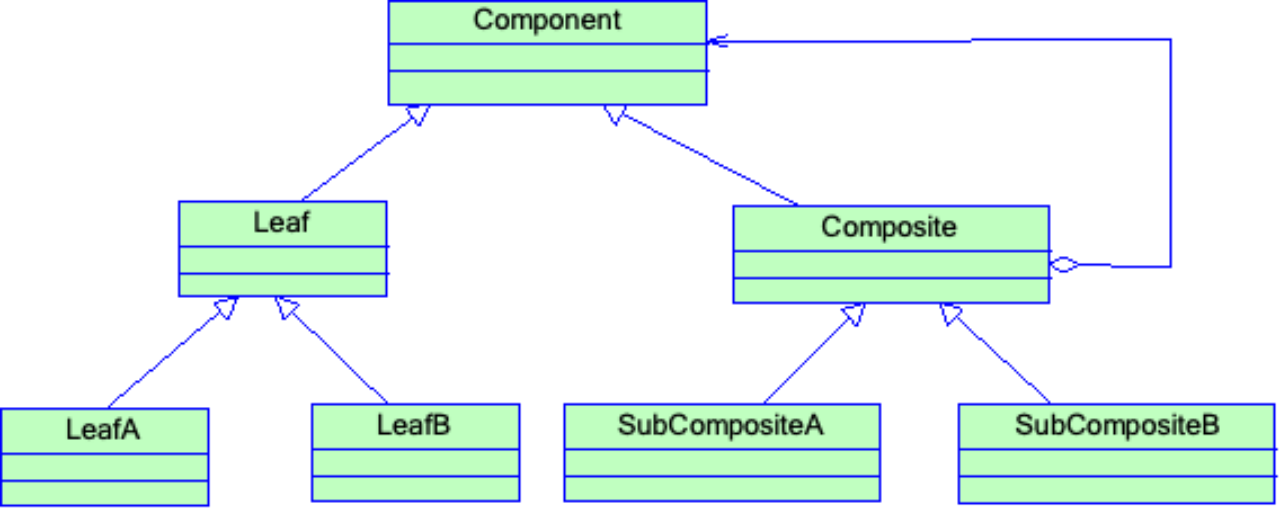
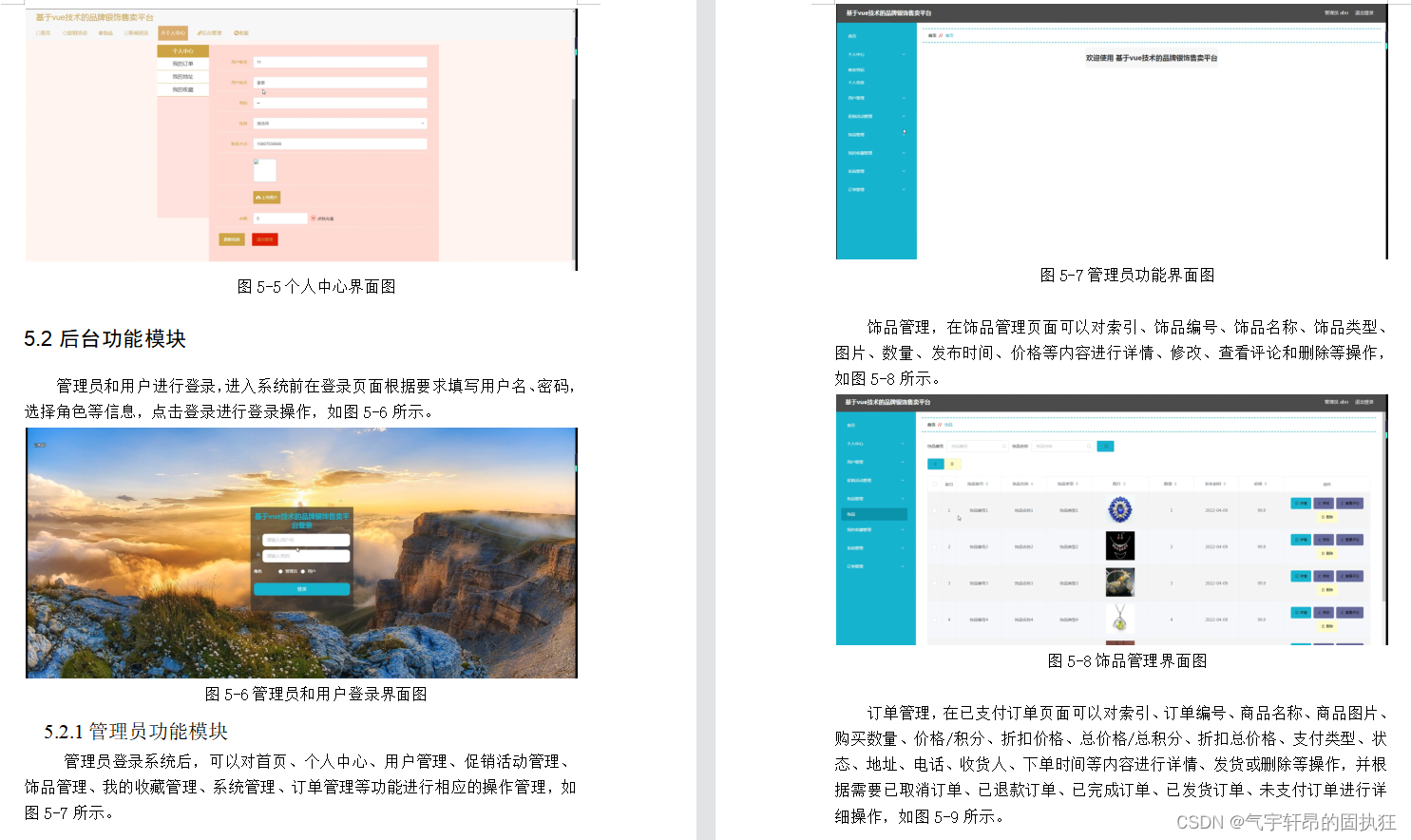
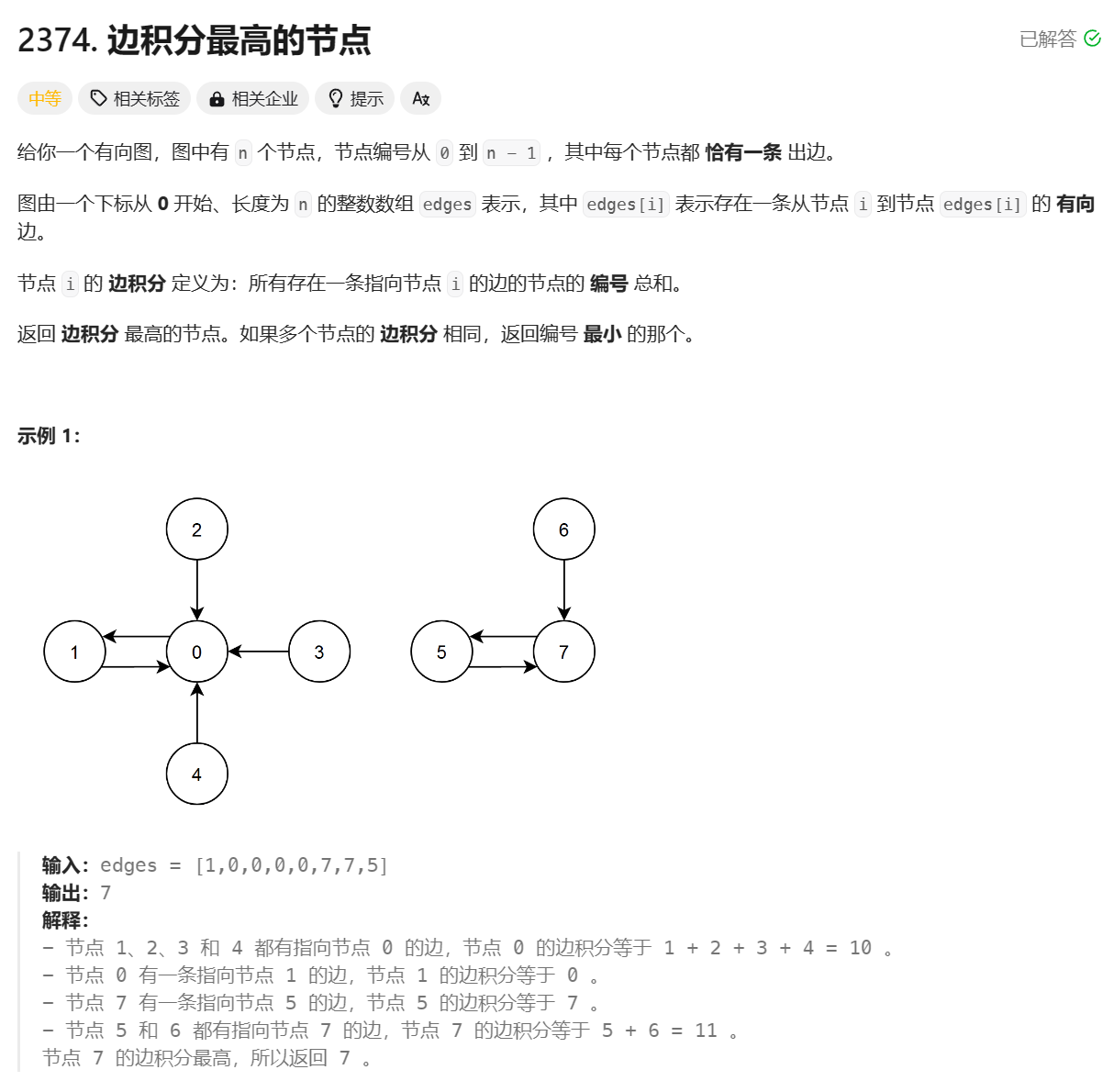
引言:揭示视觉Transformer的解释挑战
在计算机视觉应用中,Transformer模型的流行度迅速上升,但对其内部机制的后置解释仍然是一个未探索的领域。视觉Transformers通过将图像区域表示为转换后的tokens,并通过注意力权重将它们整合起来来提取视觉信息。然而,现有的后置解释方法仅考虑这些注意力权重,忽略了转换tokens中的关键信息,这无法准确地展示模型预测背后的逻辑。为了将token转换的影响纳入解释中,我们提出了TokenTM,这是一种新颖的后置解释方法,它利用我们引入的token转换效应的度量。具体来说,我们通过测量token长度的变化和它们方向上的相关性来量化token转换效应。此外,我们开发了初始化和聚合规则,以跨所有层次整合注意力权重和token转换效应,捕获模型中整体token的贡献。实验结果表明,我们提出的TokenTM在分割和扰动测试中的性能优于现有的最先进的视觉Transformer解释方法。
论文标题:Token Transformation Matters: Towards Faithful Post-hoc Explanation for Vision Transformer
