T2T基因组文献分享Telomere-to-telomere haplotype-resolved reference genome reveals subgenome divergence and disease resistance in triploid Cavendish banana
三倍体植物基因组的文献,各位同仁还有什么有特色的基因组评论区留言~

摘要
香蕉是世界上最重要的作物之一。香芽蕉型香蕉,其起源单一,均来自小果野蕉(AAA),约占全球香蕉产量的一半,因此对人类社会具有重大意义。然而,直到现在,香蕉栽培品种的高质量单倍体解析参考基因组仍然未被解码。在这里,我们报道了巴西蕉(香芽蕉)的端粒到端粒(T2T)及单倍体解析参考基因组,包含三个单倍体组装体。这三个单倍体组装体的大小分别估计为477.16 Mb、477.18 Mb和469.57 Mb。尽管起源单一,这三个单倍体组装体显示出很大差异,序列共线性水平低。在第1、4和7号染色体之间识别出几个大型互易易位。检测到可能影响果实品质和香气的基因家族扩张,如属于蔗糖/双糖/寡糖分解过程、蔗糖代谢过程、淀粉代谢过程和芳香化合物生物合成过程的基因家族。此外,还观察到与花药和花粉发育相关的基因家族扩张,这可能与香芽蕉品种的无核性和不育性有关。最后,在巴西蕉中鉴定的抗性基因比在小果野蕉中少得多,尤其是在第3和10号染色体上的基因簇中,为探索香蕉疾病抗性的分子分析提供了潜在目标。因此,这个T2T单倍体解析参考基因组将成为生物学研究、分子育种和香蕉遗传改良的宝贵遗传资源。
引言
香蕉起源于东南亚和西大洋洲地区,在那里至少在7000年前就已被驯化。大多数香蕉品种是无籽克隆品,主要是来自野生育性二倍体Musa种的二倍体或三倍体。香蕉品种的遗传多样性主要是由小果野蕉(A基因组,2n=22)内的杂交事件,以及这个物种与Musa balbisiana(B基因组,2n=22)之间的杂交产生的;同时,Musa schizocarpa(S基因组,2n=22)和Australimusa科的物种(T基因组,2n=22)也在较小程度上贡献了可食用香蕉品种的遗传内容。香蕉品种是全球消费量最大的水果之一:每年生产的香蕉超过1亿吨。此外,香蕉品种也是最不发达国家生产量第五大的粮食作物;因此,它们在这些地区维持粮食安全中发挥着重要作用。对栽培香蕉的需求持续增长;然而,它们的生产受到复杂的生物和非生物压力的极大影响。例如,香蕉产量严重受到由真菌Fusarium oxysporum f. sp. cubense (Foc)引起的香蕉枯萎病的威胁。因此,培育具有改良特性的新香蕉品种,特别是对广泛多样的病原体具有遗传抗性,对未来香蕉生产至关重要;毫无疑问,高质量的香蕉基因组将促进这种遗传操作。
10多年前就开始了香蕉基因组的测序工作。D’Hont等人报道了第一个双单倍体Pahang (DH-Pahang) 小果野蕉亚种malaccensis的草图基因组,为香蕉的遗传育种提供了关键的垫脚石。从那时起,DH-Pahang基因组已被改进两次。此外,过去十年间还报道了其他Musa基因组,例如M. balbisiana、Musa itinerans、M. schizocarpa、Musa troglodytarum和Musa beccarii。这些高质量的香蕉基因组为Musa属的进化研究以及香蕉的驯化和育种提供了必要且宝贵的资源。技术进步提高了测序能力,使得从多个物种和品种的复杂基因组的测序成为可能。多亏了长读序列,现在能够进行端到端(T2T)无缝隙的染色体序列组装,为解开前一组装中遗漏的基因组区域提供了前所未有的机会。然而,长期以来,由于基因组的复杂性,香蕉品种缺乏高质量的基因组。
在香蕉中,最有效的倍性水平是三倍体,这产生了更有活力的植物、更高的不育性和更大的无籽果实。单一物种来源的香芽蕉型香蕉(AAA)占全球香蕉产量的大约一半。几乎所有全球香蕉出口贸易都依赖于来自独特的三倍体香芽蕉品种的克隆,导致这种类型的香蕉具有狭窄的遗传基础。在本研究中,我们通过整合PacBio高保真(HiFi)读取、Oxford Nanopore Technology(ONT)超长读取和Hi-C读取,开发了一个香蕉品种巴西蕉(AAA,香芽蕉)的T2T参考基因组,该基因组由三个单倍体组装构成。这个单倍型解析的参考基因组揭示了三个单倍体组装之间存在很大的差异,序列共线性水平低。此外,发现一些巴西蕉特异基因家族的富集生物过程与果实品质和香气、以及无性生殖和不育性有关。最后,与小果野蕉基因组相比,巴西蕉基因组中抗性基因的数量明显减少,揭示了这个品种对香蕉枯萎病易感性的可能机制。我们希望这个高质量的基因组将帮助我们更好地理解香蕉的驯化,并为生物学研究和香蕉品种的育种开辟新的机会。
结果
高度连续和分相的三倍体参考基因组的组装
我们通过结合PacBio HiFi序列、Oxford纳米孔序列和Hi-C序列生成了巴西蕉基因组。总共获得了102.06 Gb(约总基因组大小的72×覆盖率)的PacBio HiFi读取,N50超过15 kb,48.00 Gb(约34×覆盖率)的ONT读取,N50为80 kb,以及156.14 Gb(约110×覆盖率)的Hi-C数据(表S1,请参见在线补充材料)。
