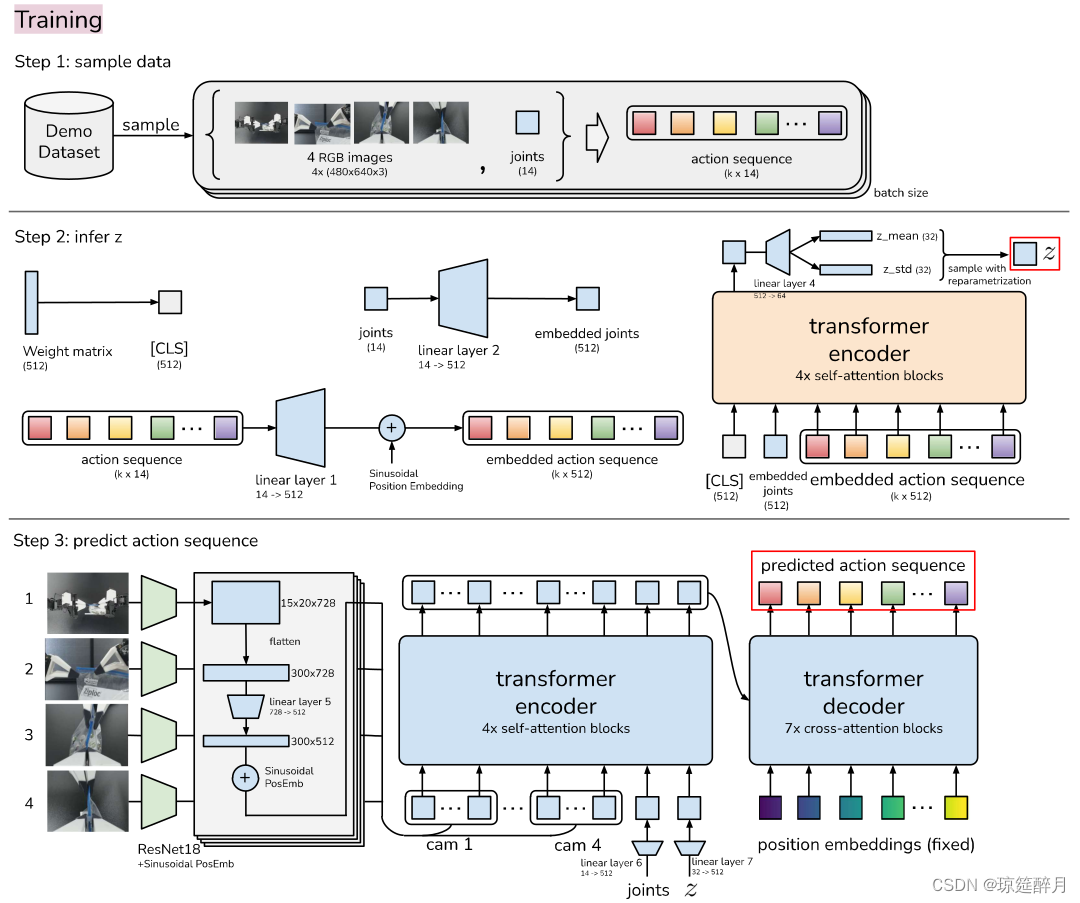
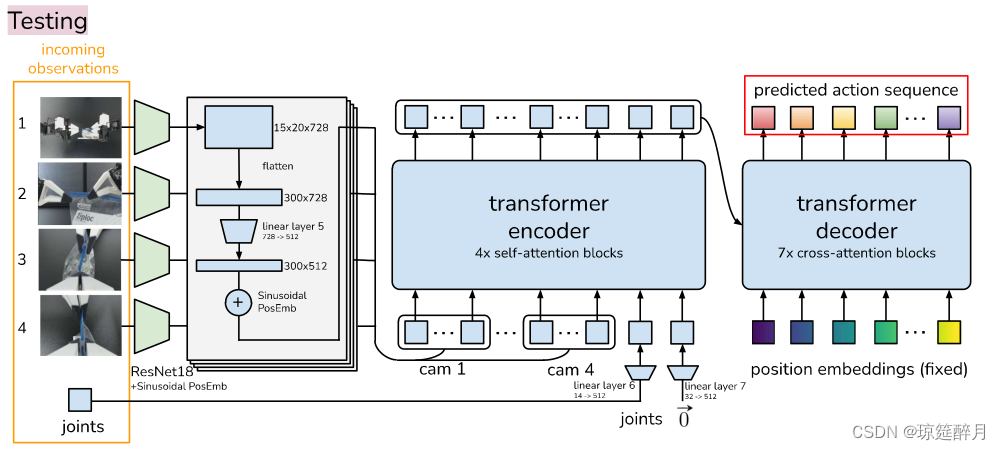
ACT逻辑解析
- ACT内核
- 1. 整体过程:
- 1.1 Action Chunking and Temporal Ensemble
- 1.2 Modeling human data(人工示教数据建模)
- 1.3 Implemention ACT
- 1.4
ACT内核
现有模仿学习缺点:在细颗粒度的任务中需要有高频的控制和闭环反馈
1. 整体过程:
- 采集示教数据:该数据为leader robots的关节位置作为动作,为什么是用
leader而不用follwer,是因为力的大小是隐式定义的,会存在差别,通过低层次PID控制器,观察者数据是由当前follower的关节位置和4张不同视角的图片构成的; - 训练
ACT,通过当前观测数据去预测一段未来行为,此处的动作对应于下一时间步长中双臂的目标关节位置,ACT基于当前观测数据模仿操作员在后续步长区间内会怎么操作,其中目标关节位置是通过点击内部的底层,高频的PID控制器跟踪获取的; - 在测试阶段,我们加载实现最低验证损失的策略,并在环境中进行预测;
- 最大的挑战还是在复合误差上
compounding errors,及实测时存在训练数据中缺少的状况;
1.1 Action Chunking and Temporal Ensemble
为了以一种与pixel-to-action 策略兼容的方式解决模仿学习的复合误差,我们试图减少在高频下收集的长轨迹的有效范围。受到 Action chuncking (神经科学的一个概念,将标记动作组合在一起,并作为一个单元执行,使它们更有效地存储和执行)的启发。直观来讲,一个 chucking 可能对应抓住糖果纸的一角或者是把电池插入电池仓中;在我们的测试中,将 chunk 的长度设置为 k:每 k 步,智能体接受一次观察值,生成 k 步的动作,并顺序执行。这就意味着任务有效长度减少了 k 倍。具体来说就是,策略模型为
π
θ
(
α
t
:
t
+
k
∣
s
t
)
\pi_\theta (\alpha_ {t:t+k} | s_t)
πθ(αt:t+k∣st) 而不是
π
θ
(
α
t
∣
s
t
)
\pi_\theta (\alpha_t | s_t)
πθ(αt∣st), chunking 可以协助实现示教数据中的非马尔可夫行为的建模。具体来说,单步的策略对时间相关的混杂因素不友好,例如示教过程中的停顿,这些状态没有任何价值,但是是存在于时间序列中的。当这种情况存在于chunk内,action chunk的策略会环节这个问题,而不会引入对历史条件政策造成因果混乱的问题。