作者与机构:Junyi Wu, Bin Duan, Weitai Kang, Hao Tang, Yan Yan - Department of Computer Science, Illinois Institute of Technology, USA; Robotics Institute, Carnegie Mellon University, USA
论文链接:https://arxiv.org/pdf/2403.14552.pdf
公众号【AI论文解读】后台回复“论文解读” 获取论文PDF!
概述视觉Transformer的内部机制及其解释性问题
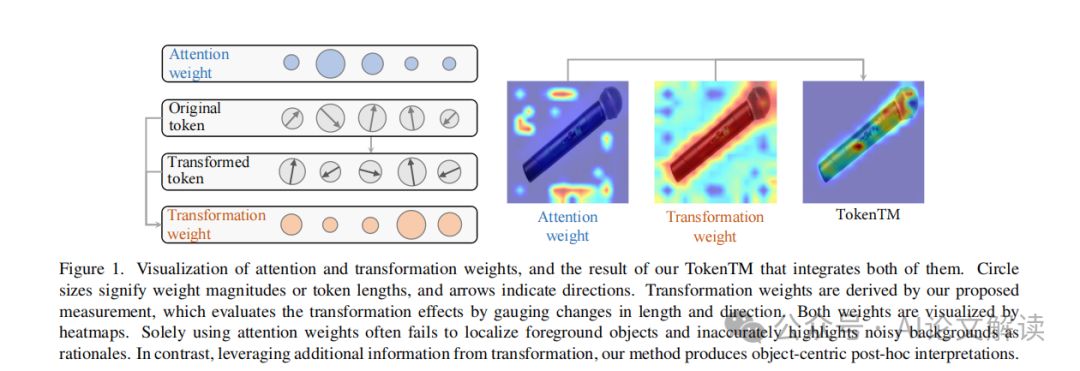
视觉Transformer是一种在计算机视觉应用中迅速流行的模型,它通过将图像区域表示为转换后的tokens,并通过注意力权重将它们整合起来来提取视觉信息。然而,对于这些模型内部机制的后置解释仍然是一个未探索的领域。现有的后置解释方法主要考虑注意力权重,忽略了转换后tokens中的关键信息,这导致无法准确揭示模型预测背后的逻辑。例如,即使某些背景区域通过高注意力权重进行了放大,如果它们被转换成更小或方向发散的tokens,它们的实际贡献可能会减少。相反,一个前景对象,尽管接收到的注意力权重很小,但由于在模型内部发生了显著的转换,它可能在预测中扮演了关键角色。因此,需要一种全面的解释方法来同时解决注意力权重和token转换这两个因素。
提出TokenTM:一种新的后置解释方法
1. TokenTM的核心思想:整合注意力权重与Token变换效应
TokenTM是一种新的后置解释方法,它的核心思想是将注意力权重与token变换效应结合起来。TokenTM通过引入token变换效应的度量来实现这一点,具体来说,通过测量token长度和方向的变化来量化token变换效应。此外,TokenTM还开发了初始化和聚合规则,以跨所有层整合注意力权重和token变换效应,捕捉模型整体的token贡献。
