最近的项目需要上监控,虽然之前也是使用这个方案,但是作为使用者一直没有太关注细节,也没有真正的去部署过,刚好凑着这次机会,彻底掌握下这套监控系统
1、监控系统架构
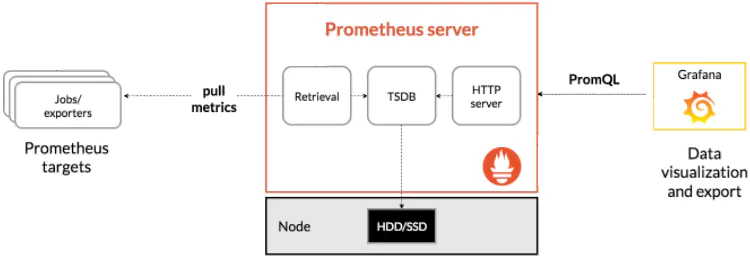
监控的架构这个图几乎每个文章都有,这里也不免俗,贴一下
1.1 先理解几个概念
- metric :指标,也就是系统监控的数据
- target:目标应用,也就是promethues拉取数据的目标
- exporter:向Prometheus提供监控样本数据的程序都可以被称为一个Exporter
- Job :可以简单理解为定时任务
- TSDB:时序数据库,是数据存储的地方
- Grafana : 展示数据的UI面板
1.2 原理
通过上图可以看到promethues server是使用pull的方式,也就是拉的方式去访问exporter的,也就是说所有的exporter都需要提供符合要求的接口,都可以接入监控系统。
promethues server 会启动一系列的定时任务,也就是job,然后根据配置的路径去拉取数据,存入TSDB 中,Grafana 使用PromQL 从数据库中获取数据,将数据整合后展示在面板上,如果是你自己做的话,你让每个受监控的app 实现相应的接口,输出json数据,然后使用将数据存入到mysql,最后再写一个管理平台,将数据使用sql查询出来展示在界面上
就是这样一个简单的逻辑,只是一套别人实现好了,有现成的规则,直接套就完了。
2、promethues
2.1 promethues是什么
Prometheus 收集和存储的度量数据是时间序列数据,也就是说度量信息与记录它的时间戳一起存储,同时存储的还有称为标签的可选键值对。
2.2 几个概念
学技术好难的一部分是专业术语,或者说叫黑话,这边介绍几个概念
Metric Name:指标名,可以理解为表名,等会PromQL中会用
Label:可以理解为查询条件,等会PromQL中会用
instance: 一个单独 scrape 的目标, 一般对应于一个进程。
2.3 技术细节
抓取到的指标会被以时间序列的形式保存在内存中,并且定时刷到磁盘上,默认是两个小时回刷一次。并且为了防止 Prometheus 发生崩溃或重启时能够恢复数据,Prometheus 也提供了类似 MySQL 中 binlog 一样的预写日志,当 Prometheus 崩溃重启时,会读这个预写日志来恢复数据。
Prometheus 采集的所有指标都是以时间序列的形式进行存储,每一个时间序列有三部分组成:
- 指标名和指标标签集合:metric_name{,....},指标名:表示这个指标是监控哪一方面的状态,
比如 http_request_total 表示:请求数量;指标标签,描述这个指标有哪些维度,比如 http_request_total 这个指标,有请求状态码 code = 200/400/500,请求方式:method = get/post 等,实际上指标名称实际上是以标签的形式保存,这个标签是name,即:name=。
- 时间戳:描述当前时间序列的时间,单位:毫秒。
- 样本值:当前监控指标的具体数值,比如 http_request_total 的值就是请求数是多少。

2.4 数据类型
promethues是时序数据库,也有自己的数据类型,这里介绍下
Prometheus 客户端库主要提供四种主要的 metric 类型
Counter (计数器类型)一般用于累计值典型的应用,只增不减 如:请求的个数,结束的任务数, 出现的错误数等等
Gauge(仪表盘类型) 一种常规的 metric,典型的应用如:温度,运行的 goroutines 的个数。可以任意加减。
Histogram(直方图类型) 可以理解为柱状图,典型的应用如:请求持续时间,响应大小。可以对观察结果采样,分组及统计
Summary(摘要类型)