动作分块的实现是非最优的:每k步生成一次观测值可能会导致机器人运动不平稳,为了提高运行的平稳性和避免观测与执行的分离,我们在每个步长都进行预测,这使得不同的动作块相互重叠,并且在给定的时间步长上会有比预测的动作更多的动作。在图3中进行了说明,提出 temporal ensemble (时态融合)来整合这些预测数据,该策略利用指数权重的机制来处理这些预测值:
ω
i
=
e
x
p
(
−
m
∗
i
)
\omega_i = exp(-m * i)
ωi=exp(−m∗i),其中
ω
0
\omega_0
ω0表示最老预测行为的权重。m 表示观测值对权重的衰减速度,m 越小,表示收敛的越快。我们注意到,与典型的平滑不同,在典型的平滑中,当前动作与相邻时间步长中的动作聚合,这会导致偏差,我们聚合了为同一时间步长预测的动作。该过程不产生额外的训练成本,只是在推理的时候需要增加点时间。在实践中,我们发现action chunking 和 temporal ensembling 是 ACT 成功的关键,他们能使轨迹更精准和平滑。

1.2 Modeling human data(人工示教数据建模)
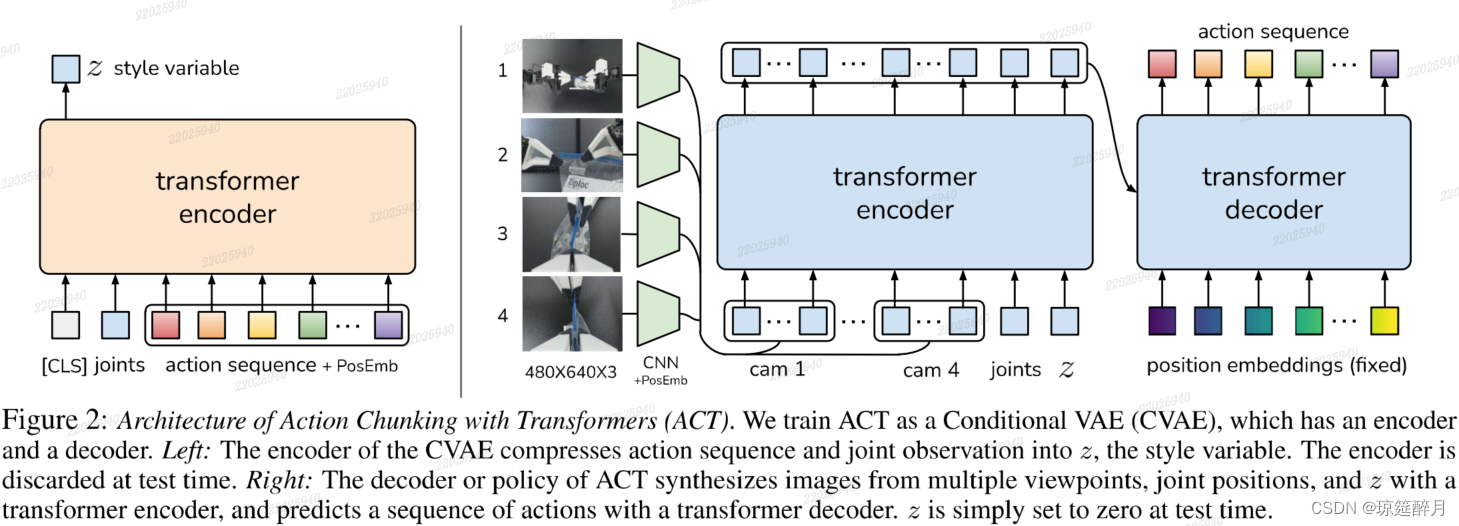
另外一个具有挑战性的任务就是从有噪声的示教数据中学习。对于同样的场景观测数据,人工会有不同的轨迹解决这个问题,在精度要求低的区域,人工就显的更加随机。因此,关注精度要求高的区域对策略来说是很重要的。为了跟踪这个问题,我们通过将 action chunking 策略训练生成模型。我们将训练策略称为是条件变分自动编码器CVAE,一种基于当前观测数据生成有条件的动作序列的方案。CVAE 分为两个部分:encoder 和 decoder(如下图所示)。 encoder :CAVE 编码器仅用于训练解码器,并在测试环节进行分解,具体的说,CAVE编码器预测风格变量 z 分布的均值和方差,该分布被参数化为对角高斯分布,给定当前的观测和动作噪声作为输入。在实践中,为了更快的进行训练,我们没用图像观测数据,仅以本体观察值和动作序列作为条件。
decoder (策略推导)过程,以 z 分布和当前观测数据(图片+关节位姿)预测动作序列。我们将z设置为先验分布的平均值,将零设置为确定性解码。整个模型是针对示教的动作快训练最大似然估计,
m
i
n
θ
−
∑
s
t
,
a
t
:
t
+
l
∈
D
l
o
g
π
θ
(
a
t
:
t
+
k
∣
s
t
)
min_\theta - \sum_{s_t, a_{t:t+l\in D}} log \pi_\theta(a_{t:t+k}|s_t)