2. Token变换的度量:长度和方向的变化
TokenTM通过两个基本属性来衡量token变换的影响:长度和方向。长度函数L(x)用于测量token的长度,通常使用L2范数来实例化。方向函数C(x, (cid:101)x)使用余弦相似度来量化方向上的相关性。TokenTM将这两个组件结合起来,定义了转换权重W,这些权重反映了原始信息在转换后tokens中保留或改变的程度,以真实评估它们的贡献。
3. 跨层聚合框架:捕捉模型整体Token贡献
TokenTM引入了一个聚合框架,用于跨整个模型衡量上下文化和转换的综合影响。整体贡献图C由tokens的数量n决定,其中Cij累积了第j个输入token对第i个输出token的影响。在模型的初始状态,每个输入token仅包含自身,没有经过上下文化或转换。聚合框架使用输入tokens的长度进行初始化,并使用更新映射Ul追踪tokens在层间的演变。最终,通过提取与[CLS] token相关的行并将其重塑为图像的空间维度,形成了最终的解释热图,突出了对预测结果影响最大的区域。
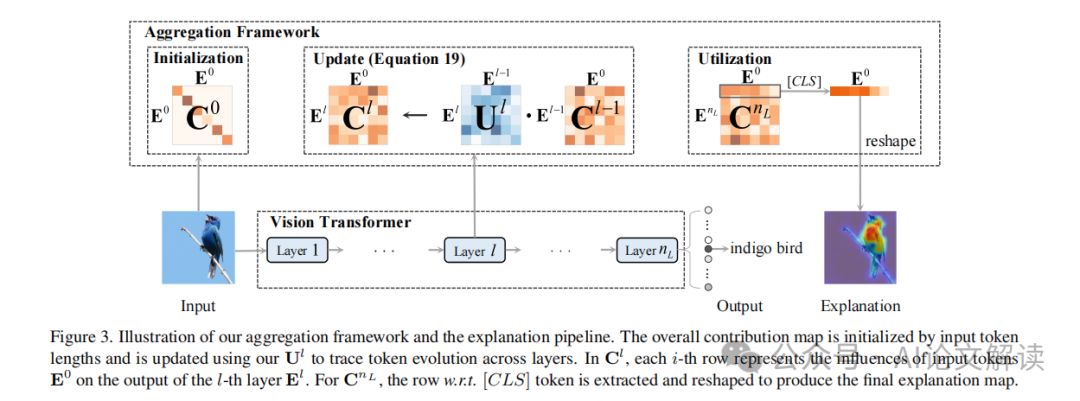
实验设计与评估方法
1. 基线方法:与现有技术的比较
在进行实验设计时,我们首先确定了一系列基线方法,以便与我们提出的TokenTM方法进行比较。这些基线方法包括广泛使用的三种类型:(i) 基于梯度的方法,如Grad-CAM [37];(ii) 基于归因的方法,如LRP [9]、Conservative LRP [3]和Transformer Attribution [13];以及(iii) 基于注意力的方法,如Raw Attention [26]、Rollout [1]、ATTCAT [35]和GAE [12]。
