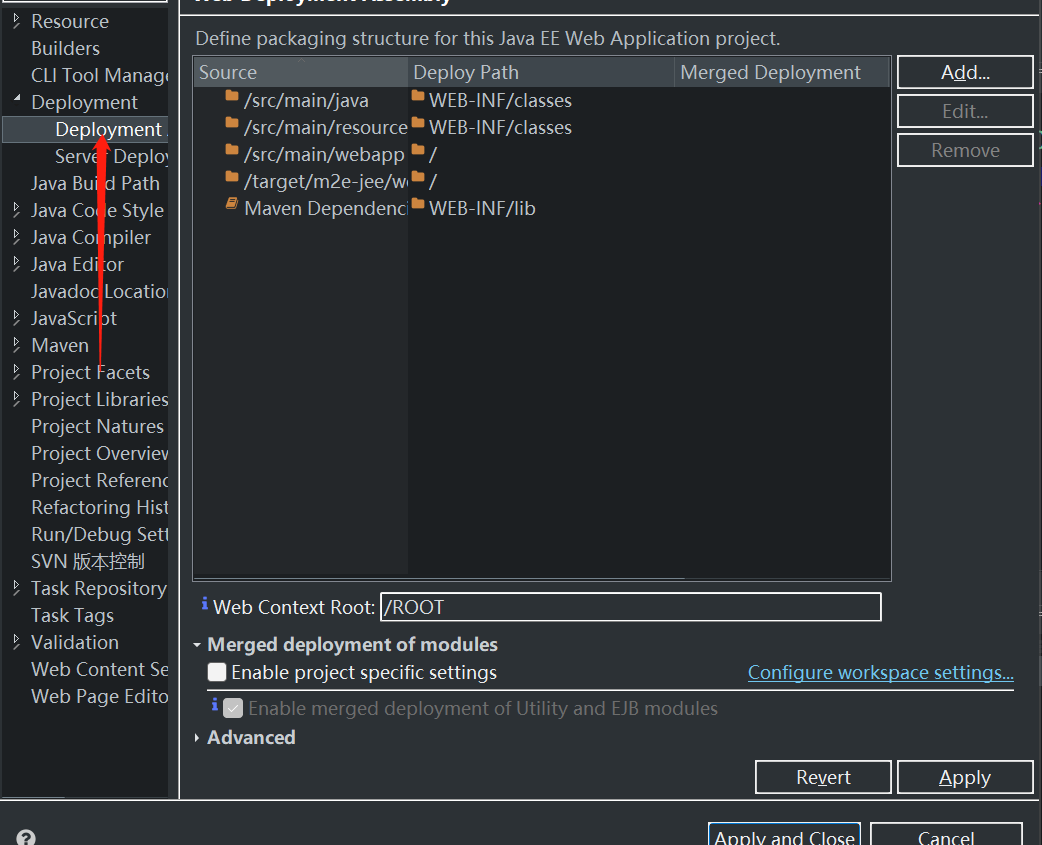
字符判断
难度:白银
时间限制:1秒
巴占用内存:64M
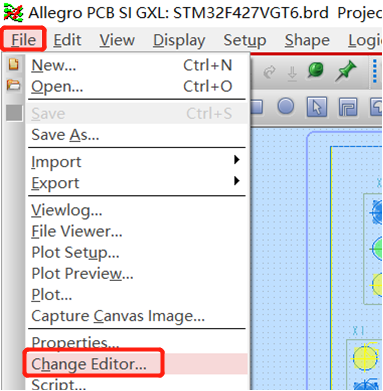
输入一个字符,判断是数字字符、大写字母、小写字母、算术运算符、
关系运算符、逻辑运算符,还是其他字符,分别输出Number?”,
"Capital letter?”,Lowercase letter'”,“Arithmetic
operators”,“Relational operators”,Logical operators”,
"Other character”。
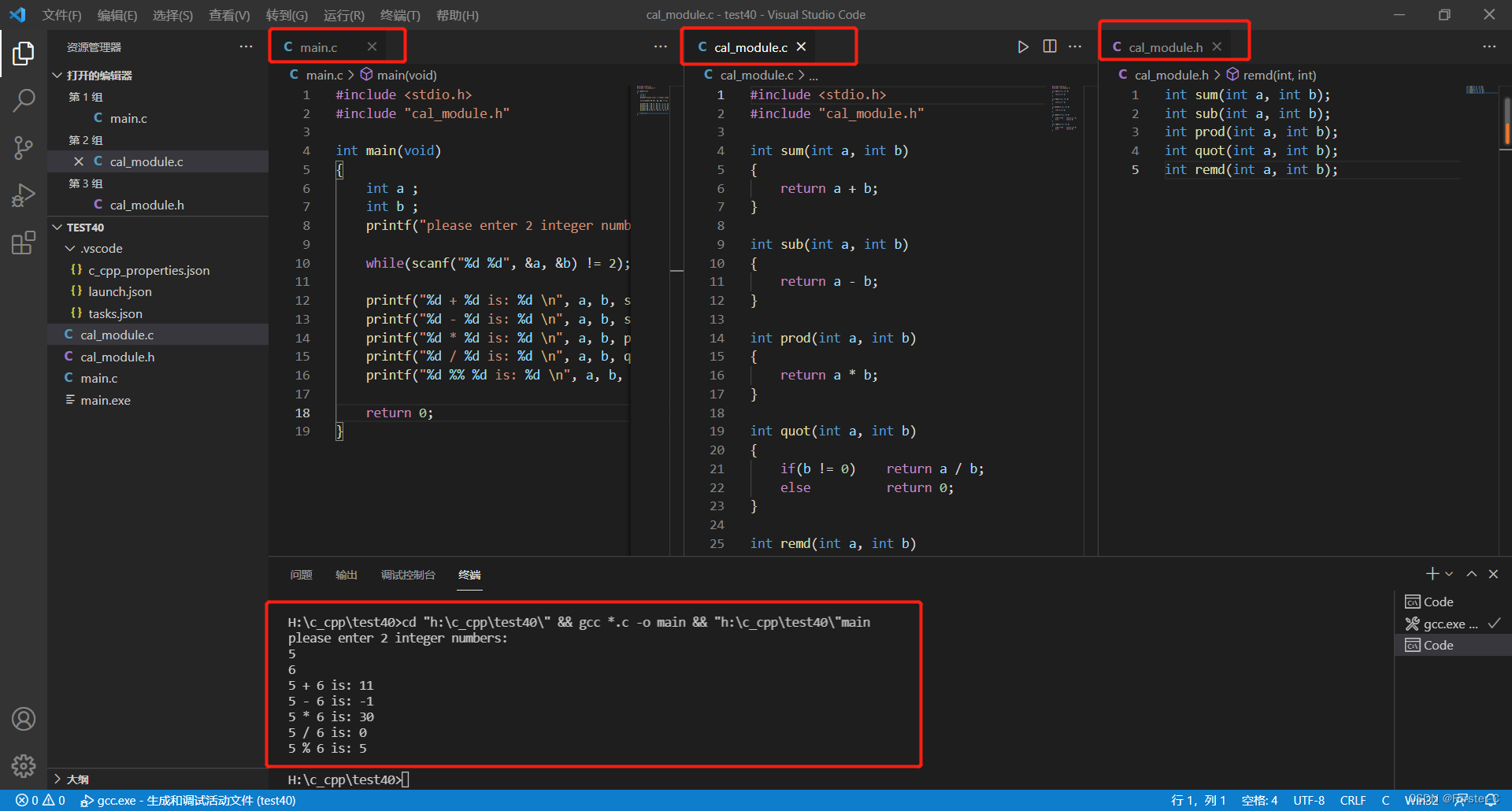
#include<bits/stdc++.h>
using namespace std;
int main()
{
char a;
cin>>a;
if (a>=48 && a<=57) cout<<"Number";
else if(a>=65 && a<=90) cout<<"Capital letter";
else if(a>=97 && a<=122) cout<<"Lowercase letter";
else if(a=='+'|| a=='-'||a=='*' ||a=='/') cout<<"Arithmetic operators";
else if(a=='='|| a=='>'|| a=='<')cout<<"Relational operators";
else if(a=='!'|| a=='&'|| a =='|' || a=='^')cout<<"Logical operators";
else cout<<"Other character";
return 0;
}术角度稍微改造一下,理论上是可以取代传统搜索引擎的。

为什么说目前形态的chatGPT还不能取代搜索引擎呢?
