文章目录
- week33 AirFormer
- 摘要
- Abstract
- 一、论文的前置知识
- 1. 多头注意力机制(MSA)
- 2. 具有潜变量的变分模型
- 二、文献阅读
- 1. 题目
- 2. abstract
- 3. 问题与模型阐述
- 3.1 问题定义
- 3.2 模型概述
- 3.3 跨空间MSA(DS-MSA)
- 3.4 时间相关MSA(CT-MSA)
- 3.5 自上而下的随机阶段
- 3.6 预测以及优化
- 4. 文献解读
- 4.1 Introduction
- 4.2 创新点
- 4.3 实验过程
- 1. 数据集
- 2. 比较的基线模型
- 3. 消融实验
- 4.4 结论
- 三、GAN
- 1. 任务要求
- 2. 实验结果
- 3.实验代码
- 3.1数据准备
- 3.2 模型构建
- 3.3 展示函数
- 3.4 训练过程
- 小结
- 参考文献
week33 AirFormer
摘要
本文主要讨论基于Transformer的空气质量预测。首先本文简要介绍了多头注意力机制(MSA)、 具有潜变量的变分模型。其次本文展示了题为AirFormer: Predicting Nationwide Air Quality in China with Transformers的论文主要内容。该文提出了一种名为 AirFormer 的新型 Transformer 架构,用于集体预测中国全国范围内的空气质量,并以前所未有的精细空间粒度覆盖数千个地点。该实验实现GAN网络,并使用MNIST数据库训练GAN,GAN绘制手写数字图片。
Abstract
This article focuses on Transformer-based air quality prediction. First, this paper briefly introduces the multi-head attention mechanism (MSA) and the variational model with latent variables. Secondly, this paper presents the main content of the paper entitled AirFormer: Predicting Nationwide Air Quality in China with Transformers. This paper proposes a novel Transformer architecture called AirFormer for collectively predicting air quality across China and covering thousands of locations with unprecedented spatial granularity. This experiment implements the GAN construct, trains the GAN using the MNIST database, and uses the GAN to draw handwritten digital pictures.
一、论文的前置知识
1. 多头注意力机制(MSA)
MSA 是 Transformer 学习对齐的关键操作,其中序列中的每个令牌学习从其他令牌收集消息。设
X
∈
R
S
×
C
X ∈ R^{S×C}
X∈RS×C 为长度为 N、特征维度为 C 的输入序列。单头的操作定义为:
X
h
=
Softmax
(
α
Q
h
K
h
T
)
V
h
(2)
X_h=\text{Softmax}(\alpha Q_hK_h^T)V_h \tag{2}
Xh=Softmax(αQhKhT)Vh(2)
其中
X
h
∈
R
S
×
C
/
N
h
X_h\in R^{S\times C/N_h}
Xh∈RS×C/Nh为输出特征;
Q
h
=
X
W
q
,
K
h
=
X
W
k
,
V
h
=
X
W
v
Q_h=XW_q,K_h=XW_k,V_h=XW_v
Qh=XWq,Kh=XWk,Vh=XWv为query、key、value;
W
q
,
W
k
,
W
v
∈
R
C
×
C
/
N
h
W_q,W_k,W_v\in R^{C\times C/N_h}
Wq,Wk,Wv∈RC×C/Nh为线性映射的可学习参数,
N
h
N_h
Nh是头的数量,
α
\alpha
α是比例因子。方程的计算复杂度式 (2) 与序列长度 S 成二次方。
2. 具有潜变量的变分模型
变分自动编码器(VAE)早已被证明是恢复潜在空间上复杂多模态分布的有效建模范例。 VAE 使用未观察到的潜在变量 z 来解决数据分布 p(x) 的问题,并由 θ 参数化为:
p
θ
(
x
)
=
∫
p
θ
(
x
∣
z
)
p
θ
(
z
)
d
z
(3)
p_\theta(x)=\int p_{\theta}(x|z)p_\theta (z)dz \tag{3}
pθ(x)=∫pθ(x∣z)pθ(z)dz(3)
由于积分通常很棘手,VAE 引入了近似后验
q
φ
(
z
∣
x
)
q_φ(z|x)
qφ(z∣x) 并隐式优化边际对数似然的证据下界 (ELBO):
l
o
g
p
θ
(
x
)
≥
−
K
L
(
q
φ
(
z
∣
x
)
E
p
θ
(
z
)
)
+
E
q
φ
(
z
∣
x
)
[
l
o
g
p
θ
(
x
∣
z
)
]
log pθ(x) ≥ −KL (q_φ(z|x) E_{p_θ}(z))+E_{q_φ}(z|x) [log pθ(x|z)]
logpθ(x)≥−KL(qφ(z∣x)Epθ(z))+Eqφ(z∣x)[logpθ(x∣z)] ,其中 KL 表示 KL 散度。潜变量的先验
p
θ
(
z
)
p_θ(z)
pθ(z) 和后验
q
φ
(
z
∣
x
)
q_φ(z|x)
qφ(z∣x) 通常被视为具有对角协方差的高斯分布,它本质上编码了输入数据的不确定性。
二、文献阅读
1. 题目
题目:AirFormer: Predicting Nationwide Air Quality in China with Transformers
作者:Yuxuan Liang, Yutong Xia, Songyu Ke, Yiwei Wang, Qingsong Wen, Junbo Zhang, Yu Zheng, Roger Zimmermann
链接:https://arxiv.org/abs/2211.15979
发布:AAAI 2022
代码位置:https://github.com/yoshall/airformer.