2. 评估属性:定位能力、对准确性的影响、对概率的影响
在评估方法的设计中,我们关注了三个主要属性:
- 定位能力:这一属性评估解释方法在定位模型识别的前景对象方面的效果。理想情况下,一个可靠的解释应该是以对象为中心的,即准确突出模型用于做出决策的对象。
- 对准确性的影响:这一方面关注解释如何捕捉像素与模型准确性之间的相关性。我们通过在CIFAR-10、CIFAR-100 [28]和ImageNet [36]上进行扰动测试来评估这一属性。
- 对概率的影响:这一属性进一步衡量解释如何捕捉模型预测概率中重要像素的效果。同样,通过扰动测试来评估,并在ViT-B和ViT-L [17]上报告结果。
实验结果与分析
1. 定性评估:TokenTM的解释热图更为精确
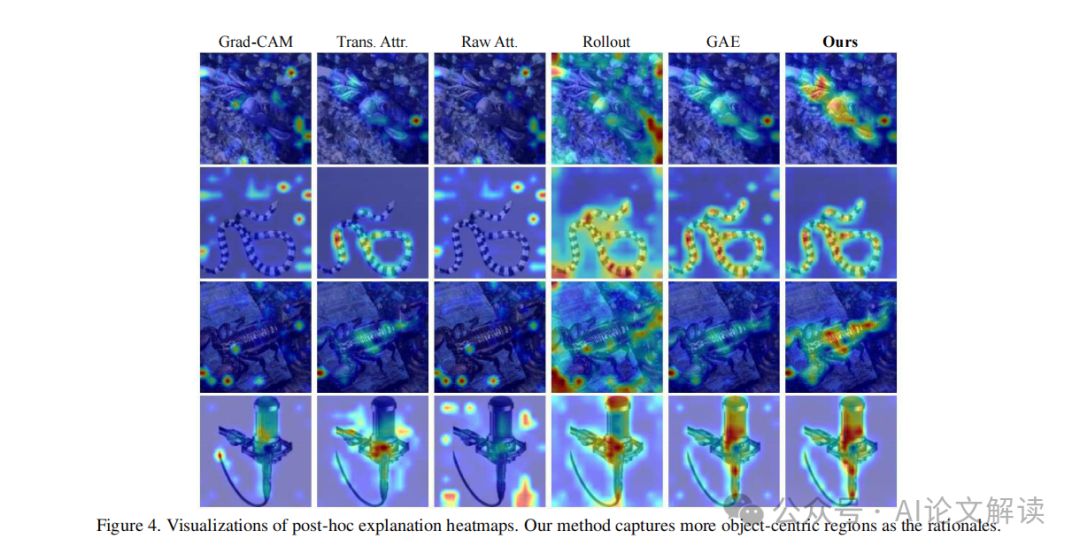
在定性评估中,我们通过可视化解释热图来展示TokenTM的效果。如图4所示,TokenTM的解释热图更加精确和详尽,与仅使用注意力权重的方法相比,TokenTM有效地消除了噪声区域,提供了更以对象为中心的分析。
2. 定量评估:TokenTM在各项指标上的表现
在定量评估方面,我们的TokenTM在多个指标上表现出色:
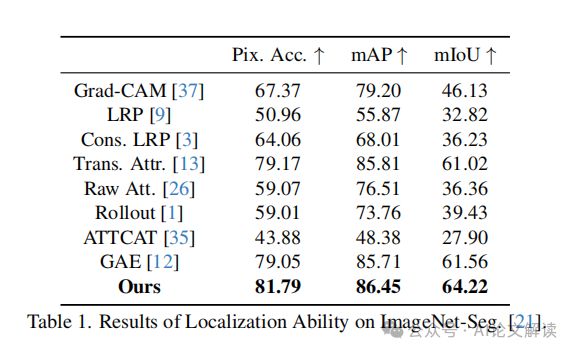
定位能力:在ImageNet-Segmentation数据集上的分割结果(表1)显示,TokenTM在像素精度、平均交并比(mIoU)和平均精度(mAP)上显著优于所有基线方法,证明了其更强的定位能力。