主要有三点原因:首先,对于不少知识类型的问题,chatGPT会给出看上去很有道理,但是事实上是错误答案的内容(参考上图的例子(from @Gordon Lee),ChatGPT的回答看着胸有成竹,像我这么没文化的基本看了就信了它,回头查了下这首词里竟然没这两句),考虑到对于很多问题它又能回答得很好,这将会给用户造成困扰:如果我对我提的问题确实不知道正确答案,那我是该相信ChatGPT的结果还是不该相信呢?此时你是无法作出判断的。这个问题可能是比较要命的。其次,ChatGPT目前这种基于GPT大模型基础上进一步增加标注数据训练的模式,对于LLM模型吸纳新知识是非常不友好的。新知识总是在不断出现,而出现一些新知识就去重新预训练GPT模型是不现实的,无论是训练时间成本还是金钱成本,都不可接受。如果对于新知识采取Fine-tune的模式,看上去可行且成本相对较低,但是很容易产生新数据的引入导致对原有知识的灾难遗忘问题,尤其是短周期的频繁fine-tune,会使这个问题更为严重。所以如何近乎实时地将新知识融入LLM是个非常有挑战性的问题。其三,ChatGPT或GPT4的训练成本以及在线推理成本太高,导致如果面向真实搜索引擎的以亿记的用户请求,假设继续采取免费策略,OpenAI无法承受,但是如果采取收费策略,又会极大减少用户基数,是否收费是个两难决策,当然如果训练成本能够大幅下降,则两难自解。以上这三个原因,导致目前ChatGPT应该还无法取代传统搜索引擎。
那么这几个问题,是否可以解决呢?其实,如果我们以ChatGPT的技术路线为主体框架,再吸纳其它对话系统采用的一些现成的技术手段,来对ChatGPT进行改造,从技术角度来看,除了成本问题外的前两个技术问题,目前看是可以得到很好地解决。我们只需要在ChatGPT的基础上,引入sparrow系统以下能力:基于retrieval结果的生成结果证据展示,以及引入LaMDA系统的对于新知识采取retrieval模式,那么前面提到的新知识的及时引入,以及生成内容可信性验证,基本就不是什么大问题。
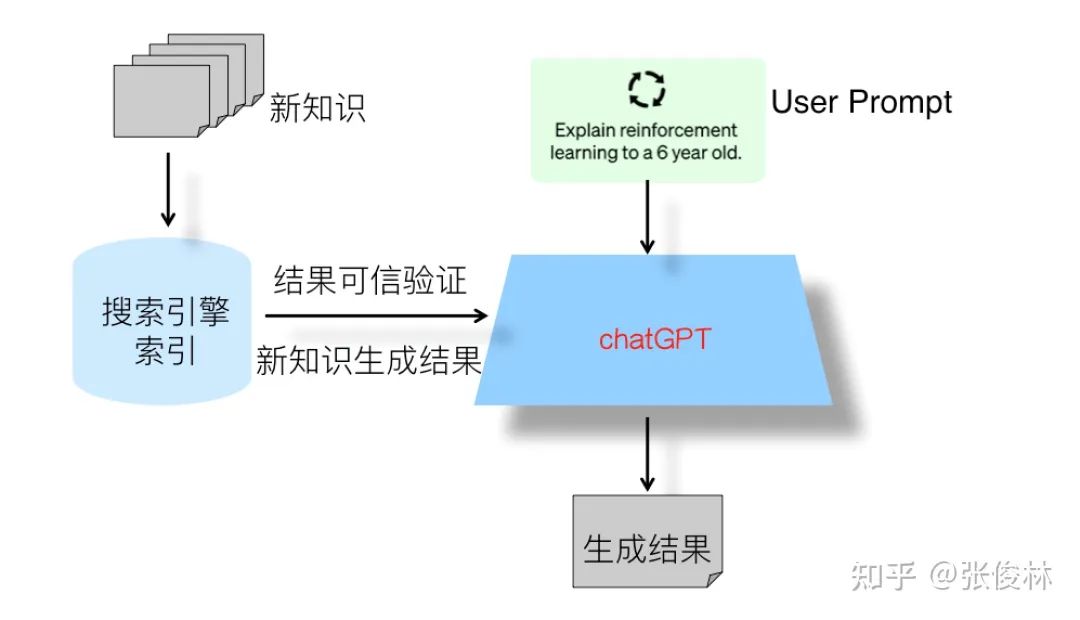
基于以上考虑,在上图中展示出了我心目中下一代搜索引擎的整体结构:它其实是目前的传统搜索引擎+ChatGPT的双引擎结构,ChatGPT模型是主引擎,传统搜索引擎是辅引擎。传统搜索引擎的主要辅助功能有两个:一个是对于ChatGPT产生的知识类问题的回答,进行结果可信性验证与展示,就是说在ChatGPT给出答案的同时,从搜索引擎里找到相关内容片段及url链接,同时把这些内容展示给用户,使得用户可以从额外提供的内容里验证答案是否真实可信,这样就可以解决ChatGPT产生的回答可信与否的问题,避免用户对于产生结果无所适从的局面。