2. abstract
该文提出了一种名为 AirFormer 的新型 Transformer 架构,用于集体预测中国全国范围内的空气质量,并以前所未有的精细空间粒度覆盖数千个地点。 AirFormer 将学习过程解耦为两个阶段
1)自下而上的确定性阶段,包含两种新型的自注意力机制,可有效学习时空表示;
2)具有潜在变量的自上而下的随机阶段,用于捕获空气质量数据的内在不确定性。
该文利用中国大陆 1,085 个站点的 4 年数据对 AirFormer 进行评估。与最先进的模型相比,AirFormer 在 72 小时的未来预测中将预测误差降低了 5%∼8%。
This paper presents a novel Transformer architecture termed AirFormer to collectively predict nationwide air quality in China, with an unprecedented fine spatial granularity covering thousands
of locations. AirFormer decouples the learning process into two stages
-
a bottom-up deterministic stage that contains two new types of self-attention mechanisms to efficiently learn spatio-temporal representations;
-
a top-down stochastic stage with latent variables to capture the intrinsic uncertainty of air quality data.
This paper evaluates AirFormer with 4-year data from 1,085 stations in the Chinese Mainland. Compared to the state-of-the-art model, AirFormer reduces prediction errors by 5%∼8% on 72-hour future predictions.
3. 问题与模型阐述
3.1 问题定义
N 个空气质量监测站在给定时间 t 的读数可表示为
X
t
∈
R
N
×
D
X_t ∈ R^N×D
Xt∈RN×D,其中 D 为测量次数,包括空气污染物(如 PM2.5、NO2)和外部因素(如天气) , 风速)。每个条目
x
i
j
x_{ij}
xij 表示第 i 个站点的第 j 个测量值。给定过去 T 个时间步中所有站点的历史读数,目标是学习一个函数 F(·) 来预测接下来
τ
τ
τ 个步中的 D’ 种测量值:
X
1
:
T
⟶
F
(
⋅
)
Y
1
:
τ
(1)
X_{1:T}\stackrel{\mathcal F(\cdot)}{\longrightarrow}Y_{1:\tau} \tag{1}
X1:T⟶F(⋅)Y1:τ(1)
其中
X
1
:
T
∈
R
T
×
N
×
D
X_{1:T}\in R^{T\times N\times D}
X1:T∈RT×N×D为历史数据,
Y
1
:
τ
∈
R
τ
×
N
×
D
′
Y_{1:\tau}\in R^{\tau\times N\times D'}
Y1:τ∈Rτ×N×D′为未来预测
3.2 模型概述
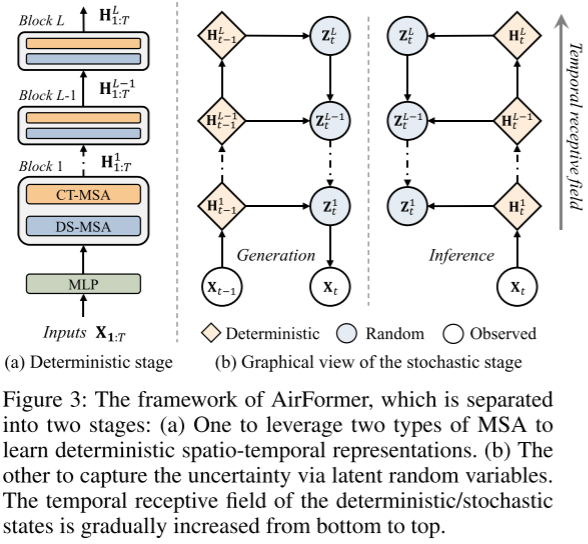
上图显示了AirFormer全国空气质量预测的框架,该框架被解耦为两个阶段
-
自下而上的确定性阶段:首先使用多层感知器(MLP)将历史读数 X 1 : T X_{1:T} X1:T 转换到特征空间。然后将转换后的特征输入 L AirFormer 模块以学习确定性时空表示。在每个块中,沿着时间和空间域分解时空建模,从而产生 MSA 的双重级别:
- DS-MSA 用于学习具有线性复杂性的空间交互,
- CT-MSA 用于捕获每个位置的时间依赖性。
