文章目录
- structure
- .p文件
- `pd.read_excel`
- enumerate
- 思维导图
- 核心源码讲解
- jiedi.py
- train.py
- 总结
structure
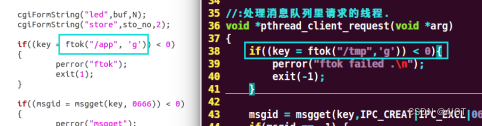
点击左边的Structure按钮就如Structure界面。从Structure我们可以看出当前代码文件中有多少个全局变量、函数、类以及类中有多少个成员变量和成员函数。
其中V图标表示全局变量,粉红色的f图标表示普通函数,左上角带红色小三角的f图标表示内嵌函数,C图标表示类,类中m图标表示成员函数,f图标表示成员变量。点击图片可以跳转到对应的代码。
.p文件
以 .p 为后缀名的文件类型通常代表 Python 中使用 pickle 模块序列化后的二进制数据文件。
具体来说:
-
pickle是 Python 标准库中用于对象序列化和反序列化的模块。它可以将 Python 对象转换成字节流,并将其保存到文件中。 -
通常情况下,使用
pickle.dump()函数将 Python 对象保存到以.p为后缀名的文件中。这样可以方便地将复杂的 Python 对象持久化存储,并在需要时使用pickle.load()函数从文件中读取和还原对象。 -
除了
.p后缀,有时也会看到以.pkl或.pickle为后缀的文件,它们都代表 pickle 格式的二进制数据文件。
pd.read_excel
pd.read_excel 是 Pandas 库中读取 Excel 文件的函数。它可以读取 .xls 和 .xlsx 格式的 Excel 文件,并将其转换为 Pandas 的 DataFrame 对象。
这个函数的主要参数有:
-
file: 要读取的 Excel 文件的路径或文件名。可以是本地文件路径,也可以是网络 URL。 -
sheet_name: 指定要读取的工作表名称或工作表索引。默认读取第一个工作表。 -
header: 指定数据的列名行号,默认为 0 表示第一行为列名。 -
index_col: 指定用哪一列作为行索引。 -
usecols: 指定要读取的列,可以是列名列表或列索引列表。 -
dtype: 指定各列的数据类型。 -
na_values: 指定哪些值被视为缺失值。
使用示例:
import pandas as pd
# 读取 Excel 文件的第一个工作表
df = pd.read_excel('data.xlsx')
# 读取 Excel 文件的第二个工作表
df = pd.read_excel('data.xlsx', sheet_name=1)
# 读取 Excel 文件的指定工作表,并指定列名行号和索引列
df = pd.read_excel('data.xlsx', sheet_name='Sheet1', header=1, index_col=0)
总之,pd.read_excel 函数提供了灵活的方式读取 Excel 文件,并将其转换为 Pandas DataFrame 对象,方便后续的数据处理和分析。
enumerate
enumerate() 函数是 Python 内置的一个函数,它可以将一个可迭代对象(如列表、字符串等)转换为一个枚举对象。
枚举对象中的每个元素都是一个元组,包含了该元素的索引和值。
思维导图
阅读源码仓库链接
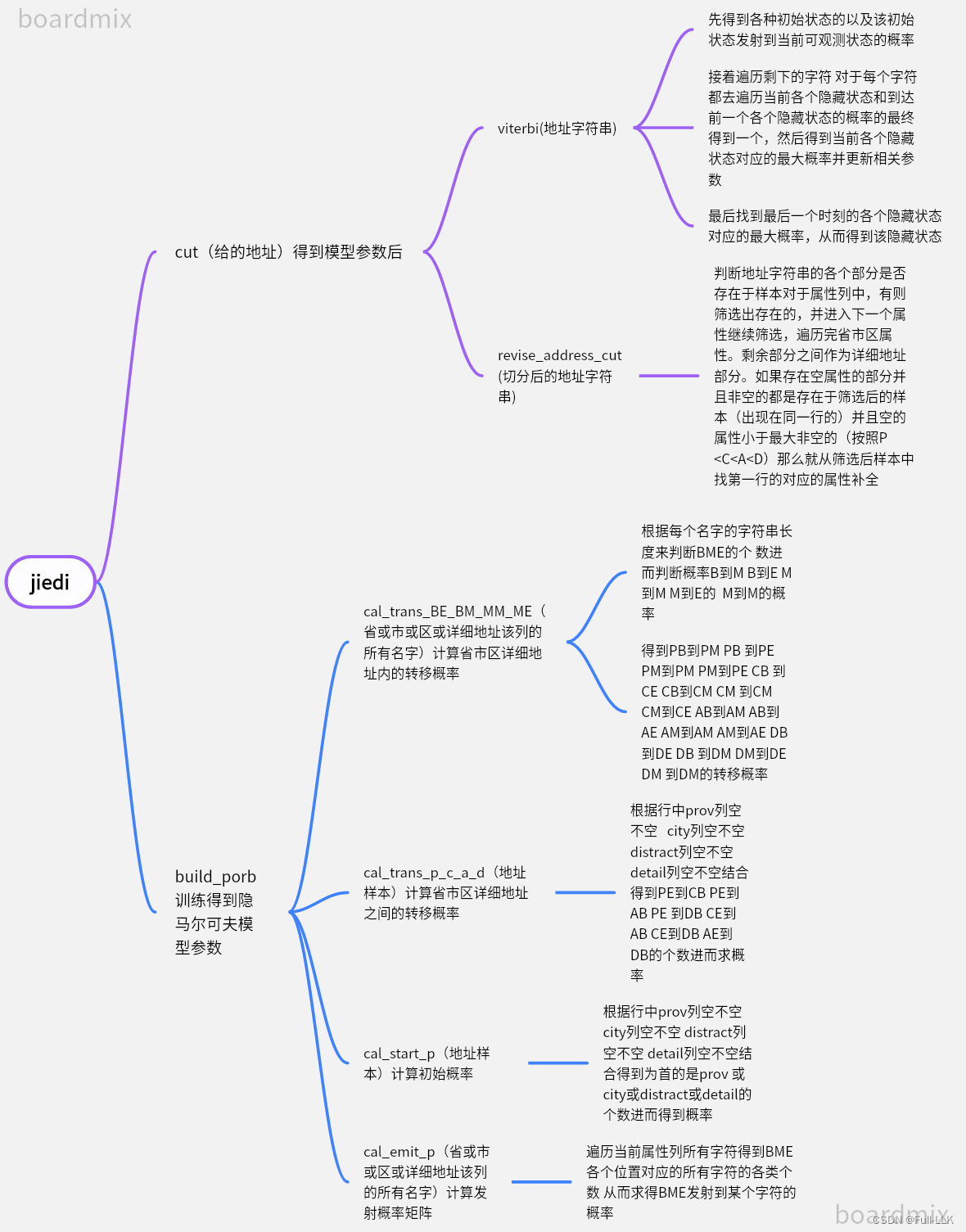
核心源码讲解
jiedi.py
"""
根据隐马尔科夫模型,进行切分地址
其中隐层状态定义为:
'pB': # 省份的开始字
'pM': # 省份的中间字
'pE': # 省份的结尾字
'cB': # 市的开始字
'cM': # 市的中间字
'cE': # 市的结尾字
'aB': # 区的开始字
'aM': # 区的中间字
'aE': # 区的结尾字
'dB': # 详细地址的开始字
'dM': # 详细地址的中间字
'dE': # 详细地址的结尾字
"""
from common import load_cache, MIN_FLOAT # 导入了common.py中的load_cache函数和MIN_FLOAT变量
import config # 导入了config.py
import os
import pandas as pd
import numpy as np
import datetime
# 分词器
class Tokenizer(object):
def __init__(self):
try:
self.start_p = load_cache(os.path.join(config.get_data_path(), 'start_p.p'))
self.trans_p = load_cache(os.path.join(config.get_data_path(), 'trans_p.p'))
self.emit_p = load_cache(os.path.join(config.get_data_path(), 'emit_p.p'))
self.mini_d_emit_p = self.get_mini_emit_p('d')
standard_address_library = pd.read_excel(os.path.join(config.get_data_path(), 'adress_area.xlsx'))
self.standard_address_library = standard_address_library.fillna('') # 用于将 DataFrame 中的所有缺失值(NaN)替换为空字符串 ''
self.time = datetime.datetime.now()
self.time_takes = {} # 空的字典(dictionary)
except Exception:
raise # 直接将异常再次抛出
# 维特比算法求大概率路径
def viterbi(self, address):
length = len(address)
V = [] # 存储中间结果
path = {} # 存储最优路径
temp_pro = {} # 字典将用于存储中间计算的概率值
for hidden_state, prop in self.start_p.items(): # 所有键值对 隐藏状态的初始概率分布
temp_pro[hidden_state] = self.start_p[hidden_state] + self.get_emit_p(hidden_state,
address[0]) # 各个初始状态对应的此时
path[hidden_state] = [hidden_state] # 各个初始状态状态此时对应的隐藏
V.append(temp_pro) # 将各个初始状态对应的初始状态概率和发射概率和的字典加入V
for i_c, character in enumerate(address[1:]): # 从地址字符串的第二个字符开始遍历。
temp_pro = {}
new_path = {}
for hidden_state, _ in self.start_p.items(): # 尝试各个隐藏状态并保存各个隐藏状态对应的最大概率
pre_hidden_state_pro = {pre_hidden_state: (pre_pro
+ self.get_trans_p(pre_hidden_state, hidden_state)
+ self.get_emit_p(hidden_state, character))
for pre_hidden_state, pre_pro in V[i_c].items()}
# 字典 键为前一个各种隐藏状态 值为前一个隐藏状态的概率+前一个隐藏状态的概率到当前隐藏状态的概率+当前隐藏状态的概率到观测状态的概率
max_pre_hidden_state, max_pro = max(pre_hidden_state_pro.items(), key=lambda x: x[1])
# 比较的依据是每个键值对中的值(x[1])
temp_pro[hidden_state] = max_pro # 当前的某个隐藏状态的最大可能概率
new_path[hidden_state] = path[max_pre_hidden_state] + [hidden_state] # 更新各个隐藏状态对应的最大路径
# path 字典中 max_pre_hidden_state 对应的路径, 加上当前的 hidden_state, 作为新的路径存储到 new_path 字典中
V.append(temp_pro) # 加入各个隐藏状态和其最大概率的列表
path = new_path # 替换
# 解析最大概率路径, 只从可能的最后一个字符状态进行解析
(prob, state) = max((V[length - 1][y], y) for y, _ in self.start_p.items())
# V的第一个键是时刻,第二个键为各个隐藏状态 就是最后一个时刻的各个隐藏状态对应各个概率的最大值
self.note_time_takes('viterbi_time_takes', self.get_time_stamp())
return prob, path[state]
# prob对应V[length - 1][y]即最优概率 state 对应y即最优状态下的最后一个时刻对应的隐藏状态,此时对应path为当前这条路径
# 获取隐含状态到可见状态的发射概率
def get_emit_p(self, hidden_state, visible_state):
if 'd' in hidden_state: # 有详细地址部分
# 对省、市、县等关键字进行过滤,防止出现在详细地址中
if '省' in visible_state or '市' in visible_state or '县' in visible_state:
return self.emit_p.get(hidden_state, {}).get(visible_state, MIN_FLOAT)
# 详细地址部分出现省、市、县的概率极小,如果确实存在发射概率就返回,不存在就返回一个很小的值
else:
return self.emit_p.get(hidden_state, {}).get(visible_state, self.mini_d_emit_p)
# 正常详细地址部分不出现省、市、县的情况,此时如果没有找到出现的就以隐藏状态的最小发射概率为准
# 无详细地址部分
else:
return self.emit_p.get(hidden_state, {}).get(visible_state, MIN_FLOAT)
