编者按: 自 2023 年以来,RAG 已成为基于 LLM 的人工智能系统中应用最为广泛的架构之一。由于诸多产品的关键功能严重依赖RAG,优化其性能、提高检索效率和准确性迫在眉睫,成为当前 RAG 相关研究的核心问题。
我们今天为大家带来的这篇文章指出,Naive RAG 在编制索引、检索和内容生成这三个核心步骤中都存在诸多问题:a) 编制索引时,信息提取不完整、分块策略简单、索引结构未优化、嵌入模型表示能力较弱;b) 检索时,检索到的信息与用户向系统提出的请求相关性不高、召回率低、对不准确的用户请求无法处理、算法单一、存在上下文信息冗余;c) 内容生成时,上下文整合不佳、过度依赖检索信息、存在生成错误/不当内容的风险。
这篇文章指出了当前 Naive RAG 系统的种种缺陷,为下一步的优化措施和解决方案指明了方向,对提升 RAG 在实际应用中的效率和准确性具有重要意义。
作者 | Florian June
编译 | 岳扬
🚢🚢🚢欢迎小伙伴们加入AI技术软件及技术交流群,追踪前沿热点,共探技术难题~
检索增强生成(Retrieval Augmented Generation,RAG)是通过整合来自外部知识源的额外信息来改进大语言模型(Large Language Models,LLMs)应用能力的一种技术。这种技术能够帮助 LLMs 产生更精确和更能感知上下文的回复,同时也能减轻幻觉现象。
自 2023 年以来,RAG 已成为基于 LLM 的软件系统中最受欢迎的架构。许多产品的功能都严重依赖 RAG 。因此,优化 RAG 的性能,使检索过程更快、结果更准确,已成为一个关键问题。
这一系列文章将重点介绍 RAG 优化技术,帮助读者提升 RAG 生成结果的整体质量。
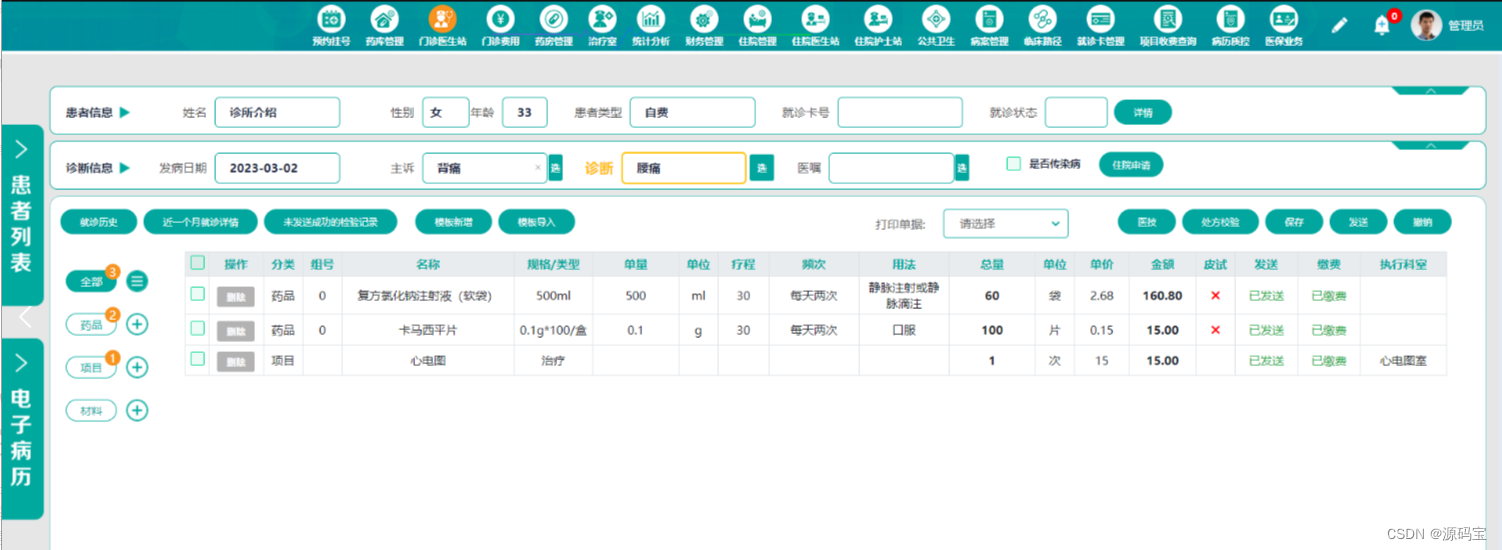
01 简单介绍 Naive(未经过优化的)RAG
如图 1 所示,未经优化的 RAG 工作流程如下:

图 1:未经优化的 RAG 经典工作流程。Image by author。
如图 1 所示,RAG 的经典工作流程主要包括以下三个步骤:
- 编制索引(Indexing) :索引的编制过程是该流程中最先执行的、较为关键的步骤,这个步骤是在离线状态下执行的。首先,对原始数据进行清理和提取,将 PDF、HTML 和 Word 等各种文件格式转换为标准化的纯文本。为了适应语言模型的上下文限制,这些文本被分成更小、更易于管理的块,这一过程被称为分块(chunking)。随后,使用嵌入模型(embedding models)将这些块转换为向量表征(vector representations)。最后,创建一个索引,以键值对的形式存储这些文本块(text chunks)及其向量嵌入(vector embeddings),从而实现高效且可扩展的搜索能力。
- 检索(Retrieval) :user query(译者注:指用户输入到 RAG 系统的问题)被用于从外部知识源(external knowledge sources)中检索相关的上下文。为了实现这一点,user query 需要经过编码模型(encoding model)处理,生成语义相关的嵌入。然后,在向量数据库**上进行相似度搜索(similarity search),以检索出前 k 个最接近的数据对象(data objects)。