minθ−st,at:t+l∈D∑logπθ(at:t+k∣st)
具有标准VAE目标,该目标具有两个项:重建损失和将编码器正则化为高斯先验的项。对第二项评判标准增加权重
β
\beta
β,提高
β
\beta
β 会导致传递更少的 z。我们发现,CAVE 的判断准则在从示教数据中学习到精确的任务逻辑是至关重要的。
1.3 Implemention ACT
我们基于 transform 实现 CVAE 的 encoder 和 decoder 过程,将 transformer 设计为合成信息序列和生成新序列。CVAE encoder 类似于 BERT 的 transformer encoder 结构。
encoder 过程:
INPUT:
- 当前关节位置
- k步的目标动作序列(这些数据都是来源于示教数据),
[CLS]
OUTPUT: transformer 处理后,[CLS] 对应的特征用于计算 z分布的均值和方差。
decoder 过程:
Components: ResNet , transformer encoder, transformer decoder
INPUT: 当前观测值, z 分布
OUTPUT: 预测的 k 步
解码过程: transformer encoder 整合来自于不同视角的相机图片,关节位置以及style variable, transformer decoder 生成连贯的动作序列。其中,相机图片来源于4个示教,分辨率为 480 * 640,关节坐标为 7*2=14 DOF,动作空间是面向2个机器人的14维向量,对于每个动作块,输出就是 14 * k。
- 用
ResNet18(很经典,但是具体能发挥多大作用未知) 作为backbone处理图片,使图片由480*640*3转变成15*20*512,然后经由全连接层变成200*512,为保存空间信息,将4张图整合在一起,构成1200*512。 - 增加两个特征:当前关节位置和
style variable z,
它们分别通过线性层从其原始尺寸投影到512,因此,transformer encoder的输入为1202 * 512。变换器-解码器通过交叉注意对编码器输出进行调节,其中输入序列是固定的,维度为k * 12,key和value均来自于encoder。transformer decoder的输出是k * 512,为了与机械臂关节维度吻合,通过MLP将维到k * 14。 loss:鉴于L1 loss在动作序列中的精度更高,所以我们采用L1 loss而不用更常见的L2 loss,而且还注意到,采用机器人的步进值要比目标关节位置的效果好。
算法伪代码如下图所示:


1.4
详细的逻辑如下展示: