LLM是优秀的手语翻译者
- 简介
- Related Work
- Method
- SignLLM Overview
- ector-Quantized Visual Sign Module
- Codebook Reconstruction and Alignment
LLMs are Good Sign Language Translators
简介
基于观察,我们发现LLMs可以通过利用与之前学习过的语言的共有特性来有效处理新语言。因此,我们旨在引入一些设计,将这些签名视频转换为对LLMs可读和友好的类语言格式。具体而言,我们假设向LLM提供签名视频的语言式表征可以改善LLM对签名视频的理解,并促进对之前学习过的语言的共有特性的更大利用,从而使得LLM在SLT(手语到语音翻译)性能上取得更好的表现。
为了获得类语言的签名视频表征,我们从语言学研究和LLM的分析中汲取灵感,并通过以下两个基本的类语言特性来规范化签名视频:离散特性:口语语言本质上是离散的,因为每种语言都包含有限的词汇(和子词)来表达不同的概念,这使得它们可以通过具有不同标记的离散词汇自然地表示[8, 59]。分层结构:大多数口语都表现出三个分层的语义级别——句子、词汇和字符级别[36, 52]。这种分层结构使得语言可以用有限的字符表达广泛的词汇,以及用有限的词汇表达多样化的句子。
在本文中,我们提出了SignLLM,这是一个新颖的框架,旨在规范化输入的签名视频,生成具有类语言特性的签名标记表征,这些表征与LLMs兼容且友好。我们提出的SignLLM包括两个关键设计,以赋予生成的签名标记离散特性和分层结构。
首先,我们引入了向量量化的视觉签名(VQ-Sign)模块,该模块促进将签名视频转换为一系列离散的字符级别签名标记。为了实现这一点,VQ-Sign模块包含一个通过自监督上下文预测任务优化的字符级别签名码本。接下来,我们引入了码本重建与对齐(CRA)模块,该模块通过最优传输公式将字符级别的签名标记转换为词汇级别的签名标记。
此外,我们还采用了签名-文本对齐损失,以进一步缩小签名标记与文本标记之间的差距。这些设计使得SignLLM能够生成体现口语语言两个关键特性的签名句子:离散特性和分层结构,这增强了它们与LLMs的兼容性,并使它们更容易被LLMs解读。
在生成类语言的签名句子后,我们将它们与一个现成的且冻结的LLM以及一个文本提示一起输入,指示LLM生成所需语言的翻译。我们通过实证观察到,通过采用我们的SignLLM设计来对齐签名视频与语言,我们已经可以利用一个冻结的LLM达到SLT的最先进性能。这些发现表明,我们提出的SignLLM框架是有效利用LLMs进行SLT的一个有希望的第一步。我们希望我们的初步探索能启发社区内的未来工作,利用LLMs进行SLT。
总之,我们的主要贡献是:
(1)我们提出了一个新颖的SignLLM框架,这是第一个利用现成的且冻结的LLMs进行SLT的框架。
(2)为了使输入的签名视频与LLMs兼容,我们的SignLLM框架融合了两个设计:一个VQ-Sign模块,将签名视频量化为一系列离散的字符级别签名标记,以及一个CRA模块,将字符级别的签名标记转换为词汇级别的签名标记。
(3)通过我们提出的设计,我们在两个流行的SLT数据集上取得了无需词汇的最先进结果。
Related Work
手语翻译(SLT)旨在将手语视频转换为自然语言句子。这是一项具有挑战性的任务,需要理解视觉和语言线索[69, 72, 73],而配对的手语-文本数据有限更是加剧了这一挑战,限制了SLT方法的性能。为了提高SLT的性能,许多先前的工作旨在增强SLT方法的视觉手语表征和文本解码能力。一些工作提出了基于RNN、GCN[34]和Transformer的深度架构。其他方法包括引入关键点估计器以增强视觉手语表征,引入预训练任务[22, 72],或联合建模几个与SLT相关的任务。一些工作还引入了更大的数据集(例如,How2Sign和BOBSL),它们具有庞大的手语和文本词汇,带来了巨大的挑战。