如上图(a)所示,第 l 个块的输出状态是一个 3D 张量,表示为 H 1 : T l ∈ R T × N × C H^l_{1:T} ∈ R^{T×N×C} H1:Tl∈RT×N×C。
-
自上而下的随机阶段:一旦获得确定性表示,则在每个级别产生潜在变量 Z。为了保持 Transformer 的并行性,坚持不在不同时间步之间建立显式依赖关系。相反,通过将潜在变量 Z t l − 1 Z^{l−1}_t Ztl−1 调节到其高级变量 Z t l Z^l_t Ztl 来隐式构建时间依赖性,如上图 (b) 所示,其中 Z t i ∈ R N × C Z^i_t ∈ R^{N×C} Zti∈RN×C 且 i = {1,… 。 。 ,L}。这样,较低层的潜在变量更关注局部信息,而较高层的潜在变量由于其相应的确定性输入而具有更大的感受野。在我们的模型中,生成任务是使用先验 p θ ( Z t l ∣ X 1 : t − 1 ) p_θ(Z^l _t|X_{1:t−1}) pθ(Ztl∣X1:t−1) 在给定所有过去步骤的情况下预测下一个时间步骤,推理任务是近似后验 $q_φ(Z^l_t|X_{1:t}) $ .由于 AirFormer 属于 VAE 家族,我们通过联合优化预测损失和 ELBO 来训练我们的模型。
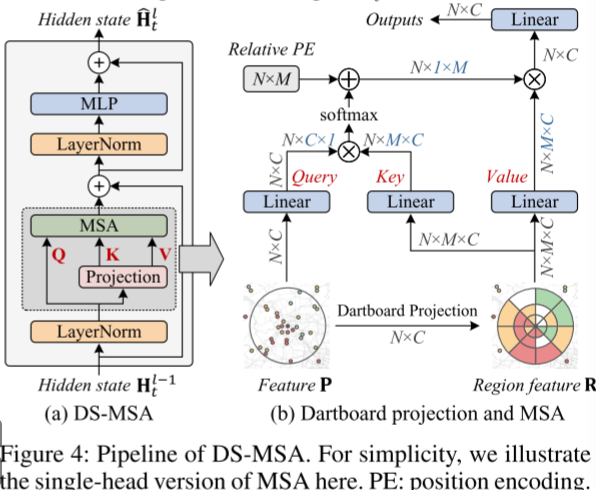
3.3 跨空间MSA(DS-MSA)
整体设计
一个地方的空气质量,除了当地的排放外,还会收到相邻地方的影响。提出了DS-MSA去捕获同一时间某地方与其他区域的联系。DS-MSA有更大的感受野但是却只有线性的计算复杂度。DS-MSA以上一个block得到的隐变量H作为输入,首先对其进行LayerNorm将其经过Linear层生成该站点的query矩阵,并将周围环境投影到Dartboard中得到key和value,以该方法减少计算复杂度。最后执行MSA学习空间依赖性,利用MLP输出结果H1。
详细设计
-
对于每个站点,都会有一个相应的映射矩阵A(M*N),其中M表示区域数量,N表示站点总个数。A矩阵中的值a[i,j]表示第j个站点属于i区域的可能性,A矩阵中一行值的和0(类似AVG)
-
对于每个站点区域的划分,是以当前站点为中心的同心圆,如下面例子中一共有3*8+1=25个区域(25<<1000+,极大地降低计算复杂度)
-
假设进入dartboard映射的输入是P矩阵(NC),通过A矩阵,可以得到每个站点的区域表示R[i] = A[i]P(MC),最终的区域表示是R = [R1,R2,R3…Rn](NM*C),N个站点的区域表示concat得到。
-
之后使用得到的query和根据R经过linear得到的key和value进入MSA捕获空间关联。
- X h = softmax ( α Q h K h T + B h ) V h (5) X_h=\text{softmax}(\alpha Q_hK_h^T+B_h)V_h \tag{5} Xh=softmax(αQhKhT+Bh)Vh(5)
-
B是一个可学习的相对位置编码用于增加位置信息。我们可以引入风俗风向等外部信息作为辅助。
DS-MSA模块考虑了空气污染分散的领域知识,由于将区域的个数从N个站点降低到M个region,计算复杂度降低,使用dartboard映射不会再MSA中引入额外的可学习变量,固模型是轻量级的。
3.4 时间相关MSA(CT-MSA)

整体设计
一个地方的空气变化不但会受到周围地区的影响,还会受到之前空气排量的影响。如果直接使用MSA学习时间依赖会产生平方级的成本,因此使用CT-MSA代替标准MSA
详细设计
鉴于时间越接近当前时间相关性越强,因此作者使用非重叠的窗口,在窗口内执行MSA捕获时间步长之间的局部交互作用。为了尽量不丧失MSA的感受野,作者从上到下逐渐增加了窗口的大小。
时间因果关系:由于当前时间的空气质量不以其未来为条件,所以遵循WaveNet在MSA中引入因果关系,确保模型不会违反输入数据的时间顺序。这种顺序关系可以在mask attention map中的区域实现。
为了在MSA中实现位置敏感性,在CT-MSA的输入中增加了绝对位置编码。
3.5 自上而下的随机阶段

整体设计
获得确定性表示后,构建潜在随机变量来了解空气质量数据的不确定性,例如不可预测的因素和噪声观测。