2.5 PromQL
刚刚提到了 Prometheus 中指标有哪些类型以及如何导出我们的指标,现在指标导出到 Prometheus 了,利用其提供的 PromQL 可以查询我们导出的指标。
PromQL 是 Prometheus 为我们提供的函数式的查询语言,查询表达式有四种类型:
- 字符串:只作为某些内置函数的参数出现
- 标量:单一的数字值,可以是函数参数,也可以是函数的返回结果
- 瞬时向量:某一时刻的时序数据
- 区间向量:某一时间区间内的时序数据集合
2.5.1 瞬时查询
直接通过指标名即可进行查询,查询结果是当前指标最新的时间序列,比如查询 Gc 累积消耗的时间:go_gc_duration_seconds_count
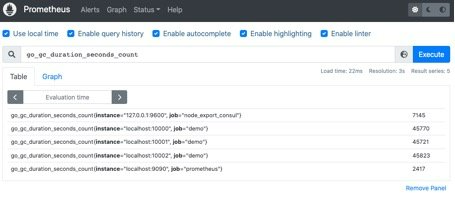
2.5.2 过滤查询
我们可以看到查询出来有多个同名指标结果,可以用{}做标签过滤查询:比如我们想查指定实例的指标。go_gc_duration_seconds_count{instance="127.0.0.1:9600"}
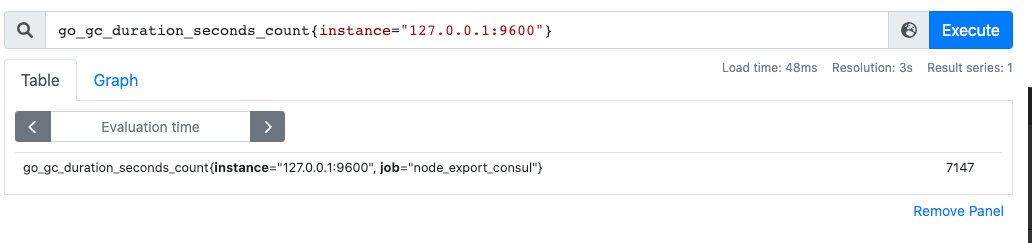
而且也支持则表达式,通过=~指定正则表达式,如下所示:查询所有 instance 是 localhost 开头的指标。go_gc_duration_seconds_count{instance=~"localhost.*"}
2.5.3 范围查询
范围查询的结果集就是区间向量,可以通过[]指定时间来做范围查询,查询 5 分钟内的 Gc 累积消耗时间:go_gc_duration_seconds_count{}[5m]
注意:这里范围查询第一个点并不一定精确到刚刚好 5 分钟前的那个时序样本点,他是以 5 分钟作为一个区间,寻找这个区间的第一个点到最后一个样本点。
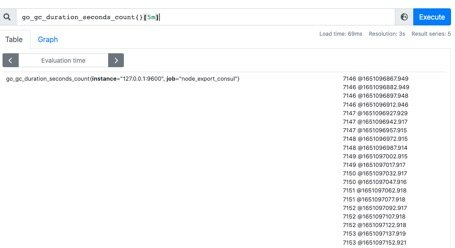
时间单位:d:天,h:小时,m:分钟,ms:毫秒,s:秒,w:周,y:年
同样支持类似 SQL 中的 offset 查询,如下:查询一天前当前 5 分钟前的时序数据集:
go_gc_duration_seconds_count{}[5m] offset 1d
3、exporter
所有可以向Prometheus提供监控样本数据的程序都可以被称为一个Exporter。而Exporter的一个实例称为target,如下所示,Prometheus通过轮询的方式定期从这些target中获取样本数据:
Prometheus社区提供了丰富的Exporter实现,涵盖了从基础设施,中间件以及网络等各个方面的监控功能。这些Exporter可以实现大部分通用的监控需求。下表列举一些社区中常用的Exporter:
 4、Grafana
4、Grafana
Grafana是开源的、炫酷的可视化监控、分析利器,它还有丰富的套件供您选择,目前,它已拥有54个数据源,50个面板,17个应用程序和1732个仪表盘。总而言之Grafana是一个跨平台的开源的度量分析和可视化工具,可以通过将采集的数据查询然后可视化的展示,并及时通知。
grafana有热插拔控制面板和可扩展的数据源,目前已经支持Graphite、InfluxDB、OpenTSDB、Elasticsearch。
这里需要留意的是,上面官方列举的数据源都是时序型数据库。这也透露出 Grafana 的另一大适用性:Grafana 一般是配合时序数据库做数据展示的。
Grafana 与 Kibana 的区别
Kibana 是运维圈耳熟能详的后端数据实时展示工具。日常工作中,大家都用 Kibana 结合Logstash、ElasticSearch 等组件一起使用做日志展示、索引、分析的。但Kibana也可以接入其他数据源的,只不过最常见的用法还是展示日志。
Grafana 最早其实应该是 Kibana3 的一个分支。不同的是,Grafana 拥有自己的权限管理和用户管理系统,而 Kibana 没有权限管理系统。Kibana 和 ES 结合紧密,支持强大的ES语法,比较适合做一些多维度的分析和查询,而Grafana更适合用于展示,图形比Kibana美观很多。