利用基于21个k-mer的GenomeScope 2.0【18】估算,巴西蕉的单倍体基因组大小约为457.31 Mb,杂合率为2.855%(图S1,请参见在线补充材料)。为了实现端到端(T2T)和单倍型解析的基因组,我们采用了一种组装方案,该方案允许结合HiFi和Hi-C读取来组装分相的基因组,并结合ONT读取来填补空缺(图S2,请参见在线补充材料)。基于HiFi和Hi-C读取,应用hifiasm【19】构建了一个分相的二倍体组装,生成了581.77 Mb和959.85 Mb的主要连续片段,N50分别为14.95 Mb和16.15 Mb。在小果野蕉 ssp. malaccensis(X. Liu等人未发表的结果)的T2T基因组的帮助下,连续片段进一步被排序、定向和分组。然后使用Hi-C读取来锚定和移除一些短连续片段,除此之外还将较大的连续片段分成两组。接下来使用NextDenovo(GitHub - Nextomics/NextDenovo: Fast and accurate de novo assembler for long reads)来构建ONT组装,随后用于填补HiFi组装的参考基因组的空缺。填补空缺后,生成了一个几乎完整和分相的参考基因组,名为BXJ,包含33个假染色体(每个单倍体组装11个),总长度为1.42 Gb,单倍体组装的大小为469.57–477.18 Mb(图1A和表1;表S2,请参见在线补充材料)。三个单倍体组装分别命名为BXJ1、BXJ2和BXJ3。每个单倍体组装中最长的染色体是染色体8,大小分别为53.00 Mb、54.63 Mb和52.65 Mb。最短的染色体在BXJ1和其他两个单倍体组装之间略有不同;具体来说,染色体2是BXJ1中最短的染色体(33.52 Mb),而染色体11是BXJ2(33.79 Mb)和BXJ3(32.90 Mb)中最短的染色体。使用100-kb间隔,分别计算了BXJ基因组的基因密度、TE密度、Copia密度、Gypsy密度、GC含量和潜在的着丝粒串联重复密度(图1A)。这是第一个端到端和单倍型解析的三倍体香蕉参考基因组。

香芽蕉参考基因组概览。A 巴西蕉基因组的circos图。轨迹代表以下元素(从外到内):(a) 33条染色体序列的示意图,(b) 着丝粒重复序列密度,(c) GC含量,(d) 可移动元素密度,(e) Gypsy元素密度,(f) Copia元素密度,(g) 基因密度。最内层是同源关系。B 巴西蕉基因组的Hi-C相互作用热图。C 33个假染色体的HiFi覆盖率。D 在BXJ1、BXJ2和BXJ3中HiFi、Illumina和RNAseq读取的映射率。E 在BXJ1、BXJ2和BXJ3中的BUSCO评估。F BXJ1、BXJ2和BXJ3之间的序列共线性。灰线代表长度为15,000 bp的共线性块,红线代表潜在的倒置。
Table 1
Genome assembly statistics for 巴西蕉 and MAv4
| Baxijiao | MAv4 | |||
|---|---|---|---|---|
| BXJ1 | BXJ1 | BXJ1 | ||
| Cumulative size (bp) | 477 162 536 | 477 181 898 | 469 568 689 | 468 821 802 |
| HiC scaffolds | 11 | 11 | 11 | 11 |
| Complete BUSCO (N = 1614) | 97.40% | 97.80% | 93.80% | 98.80% |
| Gaps | 33 | 40 | 71 | 15 |
| After gap-closing | 0 | 2 | 0 | 15 |
| Number of Telomere | 19 | 17 | 17 | 22 |
| HiFi mapping rate | 99.84% | 99.80% | 99.50% | |
| Illumina mapping rate | 97.95% | 97.66% | 96.36% | |
| Repeats | 53.76% | 54.14% | 55.13% | 52.62% |
| LAI index | 19.84 | 20.65 | 20.22 | |
| Number of predicted genes | 37 185 | 37 241 | 37 178 | 36 979 |
基因组注释和质量评估
在三个单倍体组装中,分别鉴定出256.48 Mb(53.76%)、258.29 Mb(54.14%)和258.84 Mb(55.13%)的重复区域(表S3,请参见在线补充材料),与其他香蕉基因组中的重复区域相似(例如小果野蕉:52.62%【7】;M. beccarii:55.99%【12】)。其中,最丰富的重复序列是长末端重复(LTR),在BXJ1、BXJ2和BXJ3组装中分别占36.36%、35.44%和33.53%(表S3,请参见在线补充材料)。从BXJ1、BXJ2和BXJ3预测出总共37,185、37,241和37,178个高置信度蛋白编码基因(表1),这比最新版本的小果野蕉双单倍体基因组(以下简称MAv4)【7】预测的基因数(36,979)略多。BXJ1、BXJ2和BXJ3预测的基因总长度分别为142.78 Mb、138.99 Mb和133.28 Mb。这些蛋白编码基因的平均长度分别为3,839 bp、3,732 bp和3,584 bp。
使用七个碱基重复序列(5'端的CCCATTT和3'端的TTTAGGG)作为查询,我们共估计了53个端粒,并分别为BXJ1、BXJ2和BXJ3构建了8、6和6个端粒到端粒的染色体(表S4,请参见在线补充材料)。识别的端粒长度在BXJ1中范围为6,006到33,838 bp,在BXJ2中为2,345到44,905 bp,在BXJ3中为4,494到26,964 bp。最长的端粒序列位于BXJ2的Chr10右端,而最短的一个位于BXJ2的Chr08右端。