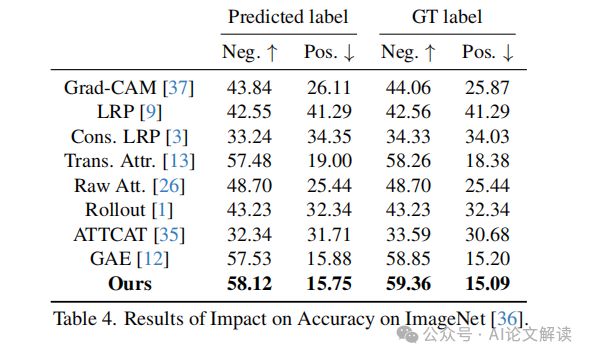
对准确性的影响:在CIFAR-10、CIFAR-100和ImageNet上的扰动测试结果(表2、表3和表4)表明,TokenTM在正面和负面测试中均优于基线方法。在正面测试中,较低的AUC指标表明性能更好;而在负面测试中,较高的AUC则更为理想。

对概率的影响:在ViT-B和ViT-L模型上的扰动测试结果(表5)显示,TokenTM在AOPC和Log-odds分数(LOdds)上的表现突出,这些指标量化了输出概率相对于预测标签的平均变化。

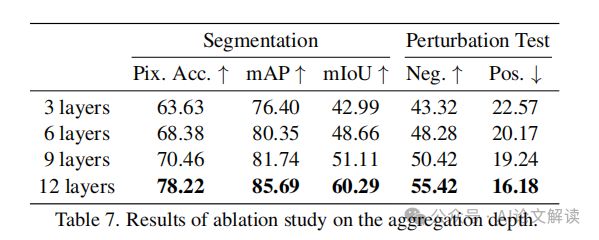
此外,我们还进行了消融研究,以验证所提出的转换测量(长度L和归一化指数余弦相关性NECC)和聚合框架(AF)的效果(表6)。结果表明,每个提出的组件都在视觉变换器解释上提高了性能。我们还研究了聚合深度对TokenTM性能的影响(表7),结果表明,随着聚合层数的增加,性能稳步提升,这表明深层聚合对于捕捉模型推理的真实理由至关重要。

消融实验:验证提出组件的有效性
1. 提出组件的消融研究:L和NECC的影响
在进行消融实验时,研究者们关注了提出的TokenTM方法中两个关键组件——长度函数L和归一化指数余弦相关性(NECC)——对模型解释性的影响。长度函数L通过计算嵌入空间中的L2范数来衡量原始或变换后的token的长度。NECC则用于量化变换后的token与其原始对应token之间的方向相关性,采用余弦相似度来衡量两个token之间的角度。