4、promethues环境搭建
我懒,所以直接用docker部署,这里是官方镜像 Docker
4.1 部署脚本
直接上启动脚本 start_promethues.sh
docker run -d \
--name prometheus \
-p 9090:9090 \
--privileged=true \
-v /home/data/promethues/conf/prometheus.yml:/etc/prometheus/prometheus.yml \
-v /home/data/promethues/data/:/data \
-e TZ=Asia/Shanghai \
prom/prometheus:latest4.2 配置文件
这里我挂载了配置 prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['127.0.0.1:9090']
- job_name: 'chongxin'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
metrics_path: '/actuator/prometheus'
static_configs:
- targets: ['192.168.13.1:8080']这里配置了两个job,一个promethues自身的监控,还有一个是我自己写的springboot应用,等会下面会展示。
4.3 验证
输入 http://127.0.0.1:9090/进入,点击 status-> Targets 可以看到在线的应用,已经指标获取的路径

这里可以看到有两个应用在线,可以点链接进去,可以看到都有哪些指标。
4.4 服务注册
promethues监控的目标有两种注册方式,
一种是静态注册,也就是直接写到配置中,
一种是动态注册,通过服务发现实现,但是需要将注册中心的地址通过静态注册的方式
4.4.1静态注册
静态的将服务的 IP 和抓取指标的端口号配置在 Prometheus yaml 文件的 scrape_configs 配置下:
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]以上就是注册了一个名为 prometheus 的服务,这个服务下有一个实例,暴露的抓取地址是 localhost:9090。
4.4.2 动态注册
动态注册就是在 Prometheus 文件的 scrape_configs 配置下配置服务发现的地址和服务名,Prometheus 会去该地址,根据你提供的服务名动态发现实例列表,在 Prometheus 中,支持 consul,DNS,文件,K8s 等多种服务发现机制。
基于 consul 的服务发现:
- job_name: "node_export_consul"
metrics_path: /node_metrics
scheme: http
consul_sd_configs:
- server: localhost:8500
services:
- node_exporter我们 consul 的地址就是:localhost:8500,服务名是 node_exporter,在这个服务下有一个 exporter 实例:localhost:9600。
5、部署grafana
5.1 部署脚本
docker run \
--user root \
-d \
-p 3000:3000 \
--name=grafana \
-v /home/data/grafana/data:/var/lib/grafana \
grafana/grafana5.2 验证
地址:http://127.0.0.1:3000
默认用户名和密码是admin/admin,首次登录会让你修改密码

