学习了mysql函数,接下来学习mysql基本查询。
1,基本查询语句
MySQL从数据表中查询数据的基本语句为SELECT 语句。SELECT语句的基本格式是:
SELECT
(*I <字段列表>}
FROM <表1>,<表2>..
[WHERE<表达式>
[GROUP BY <group by definition>]
[HAVING <expression> [<operator> <expression>)...]]
[ORDER BY <order by definition>]
[LIMIT[<offset>,] <row count>]
]
SELECT [字段1,字段2,...,字段n]
FROM [表或视图]
WHERE[查询条件];其中,各条子句的含义如下:
{*|<字段列表>}包含星号通配符选择字段列表,表示查询的字段,其中字段列至少包含一个字段名称,如果要查询多个字段,多个字段之间用逗号隔开,最后一个字段后不要加逗号。
FROM<表1>,<表2>...,表1和表2表示查询数据的来源,可以是单个或者多个。
WHERE子句是可选项,如果选择该项,将限定查询行必须满足的查询条件。
GROUP BY<字段>,该子句告诉MySQL如何显示查询出来的数据,并按照指定的字段分组。
[ORDER BY<字段>],该子句告诉MySQL按什么样的顺序显示查询出来的数据,可以进行的排序有:升序(ASC)、降序(DESC)
[LIMIT[<offset>,] <row count>],该子句告诉MySQL每次显示查询出来的数据条数。SELECT的可选参数比较多,可能无法一下完全理解,不要紧,接下来将从最简单的开始,一步一步深入学习之后,会对各个参数的作用有清晰的认识。
下面以一个例子说明如何使用SELECT从单个表中获取数据。
首先定义数据表,输入语句如下:
CREATE TABLE fruits
(
f_id char(10) NOT NULL,
s_id INT NOT NULL,
f_name char(255) NOT NULL,
f_price decimal(8,2) NoT NULL,
PRIMARY KEY(f_id)
);需要插入如下数据:
INSERT INTO fruits (f_id, s_id, f_name, f_price)
VALUES('a1', 101, 'apple', 5.2),
('b1', 101, 'blackberry', 10.2),
('bsl', 102, 'orange', 11.2),
('bs2', 105, 'melon', 8.2),
('t1', 102, 'banana', 10.3),
('t2', 102,'grape', 5.3),
('o2', 103, 'coconut', 9.2),
('c0', 101, 'cherry', 3.2),
('a2', 103, 'apricot',2.2),
('12', 104, 'lemon', 6.4),
('b2', 104, 'berry', 7.6),
('m1', 106, 'mango', 15.7),
('m2', 105, 'xbabay', 2.6),
('t4', 107, 'xbababa', 3.6),
('m3', 105, 'xxtt', 11.6),
('b5',107, 'xxxX', 3.6);使用SELECT语句查询f_id和l f_name字段的数据。
SELECT f_id, f_name FROM fruits;该语句的执行过程是,SELECT语句决定了要查询的列值,在这里查询f_id和f_name两个字段的值,FROM子句指定了数据的来源,这里指定数据表 fruits,因此返回结果为 fruits表中f_id和f_name两个字段下所有的数据。其显示顺序为添加到表中的顺序。
2,单表查询
单表查询是指从一张表数据中查询所需的数据。本节将介绍单表查询中的各种基本的查询方式,主要有:查询所有字段、查询指定字段、查询指定记录、查询空值、多条件的查询、对查询结果进行排序等。
1,查询所有字段
1.在SELECT语句中使用星号(*)通配符查询所有字段