此外,一些近期的工作[67, 72]关注无标注语义词境——这些工作在训练过程中不使用手语标注语义词,这降低了训练SLT模型的成本,我们的工作也属于这一类别。与现有工作相比,我们旨在利用现成的、冻结的大型语言模型(LLM)来进行SLT,通过将手语视频规范化为类似语言的表征,并提示LLM生成所需语言的文本。
大型语言模型(LLMs)指的是在非常大的网络级文本语料库上经过广泛训练的语言模型。LLM展示了令人印象深刻的文本生成能力,最近吸引了大量关注。特别是,由于LLM在大量文本数据上进行训练,它们在包括代码生成、开放领域问题回答和多语言翻译在内的各种基于文本的任务上展现了强大的泛化能力。
受到LLM最近进展的启发,我们探索利用LLM进行手语视频的翻译,通过我们的SignLLM框架将手语视频转换为一系列类似语言的符号令牌,并将这些符号令牌视为一种可以通过LLM翻译的语言。据我们所知,我们是第一个利用现成的、冻结的LLM来解决SLT问题的研究。
Method
在本节中,我们首先在第3.1节介绍我们SignLLM的概览。接着,我们在第3.2节和第3.3节分别描述SignLLM框架的两个主要组成部分:VQ-Sign和CRA模块。最后,我们在第3.4节列出训练和推理的细节。
SignLLM Overview
为了有效地处理手语翻译(SLT),本文我们受到了LLM在跨多种语言生成翻译方面的卓越能力的启发[9, 15]。特别是,LLM已经在大型网络规模的多元文本语料库上进行了广泛训练,并且学习了许多语言特性的多样知识,因此它们能够借鉴先前学习语言的共有特性,以有效地处理数据有限的新语言[66, 76]。
因此,为了利用LLM强大的翻译能力来处理SLT,我们引入了一种新颖的SignLLM框架。SignLLM将输入的手语视频转换成与口语语言的言语特性对齐的语言式手语句子,并且这种句子对LLM友好且兼容。然后,为了执行SLT,可以将语言式手语句子连同指导LLM生成目标语言翻译的文本提示一起输入现成的且冻结的LLM。
具体来说,为了生成对LLM友好且易懂的手语句子,我们旨在将我们的手语句子规范为体现两个核心言语特性:离散特性:口语语言自然是离散的,由具有相应词汇中离散标记的独立单词或子单词组成[8, 59]。层次结构:大多数口语语言表现出三个层次化的语义水平——句子、单词和字符水平[36, 52],其中单词由字符组成,句子由各种单词组成。

为了实现上述目标,我们的SignLLM框架如图1所示,包含三部分:
- VQ-Sign模块将输入的手语视频转换为离散的手语标记序列,将手语表示与文本的离散特性对齐。这些手语标记是从学习的离散字符级码本中检索的字符级手语标记。
- CRA模块将字符级手语标记的有意义的组合映射为形成手语句子的单词级手语标记,进一步将层次化的语言式结构赋予视频手语表示。此外,我们还使手语标记码本向文本标记空间对齐,以提高语义兼容性。
- 现成的LLM将手语句子作为输入,并有一个指导性的文本提示,指导LLM生成目标语言的翻译。关于文本提示的更多细节在附录中。接下来,我们将详细介绍我们的VQ-Sign和CRA模块。
ector-Quantized Visual Sign Module
首先,为了生成类似语言的表示,我们希望赋予输入手语视频_离散特性_,使其与本质上是离散的、由词汇中独特标记组成的口语语言表示更为接近。然而,这并非易事,因为手语视频是在高维时空空间中的连续信号,不能轻易地由一组离散标记来表示,且相应的词汇并不容易获得。因此,我们引入了我们的向量量化的视觉手语(VQ-Sign)模块,通过手语代码本将手语视频量化为一系列离散的手语标记。如图1所示,我们的VQ-Sign模块包含一系列步骤,下面我们将详细阐述。
在第一步中,我们从高维输入手语视频中提取紧凑特征,其中是视频帧数,和分别是视频帧的高度和宽度。确切地说,手语视频首先被组织成一系列短的、重叠的视频片段,然后每个短视频片段被送入视觉编码器以提取维度为的紧凑特征表示。总的来说,这一步骤将原始的高维输入手语视频转化为紧凑特征,其中表示相邻片段起始帧之间的帧数。值得注意的是,由于是通过处理个短片段获得的,也可以被视为一系列个片段级特征,即,其中每个对应于第个短片段的特征。
在下一步中,我们使用代码本将特征转化为一系列离散标记。具体来说,我们将每个片段的特征通过找到代码本中的匹配标记来离散化为离散标记,其中代码本中的第个标记表示为,是代码本中的标记数。匹配标记是代码本中与特征在欧氏距离上最近的元素,即。匹配后,每个特征被替换为,如图1所示,形成一个离散标记序列,例如。需要注意的是,我们在开始时随机初始化代码本中的所有标记,并在训练过程中优化它们,如下所述。
然而,我们在学习离散码本 时面临挑战。特别是,尽管自动编码 [59] 已成为生成离散单元码本的一种流行方法,但手语视频的高复杂性使得自动编码(即手语视频的自我重建)具有挑战性且成本高昂。因此,受到在文本和语音表示学习中广泛使用的前馈编码 [4, 6, 44, 46] 的启发,我们提出通过上下文预测任务来学习手语视频的离散表示。上下文预测 [46] 是一种自监督任务,它关注于基于当前信息在潜在空间中识别未来的内容,这种任务可以在不重建高维输入视频数据的情况下学习离散表示。此外,先前的工作表明,使用上下文预测进行训练可以有效捕捉序列元素之间的时间依赖性和关系 [5, 27],并且学到的表示通常可以迁移到下游任务 [6, 46]。
具体来说,我们采用了一个上下文预测任务,在这个任务中,我们尝试在各个时间步 上基于当前的上下文表示 来区分未来的样本 。为了促进这项任务,在我们获得离散标记序列 之后,我们进一步使用一个自回归模型 来生成上下文潜在表示 ,该模型汇总了在某个时间步 之前的所有离散标记(即 )以产生上下文潜在表示 。然后,我们通过最小化以下上下文预测对比损失 来优化我们的模块:
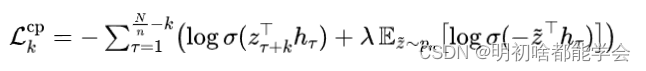
其中 是通过应用一个可训练的线性层到 得到的, 是 在负样本中为真实样本的概率, 是从一个小批量 中抽取的负样本, 是一个超参数。我们将 在不同的步长 上求和,以获得上下文预测损失 ,其中 是我们感兴趣的未来片段的最大数量。
遵循 [18],为了优化 和 之间的匹配,我们进一步添加了两个损失来优化 和 之间的匹配距离,这样我们的 VQ-Sign 模块要优化的总损失 如下:
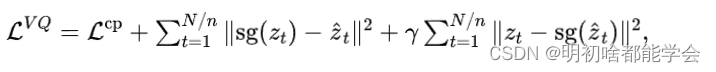
其中 是停止梯度运算符, 是一个超参数。通过优化 ,我们可以训练我们的 VQ-Sign 和离散码本,而无需重建高维视频片段,这使得码本构建成为一个可行且相对低成本的选项。
总之,我们的VQ-Sign将手语视频转换为离散的手语标记序列 ,这对LLMs来说更加友好和易于理解。值得注意的是,生成的离散标记 可以类比为字符级标记,在某种意义上,每个离散标记 对应一个短片段,并且单独可能不包含太多的语义意义(类似于语言字符),但它们可以组合成一个序列以传达清晰的语义意义(类似于形成一个词或句子)。因此,受到这一点的启发,我们将VQ-Sign的码本 称为字符级码本,其中包含字符级的手语标记。
Codebook Reconstruction and Alignment
在前一节中,我们将符号视频量化为离散的字符级符号标记,这使得它们更接近语言表示。在本节中,我们的目标是给我们的符号视频表示赋予一种_分层结构_,使它们与语言表示的契合度更高。具体而言,我们的目标是将由字符级符号标记组合成单词级符号标记,以反映口头语言中观察到的分层结构,这使得它们与大型语言模型(LLMs)更加兼容。