详细设计
-
生成阶段(generation):在过去所有的步骤中预测下一步
-
在编码确定性状态 H t H_t Ht中的位置之间的空间依赖性之后,可以将一组随机变量的先验分布 Z t = { Z t l , … , Z t L } \mathcal Z_t=\{Z_t^l,\dots,Z_t^L\} Zt={Ztl,…,ZtL}分解为
-
p θ ( Z t ∣ X 1 : t − 1 ) = ∏ n = 1 N p θ ( { z t , n 1 , … , z t , n L } ∣ X 1 : t − 1 ) = ∏ n = 1 N p θ ( z t , n L ∣ h t − 1 , n L ) ∏ l = 1 L − 1 p θ ( z t , n l ∣ z t , n l + 1 , h t − 1 , n l ) (6) p_\theta(\mathcal Z_t|X_{1:t-1})=\prod_{n=1}^N p_\theta(\{z_{t,n}^1,\dots,z_{t,n}^L\}|X_{1:t-1})\\ =\prod_{n=1}^N p_\theta(z_{t,n}^L|h_{t-1,n}^L)\prod_{l=1}^{L-1}p_\theta(z_{t,n}^l|z_{t,n}^{l+1},h_{t-1,n}^l) \tag{6} pθ(Zt∣X1:t−1)=n=1∏Npθ({zt,n1,…,zt,nL}∣X1:t−1)=n=1∏Npθ(zt,nL∣ht−1,nL)l=1∏L−1pθ(zt,nl∣zt,nl+1,ht−1,nl)(6)
-
其中 z t , n l ε R C & h t , n l ε R C z^l_{t,n} ε R^C \& h^l_{t,n} ε R^C zt,nlεRC&ht,nlεRC 分别是 Z t l Z^l_t Ztl 和 H t l H^l_t Htl 的第 n 行。在6式中按照VAE将每一层的先验分布设置为高斯分布,如下
-
p θ ( z t , n l + 1 , h t − 1 , n l ) = N ( μ t l , σ t l ) (7) p_\theta(z_{t,n}^{l+1},h_{t-1,n}^l)=\mathcal N(\mu_t^l,\sigma_t^l) \tag{7} pθ(zt,nl+1,ht−1,nl)=N(μtl,σtl)(7)
-
其中均值 µ t l µ^l_t µtl 和对角协方差 σ t l σ^l_t σtl 由所有位置共享的神经网络 f l ( z t , n l + 1 , h t − 1 , n l ) f^l(z^{l+1}_{t,n}, h^l _{t−1,n}) fl(zt,nl+1,ht−1,nl) 参数化。
-
-
推理阶段(inference):推断模型被应用于近似给定当前和先前步骤的 Z 的后验分布。也就是说,推断模型的作用是根据当前和之前的数据,来预测未知变量 Z 的概率分布。这种方法可以帮助更准确地推断出 Z 的值,从而得到更可靠的结果。后验分布 Z t Z_t Zt计算方式如下
-
q ϕ ( Z t ∣ X 1 : t ) = ∏ n = 1 N q ϕ ( z t , n l ∣ h t , n L ) ∏ l = 1 L − 1 q ϕ ( z t , n l ∣ z t , n l + 1 , h t , n l ) , where q ϕ ( z t , n l ∣ z t , n l + 1 , h t , n l ) = N ( μ ^ t l , σ ^ t l ) (8) q_\phi(\mathcal Z_t|X_{1:t})=\prod_{n=1}^Nq_\phi (z_{t,n}^l|h_{t,n^L})\prod_{l=1}^{L-1}q_\phi (z_{t,n}^{l}|z_{t,n}^{l+1},h_{t,n}^l),\\ \text{where}\quad q_\phi(z_{t,n}^l|z_{t,n}^{l+1},h_{t,n}^l)=\mathcal N(\hat \mu_t^l,\hat \sigma_t^l) \tag{8} qϕ(Zt∣X1:t)=n=1∏Nqϕ(zt,nl∣ht,nL)l=1∏L−1qϕ(zt,nl∣zt,nl+1,ht,nl),whereqϕ(zt,nl∣zt,nl+1,ht,nl)=N(μ^tl,σ^tl)(8)