消融研究的结果表明,每个提出的组件都能够提高模型在图像分割和扰动测试中的性能,这验证了它们在视觉Transformer解释中的有效性。具体来说,当仅使用基线方法(即不应用提出的组件)时,性能是最低的。随着逐步引入长度函数L和NECC,性能得到了显著提升,这表明这两个组件对于捕捉Transformer层中token变换的影响至关重要。
2. 聚合深度的消融研究:深度对解释性的影响
研究者们还探讨了聚合深度对TokenTM方法解释性的影响。通过逐渐增加模型中被聚合的层数,从最初的几层到整个网络的深度,他们观察到性能的持续提升。这一发现表明,深层聚合token变换和上下文化效应对于捕捉模型推理过程中的真实逻辑至关重要。随着聚合包含更多层,解释性热图逐渐细化并更集中于模型识别的对象,从而更精确地定位了模型预测背后的理由。
总结与展望:TokenTM方法的意义与未来研究方向
TokenTM方法通过引入token变换测量和跨所有层的聚合框架,为视觉Transformer的解释提供了一个新的视角。它不仅考虑了注意力权重,还考虑了token变换的影响,从而生成了更忠实的后验解释。实验结果表明,TokenTM在定位能力、准确性影响和概率影响方面均优于现有的最先进方法。
未来的研究可以在几个方向上进行拓展。首先,TokenTM方法可以应用于其他类型的Transformer模型,如自然语言处理或音频处理中的模型,以验证其泛化能力。其次,可以进一步探索token变换的其他属性,如形状或纹理,以提高解释性。最后,可以研究如何将TokenTM与其他解释性方法结合,以提供更全面的模型解释。随着对模型透明度和可解释性需求的增加,TokenTM及其未来的改进将在提高人们对复杂机器学习模型决策的信任中发挥重要作用。