着丝粒是染色体上的一种特殊核苷酸序列,它将两个子染色单体连接在一起,并参与有丝分裂和减数分裂中的移动。使用串联重复查找器【20】,识别出了巴西蕉基因组中着丝粒的大致位置,长度范围在BXJ1为924,207到3,415,439,在BXJ2为930,592到3,844,332,在BXJ3为481,633到4,080,464 bp(表S5和图S3,请参见在线补充材料)。
BXJ组装的质量和完整性通过多种方式进行评估。首先,估计的每个单倍体组装的基因组大小(469.57–477.18 Mb)略长于MAv4的基因组大小(~468.82 Mb)【7】;此外,JuiceBox【21】可视化的Hi-C数据在所有染色体上展现了高度一致性,提供了其排序和定向的准确性(图1B)。其次,HiFi和Illumina读取都与三个单倍体组装进行了比对;每个染色体的平均HiFi读取覆盖率约为200×(图1C);此外,97.95%、97.66%和96.36%的Illumina读取,以及99.84%、99.80%和99.50%的HiFi读取分别成功比对到BXJ1、BXJ2和BXJ3(图1D),表明这个组装充分且高覆盖了巴西蕉基因组。第三,三个单倍体组装观察到高LTR组装指数(LAI)分数(19.84、20.65和20.22)(表1)。最后,使用BUSCO【22】进行的完整性评估显示,BXJ1、BXJ2和BXJ3的完整序列分别占保守的核心真核基因集的97.40%、97.80%和93.80%(表1和图1E)。总体而言,这些结果展示了BXJ参考基因组的高质量、准确性和可靠性。
全基因组比较和同源性分析
BXJ1、BXJ2和BXJ3具有一组相似的基因组特征,如类似的基因组大小和基因数目,以及平行的重复内容(表1)。然而,同源性分析揭示了单倍体组装之间核苷酸序列的低水平共线性(图1F),这可能归因于亚种小果野蕉亚基因组的不同起源。同时,由于进化上保守的编码区域,观察到三个单倍体组装中基因之间的高同源性关系。基因组共线性分析揭示,在三对两两比较中(BXJ1对BXJ2,BXJ1对BXJ3,BXJ2对BXJ3),分别有29,131、27,571和28,838个转录本匹配到31、37和37个同源性块。使用MCScan【23】识别了BXJ基因组内的大量结构变异。在Chr01、Chr04和Chr07之间识别出了几个大的互换易位(图2A)。具体来说,观察到Chr01和Chr04之间的同源性关系,表明在BXJ2的Chr01长臂远端和BXJ1及BXJ3的Chr04长臂中的0.47–0.50 Mb区域发生了一次互换易位(图S4A,请参见在线补充材料)。此外,还识别了另一次涉及BXJ1和BXJ3的Chr01长臂远端的1.88–3.12 Mb区域与BXJ2的Chr04长臂的互换易位(图S4B,请参见在线补充材料)。此外,还观察到Chr01和Chr07之间的同源性关系,显示了在BXJ1的Chr01长臂远端与BXJ2的Chr07中的1.04 Mb区域之间存在互换易位(图S4C,请参见在线补充材料)。
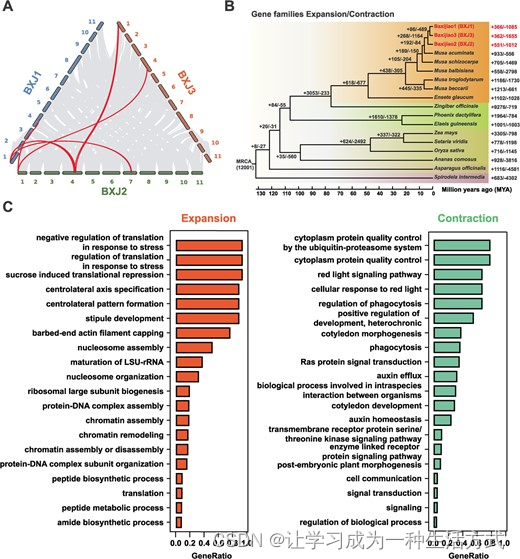
在巴西蕉内部和巴西蕉与其他单子叶植物种类之间的全基因组比较。A 基因水平的同源性分析。突出显示的线代表互换易位。其他线代表同源性块。B 推断的系统发育树及在巴西蕉和其他单子叶植物中扩张(+)或收缩(-)的基因家族。在分支(物种间共享/BXJ单倍体组装)和叶节点(特定物种/BXJ单倍体组装中共享)上扩张和收缩基因家族的数量已被标注。C 巴西蕉中扩张和收缩基因的顶级富集生物过程。
根据序列同一性,我们在单倍型解析的BXJ基因组和MAv4之间获得了18,263组等位基因组(表S6,请参见在线补充材料)。这些等位基因组在基因组的11条染色体上均匀分布。三个单倍体组装中大多数等位基因的编码序列与MAv4中的高度相似(平均值=96.50%,96.59%,和96.62%)。此外,通过计算等位基因对之间的Ka/Ks值,我们发现大多数等位基因经历了纯化选择(Ka/Ks<1,图S5,请参见在线补充材料)。
基因家族进化
我们使用巴西蕉和其他15种单子叶植物中的同源基因进行了系统基因组学分析,包括香蕉栽培品种的主要祖先贡献者:小果野蕉(A基因组)、M. balbisiana(B基因组)、M. schizocarpa(S基因组)和M. troglodytarum(T基因组)。系统发育树表明,巴西蕉的三个单倍体组装聚在一起,与小果野蕉亲缘关系最近(图2B)。
总共从选定的单子叶植物种类的612,509个基因中鉴定出了38,387个正交群。基于系统发育树,鉴定出可能扩张和收缩的基因家族。总共有447个显著扩张和收缩的基因家族,包含1,551个特定于巴西蕉的基因。共有117个基因家族由694个基因组成,在巴西蕉基因组中显著扩张。GO富集分析揭示,这些扩张的基因显著富集在199个生物过程中(表S7,请参见在线补充材料)。最富集的生物过程与应对压力和蔗糖诱导的翻译抑制有关(图2C)。有趣的是,一些其他显著富集的生物过程与碳水化合物来源和花粉发育有关,包括对二糖的反应、对蔗糖的反应、对碳水化合物的反应、接受花粉、识别花粉、花粉-柱头相互作用和花粉萌发。同时,330个基因家族由857个基因组成,在巴西蕉中显著收缩,富集在231个生物过程中(表S8,请参见在线补充材料)。大部分富集的生物过程(30%)与植物生长、形态发生和激素有关,如子叶发育、果实发育、花药发育、花器官形态发生、涉及繁殖的发育过程、生长素外流、激素介导的信号通路等。此外,一些富集的生物过程(14%)与对外部生物和非生物因素的反应有关,包括对共生真菌的反应、对细菌的反应、免疫反应激活的信号转导、红光或远红光信号通路、以及对蓝光的细胞反应。在单倍体组装中也鉴定了潜在的扩张和收缩基因家族(表S9,请参见在线补充材料)。有趣的是,一些显著扩张的基因家族在芳香化合物生物合成过程、蔗糖分解过程、二糖分解过程、寡糖分解过程、蔗糖代谢过程和淀粉代谢过程中富集,这可能对果实质量很重要(图S6和表S10–S12,请参见在线补充材料)。此外,一些扩张的基因家族涉及花药,特别是花药壁绒毡层的发育,如花药形态发生和花药壁绒毡层形成。