-
式8采用与式6相同的因式分解方式。每层高斯分布的参数由神经网络 g l ( z t , n l + 1 , h t , n l ) gl(z^{l+1}_{t,n} , h^l_{t,n}) gl(zt,nl+1,ht,nl) 参数化。与生成模型类似,后验分布生成的随机变量也可以有效考虑空气质量的时空依赖性,从而提高预测性能。
-
该阶段分为两个子步骤:自上而下采样以及随机化预测
- 采样阶段,模型会以历史观测数据和先前生成的空气质量指数值作为输入,并使用Decoder来生成一组可能的未来时刻的候选空气质量序列。每个候选序列都是从“起始”标记开始生成的,直到达到预定的预测时间窗口为止。
- 随机化预测阶段,模型会对所有候选空气质量指数序列进行评估,并选择其中最能符合真实未来空气质量指数的序列作为最终的预测结果。这个评估过程基于一个分数函数,它将历史时刻的观测数据、先前生成的空气质量指数值以及每个候选序列的概率分布情况结合起来计算得出。
在Top-Down Stochastic Stage中,每个候选空气质量指数序列都是通过随机采样生成的。这种随机性的引入可以使模型更好地处理未知和噪声数据,从而提高模型的泛化能力和鲁棒性。同时,使用多个候选序列并对它们进行评估,也可以增强模型的表现力和预测准确性。
3.6 预测以及优化
该网络使用确定性参数(自下而上的确定性阶段)以及随机隐性参数(自上而下的随机性阶段)进行预测,使用由两部分组成的损失函数,函数的第一部分为真实值与预测值的L1范数,第二部分为所有阶段的负ELBO之和。其中ELBO由两部分组成,第一部分为重构的似然性,第二部分为KL散度。
4. 文献解读
4.1 Introduction
基于注意力的模型,特别是 Transformer,已成为捕获空气质量数据空间相关性的有力替代方案。与 STGNN 相比,它们有两大优点。首先,它们共同捕捉每一层不同地方之间的短期和长期相互作用,而 STGNN 仅对局部环境进行卷积。其次,不同地点之间空气质量的相关性是高度动态的,随着时间的推移而变化。使用基于注意力的模型自然可以解决这个问题。

在这项研究中,扩大了范围,使用变压器以前所未有的精细空间粒度集体预测中国大陆的空气质量,覆盖数千个站点。如上图所示,预测目标涵盖了中国大陆的所有省份,并且密集分布在珠江三角洲等发达地区。如此精细的覆盖范围不仅为公众提供了更多具有较高社会影响力的有用信息,而且包含了更多有利于模型训练的数据样本
多头自注意力(MSA)是变压器空间建模的关键操作,它的计算复杂度与站点数量 N 呈二次方关系。随着 N 的增长,这种费用可能会变得难以承受,特别是对于细粒度数据。
同时,由于两个因素,未来的空气质量读数本质上是不确定的:观测不准确或缺失,以及一些不可预测的因素。虽然早期的尝试通过确定性方法在空气质量预测方面表现出了良好的性能,但大多数尝试仍然无法捕捉大规模空气质量数据中的这种不确定性。
为了应对这些挑战,提出了一种用于中国全国空气质量预测的新型Transformer架构,名为 AirFormer。该方法受到空气污染领域知识的启发,这使我们能够构建具有更多解释的模型。 AirFormer 将这两个问题的解决方案分为两个阶段:确定性阶段和随机阶段。在确定性阶段,我们提出了两种新型的 MSA 来分别有效地捕获空间和时间依赖性。在随机阶段,我们探索将潜在随机变量包含到变压器中。这些潜在变量是从从确定性隐藏状态学习到的概率分布中采样的,从而捕获输入数据的不确定性。
4.2 创新点
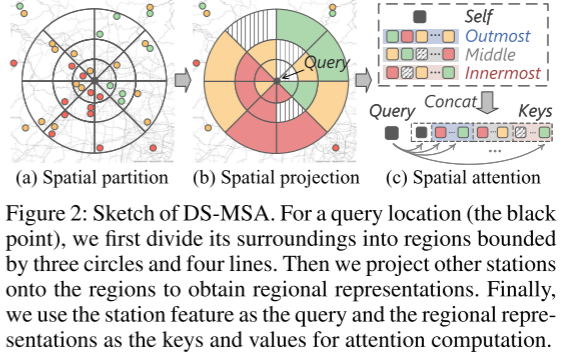
- 考虑到附近位置之间的空间相关性通常比远处位置之间的空间相关性更强,设计了 Dartboard Spatial MSA (DS-MSA) 来有效捕获空间关系。顾名思义,每个位置都以细粒度关注其较近的环境,以粗粒度关注较远的站点(见上图)。与具有二次成本的标准 MSA 相比,DS-MSA 仅采用与站点数量相关的线性复杂度。
- 设计了因果时间 MSA (CT-MSA) 来学习时间依赖性。它确保步骤的输出仅源自先前的步骤,即因果关系。还引入了局部性来提高效率,每层的感受野像卷积一样逐渐增加。
- 利用变分模型的最新进展,通过潜在变量增强了变压器,以捕获空气质量数据的不确定性。为了保持变压器的并行性,潜在随机变量按照隐式时间依赖性分层排列。
- 这是第一个对数千个地点的空气质量进行集体预测的工作。实证结果表明,AirFormer 的预测误差比现有模型低 4.6%-8.2%。
4.3 实验过程
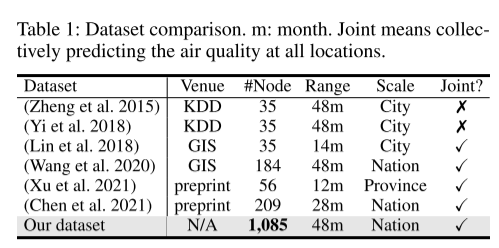
1. 数据集
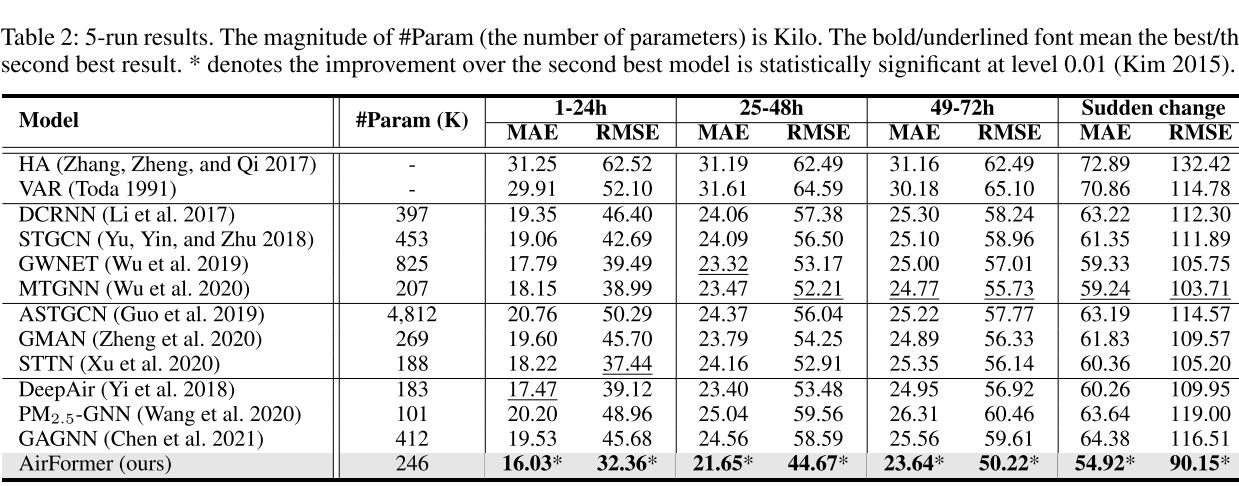
2. 比较的基线模型
评估指标选择:MAE和RMSE
- 传统方法
- STGNN变体
- 基于注意力机制的模型
- 空气质量预测模型
运行结果如下
3. 消融实验
DS-MSA的性能
对比了没有DS-MSA,标准的MSA,MSA(50km),DS-MSA(50-200),DS-MSA(50),DS-MSA(50-200-500)。灰色行表示最终的模型,加粗为最好,横线表示性能第二好的。
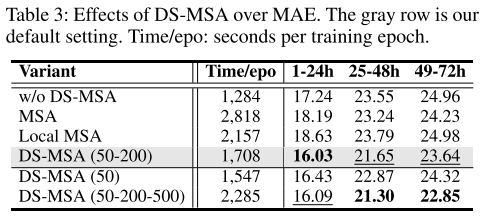
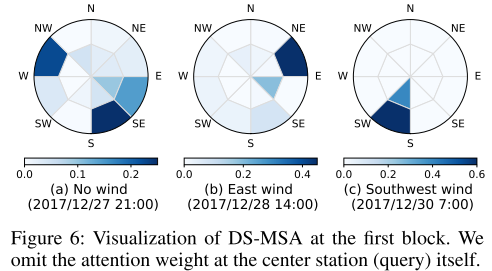
此外为了验证DS-MSA的性能,对以西直门为中心的50-200的dartboard进行研究,当没有风的时候,权重被分散,如果有来自东风或者西南风,注意力的权重会集中在相应的方向上,这说明DS-MSA不但有效,而且对于模型的可解释性也更强。
CT-MSA的性能
对比了没有CT-MSA,WaveNet取代CT-MSA,标准的MSA。首先可以看到所有具有时间模块变体的模型性能都比没有CT-MSA的性能好,这一现象说明根据时间建模的必要性,此外,两个使用锁头注意力机制的模型性能比WaveNet的性能好,说明了MSA在空气质量预测的优越性。此外,将英国关系和局部窗口集成到MSA可以持续提高性能

隐变量的性能
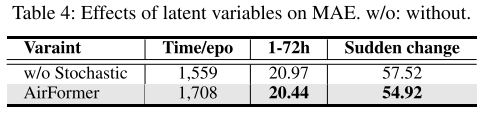
因为气体扩散的随机性,捕获空气质量数据中的不确定性可以有效的提高性能,增强模型的鲁棒性。
位置编码的性能
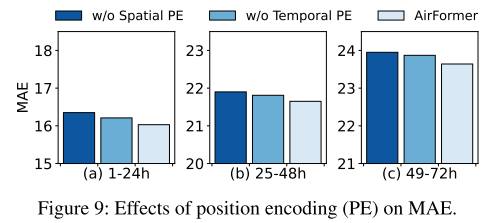
由于MSA是排列不变的,作者将位置编码集成到DS-MSA和CT-MSA中,用来考虑顺序信息
4.4 结论
- 考虑到附近区域的空间对该区域的相关性要大于遥远区域的相关性,设计了DS-MSA有效捕获位置空间关系
- 设计了因果时间模块CT-MSA学习时间依赖性,确保每一个步骤的输出只来自前面的步骤。引入局部性来提高效率
- 使用VAE模型的思想,增强了具有隐变量的transformer,以此捕获空气质量数据的不确定性
- 是第一次共同预测数千个地点的空间质量的工作,比现有的SOTA误差低4-8个百分点。
三、GAN
1. 任务要求
使用pytorch实现GAN网络,并使用MNIST数据库训练GAN,GAN绘制手写数字图片。其中,GAN使用MLP构建
2. 实验结果
GAN进行十九次迭代后的绘制效果

3.实验代码
3.1数据准备
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
import torchvision
from torchvision import transforms
# 数据准备
# 对数据做归一化 (-1, 1)
transform = transforms.Compose([
transforms.ToTensor(), # 将数据转换成Tensor格式,channel, high, witch,数据在(0, 1)范围内
transforms.Normalize(0.5, 0.5) # 通过均值和方差将数据归一化到(-1, 1)之间
])
# 下载数据集
train_ds = torchvision.datasets.MNIST('data',
train=True,
transform=transform,
download=True)
# 设置dataloader
dataloader = torch.utils.data.DataLoader(train_ds, batch_size=64, shuffle=True)
# 返回一个批次的数据
imgs, _ = next(iter(dataloader))
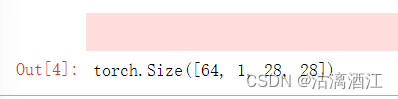
# imgs的大小
imgs.shape
3.2 模型构建
# 定义生成器
# 输入是长度为 100 的 噪声(正态分布随机数)
# 输出为(1, 28, 28)的图片
# linear 1 : 100----256
# linear 2: 256----512
# linear 2: 512----28*28
# reshape: 28*28----(1, 28, 28)
class Generator(nn.Module): #创建的 Generator 类继承自 nn.Module
def __init__(self): # 定义初始化方法
super(Generator, self).__init__() #继承父类的属性
self.main = nn.Sequential( #使用Sequential快速创建模型
nn.Linear(100, 256),
nn.ReLU(),
nn.Linear(256, 512),
nn.ReLU(),
nn.Linear(512, 28*28),
nn.Tanh() # 输出层使用Tanh()激活函数,使输出-1, 1之间
)
def forward(self, x): # 定义前向传播 x 表示长度为100 的noise输入
img = self.main(x)
img = img.view(-1, 28, 28) #将img展平,转化成图片的形式,channel为1可写可不写
return img
# 定义判别器
## 输入为(1, 28, 28)的图片 输出为二分类的概率值,输出使用sigmoid激活 0-1
# BCEloss计算交叉熵损失
# nn.LeakyReLU f(x) : x>0 输出 x, 如果x<0 ,输出 a*x a表示一个很小的斜率,比如0.1
# 判别器中一般推荐使用 LeakyReLU
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.main = nn.Sequential(
nn.Linear(28*28, 512), #输入是28*28的张量,也就是图片
nn.LeakyReLU(), # 小于0的时候保存一部分梯度
nn.Linear(512, 256),
nn.LeakyReLU(),
nn.Linear(256, 1), # 二分类问题,输出到1上
nn.Sigmoid()
)
def forward(self, x):
x = x.view(-1, 28*28)
x = self.main(x)
return x
3.3 展示函数
# 绘图函数
def gen_img_plot(model, epoch, test_input):
prediction = np.squeeze(model(test_input).detach().cpu().numpy())
fig = plt.figure(figsize=(4, 4))
for i in range(16):
plt.subplot(4, 4, i+1)
plt.imshow((prediction[i] + 1)/2) # 确保prediction[i] + 1)/2输出的结果是在0-1之间
plt.axis('off')
plt.show()
test_input = torch.randn(16, 100, device=device)
3.4 训练过程
# GAN的训练
# 保存每个epoch所产生的loss值
D_loss = []
G_loss = []
# 训练循环
for epoch in range(20): #训练20个epoch
d_epoch_loss = 0 # 初始损失值为0
g_epoch_loss = 0
# len(dataloader)返回批次数,len(dataset)返回样本数
count = len(dataloader)