# 正常返回,没有就返回一个很小的值
pass
# 获取详细地址最小的发射概率
def get_mini_emit_p(self, h_state_feature):
mini_p = -MIN_FLOAT # 大值
for h_state, v_states_pro in self.emit_p.items():
if h_state_feature in h_state: # 隐藏状态存在d
for v_state, pro in v_states_pro.items(): # 该隐藏状态对应的观测状态和发射概率
mini_p = min(mini_p, pro) # 找一个更小的
return mini_p # 即所有隐藏状态转换到所有观测状态中最小的概率
# 获取前一隐含状态到下一隐含状态的转移概率
def get_trans_p(self, pre_h_state, h_state):
return self.trans_p.get(pre_h_state, {}).get(h_state, MIN_FLOAT)
# 修正市区详细地址
def revise_address_cut(self, pro, city, area, detailed):
# 1、修正省市区地址
list_addr = [pro, city, area, detailed] # 将各个字符合并成一个列表
col_name = ['pro', 'city', 'area'] # 定义三个列名
revise_addr_list = ['', '', '', ''] # 修正后的地址信息
i = 0
k = 0
filter_df = self.standard_address_library
while i < len(col_name) and k < len(col_name):
# 三列都判断过一遍后或者已经判好(判好表示存在或者为空)到第四列出去(K)
add = list_addr[k] # 得到的可观测序列的列表
if add == '': # 只观测前三个 k < len(col_name)
k += 1 # 前三个出现空的时候k+1,表示这个已经存在并判断完了,不然会判断到详细地址去
continue
while i < len(col_name):
# 避免重复判断字符串是否被包含,优化匹配效率
area_set = set(filter_df[col_name[i]].values)
# 用于获取 DataFrame 中某一列的唯一值集合 当前列(省、市或区)在标准地址库中的所有唯一值
match_area_set = {a for a in area_set if add in a}
# 当前可观测状态出现在列中的所有值的集合
# 遍历 area_set 中的每个元素 a(也就是每个区域),并且只有当 add 这个变量存在于 a 中时,才会将 a 包含在新的集合中
filter_temp = filter_df.loc[filter_df[col_name[i]].isin(match_area_set), :]
# 检查 filter_df[col_name[i]] 中的每个值是否存在于 match_area_set 集合中
# 用这个布尔型 Series 作为行索引,选择满足条件的行,并返回一个新的 DataFrame filter_temp。
if len(filter_temp) > 0:
revise_addr_list[i] = add # 存在就保持不变
filter_df = filter_temp # 过滤后的赋值data
i += 1 # 下一个
k += 1 #
break
else: # 不存在 就看下一个属性(省市区)
i += 1 # k没有+1说明不存在一个属性
continue
# 将剩余的值全作为详细地址
revise_addr_list[3] = ''.join(list_addr[k:len(list_addr)])
# 不存在的属性部分当作详细地址
self.note_time_takes('revise_address_0_time_takes', self.get_time_stamp())
# 2、补全省市区地址
effective_index_arr = np.where([s != '' for s in revise_addr_list[0:3]])[0]
# np.where(数组)数组如果是多维的,返回值也是多维数组,所以用到了[0],这里一维字符串数组返回值也只有一个数组
# 返回所有大于5的数组元素的索引所构成数组
max_effective_index = 0
if len(effective_index_arr) > 0:
max_effective_index = effective_index_arr[-1]
# 最后一个不为空的索引值
if len(filter_df) > 0: # 非空的都是存在于样本中的
for index, addr in enumerate(revise_addr_list):
if addr == '' and index < max_effective_index: # 空的在不空以下
revise_addr_list[index] = filter_df.iloc[0, :][col_name[index]]