抗性基因
植物基因组通常包含大量的病抗(R)基因。植物R蛋白有两个主要类别:膜结合型模式识别受体(PRRs)和细胞内核苷酸结合、富含亮氨酸重复的受体(NLRs)。PRRs是受体样激酶(RLKs)或受体样蛋白(RLPs)【24】。在这项研究中,我们首先使用RGAugury【25】预测巴西蕉和小果野蕉中的抗性基因类似物(RGAs)。分别在BXJ1、BXJ2和BXJ3中预测了68、52和69个NBS编码基因,与MAv4中的124个相比(表2)。对RLK-和RLP型RGAs的预测也表明,巴西蕉携带的R基因明显少于小果野蕉(表2)。上述预测的RGAs在MAv4和巴西蕉基因组中的分布在补充图S7中展示(请参见在线补充材料)。此外,我们使用NLR-annotator【26】来表征可能与疾病抗性相关的基因组区域。预测的NLR位点可能是具有完整或部分开放阅读框的基因,也可能是被研究基因组中伪基因化序列的痕迹【26】。在BXJ1、BXJ2和BXJ3中分别检测到了123、126和140个NLR位点(表2;表S13–S15,请参见在线补充材料),与MAv4中的128个位点相比【7】。NLR位点在所有11条染色体上分布不均(图3)。一些NLR位点倾向于成簇地聚集在一起。在BXJ基因组中观察到三个主要的预测NLR位点簇:两个在Chr03和一个在Chr10(表3)。值得注意的是,BXJ基因组中大部分NLR位点位于基因间区域(BXJ1:37.4%;BXJ2:59.5%;BXJ3:38.6%)。与MAv4中的122个基因相似,三个单倍体组装中只预测到了77、51和79个抗性基因,与NBS编码RGAs的预测相似。特别是在Chr03长臂远端的基因簇中(BXJ1:43.02–43.80 Mb;BXJ2:41.36–42.09 Mb;BXJ3:36.85–37.62 Mb),所有NLR位点都被预测为伪基因化序列(图3和表3)。此外,在Chr10的基因簇中,所有NLR位点在BXJ2中(21.93–22.73 Mb)被预测为伪基因化,而在BXJ1(19.29–20.01 Mb)和BXJ3(20.93–21.73 Mb)中,大多数NLR位点根据基因注释仍被认为是功能性的(图3和表3)。总的来说,与小果野蕉相比,在巴西蕉中鉴定到的抗性基因数量要少得多。
Table 2
Summary of the predictions by RGAugury and NLR-annotator
| Genome | RGAugury | NLR-annotator | |||
|---|---|---|---|---|---|
| NBS encoding | RLK | RLP | NLR loci | NLR gene | |
| MAv4 | 124 | 752 | 109 | 128 | 122 |
| BXJ1 | 68 | 554 | 63 | 123 | 77 |
| BXJ2 | 52 | 541 | 87 | 126 | 51 |
| BXJ3 | 69 | 468 | 62 | 140 | 79 |
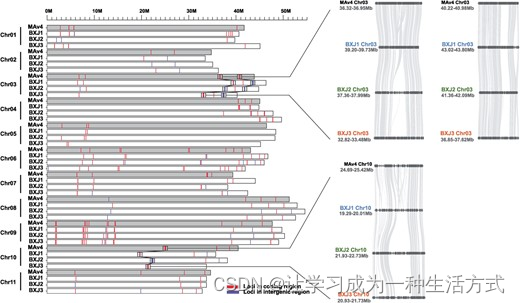
MAv4和巴西蕉基因组中NLR位点的分布。染色体上的线表示这些位点分别位于编码区和基因间区域。右侧面板展示了染色体3和10中基因簇的同源关系。
Table 3
Comparison of NLR clusters between the BXJ and MAv4 assemblies
| Chr | Location (Mb) | No. NLR genes / No. NLR loci | ||||||
|---|---|---|---|---|---|---|---|---|
| BXJ1 | BXJ2 | BXJ3 | MAv4 | BXJ1 | BXJ2 | BXJ3 | MAv4 | |
| Chr03 | 39.20–39.73 | 37.36–37.99 | 32.82–33.48 | 36.32–36.95 | 3/8 | 0/12 | 19/20 | 15/16 |
| Chr03 | 43.02–43.80 | 41.36–42.09 | 36.85–37.62 | 40.22–40.98 | 0/26 | 0/17 | 0/33 | 14/18 |
| Chr10 | 19.29–20.01 | 21.93–22.73 | 20.93–21.73 | 24.69–25.42 | 8/13 | 0/18 | 10/17 | 12/13 |
No. NLR genes: number of NLR genes predicted.
No. NLR loci: number of NLR loci detected.