6、springboot 监控步骤
6.1 创建springboot 项目
创建项目没有什么特殊的,直接一路next 火花带闪电
6.2 引用监控包
pom.xml 中添加引用
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--prometheus-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
</dependencies>6.3 配置开启指标
application.yml中添加配置,如果你是application.properties 则修改为对应的配置
spring:
application:
name: chongxin
#prometheus监控平台配置
management:
endpoints:
web:
exposure:
include: "*"
exclude: configprops
endpoint:
health:
show-details: ALWAYS
metrics:
tags:
application: ${spring.application.name}6.4 监控指标
这里直接添加一个controller,进行Counter计数指标
import io.prometheus.client.CollectorRegistry;
import io.prometheus.client.Counter;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class TestController {
private final Counter requestCount;
public TestController(CollectorRegistry collectorRegistry) {
requestCount = Counter.build()
.name("request_count")
.help("Number of hello requests.")
.register(collectorRegistry);
}
@GetMapping("/test")
public String sayHello() {
requestCount.inc();
return "hello";
}
}注意,这里的name 就是表名,也叫指标名,等会配置用的到
7、配置监控指标,联动系统
整体的思路就是grafana从promethues中获取数据,然后配置展示的方式
7.1 配置数据源
点击设置,选择Data sources ,然后选择add data source,我这里是套装,直接选择promethues,根据你自己的数据库,选择合适的类型

7.2 配置监控指标
配置监控指标看板,官方提供了一些现成的模板,比如你要监控mysql,只要使用Mysql Exporter,这个时候直接使用官方的模板就可以了,这样可以快速接入
这里我直接选了一个springboot的模板,等会在模板上再加一些指标即可
官方模板地址:JVM (Actuator) with application name | Grafana Labs
导入SpringBoot模板13694,如下,红框处可以添加自定义的监控指标

添加自定义模板,我这里选择了Graph,然后点击title 出现下拉框修改指标,点击编辑

输入指标名request_count,会有提示,这里简单的做个展示,直接request_count_total
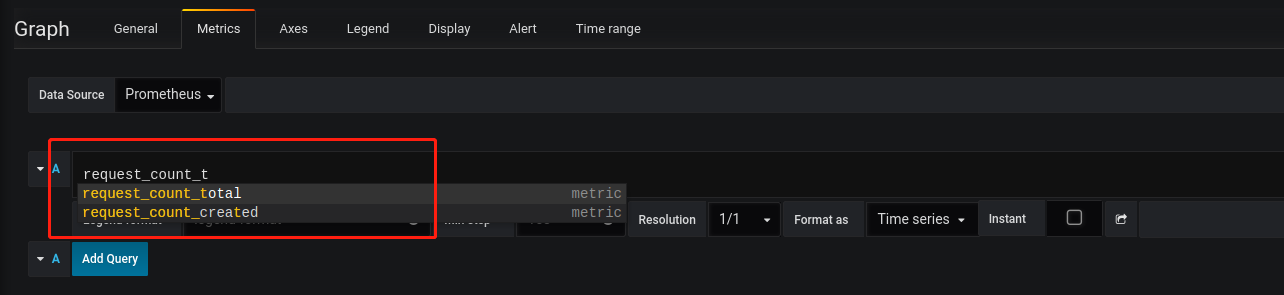
返回之后可以看到图形有个数据,至此已经联动好了
8、总结
这一篇的内容还挺多的,主要是嫌麻烦分几批,直接放入一个算了
技术上来说没什么难处,难的点在于接触新的概念,如果理解了也就没什么难的了
今天主要是学习了时序数据库(Promethues)和简单查询语法PromQL,UI看板的配置(Grafana),Exporter等监控系统的相关知识。
对了,今天并没有去探索grafana的警告机制,后续会补全
点赞鼓励,养成赞美的习惯