# [0]: 这表示访问第 0 行(也就是第一行)的数据。在 Pandas 中,行索引从 0 开始。
# [:]: 这表示访问该行的所有列。冒号 : 表示选择该行的所有列。
# 补全为剩余的filter_df第零行的对应属性列的值
self.note_time_takes('revise_address_1_time_takes', self.get_time_stamp())
return revise_addr_list[0], revise_addr_list[1], revise_addr_list[2], revise_addr_list[3]
# 初始化耗时初始时刻和耗时记录
def time_init(self):
self.time = datetime.datetime.now()
self.time_takes = {}
# 计算初始时刻至今的耗时
def get_time_stamp(self):
time_temp = datetime.datetime.now()
time_stamp = (time_temp - self.time).microseconds / 1000000
self.time = time_temp
return time_stamp
# 记录各个时间段名称和耗时时间字典
def note_time_takes(self, key, time_takes):
self.time_takes[key] = time_takes
dt = Tokenizer()
# 对输入的地址进行切分
def cut(address):
# 带切分地址必须大于一个字符
if address is None or len(address) < 2:
return '', '', '', '', 0, [], {}
# address 是 None,或者它是一个空字符串或只包含一个字
dt.time_init()
p, max_path = dt.viterbi(address) # max_path是一个隐藏状态字符串
pro = ''
city = ''
area = ''
detailed = ''
for i_s, state in enumerate(max_path): # 相当于遍历隐藏状态字符串
# enumerate() 函数用于将一个可迭代对象(如列表、字符串等)转换为一个枚举对象(enumerate object)
character = address[i_s] # 可观测序列与隐藏状态序列相同下标下一一对比
if 'p' in state:
pro += character
elif 'c' in state:
city += character
elif 'a' in state:
area += character
else:
detailed += character # 当前对应的隐藏状态是啥就往对应分布的地方加上当前隐藏状态对应的可观测状态的字符
# 通过字典修正输出
r_pro, r_city, r_area, r_detailed = dt.revise_address_cut(pro, city, area, detailed)
return r_pro, r_city, r_area, r_detailed, p, max_path, dt.time_takes
if __name__ == '__main__':
# 读取execel批量测试
# 读取一些切分地址后的样本
address_sample = pd.read_excel(r'.\data\df_test.xlsx')
address_sample['pro_hmm'] = ' '
address_sample['city_hmm'] = ' '
address_sample['area_hmm'] = ' '
address_sample['detailed_hmm'] = ' '
address_sample['route_state_hmm'] = ' '
# 创建了一个新的列 'pro_hmm' city_hmm area_hmm detailed_hmm route_state_hmm新列的初始值被设置为空格 ' '
s_time = datetime.datetime.now()
time_takes_total = {}
for index, row in address_sample.iterrows():
# .iterrows(): 这是 DataFrame 对象的一个方法,它返回一个迭代器,可以用于遍历 DataFrame 中的每一行
# index 变量表示当前行的索引值,row 变量是一个 Pandas Series 对象,包含了该行的所有数据
addr = row['address_'].strip().strip('\ufeff')
# 'address_' 是这行数据中对应的地址列的列名
# strip() 方法用于删除字符串两端的空白字符,包括空格、制表符、换行符等
# \ufeff 是一个特殊的Unicode字符,称为"字节顺序标记"(Byte Order Mark, BOM)。
# 有时候,从某些数据源导入的字符串数据可能会包含这个字符,需要将其删除。
pro, city, area, detailed, *route_state, time_takes = cut(addr)
