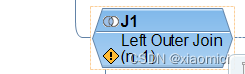
一旦我们用了join,那就会有个Analytic Engine分析引擎来确保不是唯一连接的时候,关键值不会被重复。
啥是模糊关联?
一般来讲关联基数是1:n, 或者n:1,或者 m:n都是。
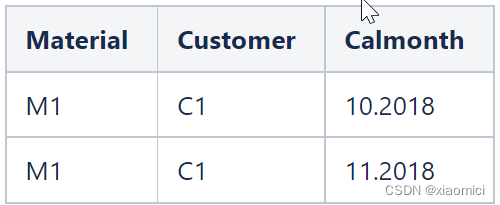
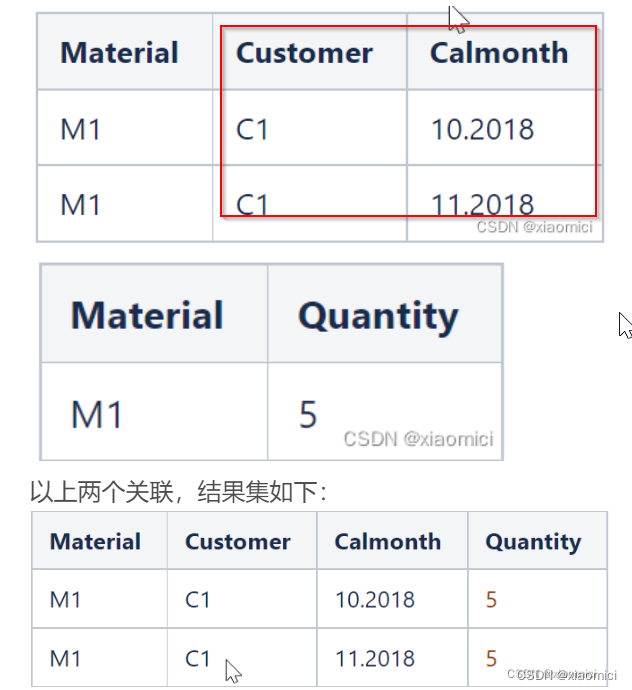
以上两个关联,结果集如下:
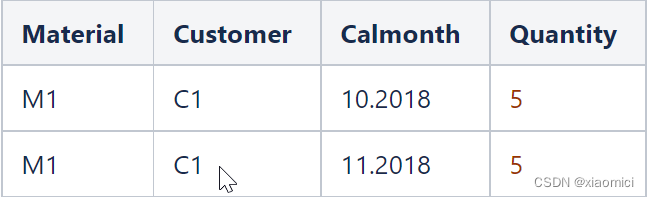
这时候,结果集连带着关键值了。
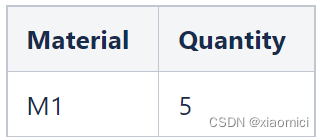
那query来了,说要看这个C1客户的quantity。
很显然,应该是5,不能给人家个10。也就是系统不能搞个sum。
这个就是分析引擎干的活了。
需要Analytic Engine.