分相三倍体参考基因组中同源基因的表达模式
为了确定同源基因的表达模式,我们重点关注了52593个表达基因(在总共18263个三联体中有17531个同源三联体,占95.99%),这些基因在三个单倍体组装中具有1:1:1的基因对应关系,并且在至少一个组织中的同源基因表达量>0.5个每百万转录本(TPM)(表S16,见在线补充材料)。对于这52593个表达的三联体,我们首先标准化了每个单独组织和联合分析中BXJ1、BXJ2和BXJ3同源基因的相对表达量。然后,我们进行了一项全球分析,整合了所有四个组织的数据(图4A)。平均而言,约40%的同源基因三联体显示非平衡的表达模式,其中单个同源基因相对于其他两个表现出较高(同源基因占优)或较低的表达量(同源基因受抑)。就每个组织而言,平衡的三联体范围从果实的49.45%到叶子的55.00%(图4B)。在每个组织中,同源基因占优的三联体以中等频率出现(范围从11.95%到12.83%),而同源基因受抑的三联体更为频繁(从33.06%到37.72%)。占优组中的同源三联体基因比平衡组或受抑组中的基因具有更高的绝对转录本丰度(图4C)。此外,我们发现非平衡三联体的Ka/Ks值略高于平衡三联体(图4D)。对非平衡三联体进行了GO富集分析;然而,这些基因没有观察到显著的功能富集。非平衡表达基因的密度在图4E中呈现,显示了这些基因沿染色体末端区域的丰度更高。
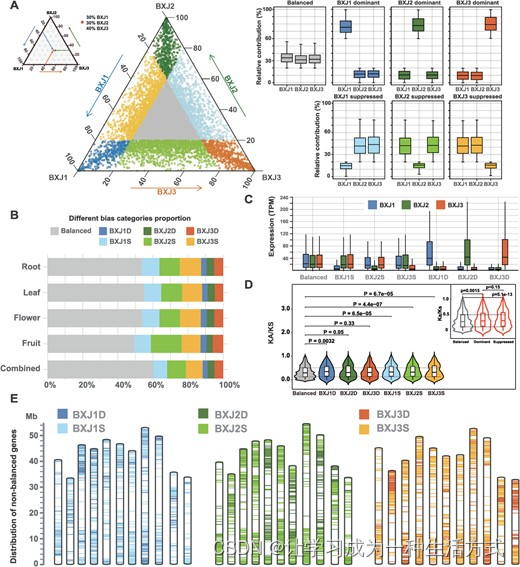
同源三联体中同源基因表达偏倚。A 三元图显示了巴西蕉中17531个同源三联体(52593个基因)的相对表达水平。每个圆圈代表一个基因三联体,其中BXJ1、BXJ2和BXJ3坐标表明每个同源基因对整体三联体表达的相对贡献(左上角显示了一个示例)。灰色圆圈代表平衡的三联体,而顶点处的彩色圆圈对应于同源基因占优组的三联体,靠近边缘和顶点之间的彩色圆圈对应于同源基因受抑组的三联体。箱形图基于三联体分配到七个组别,表明每个同源基因的相对贡献,包括分别代表BXJ1、BXJ2和BXJ3占优的BXJ1D、BXJ2D、BXJ3D,以及代表BXJ1、BXJ2和BXJ3受抑的BXJ1S、BXJ2S和BXJ3S。B 在4个组织中和综合分析中每组同源基因表达偏倚的贡献。C 七个组别中每个单倍体基因组的绝对TPM表达丰度的箱形图。D 七个类别的Ka/Ks值的小提琴图。平衡类别的Ka/Ks值略低于同源基因占优和同源基因受抑组。E 在所有33条染色体中同源基因表达偏倚基因的分布。
讨论
香蕉是全球最受欢迎的水果之一,也是全球产量第五大的食品作物。在香蕉的驯化过程中选择的主要特征是孤雌生殖和不育性,这确保了形成肉质且可食用的无籽果实。由于难以通过非孤雌生殖和育性野生种的重组生成高质量的孤雌生殖和不育品种,因此香蕉的遗传改良和育种极具挑战性。在这种背景下,香蕉品种的基因组特征描述和对野生向驯化过渡的深入理解对于成功的香蕉育种计划至关重要。在这里,我们组装了巴西蕉的端到端(T2T)和单倍型解析的参考基因组,它是最商业化的香芽蕉的代表。我们采用HiFi读取、ONT超长读取和Hi-C读取的组合装配方案生成了高质量的BXJ基因组,实现了高连续性和准确性的组装目标。包括基因组大小和一致性、读取映射、LAI得分和BUSCO在内的多项评估支持了BXJ组装的高质量、准确性和可靠性。此外,我们还确定了染色体中端粒和着丝粒的位置。据我们所知,这是首个三倍体香蕉的T2T和分相参考基因组。这个基因组将为进一步研究香蕉的驯化、分子育种和香蕉品种的遗传改良提供宝贵的遗传资源。
三倍体香芽蕉品种的单倍型解析参考基因组展示了亚基因组间的序列和表达差异
三倍体香芽蕉品种的单倍型解析参考基因组显示了亚基因组间的序列和表达差异。驯化过程在驯化物种的基因组中留下了标记。栽培香蕉源自于Musa属内部或种间的杂交[2]。大多数香蕉品种源自小果野蕉(A基因组),这是一组在地理上在东南亚的不同大陆和岛屿上被隔离的亚种[27]。四个特定的小果野蕉亚种被提出为香蕉品种的主要亲本贡献者,即banksii、burmannica、malaccensis和zebrina[1]。累积的证据将来自新几内亚的亚种banksii、来自爪哇的zebrina和来自马来西亚和苏门答腊的malaccensis作为香蕉品种遗传构成的主要贡献者,并且burmannica的参与较小[28, 29]。此外,最近对纯小果野蕉起源的香蕉品种的研究提出了存在缺失的祖先基因库,这些基因库参与了香蕉品种的形成[15, 16, 30]。香芽蕉型香蕉具有单一物种的小果野蕉起源(AAA)。以前的研究已经确定了‘Mlali’亚组,来自banksii和zebrina/microcarpa的后裔,作为香芽蕉的2N配子供体;这些研究还表明N配子由一个具有malaccensis从属关系的AA二倍体提供[27, 31]。然而,香蕉驯化期间的杂交事件远比预期的要频繁,导致对香芽蕉的贡献超过三个。据报道,香芽蕉具有小果野蕉亚种banksii、zebrina和malaccensis的混合镶嵌剖面,以及M. schizocarpa和两个未知贡献者[16]。对于巴西蕉,任何两个单倍体组装之间存在低水平的序列共线性,与香芽蕉的复杂种内或种间杂交起源一致。此外,染色体重排、扩张/收缩的基因家族以及同源基因的表达模式在三个单倍体组装中也显示了差异,进一步支持了三倍体香蕉杂交化的复杂故事。