# 切分
address_sample.loc[index, 'pro_hmm'] = pro
address_sample.loc[index, 'city_hmm'] = city
address_sample.loc[index, 'area_hmm'] = area
address_sample.loc[index, 'detailed_hmm'] = detailed
address_sample.loc[index, 'route_state_hmm'] = str(route_state) # 隐藏路径
# 将index行的各个cut后对应的值的列填值
time_takes_total = {key: (time_takes_total.get(key, 0) + value) for key, value in time_takes.items()}
# 如果 key 存在于字典 time_takes_total 中,则返回该 key 对应的值。
# 如果 key 不存在于字典中,则返回默认值 0。
# 每个事件段的所花的时间
e_time = datetime.datetime.now()
times_total = (e_time - s_time).seconds
print('总共{}条数据,共耗时:{}秒,平均每条{}秒。'.format(index + 1, times_total, times_total / (index + 1)))
print({key: value for key, value in time_takes_total.items()})
# 每条数据各个步骤的时间
address_sample.to_excel(r'.\data\df_test_hmm.xlsx')
# 结果转换为xlsx形式存储到表中
# adr = '青岛路6号 一楼厂房'
# pro, city, area, detailed, *_ = cut(adr)
# print(pro)
# print(city)
# print(area)
# print(detailed)
train.py
"""
根据语料库,训练初始状体概率、状态转移概率、发射概率
"""
import pandas as pd
import numpy as np
from common import cal_log, save_cache
import os
import config
# # 定义状态的前置状态
# PrevStatus = {
# 'pB': [], # 省份的开始字
# 'pM': ['pB'], # 省份的中间字
# 'pE': ['pB', 'pM'], # 省份的结尾字
# 'cB': ['pE'], # 市的开始字
# 'cM': ['cB'], # 市的中间字
# 'cE': ['cB', 'cM'], # 市的结尾字
# 'aB': ['cE'], # 区的开始字
# 'aM': ['aB'], # 区的中间字
# 'aE': ['aB', 'aM'], # 区的结尾字
# 'dB': ['aE'], # 详细地址的开始字
# 'dM': ['dB'], # 详细地址的中间字
# 'dE': ['dB', 'dM'], # 详细地址的结尾字
# }
# 生成隐马尔科夫模型的训练概率
def build_porb():
start_p, trans_p, emit_p = cal_prob()
save_cache(start_p, os.path.join(config.get_data_path(), 'start_p.p'))
save_cache(trans_p, os.path.join(config.get_data_path(), 'trans_p.p'))
save_cache(emit_p, os.path.join(config.get_data_path(), 'emit_p.p'))
# 计算状态转移概率
def cal_prob():
# 初始化
trans_p = {} # 状态转移概率
emit_p = {} # 发射概率
# 读取省市区的标准名称
address_standard = pd.read_table(r'E:\project\poc\address_cut\data\dict3.txt',
header=None, names=['name', 'num', 'type'], delim_whitespace=True)
#header=None: 这个参数告诉Pandas这个文件没有标题行,所以需要自动生成列名。
#names=['name', 'num', 'type']: 这个参数指定了要使用的列名。在这个例子中,列名分别是"name"、"num"和"type"
# delim_whitespace=True: 这个参数告诉Pandas使用空白字符(空格和/或制表符)作为分隔符来分割各个列。
# 读取一些切分地址后的样本
address_sample = pd.read_excel(r'E:\project\poc\address_cut\data\df.xlsx')
# 1、计算状态转移概率矩阵
trans_p.setdefault('pB', {})['pE'], trans_p.setdefault('pB', {})['pM'], \
trans_p.setdefault('pM', {})['pM'], trans_p.setdefault('pM', {})['pE'] = \
cal_trans_BE_BM_MM_ME(set(address_standard.loc[address_standard['type'] == 'prov', 'name'].values))
# trans_p.setdefault('pB', {})['pE']类似trans_p = {'pB': {'pE': <未指定的值>}}
#从 address_standard DataFrame 中筛选出 'type' 列等于 'prov' 的行,取出 'name' 列的值。
#将这些省份名称去重后,作为参数传递给 cal_trans_BE_BM_MM_ME 函数
trans_p.setdefault('cB', {})['cE'], trans_p.setdefault('cB', {})['cM'], \
trans_p.setdefault('cM', {})['cM'], trans_p.setdefault('cM', {})['cE'] = \
cal_trans_BE_BM_MM_ME(set(address_standard.loc[address_standard['type'] == 'city', 'name'].values))
trans_p.setdefault('aB', {})['aE'], trans_p.setdefault('aB', {})['aM'], \
trans_p.setdefault('aM', {})['aM'], trans_p.setdefault('aM', {})['aE'] = \
cal_trans_BE_BM_MM_ME(set(address_standard.loc[address_standard['type'] == 'dist', 'name'].values))
detailed_address_sample = get_detailed_address(address_sample)
# 详细地址样本库
trans_p.setdefault('dB', {})['dE'], trans_p.setdefault('dB', {})['dM'], \
trans_p.setdefault('dM', {})['dM'], trans_p.setdefault('dM', {})['dE'] = \
cal_trans_BE_BM_MM_ME(set(detailed_address_sample))
# 计算省市区详细地址四者之间的对应的隐藏状态转移矩阵
cal_trans_p_c_a_d(address_sample, trans_p)
# 2、计算初始概率矩阵
start_p = cal_start_p(address_sample) # 初始状态概率
# 3、计算发射概率矩阵
emit_p['pB'], emit_p['pM'], emit_p['pE'] = \
cal_emit_p(set(address_standard.loc[address_standard['type'] == 'prov', 'name'].values))
emit_p['cB'], emit_p['cM'], emit_p['cE'] = \
cal_emit_p(set(address_standard.loc[address_standard['type'] == 'city', 'name'].values))
emit_p['aB'], emit_p['aM'], emit_p['aE'] = \
cal_emit_p(set(address_standard.loc[address_standard['type'] == 'dist', 'name'].values))
emit_p['dB'], emit_p['dM'], emit_p['dE'] = \
cal_emit_p(set(detailed_address_sample))
return start_p, trans_p, emit_p
# 计算发射概率矩阵
def cal_emit_p(str_set): #省或市或区汉字
str_list = list(str_set)
stat_B = {}
stat_M = {}
stat_E = {}
length = len(str_list)
M_length = 0
for str in str_list: # 字符串组
str_len = len(str)
for index, s in enumerate(str):# 字符串
if index == 0:
stat_B[s] = stat_B.get(s, 0) + 1
# get得到字典中s的值,没用就返回0
elif index < str_len - 1:
stat_M[s] = stat_M.get(s, 0) + 1
M_length += 1
# 中间字符个数
else:
stat_E[s] = stat_E.get(s, 0) + 1
# 末尾字符个数
B = {key: cal_log(value / length) for key, value in stat_B.items()}
# 开头出现某个汉字在整个省或市或区汉字汉字字符串组中的比例的对数
M = {key: cal_log(value / M_length) for key, value in stat_M.items()}