用RSOHCPR检查有模糊join的CP,就会看到这个警告。

这是个警告。就是告诉你有这个模糊join。但是不是说基于这个CP的query就跑不起来了。
而是说,分析引擎待会来处理这个模糊关联的时候,它会引起性能问题,会导致超高的内存消耗。
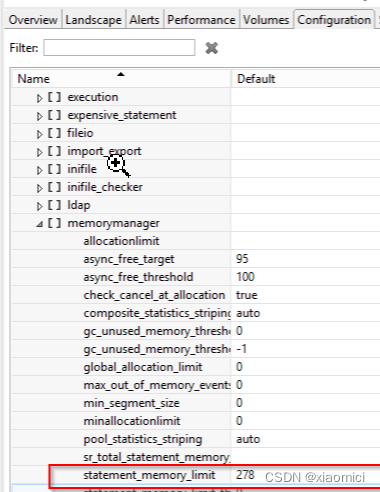

如果你的底层ADSO数据量特别大,比如我们这个,几十亿条的数据,那么会用掉几百个G的内存。因为与此同时有大量数据被传送到Analytic Engine。然后最后还有可能跑不出来,导致一个memory allocation error。
所以,为了防止query的性能和内存问题。就要避免这个模糊关联。
那万一实在避免不了呢?那就不要再在模糊关联之外再搞join了。
要是还是避免不了多重join,那就说,能不能用一样的join字段吧。
要是说又有模糊关联,又在这个上面还有好几个join,另外其他的join还都不是一样的join字段。那就有可能最后分析引擎跑出来的数据它不对。
所以就是说,定义join的时候要特别小心。
文章目录
- 1. 定义关联基数
- 2. CP上的query运行时间过长