在这项研究中,我们检测到与可能影响巴西蕉果实品质的多个过程相关的基因家族扩张,如蔗糖/二糖/寡糖分解过程、蔗糖代谢过程、淀粉代谢过程和芳香化合物生物合成过程。可溶性糖(例如蔗糖、葡萄糖和果糖)对果实风味和口感有重要影响。可溶性糖还为与果实品质相关的其他化合物的合成提供了前体,如氨基酸、有机酸和抗氧化微量营养素。一般来说,由于持续的选择和育种努力,许多现代水果的糖含量发生了很大变化[32, 33]。香蕉在收获后早期阶段的糖含量相当低。在果实发育过程中,香蕉积累了大量的淀粉储备(占其鲜重的15-35%)。然而,由于淀粉的复杂代谢从合成转变为分解,淀粉含量在后熟期急剧下降,可溶性糖积累[34]。淀粉向糖的转变似乎对果肉的甜化负有责任,也为决定熟香蕉其他品质特征的代谢过程提供能量;例如,挥发性化合物的合成、果皮颜色变化,甚至果肉软化,从而在最终果实品质中发挥重要作用[35]。此外,芳香化合物对果实品质至关重要,因为香气是果实风味的主要指标。香蕉果实具有令人愉悦的风味。典型的风味化合物在香蕉成熟期间合成,形成香蕉果实的独特香气特征[36]。许多香蕉品种的芳香剖面已被广泛揭示,表明典型的香蕉香气是复杂的挥发性化合物混合物的结果[37-39]。在这种意义上,巴西蕉基因组中与碳水化合物代谢和芳香化合物生物合成相关的扩张生物过程可能是其野生祖先在驯化过程中形成的不同特征,并在其果实品质中发挥重要作用。我们还观察到与花药和花粉发育相关的基因家族在巴西蕉基因组中的扩张。巴西蕉品种是三倍体和孤雌生殖的,因此产生无籽的果实,而小果野蕉的果实含有大量种子,使其不可食[40]。相对地,根据我们的观察,巴西蕉具有薄花药而无花粉,但小果野蕉具有较大尺寸的花药并充满花粉。因此,巴西蕉基因组中这些扩张的基因家族可能对栽培的巴西蕉与其野生祖先之间的繁殖差异负责。花药壁绒毡层是提供营养以支持花粉粒成熟的一层细胞[41, 42]。这里扩张的基因家族在与花药壁绒毡层相关的几个生物过程中被富集,预期在巴西蕉的孤雌生殖特性中发挥关键作用。巴西蕉基因组中一些收缩的基因家族涉及与对外部生物和非生物因素的响应相关的生物过程。积累的证据表明,与其野生祖先相比,香蕉品种通常对病原体和环境压力的抗性降低[43, 44]。这些收缩的基因家族将为进一步调查香蕉品种中减少的抗性的遗传基础提供候选者。
在这项研究中,我们还研究了巴西蕉中的同源基因表达模式。平均而言,约40%的同源基因三联体呈现非平衡的表达模式,其中单个同源基因相对于其他两个显示更高(同源基因占优)或更低的表达(同源基因受抑),与其他作物如甘蓝型油菜(36.5%)和面包小麦(约30%)的发现类似[45, 46]。尽管具有同源基因表达偏倚的基因在任何生物过程中都没有显著富集,但它们的分布并非随机,倾向于位于染色体末端的区域,这些区域在被子植物中的重组率高于更靠近中心的序列[47]。此外,我们发现非平衡三联体的Ka/Ks值略高于平衡三联体,表明具有同源基因表达偏倚的基因可能处于更松弛的选择压力下,具有略微更高的进化速率。
疾病抵抗力和香蕉育种
植物病原体继续对香蕉产量构成重大挑战。近几十年来,香蕉生产严重受到土传真菌Foc的影响,Foc是香蕉枯萎病的致病因子。该病原体可以通过植物材料、水和土壤传播。尽管人类社会为控制香蕉枯萎病做出了许多努力,但这些控制措施对于在Foc感染的土壤中可持续生产易感品种并不足够有效。在过去的几十年中,香芽蕉种植园受到了Fusarium的新菌株热带4号(Foc-TR4)的威胁。识别赋予Foc抗性的染色体区域将有助于香蕉育种计划中的分子辅助选择。R基因编码可以检测病原体的蛋白质,因此在作物的显著免疫反应中发挥关键作用。在这里,我们发现巴西蕉中识别的抗性基因远少于野生香蕉小果野蕉。最近,Chen等人已经鉴定了一个控制对Foc的亚热带4号(STR4,影响亚热带的香芽蕉)抗性的主要数量性状位点(QTL)。这个QTL位于染色体3长臂远端,对应于MAv4基因组中发现的两个NLR基因簇。有趣的是,我们发现在巴西蕉基因组中的相关基因簇里,几乎所有NLR位点都位于基因间区域,表明它们可能已经拟基因化。鉴于这个控制STR4抗性的QTL,这些基因簇中NLR基因数量大大减少可能是巴西蕉易感Foc的原因。这一发现进一步证实了染色体3长臂远端是在香蕉中介导Foc抗性的重要区域。染色体10中的基因簇里也鉴定了拟基因化的NLR位点,表明这些基因组区域也可能参与病原体抵抗。有趣的是,三个单倍体组装中表达的NLR位点模式不同。例如,染色体3中的一个基因簇里的几乎所有NLR位点在BXJ3中保持功能,而同一染色体中的其他基因簇里的NLR位点在BXJ1和BXJ2中几乎都已拟基因化;此外,染色体10中的基因簇里的NLR位点在BXJ2中完全拟基因化,但在其他两个单倍体组装中大部分位点保持功能。这些发现进一步支持了巴西蕉亚基因组具有不同的起源,并暗示它们可能对疾病抵抗力有不同的贡献。因此,表达的NLR位点的不同模式将为未来准确的香蕉育种计划提供可靠的参考。总之,染色体3和10中的R基因簇可能是执行香蕉抗性分子分析的潜在目标,这将需要进一步的研究。
总结来说,我们提出了香芽蕉巴西蕉的高质量T2T和单倍型解析参考基因组。三个单倍体组装之间的低核苷酸序列共线性和差异紧密反映了这个品种复杂的驯化历史。发现一些与巴西蕉特定基因家族有关的生物过程被富集,这与果实品质、孤雌生殖和不育性有关。此外,与小果野蕉基因组相比,在巴西蕉基因组中发现的R基因数量大大减少,这揭示了这个品种可能对香蕉枯萎病易感的机制。这个基因组装配将为理解驯化、分子育种和香蕉的遗传改良提供宝贵的参考。
材料和方法
植物材料、DNA提取和测序