# 中间出现某个汉字在整个省或市或区汉字汉字字符串组中的比例的对数
E = {key: cal_log(value / length) for key, value in stat_E.items()}
# 末尾出现某个汉字在整个省或市或区汉字汉字字符串组中的比例的对数
#cal_log 是指某个对数函数
return B, M, E
# 根据地址样本,省市区详细地址之间的转移矩阵
def cal_trans_p_c_a_d(address_df, t_p):
df_prov = address_df[address_df['prov'].isnull().values == False]
# prov列不为空的行
df_prov_no_city = df_prov[df_prov['city'].isnull().values == True]
# prov列不为空的并且city列为空的行
df_prov_no_city_no_area = df_prov_no_city[df_prov_no_city['dist'].isnull().values == True]
# prov列不为空的并且city列为空并且dist列为空的行
t_p.setdefault('pE', {})['cB'] = cal_log(1 - len(df_prov_no_city) / len(df_prov))
# 对于1-省后面不是城市开始的概率
# 省后面是城市开始
t_p.setdefault('pE', {})['aB'] = cal_log((len(df_prov_no_city) - len(df_prov_no_city_no_area)) / len(df_prov))
# 省后面直接是地区开始 对于身后面不是城市的概率减去省后面既不是城市也不是地区的概率即省后面是地区的概率
t_p.setdefault('pE', {})['dB'] = cal_log(len(df_prov_no_city_no_area) / len(df_prov))
# 省后面直接是详细地址开始 省后面既不是城市也不是地区开始的概率即省后面是详细地址开始的概率
df_city = address_df[address_df['city'].isnull().values == False]
# 城市列不为空的行
df_city_no_area = df_city[df_city['dist'].isnull().values == True]
# 城市列不为空且地区列为空的行
t_p.setdefault('cE', {})['aB'] = cal_log(1 - len(df_city_no_area) / len(df_city))
# 城市后面是是区域开始
t_p.setdefault('cE', {})['dB'] = cal_log(len(df_city_no_area) / len(df_city))
# 城市后面是详细地址开始
t_p.setdefault('aE', {})['dB'] = cal_log(1.0)
# 区域后面是详细地址开始 百分之百有可能是规定吧
# 根据地址样本, 计算初始概率矩阵
def cal_start_p(address_df):
length = len(address_df)
df_prov_nan = address_df[address_df['prov'].isnull().values == True]
# 省列为空的行
length_pB = length - len(df_prov_nan)
# 省列不为空的行 即起始状态为 pb
df_city_nan = df_prov_nan[df_prov_nan['city'].isnull().values == True]
# 省列为空且市列为空的行
length_cB = len(df_prov_nan) - len(df_city_nan)
# 省列为空并且市列不为空的个数 即起始状态为 cb
df_area_nan = df_city_nan[df_city_nan['dist'].isnull().values == True]
# 省列为空且市列为空且地区列为空的行
length_aB = len(df_city_nan) - len(df_area_nan)
# 省列为空并且市列为空但地区列不为空的个数 即起始状态为 ab
length_dB = len(df_area_nan)
# 省列为空且市列为空且地区列为空且详细地址不为空(详细地址列一定不为空规定吧)
s_p = {'pB': cal_log(length_pB / length), # 省份的开始字
'pM': -3.14e+100, # 省份的中间字
'pE': -3.14e+100, # 省份的结尾字
'cB': cal_log(length_cB / length), # 市的开始字
'cM': -3.14e+100, # 市的中间字
'cE': -3.14e+100, # 市的结尾字
'aB': cal_log(length_aB / length), # 区的开始字
'aM': -3.14e+100, # 区的中间字
'aE': -3.14e+100, # 区的结尾字