- 3. 高内存消耗
1. 定义关联基数
一旦CP上出现了模糊关联,那为了防止关键值重复,分析引擎就需要拿到所有的join字段,而不是只拿query里需要的字段,这就导致内存消耗了。
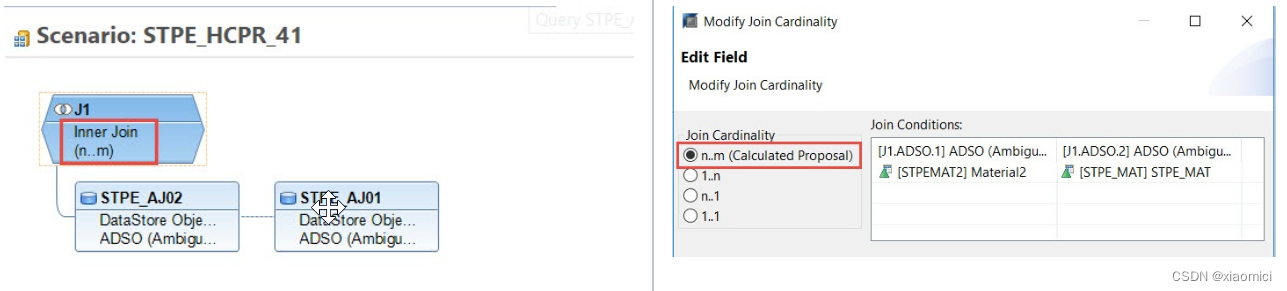
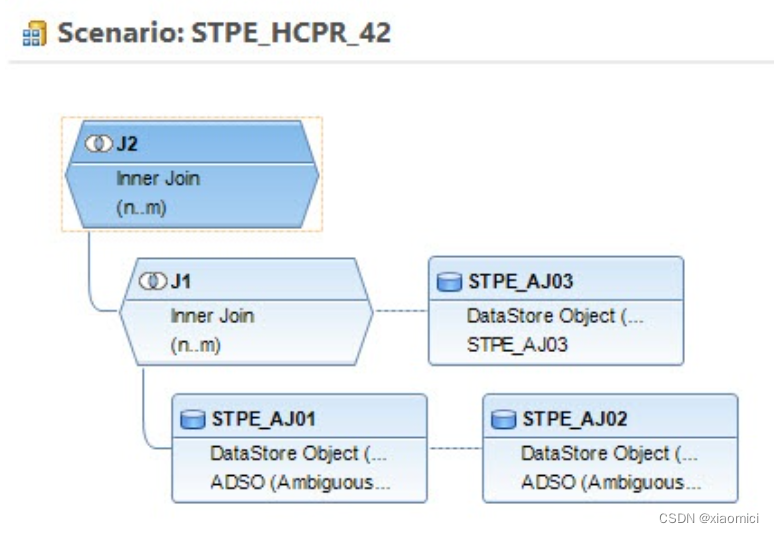
举个例子来说,下面的这个模型,关联基数都是n:m
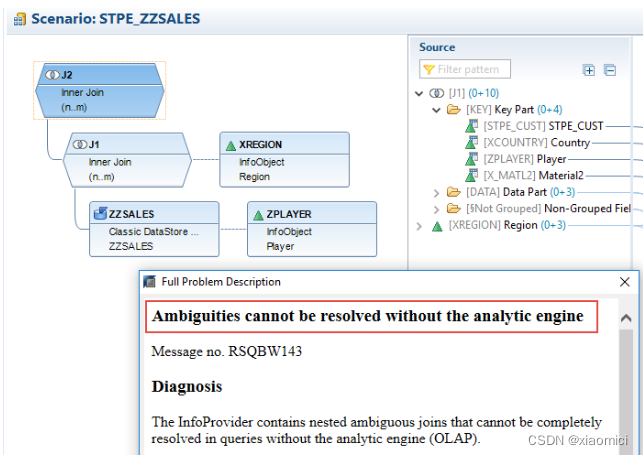
原因是这个ADSO对应关联的两个infoset,确实是多对多的关系。
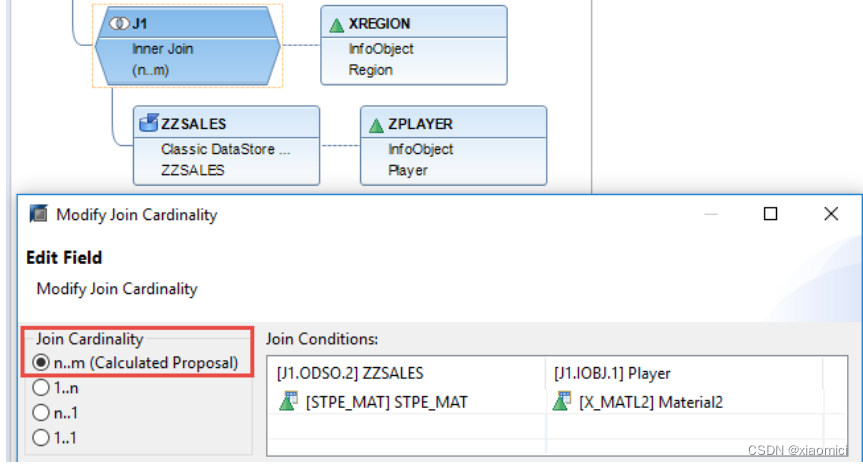
系统会自动给我们选择关联基数,这个不用改,自己强行改那可能会出错。
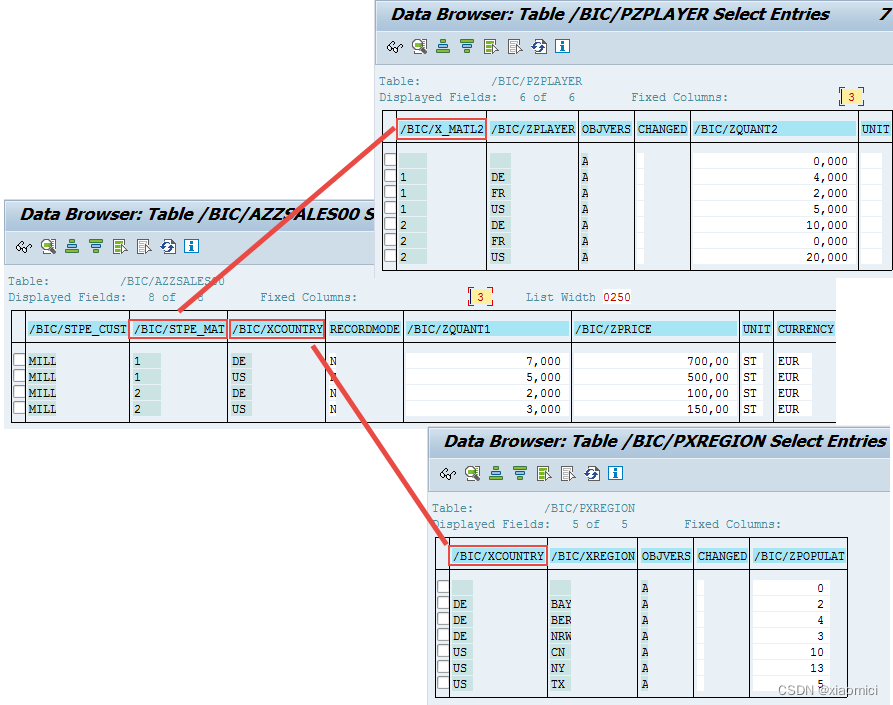
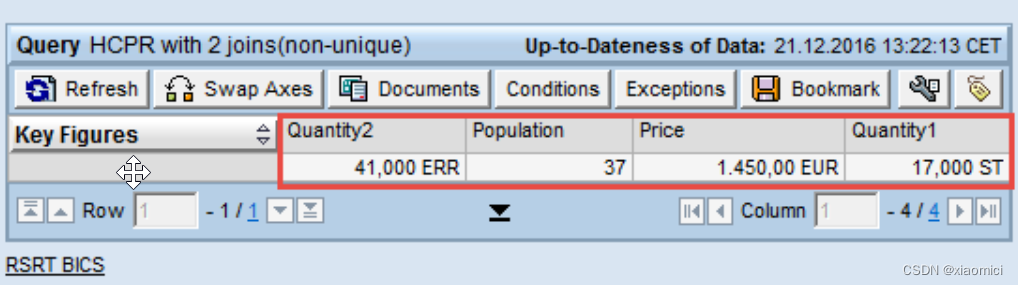
在这两个INFOSET里,ZQUANT2的sum值是41 , ZPOPULAT 值是37.
如果用listcube去直接查看这个CP的值,那么值显然是错的。