- 内容生成(Generation) :user query 和检索到的附加上下文填入一个 prompt 模板中。最后,将来自检索步骤的增强 prompt (译者注:包含用户请求内容和检索上下文的prompt)输入到 LLM 中。
02 使用 Naive RAG 存在的问题
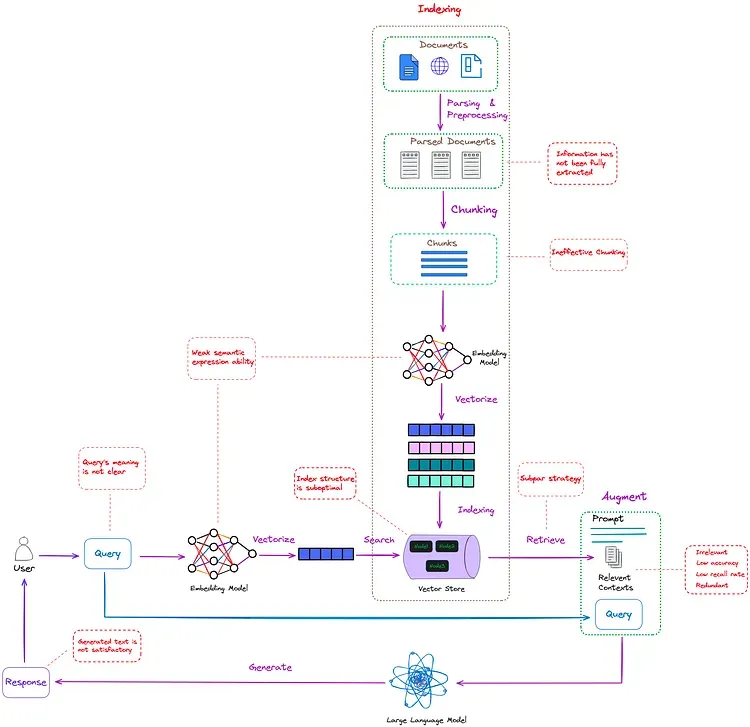
图 2:Naive RAG 存在的问题(用红色虚线框标出)。Image by author。
如图 2 所示,Naive RAG 在上述三个步骤中都存在一些问题(用红色虚线框标出),有很大的优化空间。
2.1 编制索引(Indexing)
- 信息提取过程不完整,因为它不能有效处理 PDF 等非结构化文件中的图像和表格中的有用信息。
- 分块过程(chunking process)采取的是 “一刀切” 策略,而非根据不同文件类型的特点选择最佳策略。这导致每个文本片段都包含不完整的语义信息。此外,它也没有考虑到文本中已存在的重要细节,如文本中已有的标题。
- 索引结构未经充分优化,导致检索功能低效。
- 嵌入模型的语义表示能力较弱。
2.2 检索(Retrieval)
- 从外部知识源检索到的信息与 user query 的相关性不高,并且所检索到的信息的准确率也较低。
- 由于召回率(recall rate)低,无法检索到所有相关段落,从而影响了 LLMs 生成全面答案的能力。
- 用户向系统提出的请求可能不准确,或者嵌入模型的语义表示能力可能较弱,导致无法检索到有价值的信息。
- 检索算法是受限制的,因为它没有结合不同类型的检索方法或算法,如关键词、语义和向量检索(keyword, semantic, and vector retrieval)的组合。
- 当检索到的多个上下文包含相似信息时,会出现信息冗余,导致生成的答案中出现重复内容。
2.3 内容生成(Generation)
- 可能无法将检索到的上下文与当前的生成任务有效整合,从而导致输出结果不一致。
- 在生成过程中过度依赖 enhanced information(译者注:指的是从外部知识源检索到的、与当前生成任务相关联的额外信息)的风险很高。可能导致生成的内容只是重复输出检索到的内容,而没有提供有价值的信息。
- LLM 可能会生成不正确的、不相关的、不当的或有偏见的回复。
需要注意的是,导致这些问题出现的原因可能是多方面的。例如,如果给用户的最终回复包含不相关的内容,这可能不完全是 LLM 的问题。其根本原因可能是从 PDF 中不能精确地提取文档内容,或者嵌入模型无法准确捕捉语义,等等。
03 Conclusion
本文主要介绍 Naive RAG 中存在的问题。
后续文章将提供缓解这些问题的措施和解决方案,帮助改善 RAG 的性能,使其在实际应用中更加有效地帮助大家解决问题。
如果本文有任何错误或遗漏,敬请指出。
Thanks for reading!
——
Florian June
An artificial intelligence researcher, mainly write articles about Large Language Models, data structures and algorithms, and NLP.
END
本文经原作者授权,由 Baihai IDP 编译。如需转载译文,请联系获取授权。
原文链接:
https://ai.plainenglish.io/advanced-rag-part-01-problems-of-naive-rag-7e5f8ebb68d5