。我们的模型可以运行在任意长度的视频上,因为记忆具有恒定的大小,还可以在处
理整个视频之前输出预测。
我们在三个流行的密集视频字幕生成数据集上评估了我们的方法:ActivityNet[29]、YouCook2[64]和ViTT[23]。我们的结果显示,与不可避免地使用更少的帧或特征的最先进技术相比,我们的流式模型显著提高了性能,最多提高了11.0 CIDEr点。我们证明了我们的方法在GIT[48]和Vid2Seq[59]架构上具有泛化能力。最后,我们提出的记忆机制也可以应用于段落字幕生成,将基线提高了1-5 CIDEr点。
Related Work
密集视频字幕生成。 密集视频字幕生成需要标注事件,并在时间上对其进行定位。传统上,先前的研究采用两阶段方法,首先在视频中定位事件,然后随后对其进行字幕生成[24, 25, 29, 47, 50]。更近期的端到端方法包括PDVC [66],它使用类似DETR [10]的模型来推断事件字幕和时间戳。Vid2Seq [59]用时间戳标记扩展了语言模型的词汇,使它们能够像常规字幕生成模型一样生成连接的事件字幕。我们也使用了[59]的输出表述,因为它与基础视觉-语言模型[48]整合得很好。一个相关但不同的问题是电影中的音频描述[20, 21, 43],这需要为视障人士生成必须补充对话的字幕,并且经常使用辅助的非因果模型来识别角色或他们的对话[21]。
据我们所知,所有先前的密集字幕生成模型都不是因果模型,因为它们一次编码整个视频。此外,为了处理长视频,它们通常使用经过大幅下采样的视觉特征(通过选择几帧[11, 30, 48],或者每帧进行空间池化特征[51, 59, 65])。相比之下,我们以流式方式处理视频,用一个记忆模块一次处理一个帧的长输入序列,并使用一种新颖的解码算法流输出句子。
长视频的模型。 处理较长视频的常见方式是使用记忆机制来提供过去事件的紧凑表示。使用变压器,记忆可以通过将过去观察的标记作为当前时间步的输入来实现[13, 36, 56]。在视觉中的例子包括[22, 35, 53, 54],它们离线预提取特征并在推理时检索它们,因此不是因果模型。MemViT [55]使用前一时间步的标记激活作为当前时间步的输入。然而,这意味着序列长度会随时间增长,因此它无法处理任意长的视频。将记忆视为将先前观察到的标记压缩成较小、固定大小的集合以在未来的时间步使用的另一种观点。Token Turing Machines [41]使用[40]的标记总结模块总结过去和当前的观察。MovieChat [44]遵循类似的想法,但使用Token Merging [5]的一个变体来进行总结。TeSTra [62]使用指数移动平均来整合视频特征。这种方法的优点是记忆库具有固定大小,因此无论视频的长度如何,计算成本都保持有限。我们的记忆模型具有这一同样理想的属性。然而,我们的记忆基于聚类,使用类似K-means算法的中心来总结每个时间步的标记,我们通过实验证明这优于其他选择。
视频中的因果模型。 我们的流式模型是因果模型,这意味着其输出仅依赖于当前和过去的帧,没有访问未来帧。尽管我们不知道先前的因果模型用于密集视频字幕生成,但在许多其他视觉领域中有因果模型。在线动作检测[14, 28, 62, 63]旨在在实时视频中预测动作标签,不访问未来帧。类似地,在线时间动作定位[7, 26, 42]模型在观察动作后也预测动作的开始和结束时间。大多数对象跟踪[3, 52]和视频对象/实例分割[9, 32, 34]的模型也是因果模型。
上述任务的一个共同主题是模型必须对视频的每个帧进行预测。相比之下,我们专注于密集视频字幕生成[29],这是具有挑战性的,因为输出字幕与视频帧不是一一对应的。我们通过提出一种流式解码算法来解决这一问题。
3 Streaming Dense Video Captioning
标题生成模型通常由一个视觉编码器和一个文本解码器组成。我们概述了这些方法,并展示了它们如何扩展到密集标题生成。
视觉编码器。 第一步是将视频编码为特征 ,其中 是特征分辨率(对于基于变换器的编码器,这是令牌的数量), 是特征维度。视觉特征编码器 可以是一个原生的视频骨干网络[1, 4],或者是一个应用于每一帧的图像编码器[37, 60]。在后一种情况下,视频特征是图像特征的堆叠,,其中 是每帧的令牌数。我们使用逐帧编码,但不是从整个视频中预先提取它们,而是使用一个记忆机制以因果、流式的方式处理特征(第3.2节),这种方式可以推广到更长的视频时长。
文本解码器。 给定视觉特征 和可选的文本前缀令牌 ,文本解码器 从它们生成一系列单词令牌 。我们使用自回归[19, 45]解码器,它根据之前的单词 和(如果有的话)前缀生成下一个单词令牌 ,即 。注意,在标题生成任务中通常不使用前缀令牌,但在问题回答(QA)任务中使用它们来编码输入问题。具体来说,文本解码器 是一系列在视觉特征 和前缀的词嵌入[38, 48]的连接上操作的变换层[45]。这种架构在图像和视频的标题生成和QA任务中都被证明是有效的[11, 30, 48]。
带时间戳的密集视频标题生成。 结合上述视觉编码器和文本解码器,为视频标题生成提供了一个基本架构。为了将其扩展为带有开始和结束时间戳的多个事件的标题生成,Vid2Seq[59]引入了两项主要修改:首先,它扩展了标题生成模型的词汇表 ,加入了时间令牌 和 ,分别代表开始和结束时间。因此,一个单独的事件表示为 ,且 ,其中 ∣ V ∣ ≤ w s < w e ≤ ∣ v ′ ∣ |V|\leq w^{s}<w^{e}\leq|v^{\prime}| ∣V∣≤ws<we≤∣v′∣, ∣ t ∣ |t| ∣t∣ 是时间令牌的数量。其次,vid2seq按开始时间顺序将所有定时标题连接成一个长的标题: c = " [ c 1 ′ , c 2 ′ , ⋯ , c " n e ′ ] \mathbf{c}="[\mathbf{c}^{\prime}_{1},\mathbf{c}^{\prime}_{2},\cdots,\mathbf{c}" ^{\prime}_{n_{e}}] c="[c1′,c2′,⋯,c"ne′],其中=“” n e n_{e} ne=“” 是事件的数量。因此,密集视频标题生成可以形式化为具有目标=“” c \mathbf{c} c=“” 的标准视频标题生成。<=“” p=“”>
尽管Vid2Seq[59](广义)架构很有效,但它有几个关键局限性:首先,它将整个视频的视觉特征 通过解码器,这意味着它不能有效地扩展到更长的视频和更多的令牌。此外,由于Vid2Seq在处理整个视频后一次预测所有事件标题,它在预测长而详细标题方面存在困难。为了解决这些问题,我们引入了流式密集视频标题生成模型,我们使用一个记忆模块一次处理一个输入,以限制计算成本,并流式输出,这样我们可以在处理整个视频之前做出预测。