巴西蕉植物材料(‘巴西蕉’)采集自中国科学院华南植物园。包括新鲜根、叶、花和果实在内的组织样品被收集,然后立即在液氮中冷冻,并保存在−80°C下以备进一步进行DNA/RNA提取。采用CTAB方法从叶片样品中提取高质量的基因组DNA。使用Qubit荧光计(Thermo Fisher Scientific)评估提取的DNA的浓度和纯度。通过凝胶电泳检查DNA的完整性。
对于PacBio HiFi测序,使用SMRTbell Express Template Prep Kit 2.0按照制造商的建议构建了标准的SMRTbell文库(Pacific Biosciences,CA,美国)。然后在PacBio Sequel II系统上对文库进行了测序。使用Oxford Nanopore SQK-LSK109套件根据制造商的说明准备了ONT文库,然后在Nanopore PromethION平台上进行了测序。对于Hi-C测序,将基因组DNA与甲醛交联并提取以进行Hi-C文库制备。然后在Illumina NovaSeq平台(Illumina,CA,美国)上对文库进行了成对末端测序。对于Illumina测序,使用Illumina NovaSeq平台生成了成对的150-bp读数。对于RNA测序,使用NEBNext® Ultra™ II Directional RNA Library Prep Kit for Illumina®(New England Biolabs,MA,美国)从所有组织样品中分离出总RNA。同样在Illumina NovaSeq平台上生成了成对的150-bp读数。所有测序工作均由安徽双螺旋基因科技有限公司(中国安徽)完成。
单倍型分辨率参考基因组组装和填补缺失
通过CCS软件(https://github.com/PacificBiosciences/ccs)生成一致性读取(HiFi读取),使用默认参数。通过fastp版本0.23.2 [50]过滤Hi-C读取。首先使用高度准确的HiFi读取估计基因组大小和杂合率,根据jellyfish [51]产生的K-mer计数,使用GenomeScope版本2.0 [18]。随后,使用HiFi读取和Hi-C读取进行新组装,使用hifiasm v0.16.1 [19]生成‘巴西蕉’的初步contig基因组,其中包括两个主要单倍型:一个具有较小基因组大小的第一个主要单倍型组装和一个包含两个单倍型基因组未相位化contigs的较大组装。然后使用Hi-C数据锚定并删除主要基因组的一些短contig。简要地说,首先使用ragtag v2.1.0 [52]根据T2T版本的小果野蕉 ssp. malaccensis基因组(刘等人未发表的结果)的指导,对第一个单倍型contigs进行排序、定向和聚类。同时,使用Juicer v1.6 [53]和3D-DNA v180922 [54]依次将contigs锚定到11个伪染色体上。此外,引入JuiceBox v2.20.00 [21]以可视化Hi-C数据和手动修改,以获得包含11个伪染色体的第一个单倍型组装。然后,将相同的工作流程结合ragtag、Juicer、3D-DNA和JuiceBox应用于包含未相位化contigs的另一个主要单倍型,并使用冗余的Hi-C信号将第二个和第三个单倍型组装分离开来。然后使用JuiceBox中的agp2assembly.py和01_2assemblyto2.py工具将来自三个单倍型组装的contigs分组并以顺序方式排列。同时,通过检查最终的结果,将包含来自所有三个单倍型组装的contigs和组装的文件引入JuiceBox,根据Hi-C信号手动调整一些属于第三个单倍型组装的多余contigs。最后,我们基于我们的高覆盖Hi-C数据和高准确度的HiFi读取生成了33个伪染色体。对于填补缺口,首先使用ONT超长读取通过NextDenovo(https://github.com/Nextomics/NextDenovo)进行新组装,并使用默认参数使用Nextpolish [55]根据HiFi读取和Illumina读取进行修饰。然后使用minimap2 v2.24-r1122 [56]将ONT修饰的contigs映射到主要基因组。因为主要基因组中仅有144个缺口,我们使用Integrative Genomics Viewer(IGV)[57]工具检查断点位置,并根据比对填补缺口。填补缺口后,生成了一个几乎完整的、有相位的参考基因组,命名为BXJ。图S2(请参见在线补充材料)展示了‘巴西蕉’基因组组装方案。使用TIDK v0.2.1(https://github.com/tolkit/telomeric-identifier)识别端粒区域。基于Tandem Repeats Finder v4.09 [20]的结果使用默认参数和TE库识别着丝粒区域。
组装验证和质量评估
使用HiFi和Illumina读取来评估BXJ的准确性。将HiFi读取通过minimap2映射到组装结果中,而Illumina读取则使用BWA v0.7.17-r1188 [58]进行比对。使用BamTools v2.5.1 [59]计算比对率。利用LTR_retriever v2.9.0 [60]计算的LTR组装指数(LAI)用于评估基因组组装质量。使用BUSCO v5.4.3 [22]评估单倍型解析的基因组组装的完整性,使用‘embryophyta_odb 10’数据库。
全基因组比对和同源分析