直观地说,考虑一个口头语言的句子,我们可以将其表示为单词序列,每个单词由一个或多个字符组成。例如,句子 ‘I love AI’ 可以分解为单词序列 [‘I’,‘love’,‘AI’],其中单词 ‘love’ 又由字符序列 [‘I’,‘o’,‘v’,‘e’] 组成。我们观察到,尽管每个单独的字符本身可能不包含太多的语义意义,但它们可以组合成具有更清晰语义意义的单词。类似地,我们也希望通过将字符级符号标记组合成有意义的单词级符号标记,从而赋予它们类似的分层结构。
因此,我们的目标是找到从字符级符号标记到单词级符号标记的最优转换,以提高可读性并与LLMs增强兼容性。为此,我们引入了代码簿重建与对齐(CRA)模块,将VQ-Sign的字符级代码簿 转换为单词级代码簿 ,其标记传达更丰富、更清晰的语义意义。受到最优传输方法[61, 65, 16]的启发,我们观察到上述转换可以表述为一个将字符传输到单词的最优传输问题,因此我们引入了一个带有最优传输公式的_代码簿重建算法_来找到最优转换。此外,为了进一步减小符号标记与文本标记之间的分布差距,我们的CRA模块还执行_符号-文本对齐_,增强符号标记与LLMs的语义兼容性。下面我们将详细介绍。
首先,我们代码簿重建算法的目标是基于VQ-Sign的字符级代码簿 创建一个单词级代码簿 。挑战在于确定哪些字符级符号标记应该组合在一起形成单词级符号标记,这是一个复杂的问题。为了解决这一复杂性,我们采用了基于两个基本原则的方法。首先,为了最大化单词级标记的整体可预测性并增强每个标记的独特性,我们力求最小化词汇表中每个单词级标记的_熵_ [42]。
我们注意到,几种基于语言建立子词词汇表的方法[55, 8]可以看作是熵最小化方法,它们采用不同的启发式方法建立词汇表,以达到熵最小化的目的[23]。另一方面,考虑到符号视频数据的有限可用性,我们将_代码簿大小_作为我们单词级代码簿构建中的另一个关键因素,因为有限数据语言的研究[53, 26]也识别出词汇量是一个关键方面。特别是,过小的词汇量可能导致次优的熵值,而过大的词汇量可能导致参数爆炸和标记稀疏等问题,这会影响理解[2],对于有限数据的语言来说,找到这些效果的恰当平衡变得更加敏感[53, 19]。
基于这些原则,我们的目标是确定一个最优的码本大小,以最大化熵减的同时考虑码本大小的增加。换句话说,我们希望找到一个最优的码本大小,这个大小能在码本增加时使熵减的梯度最大化。为了简化寻找最优大小的问题,我们定义了一个固定大小增量,并通过各种大小的码本进行搜索(每个码本大小之间的差异为个标记)。具体来说,我们将第个码本()定义为含有个标记的码本。然后,我们寻求确定最优的单词级别标记集合,其中每个单词级别标记由字符级别标记组成。我们通过将字符组合构建为一个最优传输问题来解决这个问题,其中字符被传输到单词。
然而,由于手语视频的时间复杂性,确定能传达精确语义信息的特定字符组合可能会很有挑战性,这通常使得字符级别标记序列变得相当混乱。例如,一些签署者可能以较慢的速度执行签署动作,这可能导致连续的短视频片段非常相似,从而导致连续重复的字符级别离散标记。因此,由于这种字符级别标记的重复,不同签署者之间的字符级别序列可能会相差很大(例如,与),即使它们可能包含相同的语义信息。同时,简单地直接过滤掉重复的字符级别标记(例如,将所有设置为)并不是最优的,因为某些手语的速度也能传达一些信息[31, 60],例如,如果签署者快速签署“ugly”,它在美式手语中传达的是“very ugly”。
重复字符的预处理。 因此,为了减轻签署者速度的影响,同时保留每个手语速度的信息,我们首先对字符级别序列进行以下预处理:首先,我们在字符级别序列中找到所有重复的标记,并计算每个序列中重复标记的平均数量()。然后,对于每个重复序列(例如,),我们保留第一个字符并移除尾随的重复字符(例如,变为)。同时,如果字符级别标记重复超过次,我们插入一个单独的字符级别标记作为“减速”信号,例如,如果,变为。关键在于,这允许我们减少冗余,同时仍然表示考虑签署者速度差异的“快速”或“慢速”手语。总的来说,这种预处理和减少重复字符使得字符级别序列变得不那么混乱,有助于寻找特定的有意义的字符组合。