'dB': cal_log(length_dB / length), # 详细地址的开始字
'dM': -3.14e+100, # 详细地址的中间字
'dE': -3.14e+100, # 详细地址的结尾字
}# -3.14e+100表示不可能 因为起始状态只有可能是 pb cb ab db
return s_p
# 获取样本数据中的详细地址
def get_detailed_address(address_df):
detailed_address = []
for index, row in address_df.iterrows():
tmp = row['address_'].strip().strip('\ufeff')
if row['prov'] is not None and row['prov'] is not np.nan:
tmp = tmp.replace(row['prov'], '', 1)
# prov 列不为空且不为 NaN,则使用 replace() 方法将 tmp 中的省份信息删除
if row['city'] is not None and row['city'] is not np.nan:
tmp = tmp.replace(row['city'], '', 1)
if row['dist'] is not None and row['dist'] is not np.nan:
tmp = tmp.replace(row['dist'], '', 1)
detailed_address.append(tmp)
# 最后只剩详细地址部分了
return detailed_address
# 计算字符串数组中“开始字-->结束字”、“开始字-->中间字”、“中间字-->中间字”和“中间字-->结束字”的转移概率
def cal_trans_BE_BM_MM_ME(str_set): # 根据各个样本的字符长度来判断对应的隐藏状态的个数从而计算概率
str_list = list(str_set)
length = len(str_list)
if length == 0:
raise Exception('输入的集合为空')
str_len_ori = np.array([len(str) for str in str_list])
# 各个字数长度的数组
# 筛选出字数大于1的地名,进行计算
str_len = str_len_ori[np.where(str_len_ori > 1)]
# if sum(str_len < 2):
# raise Exception('含有单个字的省、市、区名称!')
# “开始字-->结束字“的概率
# 两个字就是直接开始字和结束字
p_BE = sum(str_len == 2) / length
# 除了开始字到中间字就是开始字到结束字了
# “开始字-->中间字”的概率
p_BM = 1 - p_BE
# “中间字 -->结束字”的概率
# 字数大于2说明有中间字,并且只存在一个中间字到结束字
# 减2是代表当前存在中间字到中间字和中间字到结束字,如果只有中间字到 结束字那么就只有1,如果是存在一个中间字到中间字那么就是2
p_ME = sum(str_len > 2) / sum(str_len - 2) # ??? 负数 ?????
# “中间字-->中间字”的概率
# 除了中间字到中间字就是中间字到结束字了
p_MM = 1 - p_ME
return cal_log(p_BE), cal_log(p_BM), cal_log(p_MM), cal_log(p_ME)
if __name__ == '__main__':
build_porb()
pass
总结
这段代码实现了一个基于隐马尔可夫模型(HMM)的地址切分器。
-
隐藏状态定义:
'pB'、'pM'、'pE': 分别表示省份的开始字、中间字和结尾字。'cB'、'cM'、'cE': 分别表示市的开始字、中间字和结尾字。'aB'、'aM'、'aE': 分别表示区的开始字、中间字和结尾字。'dB'、'dM'、'dE': 分别表示详细地址的开始字、中间字和结尾字。
-
Tokenizer 类:
- 初始化时加载隐马尔可夫模型的相关概率参数,包括起始概率、转移概率和发射概率。
- 实现
viterbi算法,用于根据输入地址找到最大概率的隐藏状态序列。 - 实现
get_emit_p和get_trans_p函数,分别用于获取发射概率和转移概率。 - 实现
revise_address_cut函数,用于根据标准地址库修正切分后的地址。 - 实现一些用于记录耗时的辅助函数。
-
cut 函数:
- 输入一个地址字符串,返回切分后的省、市、区和详细地址。
- 调用 Tokenizer 类中的
viterbi算法,得到最大概率的隐藏状态序列。 - 根据隐藏状态序列,将地址字符串切分为省、市、区和详细地址。
- 调用
revise_address_cut函数,根据标准地址库修正切分结果。 - 返回切分后的省、市、区和详细地址,以及相关的概率和耗时信息。
-
主函数:
- 读取一个测试地址样本集,对每个地址进行切分。
- 将切分结果保存到测试样本集中,并计算总耗时和平均耗时。
- 最后将修正后的测试样本集保存到 Excel 文件。
总的来说,这个代码实现了一个基于隐马尔可夫模型的地址切分器,能够较准确地将地址切分为省、市、区和详细地址,并提供了相关的概率和耗时信息。