使用默认参数的nucmer v4.0.0rc1 [61]确定单倍型组装之间的同源关系。然后使用参数‘-i 90 -l 15000’启动Delta-filter。使用LINKVIEW v1.1 (https://github.com/YangJianshun/LINKVIEW)可视化染色体水平上的同源关系。为了进一步检查大的倒位区域,我们使用IGV和JuiceBox根据Tang等人[62]和Zhou等人[63]的验证方法检查倒位的断点区域(图S8–S9,请参见在线补充材料)。MCscan [23]管道用于在BXJ单倍型组装之间查找结构变异。简而言之,使用参数‘—cscore = 0.99’的‘jcvi.compara.catalog’模块找到正交物;然后,使用‘—minspan = 30’的‘jcvi.compara.synteny’模块建立同源区域;最后,执行‘jcvi.graphics.karyotype’模块可视化同源关系。
基因组重复和基因注释
使用默认参数的RepeatModeler v2.0.1 [64]识别TEs库。使用RepeatMasker v4.1.1 (http://repeatmasker.org/)根据共识TEs库识别重复。然后将重复屏蔽的基因组导入MAKER3 v3.01.03 [65]进行基因注释。所有高置信度的Swiss-prot蛋白序列通过参数protein2genome = 1通过Protein2Genome进行同源预测。使用参数est2genome = 1的Est2Genome使用四种组织的转录本,然后使用AUGUSTUSv3.3.2构建了ab initio预测模型。AUGUSTUS模型基于分为测试和评估的两个数据集进行测试,结果表明我们的模型相当可靠。最后,再次运行MAKER3管道以获得结合了同源预测、转录本证据预测和de novo预测的高质量基因注释。使用blast结果从以下数据库进行功能注释:Pfam、UniProt、GO、KEGG、InterPro、dbCAN、EggNOG和MEROPS。
基因家族的扩张和收缩
使用Orthofinder v2.5.4 [66]比较其蛋白编码基因序列,对‘巴西蕉’和单子叶植物中的其他15种物种的基因家族进行了表征。严格存在于所有上述物种中的单拷贝正交物序列然后使用mafft v7.310 [67]进行比对。随后,对连接的序列进行了2000次bootstrap的RAxML v8.2.12 [68]的系统发育分析。构建了系统发育树后,应用MCMCTree [69]来估计分化时间,选择了9对物种作为校准点,其估计的分化时间来自TimeTree网站(表S17,请参见在线补充材料)。进行了两次MCMCTree运行以确保分化时间估计的收敛性。使用CAFE v5.0 [70]识别可能的扩张和收缩的基因家族。对显著扩张和收缩的基因集进行了GO富集分析,使用TBtools v1.108 [71]进行分析。
抗性基因的鉴定
作物物种中对疾病抗性的遗传变异通常受到疾病抗性(R)基因的影响。使用RGAugury v2.2 [25]预测‘巴西蕉’和小果野蕉中的抗性基因模拟物(RGAs)。使用NLR-Annotator [26]进行NLR位点的搜索,这是一个独立于转录本支持的NLR位点的de novo基因组注释工具。潜在的NLR位点可能对应于完整或部分基因,也可能是假基因序列的痕迹。
巴西蕉中同源染色体的表达模式
经过fastp的筛选后,RNA测序读数使用HISAT2 v2.2.1 [72]对解析出的BXJ基因组进行比对。然后使用featureCounts v2.0.4 [73]对RNA测序数据进行计数。为了识别BXJ基因组中的等位基因,我们使用DIAMOND v2.0.15 [74]将‘巴西蕉’单倍型组装和MAv4之间的蛋白序列进行比对,并根据相似性分数获得三种类型的等位基因:相互配对的三个等位基因(1:1:1对应关系)、相互配对的两个等位基因,以及剩下的基因。为了探索同源染色体表达的模式,我们着重于在三个单倍型组装之间具有1:1:1对应关系的基因三联体。在至少一个组织中表达水平>0.5每百万转录本(TPM)的同源染色体被认为是表达的。根据Ramírez-González等人的方法 [46],BXJ1、BXJ2和BXJ3同源染色体的相对表达水平被标准化,基于标准化的绝对TPM和每个同源染色体的相对表达水平,表达BXJ1=TPM(BXJ1)/(TPM(BXJ1)+ TPM(BXJ2)+ TPM(BXJ3)),表达BXJ2=TPM(BXJ2)/(TPM(BXJ1)+ TPM(BXJ2)+ TPM(BXJ3)),以及表达BXJ3=TPM(BXJ3)/(TPM(BXJ1)+ TPM(BXJ2)+ TPM(BXJ3))。每个基因三联体的同源染色体的相对表达水平被引入到使用R软件包ggtern [75]绘制的三角图中。根据这些图表,我们描述了七种同源染色体表达偏向性的组别:一个平衡组,三个同源染色体具有相似的相对表达水平,以及六个同源染色体主导或抑制的组别,根据相对于其他两个同源染色体的相对表达水平更高或更低来定义(表S18,请参见在线补充材料)。使用KAKS计算器 v2.0 [76]计算不同表达偏向性类别的Ka/Ks值。对于同源染色体主导或抑制的基因,使用TBtools进行GO富集分析。
![[图像处理] MFC载入图片并绘制ROI矩形](https://img-blog.csdnimg.cn/direct/c7c34f185b1642e8a1cb3b56e1113893.png)