这个值是咋来的?怎么就变成了82和74就翻倍了呢?
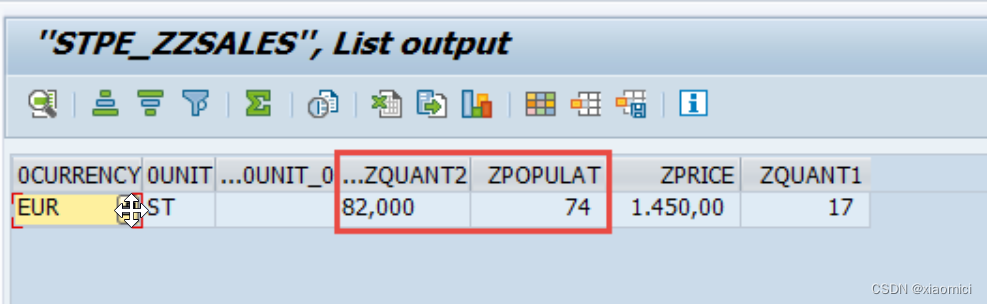
因为第一个inner join由于DE和US把QUANT2的值都翻了倍。
第二个inner join,也是因为ADSO的MAT主键把数据给翻倍了。两个在ADSO里的关联字段都出现了两次,导致关键值翻倍。
但是如果我们去建一个query去跑。
虽然最后并没有把country和MAT这两个字段加到自由特性里。但是query还是会去拿这两个字段。并且获取到正确的值。
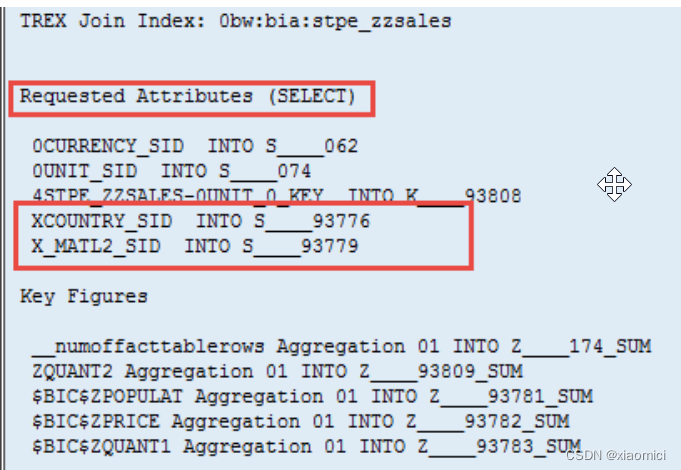
这个就是分析引擎在起作用。分析引擎在这里做了group by的操作了。
2. CP上的query运行时间过长
当然以上如果是数据量少,那没问题,但是如果数据量巨大。就可能出现query运行时间超长。
当然咱知道一个CP上的query运行时间长一般有几种可能,一个是它里面的join太多了。
二个是运行时要关联导航属性。所以说导航属性也不能搞太多的。影响性能。