当然,只有知识类问题才有必要寻找可信信息进行验证,很多其他自由生成类型的问题,比如让ChatGPT写一个满足某个主题的小作文这种完全自由发挥的内容,则无此必要。所以这里还有一个什么情况下会调用传统搜索引擎的问题,具体技术细节完全可仿照sparrow的做法,里面有详细的技术方案。传统搜索引擎的第二个辅助功能是及时补充新知识。既然我们不可能随时把新知识快速引入LLM,那么可以把它存到搜索引擎的索引里,ChatGPT如果发现具备时效性的问题,它自己又回答不了,则可以转向搜索引擎抽取对应的答案,或者根据返回相关片段再加上用户输入问题通过ChatGPT产生答案。关于这方面的具体技术手段,可以参考LaMDA,其中有关于新知识处理的具体方法。
除了上面的几种技术手段,我觉得相对ChatGPT只有一个综合的Reward Model,sparrow里把答案helpful相关的标准(比如是否富含信息量、是否合乎逻辑等)采用一个RM,其它类型toxic/harmful相关标准(比如是否有bias、是否有害信息等)另外单独采用一个RM,各司其职,这种模式要更清晰合理一些。因为单一类型的标准,更便于标注人员进行判断,而如果一个Reward Model融合多种判断标准,相互打架在所难免,判断起来就很复杂效率也低,所以感觉可以引入到ChatGPT里来,得到进一步的模型改进。
通过吸取各种现有技术所长,我相信大致可以解决ChatGPT目前所面临的问题,技术都是现成的,从产生内容效果质量上取代现有搜索引擎问题不大。当然,至于模型训练成本和推理成本问题,可能短时期内无法获得快速大幅降低,这可能是决定LLM是否能够取代现有搜索引擎的关键技术瓶颈。从形式上来看,未来的搜索引擎大概率是以用户智能助手APP的形式存在的,但是,从短期可行性上来说,在走到最终形态之前,过渡阶段大概率两个引擎的作用是反过来的,就是传统搜索引擎是主引擎,ChatGPT是辅引擎,形式上还是目前搜索引擎的形态,只是部分搜索内容Top 1的搜索结果是由ChatGPT产生的,大多数用户请求,可能在用户看到Top 1结果就能满足需求,对于少数满足不了的需求,用户可以采用目前搜索引擎翻页搜寻的模式。我猜搜索引擎未来大概率会以这种过渡阶段以传统搜索引擎为主,ChatGPT这种instruct-based生成模型为辅,慢慢切换到以ChatGPT生成内容为主,而这个切换节点,很可能取决于大模型训练成本的大幅下降的时间,以此作为转换节点。
点击进入—> CV 微信技术交流群
CVPR/ECCV 2022论文和代码下载