# 对dataloader进行迭代
for step, (img, _) in enumerate(dataloader): # enumerate加序号
img = img.to(device) #将数据上传到设备
size = img.size(0) # 获取每一个批次的大小
random_noise = torch.randn(size, 100, device=device) # 随机噪声的大小是size个
d_optim.zero_grad() # 将判别器前面的梯度归0
real_output = dis(img) # 判别器输入真实的图片,real_output是对真实图片的预测结果
# 得到判别器在真实图像上的损失
# 判别器对于真实的图片希望输出的全1的数组,将真实的输出与全1的数组进行比较
d_real_loss = loss_fn(real_output,
torch.ones_like(real_output))
d_real_loss.backward() # 求解梯度
gen_img = gen(random_noise)
# 判别器输入生成的图片,fake_output是对生成图片的预测
# 优化的目标是判别器,对于生成器的参数是不需要做优化的,需要进行梯度阶段,detach()会截断梯度,
# 得到一个没有梯度的Tensor,这一点很关键
fake_output = dis(gen_img.detach())
# 得到判别器在生成图像上的损失
d_fake_loss = loss_fn(fake_output,
torch.zeros_like(fake_output))
d_fake_loss.backward() # 求解梯度
d_loss = d_real_loss + d_fake_loss # 判别器总的损失等于两个损失之和
d_optim.step() # 进行优化
g_optim.zero_grad() # 将生成器的所有梯度归0
fake_output = dis(gen_img) # 将生成器的图片放到判别器中,此时不做截断,因为要优化生成器
# 生层器希望生成的图片被判定为真
g_loss = loss_fn(fake_output,
torch.ones_like(fake_output)) # 生成器的损失
g_loss.backward() # 计算梯度
g_optim.step() # 优化
# 将损失累加到定义的数组中,这个过程不需要计算梯度
with torch.no_grad():
d_epoch_loss += d_loss
g_epoch_loss += g_loss
# 计算每个epoch的平均loss,仍然使用这个上下文关联器
with torch.no_grad():
# 计算平均的loss值
d_epoch_loss /= count
g_epoch_loss /= count
# 将平均loss放入到loss数组中
D_loss.append(d_epoch_loss.item())
G_loss.append(g_epoch_loss.item())
# 打印当前的epoch
print('Epoch:', epoch)
# 调用绘图函数
gen_img_plot(gen, epoch, test_input)
小结
本周阅读的论文提出了一种名为 AirFormer 的新型 Transformer 架构,用于集体预测中国全国范围内的空气质量,并以前所未有的精细空间粒度覆盖数千个地点。 AirFormer 将学习过程解耦为两个阶段
1)自下而上的确定性阶段,包含两种新型的自注意力机制,可有效学习时空表示;
2)具有潜在变量的自上而下的随机阶段,用于捕获空气质量数据的内在不确定性。
参考文献
[1] Yuxuan Liang, Yutong Xia, Songyu Ke, Yiwei Wang, Qingsong Wen, Junbo Zhang, Yu Zheng, Roger Zimmermann: AirFormer: Predicting Nationwide Air Quality in China with Transformers.[J].arXiv:2211.15979v1