当有很多个join的时候,就要对数据要有明确的了解了,关联的键值关系是啥样的,最后跑query的时候,拿关键值的时候,join是不是会按照你建模顺序来执行的。先取哪个join,后取哪个join,会不会来回取值。都是个问题。
一旦join多了,而且还有模糊关联了,那analytic engine也会晕,搞不了group by 就会把数据搞错。
所以说,一般CP里面不要搞太多join。
在CP里面有个本地分组。local grouping的特性,如果是只有一个模糊关联的join,那就能在另一个表里先进行grouping,这样就让analytic engine只拿group过的记录。会少很多。比如像文章开头的表,第一个表如果被分组了,analytic engine就会只拿一条数据,如果没有被分组,那就会拿两条数据,也就是内存就得耗费的多点。
没有被用作关联字段的其他特性,比如像customer 和 calmonth,都会被拿到分析引擎去。
而本地分组的功能。
比如对于下面这个例子,一个CP里面有两个inner join的ADSO,用物料编号做关联。最后只展示关键值STPEQUANT2。但是由于物料编号不是唯一主键,所以实际上这个内连接关联基数是个m:n.
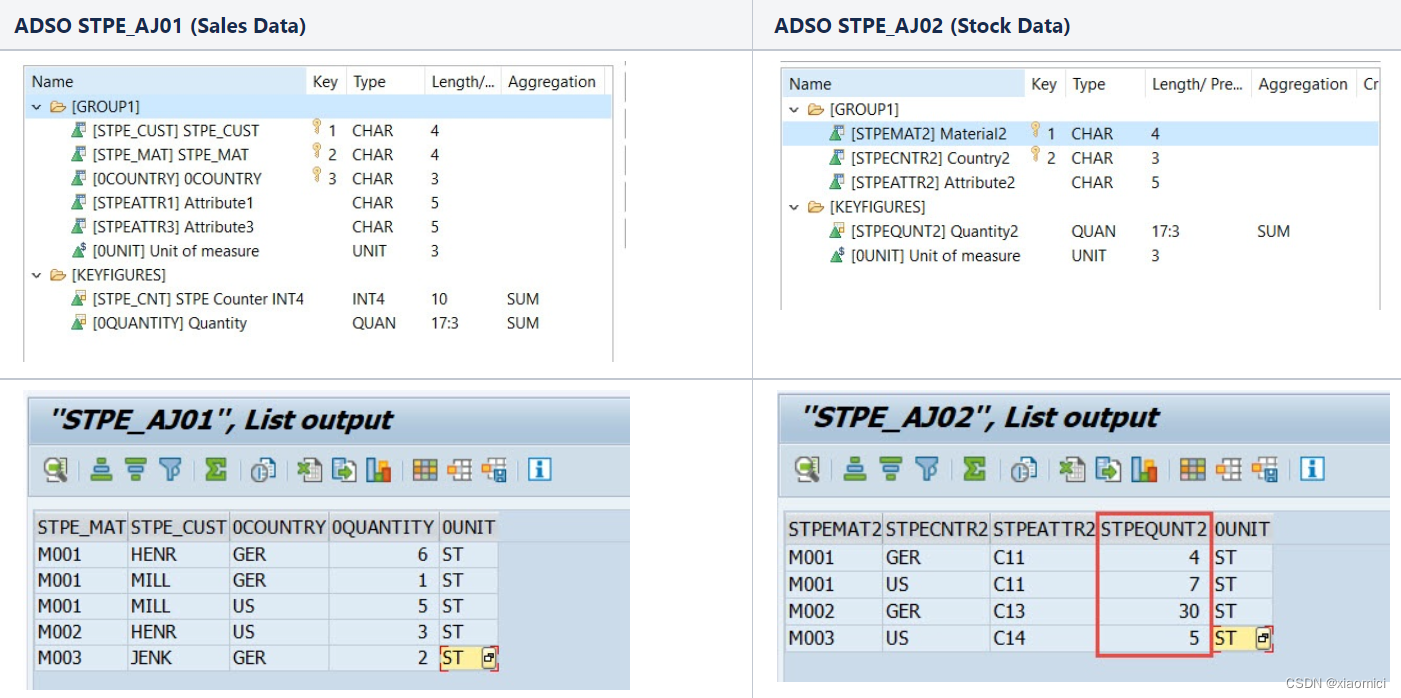
内连接的结果如下:
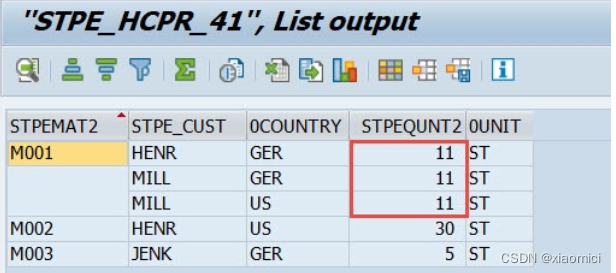
11这个值由于第一个ADSO的联合主键会出现三次,有三条M001,但是我们query会只要一个customer和quantity,那么系统还得要在country和material上面做聚集。最后给出正确答案46。
下面这个query的值能看出来,query并不是简单粗暴的直接加得到57,而是给出总计值46.
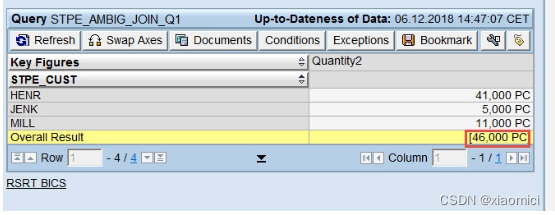
这一系列操作是怎么做的?
让我们捋一捋:
第一步内连接之后,值是这样的。
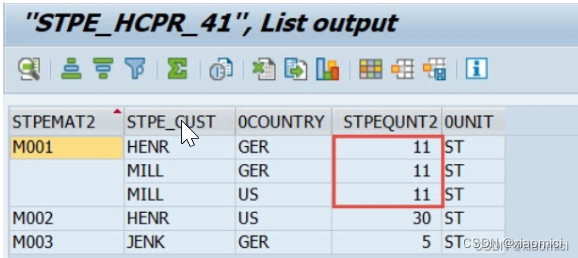
由于只有这一个join,那么本地分组就起作用了,数据库会自动给0country做聚集。把重复值去掉。
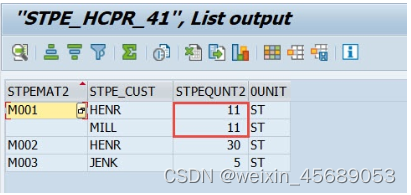
接下来就需要分析引擎来操作了,分析引擎就需要关联字段来做下钻,最后其实只需要一条11.
到RSRT去看:
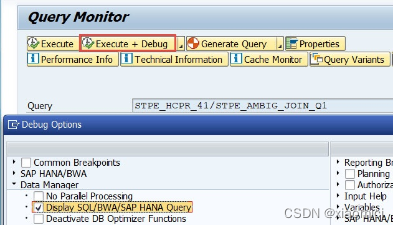
虽然说query里没把material加到自由特性,但是query在执行的时候还是选择了material。
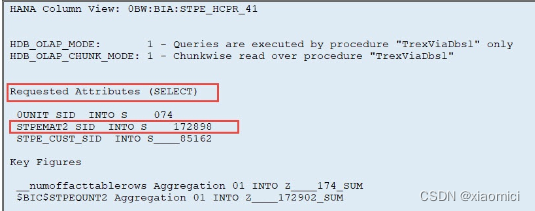
到RSRT看query的技术信息,也能看到,虽然我们字query里只选了quantity和customer,其实几乎所有的字段都被当成非可见的下钻字段了,后台都去把他们查了一遍。这也就是为啥这种ambiguous join耗费时间了。
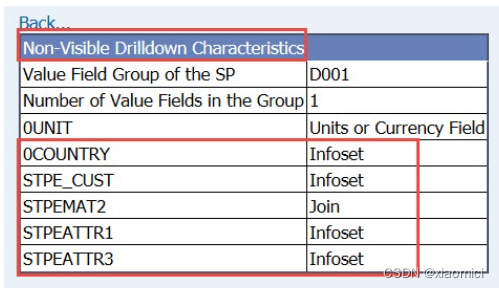
但是如果我们把行上的customer移除掉,那就只有一个select的字段是unit这个单位值,因为我们要拿的是个关键值,会自动带上单位。这时候也不会去select任何特性了,不会去做join啥的,就只把这个quantity值拿来就行了。
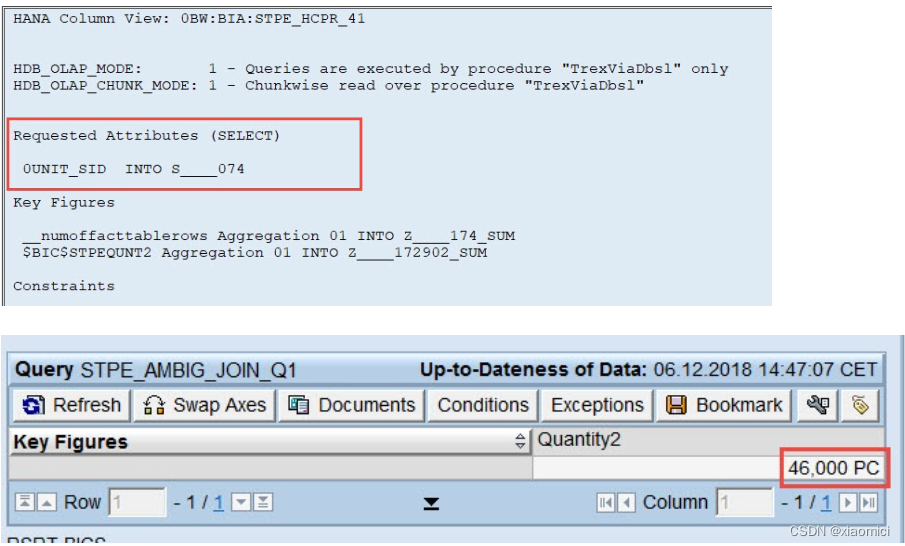
3. 高内存消耗
所以说一旦join的基数不是1:1的,那分析引擎就说得要把两边join的数据都拿来分析,到底啥聚集值才是正确的。要是俩边m:n值太多,那分析引擎就得狂跑。
如果有时候join了好几层,join字段也不一样,数据库不能提前做本地分组,把活都甩给分析引擎,那分析引擎会看你query里要啥字段,然后决定把所有的join字段和非join字段都取过去分析计算。
此时,如果你的query里面还有一些规定的filter值,那就回需要把这个filter的值也取到分析引擎做分析计算。