SELECT查询记录最简单的形式是从一个表中检索所有记录,实现的方法是使用星号(*)通配符指定查找所有列的名称。语法格式如下:
SELECT * FROM 表名;【例1】从fruits表中检索所有字段的数据,SQL语句如下:
SELECT * FROM fruits;可以看到,使用星号(*)通配符时,将返回所有列,列按照定义表时候的顺序显示。2.在SELECT语句中指定所有字段
下面介绍另外一种查询所有字段值的方法。根据前面SELECT 语句的格式,SELECT关键字后面的字段名为将要查找的数据,因此可以将表中所有字段的名称跟在SELECT子句后面,如果忘记了字段名称,可以使用DESC命令查看表的结构。有时候,由于表中的字段可能比较多,不一定能记得所有字段的名称,因此该方法会很不方便,不建议使用。例如查询fruits表中的所有数据,SQL语句也可以书写如下,
SELECT f_id, s_id, f_name, f_price FROM fruits;查询结果与【例1】相同。
一般情况下,除非需要使用表中所有的字段数据,最好不要使用通配符‘*’。使用通配符虽然可以节省输入查询语句的时间,但是获取不需要的列数据通常会降低查询和所使用的应用程序的效率。通配符的优势是,当不知道所需要的列的名称时,可以通过它获取它们。
2,查询指定字段
1,查询单个字段
查询表中的某一个字段,语法格式为:
SELECT 列名 FROM 表名;【例2】查询fruits表中 f_name列所有水果名称,SQL语句如下:
SELECT f_name FROM fruits;该语句使用SELECT 声明从fruits表中获取名称为f_name字段下的所有水果名称,指定字段的名称紧跟在SELECT 关键字之后,查询结果如下:
输出结果显示了fruits表中 f_name字段下的所有数据。
2,查询多个字段
使用SELECT声明,可以获取多个字段下的数据,只需要在关键字SELECT后面指定要查找的字段的名称,不同字段名称之间用逗号(,)分隔开,最后一个字段后面不需要加逗号,语法格式如下:
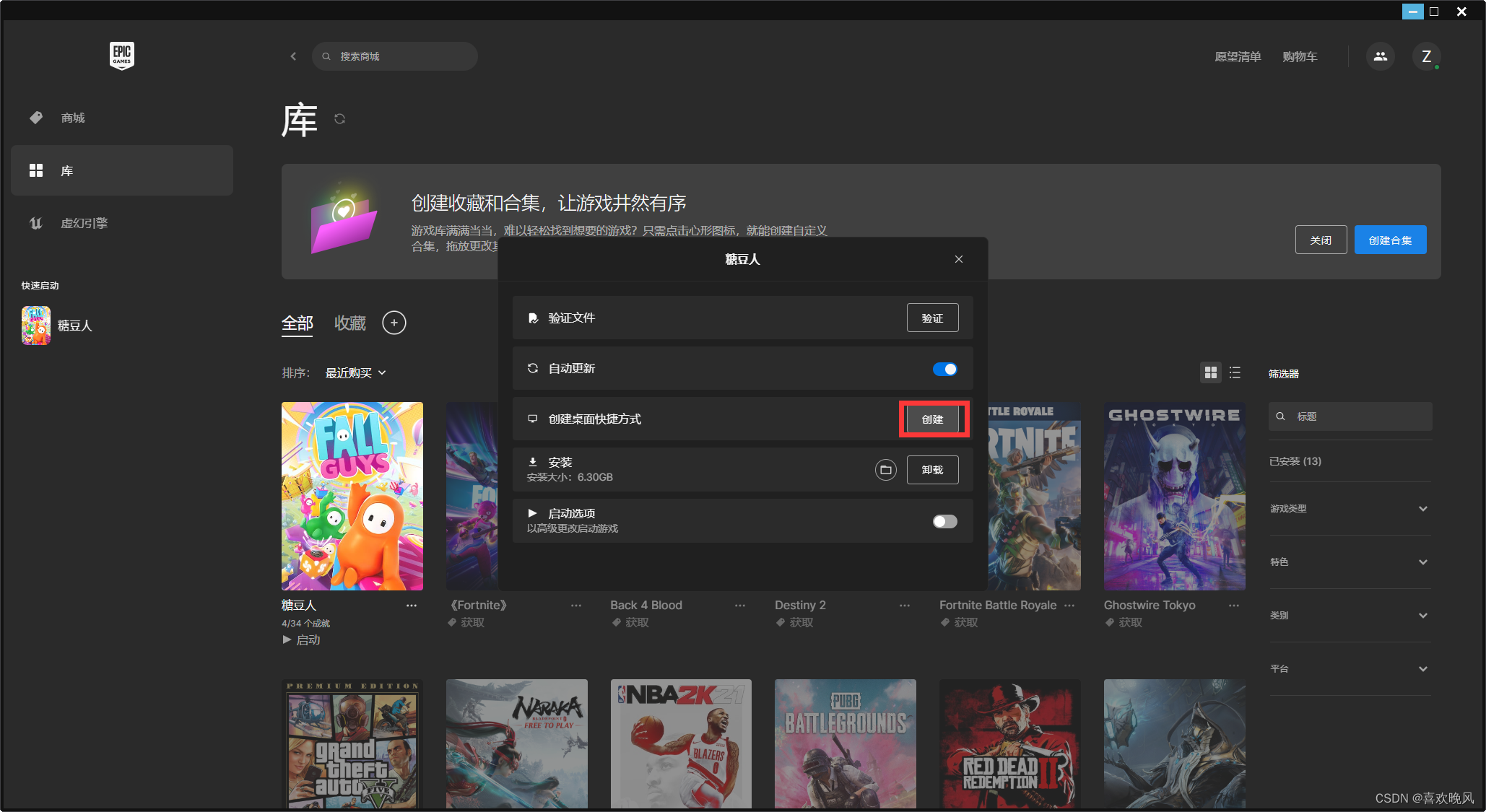
SELECT 字段名1,字段名2,, 字段名n FROM 表名;【例3】例如,从fruits表中获取f_name和 f_price两列,SQL语句如下:
SELECT f_name, f_price FROM fruits;该语句使用SELECT声明从fruits表中获取名称为f_name和 f _price两个字段下的所有水果名称和价格,两个字段之间用逗号分隔开,查询结果如下:
输出结果显示了fruits表中f_name和 f_price两个字段下的所有数据。
提示:MySQL中的SQL语句是不区分大小写的,因此 SELECT和 select 作用是相同的,但是,许多开发人员习惯将关键字使用大写,而数据列和表名使用小写,平时也应该养成一个良好的编程习惯,这样写出来的代码更容易阅读和维护。
3,查询指定记录
数据库中包含大量的数据,根据特殊要求,可能只需要查询表中的指定数据,即对数据进行过滤。在SELECT语句中,通过WHERE子句可以对数据进行过滤,语法格式为:
SELECT 字段名1, 字段名2, 字段名n
FROM 表名
WHERE 查询条件;在WHERE子句中,MySQL提供了一系列的条件判断符,查询结果如表1所示。
表1 WHERE条件判断符
| 操作符 | 说明 |
| = | 相等 |
| <>,!= | 不相等 |
| < | 小于 |
| <= | 小于或者等于 |
| > | 大于 |
| >= | 大于或者等于 |
| BETWEEN | 位于两值之间 |
【例4】查询价格为10.2元的水果的名称,SQL语句如下:
SELECT f_name, f_price
FROM fruits
WHERE f_price = 10.2;该语句使用SELECT声明从fruits表中获取价格等于10.2的水果的数据,从查询结果可以看到,价格是10.2的水果的名称是blackberry,其他的均不满足查询条件,查询结果如下:

本例采用了简单的相等过滤,查询一个指定列f _price具有值10.20。相等还可以用来比较字符串,如下:
【例5】查找名称为“apple”的水果的价格,SQL语句如下:
SELECT f_name, f_price
FROM fruits
WHERE f_name = 'apple';该语句使用SELECT 声明从fruits表中获取名称为“apple”的水果的价格从查询结果可以看到只有名称为“apple”行被返回,其他的均不满足查询条件。

【例6】查询价格小于10的水果的名称,SQL语句如下:
SELECT f_name, f_price
FROM fruits
WHERE f_price < 10;该语句使用SELECT 声明从fruits表中获取价格低于10的水果名称,即f _price小于10的水果信息被返回,查询结果如下:

可以看到查询结果中,所有记录的f_price字段的值均小于10.00元。而大于或等于10.00元的记录没有被返回。
4,带IN关键字的查询
IN操作符用来查询满足指定范围内的条件的记录,使用IN操作符,将所有检索条件用括
号括起来,检索条件之间用逗号分隔开,只要满足条件范围内的一个值即为匹配项。
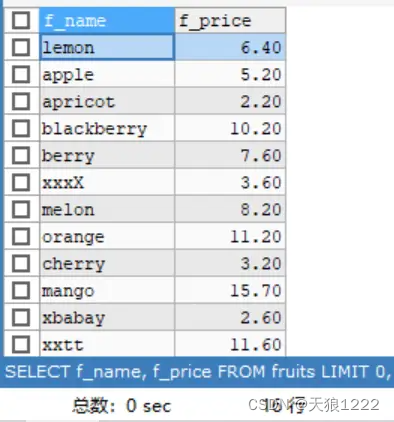
【例7】查询s_id 为 101和102的记录,SQL语句如下:
SELECT f_id, f_name, f_price
FROM fruits
where s_id IN (101,102)
ORDER BY f_name;查询结果如下;
相反的,可以使用关健字NOT来检索不在条件范围内的记录。
【例8】查询所有s_id不等于10I也不等于102的记录。SQL语句如下
SELECT f_id, f_name, f_price
FROM fruits
where s_id NOT IN (101,102)
ORDER BY f_name;查询结果如下:

可以看到,该语句在N关键字前面加上了NOT关键字,这使得查询的结果与前面一个的结果正好相反,前面检索了s_id等于 101和 102的记录,而这里所要求的查询的记录中的s_id字段值不等于这两个值中的任何一个。
5,带BETWEEN AND的范围查询
BETWEEN AND用来查询某个范围内的值,该操作符需要两个参数,即范围的开始值和结束值,如果字段值满足指定的范围查询条件,则这些记录被返回。
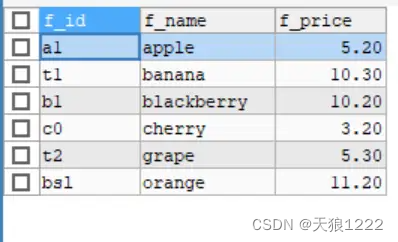
【例9】查询价格在2.00元到10.20元之间的水果名称和价格,SQL语句如下:
SELECT f_name, f_price
FROM fruits
where f_price BETWEEN 2.00 AND 10.20;查询结果如下:
可以看到,返回结果包含了价格从2.00元到10.20元之间的字段值。并且端点值10.20也包括在返回结果中,即 BETWEEN匹配范围中所有值,包括开始值和结束值。
BETWEEN AND操作符前可以加关键字NOT,表示指定范围之外的值,如果字段值不满足指定的范围内的值,则这些记录被返回。
【例10】查询价格在2.00元到10.20元之外的水果名称和价格,SQL语句如下:
SELECT f_name, f_price
FROM fruits
where f_price NOT BETWEEN 2.00 AND 10.20;查询结果如下:

由结果可以看到,返回的记录只有f _price字段大于10.20的,其实,f_price字段小于2.00的记录也满足查询条件。因此,如果表中有f price字段小于2.00 的记录,也应当作为查询结果。
6,带LIKE的字符匹配查询
在前面的检索操作中,讲述了如何查询多个字段的记录,如何进行比较查询或者是查询一个条件范围内的记录,如果要查找所有的包含字符“ge”的水果名称,该如何查找呢?﹖简单的比较操作在这里已经行不通了,在这里,需要使用通配符进行匹配查找,通过创建查找模式对表中的数据进行比较。执行这个任务的关键字是LIKE。
通配符是一种在SQL 的WHERE条件子句中拥有特殊意思的字符,SQL语句中支持多种通配符,可以和LIKE一起使用的通配符有‘%’和‘_’。
1,百分号通配符‘%’,匹配任意长度的字符,甚至包括零字符
【例11】查找所有以‘b’字母开头的水果,SQL语句如下:
SELECT f_id, f_name
FROM fruits
WHERE f_name LIKE 'b%';查询结果如下:
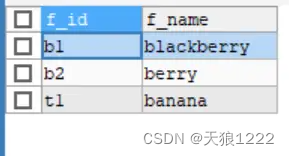
该语句查询的结果返回所有以‘b’开头的水果的id和name,‘%’告诉MySQL,返回所有以字母‘b’开头的记录,不管‘b’后面有多少个字符。
在搜索匹配时通配符‘%’可以放在不同位置。如【例12】。
【例12】在 fruits表中,查询f_name中包含字母‘g’的记录,SQL语句如下:
SELECT f_id, f_name
FROM fruits
WHERE f_name LIKE '%g%';查询结果如下:

该语句查询字符串中包含字母‘g’的水果名称,只要名字中有字符‘g’,而前面或后面不管有多少个字符,都满足查询的条件。
【例13】查询以‘b’开头,并以‘y’结尾的水果的名称,SQL语句如下:
SELECT f_id, f_name
FROM fruits
WHERE f_name LIKE 'b%y';查询结果如下:

通过以上查询结果,可以看到,‘%’用于匹配在指定的位置的任意数目的字符。
2,下划线通配符_',一次只能匹配任意一个字符
另一个非常有用的通配符是下划线通配符‘_’,该通配符的用法和‘%’相同,区别是“%’可以匹配多个字符,而‘_’只能匹配任意单个字符,如果要匹配多个字符,则需要使用相同个数的‘_’。
【例14】在fruits表中,查询以字母‘y’结尾,且‘y’前面只有4个字母的记录,SQL语句如下:
SELECT f_id, f_name
FROM fruits
WHERE f_name LIKE '____y';查询结果如下:

从结果可以看到,以‘y’结尾且前面只有4个字母的记录只有一条。其他记录的f_name字段也有以‘y’结尾的,但其总的字符串长度不为5,因此不在返回结果中。
7,查询空值
数据表创建的时候,设计者可以指定某列中是否可以包含空值(NULL)。空值不同于0,也不同于空字符串。空值一般表示数据未知、不适用或将在以后添加数据。在 SELECT 语句中使用IS NULL子句,可以查询某字段内容为空的记录。
下面,在数据库中创建数据表customers,该表中包含了本章中需要用到的数据。
CREATE TABLE customers
(
c_id int NOT NULL AUTO_INCREMENT,
c_name char (50) NOT NULL,
c_address char (50) NULL,
c_city char(50) NULL,
c_zip char (10) NULL,
c_contact char(50) NULL,
c_email char (255) NULL,
PRIMARY KEY(c_id)
) ;需要插入数据
INSERT INTO customers(c_id, c_name, c_address, c_city,c_zip, c_contact, c_email)
VALUES
(10001, 'RedHook', '200 street', 'Tianjin', '300000','LiMing','LMing@163.com'),
(10002, 'Stars', '333 Fromage Lane', 'Dalian', '116000', 'Zhangbo' , 'Jerryehotmail.com'),
(10003, 'Netbhood', '1 Sunny Place', 'Qingdao', '266000', 'Luocong', NULL),
(10004, 'JoTo', '829 Riverside Drive', 'Haikou' , '570000', 'YangShan', 'sam@hotmail.com');
SELECT COUNT(*) As cust_num FROM customers;【例15】查询customers表中 c_email为空的记录的c_id. c_name和c_email字段值 SQL语句如下:
SELECT c_id, c_name,c_email FROM customers WHERE c_email IS NULL;查询结果如下:

可以看到,显示customers表中字段c_email的值为NULL 的记录,满足查询条件。与IS NULL相反的是NOT IS NULL,该关键字查找字段不为空的记录。
【例16】查询customers表中 c_email不为空的记录的c_id、c_name和 c_email字段值,SQL语句如下:
SELECT c_id, c_name,c_email FROM customers WHERE c_email IS NOT NULL;查询结果如下:

可以看到,查询出来的记录的c_email字段都不为空值。
8,带AND的多条件查询
使用SELECT 查询时,可以增加查询的限制条件,这样可以使查询的结果更加精确。MySQL在 WHERE子句中使用AND操作符限定只有满足所有查询条件的记录才会被返回。可以使用AND连接两个甚至多个查询条件,多个条件表达式之间用AND分开。
【例17】在 fruits 表中查询s_id = 101,并且f_price大于等于5的水果价格和名称,SQL语句如下:
SELECT f_id, f_price,f_name
FROM fruits
WHERE s_id = '101' AND f_price >= 5;查询结果如下:

前面的语句检索了s_id=101的水果供应商所有价格大于等于5元的水果名称和价格。WHERE子句中的条件分为两部分,AND关键字指示 MySQL 返回所有同时满足两个条件的行。即使是 id=101的水果供应商提供的水果,如果价格<5,或者是id不等于‘101’的水果供应商里的水果不管其价格为多少,均不是要查询的结果。
上述例子的WHERE子句中只包含了一个AND语句,把两个过滤条件组合在一起。实际上可以添加多个AND过滤条件,增加条件的同时增加一个AND关键字。
【例18】在fruits表中查询s_id = 101或者102,且f _price大于5,并且f_name=apple’的水果价格和名称,SQL语句如下:
SELECT f_id, f_price,f_name
FROM fruits
WHERE s_id = '101' AND f_price >= 5 AND f_name = 'apple';查询结果如下:

可以看到,符合查询条件的返回记录只有一条。
9,带OR的多条件查询
与AND相反,在 WHERE声明中使用OR操作符,表示只需要满足其中一个条件的记录即可返回。OR也可以连接两个甚至多个查询条件,多个条件表达式之间用OR分开。
【例19】查询s_id=101或者s_id=102的水果供应商的f _price和f_name SQL语句如下:
SELECT S_id,f_name, f_price
FROM fruits
WHERE s_id = 101 OR s_id = 102;查询结果如下:

结果显示了s_id=101和s_id=102的商店里的水果名称和价格,OR操作符告诉 MySQL,检索的时候只需要满足其中的一个条件,不需要全部都满足。如果这里使用AND的话,将检索不到符合条件的数据。
在这里,也可以使用IN操作符实现与OR相同的功能,下面的例子可进行说明。
【例20】查询s_id=101或者s_id=102的水果供应商的f_price和f_name SQL语句如下:
SELECT s_id,f_name, f_price
FROM fruits
WHERE s_id IN(101,102);查询结果如下:
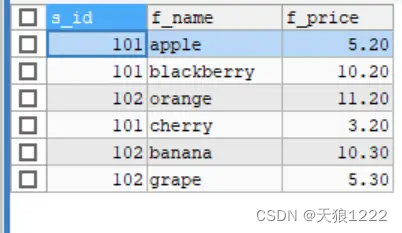
在这里可以看到,OR操作符和IN操作符使用后的结果是一样的,它们可以实现相同的功能。但是使用IN操作符使得检索语句更加简洁明了,并且IN执行的速度要快于OR。更重要的是,使用IN操作符,可以执行更加复杂的嵌套查询(后面章节将会讲述)。
提示:OR可以和AND一起使用,但是在使用时要注意两者的优先级,由于AND的优先级高于OR,因此先对AND两边的操作数进行操作,再与OR中的操作数结合。
10,查询结果不重复 distinct
从前面的例子可以看到,SELECT查询返回所有匹配的行。例如,查询fruits表中所有的s_id,其结果为:

可以看到查询结果返回了16条记录,其中有一些重复的s_id值,有时,出于对数据分析的要求,需要消除重复的记录值,如何使查询结果没有重复呢﹖在SELECT 语句中,可以使用DISTINCT 关键字指示 MySQL消除重复的记录值。语法格式为:
SELECT DISTINCT 字段名 FROM 表名;【例21】查询fruits表中 s_id字段的值,返回s_id字段值且不得重复,SQL语句如下:
SELECT DISTINCT s_id
FROM fruits查询结果如下:

可以看到,这次查询结果只返回了7条记录的s_id 值,且不再有重复的值,SELECT DISTINCT s_id告诉MySQL只返回不同的s_id行。
11,对查询结果排序
从前面的查询结果,会发现有些字段的值是没有任何顺序的,MySQL可以通过在SELECT语句中使用ORDER BY子句,对查询的结果进行排序。
1,单列排序
例如查询f_nam字段,查询结果如下:
SELECT f_name FROM fruits;可以看到,查询的数据并没有以一种特定的顺序显示,如果没有对它们进行排序,它们将根据它们插入到数据表中的顺序来显示。
下面使用ORDER BY子句对指定的列数据进行排序。
【例22】查询 fruits表的f_name字段值,并对其进行排序。SQL语句如下:
SELECT f_name FROM fruits ORDER BY f_name;该语句查询的结果和前面的语句相同,不同的是,通过指定ORDER BY子句,MySQL对查询的name列的数据,按字母表的顺序进行了升序排序。
2,多列排序
有时,需要根据多列值进行排序。比如,如果要显示一个学生列表,可能会有多个学生的姓氏是相同的,因此还需要根据学生的名进行排序。对多列数据进行排序,须将需要排序的列之间用逗号隔开。
【例23】查询 fruits表中的f_name和f_price字段,先按f_name排序,再按f_price排序,sQL语句如下:
SELECT f_name, f_price FROM fruits ORDER BY f_name, f_price;查询结果如下:
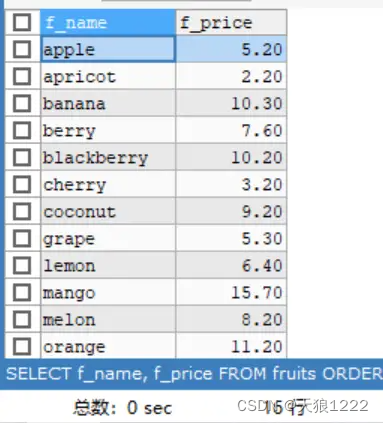
提示:在对多列进行排序的时候,酋先排序的第一列必须有相同的列值,才会对第二列进行排序。如果第一列数据中所有值都是唯一的,将不再对第二列进行排序。
3,指定排序方向
默认情况下,查询数据按字母升序进行排序(从A~Z),但数据的排序并不仅限于此,还可以使用ORDER BY对查询结果进行降序排序(从Z~A),这可以通过关键字DESC实现,下面的例子表明了如何进行降序排列。
【例24】查询 fruits表中的f_name和f_price字段,对结果按f_price降序方式排序,SQL语句如下:
SELECT f_name, f_price FROM fruits ORDER BY f_price DESC;查询结果如下:

与DESC相反的是ASC(升序排序),将字段列中的数据,按字母表顺序升序排序。实际上,在排序的时候ASC是作为默认的排序方式,所以加不加都可以。
也可以对多列进行不同的顺序排序,如【例25】所示。
【例25】查询fruits 表,先按f_price降序排序,再按f_name字段升序排序,SQL语句如下:
SELECT f_price, f_name
FROM fruits
ORDER BY f_price DESC, f_name;查询结果如下:

DESC排序方式只应用到直接位于其前面的字段上,由结果可以看出。
提示:DESC关键字只对其前面的列进行降序排列,在这里只对f_price排序,而并没有对f_name进行排序,因此,f_ price按降序排序,而f_name列仍按升序排序。如果要对多列都进行降序排序,必须要在每一列的列名后面加 DESC关键字。
4,值null排后面
往水果表添加一个排序字段
ALTER TABLE fruits ADD COLUMN sort_id INT(4) COMMENT '排序';
手动修改表格的值,保留几个不操作。
SELECT * FROM fruits ORDER BY sort_id IS NULL, sort_id ASC;
需要把NULL 值放前面,就把顺序改下
SELECT * FROM fruits ORDER BY sort_id ASC, sort_id IS NULL;
12,分组查询
分组查询是对数据按照某个或多个字段进行分组,MySQL中使用GROUP BY关键字对数据进行分组,基本语法形式为:
[GROUP BY字段] [HAVING<条件表达式>]字段值为进行分组时所依据的列名称;“HAVING<条件表达式>”指定满足表达式限定条件的结果将被显示。
1,创建分组
GROUP BY关键字通常和集合函数一起使用,例如:MAX()、MIN()、COUNT()、SUM(),AVG()。例如,要返回每个水果供应商提供的水果种类,这时就要在分组过程中用到COUNTO函数,把数据分为多个逻辑组,并对每个组进行集合计算。
【例26】根据s _id对fruits表中的数据进行分组,SQL语句如下:
SELECT s_id, COUNT(*) AS Total FROM fruits GROUP BY s_id;查询结果如下:
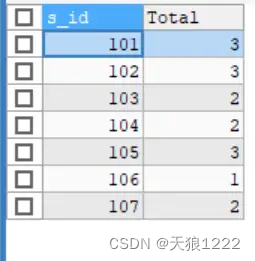
查询结果显示s_id表示供应商的ID Total字段使用COUNTO函数计算得出GROUP BY子句按照s_id排序并对数据分组,可以看到ID为101、102、105的供应商分别提供3种水果,ID为103、104、107的供应商分别提供2种水果,ID为106的供应商只提供1种水果。
如果要查看每个供应商提供的水果的种类的名称,该怎么办呢? MySQL中可以在GROUPBY字节中使用GROUP_CONCAT)函数,将每个分组中各个字段的值显示出来。
【例27】根据s_id对 fruits表中的数据进行分组,将每个供应商的水果名称显示出来,SQL语句如下:
SELECT s_id, GROUP_CONCAT(f_name) AS Names FROM fruits GROUP BY s_id;查询结果如下:

由结果可以看到,GROUP_CONCAT()函数将每个分组中的名称显示出来了,其名称的个数与COUNTO函数计算出来的相同。
2,使用HAVING过滤分组
GROUP BY可以和HAVING一起限定显示记录所需满足的条件,只有满足条件的分组才会被显示。
【例28】根据s_id对fruits表中的数据进行分组,并显示水果种类大于1的分组信息,SQL语句如下:
SELECT s_id, GROUP_CONCAT(f_name) AS Names FROM fruits
GROUP BY s_id HAVING COUNT(f_name)>1查询结果如下:

由结果可以看到,ID为101、102、103、104、105、107的供应商提供的水果种类大于1,满足HAVING子句条件,因此出现在返回结果中;而ID为106的供应商的水果种类等于1,不满足限定条件,因此不在返回结果中。
HAVING关键字与WHERE 关键字都是用来过滤数据,两者有什么区别呢?其中重要的一点是,HAVING在数据分组之后进行过滤来选择分组,而 WHERE 在分组之前用来选择记录。另外WHERE排除的记录不再包括在分组中。
3,在GROUP BY子句中使用WITH ROLLUP
使用WITH ROLLUP关键字之后,在所有查询出的分组记录之后增加一条记录,该记录计算查询出的所有记录的总和,即统计记录数量。
【例29】根据s_id对fruits表中的数据进行分组,并显示记录数量,SQL语句如下:
SELECT s_id, COUNT(*) As Total FROM fruits
GROUP BY s_id WITH ROLLUP;查询结果如下:

由结果可以看到,通过GROUP BY分组之后,在显示结果的最后面新添加了一行,该行Total 列的值正好是上面所有数值之和。
4,多字段分组
使用GROUP BY可以对多个字段进行分组,GROUP BY 关键字后面跟需要分组的字段,MySQL根据多字段的值来进行层次分组,分组层次从左到右,即先按第1个字段分组,然后在第1个字段值相同的记录中,再根据第2个字段的值进行分组...依次类推。
【例30】根据s_id和f_name字段对fruits表中的数据进行分组,SQL语句如下
SELECT * FROM fruits GROUP BY f_id, f_name;查询结果如下:

由结果可以看到,查询记录先按照s_id进行分组,再对f_name字段按不同的取值进行分组。
5,GROUP BY和ORDER BY一起使用
某些情况下需要对分组进行排序,在前面的介绍中,ORDERBY用来对查询的记录排序,如果和GROUP BY一起使用可以完成对分组的排序。
首先创建数据表,SQL语句如下:
CREATE TABLE order_items
(
o_num int NOT NULL,
o_item int NOT NULL,
f_id char(10) NOT NULL,
quantity int NOT NULL,
item_price decimal(8, 2) NOT NULL,
PRIMARY KEY (o_num, o_item)
);然后插入演示数据。SQL语句如下:
INSERT INTO order_items(o_num, o_item, f_id, quantity, item_price)
VALUES(30001, 1, 'a1', 10, 5.2),
(30001, 2, 'b2', 3, 7.6),
(30001, 3, 'bsl', 5, 11.2),
(30001, 4, 'bs2', 15, 9.2),
(30002, 1, 'b3', 2, 20.0),
(30003, 1, 'c0', 100, 10),
(30004, 1, 'o2', 50, 2.50),
(30005, 1, 'c0', 5, 10),
(30005, 2, 'b1', 10, 8.99),
(30005, 3, 'a2', 10, 2.2),
(30005, 4, 'm1', 5, 14.99);【例31】查询订单价格大于100的订单号和总订单价格,SQL语句如下:
SELECT o_num, SUM(quantity * item_price) AS orderTotal
FROM order_items
GROUP BY o_num
HAVING SUM(quantity*item_price) >= 100;查询结果如下:
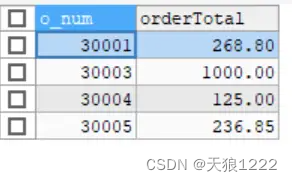
可以看到,返回的结果中 orderTotal列的总订单价格并没有按照一定顺序显示,接下来,使用ORDER BY关键字按总订单价格排序显示结果,SQL语句如下:
SELECT o_num, SUM(quantity * item_price) AS orderTotal
FROM order_items
GROUP BY o_num
HAVING SUM(quantity*item_price) >= 100
ORDER BY orderTotal;查询结果如下:

由结果可以看到,GROUP BY子句按订单号对数据进行分组,SUM)函数便可以返回总的订单价格,HAVING子句对分组数据进行过滤,使得只返回总价格大于100 的订单,最后使用ORDER BY子句排序输出。
提示:当使用ROLLUP时,不能同时使用ORDER BY子句进行结果排序。即ROLLUP和ORDERBY是互相排斥的。
13,使用LIMIT限制查询结果的数量
SELECT返回所有匹配的行,有可能是表中所有的行,如仅仅需要返回第一行或者前几行,使用LIMIT 关键字,基本语法格式如下:
LIMIT [位置偏移量,] 行数第一个“位置偏移量”参数指示 MySQL从哪一行开始显示,是一个可选参数,如果不指定“位置偏移量”,将会从表中的第一条记录开始(第一条记录的位置偏移量是0,第二条记录的位置偏移量是1...依次类推)﹔第二个参数“行数”指示返回的记录条数。
【例32】显示 fruits表查询结果的前4行,SQL语句如下:
SELECT * From fruits LIMIT 4;查询结果如下:

由结果可以看到,该语句没有指定返回记录的“位置偏移量”参数,显示结果从第一行开始,“行数”参数为4,因此返回的结果为表中的前4行记录。
如果指定返回记录的开始位置,则返回结果为从“位置偏移量"参数开始的指定行数,“行数”参数指定返回的记录条数。
【例33】在 fruits 表中,使用LIMIT子句,返回从第5个记录开始的,行数长度为3的记录,SQL语句如下:
SELECT * From fruits LIMIT 4, 3;查询结果如下:
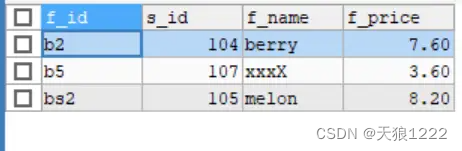
由结果可以看到,该语句指示 MySQL返回从第5条记录行开始之后的3条记录。第一个数字‘4’表示从第5行开始(位置偏移量从О开始,第5行的位置偏移量为4),第二个数字3表示返回的行数。
所以,带一个参数的LIMIT 指定从查询结果的首行开始,唯一的参数表示返回的行数,即“LIMIT n”与“LIMIT 0,n”等价。带两个参数的LIMIT可以返回从任何一个位置开始的指定的行数。
返回第一行时,位置偏移量是0。因此,“LIMIT 1,1”将返回第二行,而不是第一行。
提示:MySQL 5.7 中可以使用“LIMIT 4 OFFSET 3”,意思是获取从第5条记录开始后面的3条记录,和“LIMIT 4,3;”返回的结果相同。
3,使用聚合函数查询
有时候并不需要返回实际表中的数据,而只是对数据进行总结。MySQL提供一些查询功能,可以对获取的数据进行分析和报告。这些函数的功能有:计算数据表中记录行数的总数、计算某个字段列下数据的总和,以及计算表中某个字段下的最大值、最小值或者平均值。本节将介绍这些函数以及如何使用它们。这些聚合函数的名称和作用如表2所示。
表2 MySQL聚合函数
| 函数 | 作用 |
| AVG() | 返回某列的平均值 |
| COUNT() | 返回某列的行数 |
| MAX() | 返回某列的最大值 |
| MIN() | 返回某列的最小值 |
| SUM() | 返回某列值的和 |
1,COUNT()函数
COUNT()函数统计数据表中包含的记录行的总数,或者根据查询结果返回列中包含的数据行数。其使用方法有两种:
. COUNT(*)计算表中总的行数,不管某列有数值或者为空值。
. COUNT(字段名)计算指定列下总的行数,计算时将忽略空值的行。
【例34】查询customers表中总的行数,SQL语句如下:
SELECT COUNT(*) As cust_num
FROM customers;查询结果:

由查询结果可以看到,COUNT(*)返回customers表中记录的总行数,不管其值是什么。返回的总数的名称为cust_num。
【例35】查询customers表中有电子邮箱的顾客的总数,SQL语句如下:
SELECT COUNT(c_email) AS emai1_num
FROM customers;查询结果:
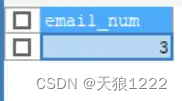
由查询结果可以看到表中5个customer 只有3个有email, customer的email为空值NULL的记录没有被COUNT()函数计算。
提示:两个例子中不同的数值,说明了两种方式在计算总数的时候对待NULL值的方式不同。即指定列的值为空的行被COUNTO)函数忽略,但是如果不指定列,而在COUNT)函数中使用星号“*”,则所有记录都不忽略。
前面介绍分组查询的时候,介绍了COUNT()函数与GROUP BY关键字一起使用,用来计算不同分组中的记录总数。
【例36】在 order_items表中,使用COUNT()函数统计不同订单号中订购的水果种类,SQL语句如下:
SELECT o_num, COUNT(f_id)
FROM order_items
GROUP BY o_num;查询结果:
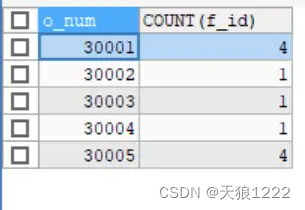
查询结果可以看到,GROUP BY关键字先按照订单号进行分组,然后计算每个分组中的总记录数。
2,SUM()函数
SUM()是一个求总和的函数,返回指定列值的总和。
【例37】在orderiterms表中查询30005号订单一共购买的水果总量,SQL语句如下:
SELECT SUM(quantity) AS items_total
FROM order_items
WHERE o_num = 30005; 查询结果:
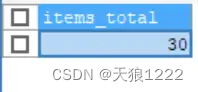
由查询结果可以看到,SUM(quantity)函数返回订单中所有水果数量之和,WHERE子句指定查询的订单号为30005。
SUM()可以与GROUP BY一起使用,来计算每个分组的总和。
【例38】在 order_items表中,使用SUM()函数统计不同订单号中订购的水果总量,SQL语句如下:
SELECT o_num,SUM(quantity) AS items_total
FROM order_items
GROUP BY o_num;查询结果:

由查询结果可以看到,GROUP BY按照订单号o_num进行分组,SUM()函数计算每个分组中订购的水果的总量。
SUM()函数在计算时,忽略列值为NULL的行。
3,AVG()函数
AVG()函数通过计算返回的行数和每一行数据的和,求得指定列数据的平均值。
【例39】在 fruits表中,查询s_id=103的供应商的水果价格的平均值,SQL语句如下:
SELECT AVG(f_price) AS avg_price
FROM fruits
WHERE s_id = 103;查询结果:

该例中,查询语句增加了一个WHERE子句,并且添加了查询过滤条件,只查询s_id= 103的记录中的f_price。因此,通过AVGO)函数计算的结果只是指定的供应商水果的价格平均值,而不是市场上所有水果的价格的平均值。
AVG()可以与GROUP BY一起使用,来计算每个分组的平均值。
【例40】在 fruits表中,查询每一个供应商的水果价格的平均值,SQL语句如下:
SELECT s_id,AVG(f_price) AS avg_price
FROM fruits
GROUP BY s_id;查询结果:

GROUP BY 关键字根据s_id字段对记录进行分组,然后计算出每个分组的平均值,这种分组求平均值的方法非常有用,例如:求不同班级学生成绩的平均值,求不同部门工人的平均工资,求各地的年平均气温等等。
AVG()函数使用时,其参数为要计算的列名称,如果要得到多个列的多个平均值,则需要在每一列上使用AVG)函数。
4,MAX()函数
MAX()返回指定列中的最大值。
【例41】在fruits表中查找市场上价格最高的水果值,SQL语句如下:
SELECT MAX(f_price) AS max_price FROM fruits;查询结果:

由结果可以看到,MAX()函数查询出了f_price字段的最大值15.70。
MAX()也可以和 GROUP BY 关键字一起使用,求每个分组中的最大值。
【例42】在 fruits表中查找不同供应商提供的价格最高的水果值,SQL语句如下:
SELECT s_id, MAX(f_price) AS max_price
FROM fruits
GROUP BY s_id;查询结果:
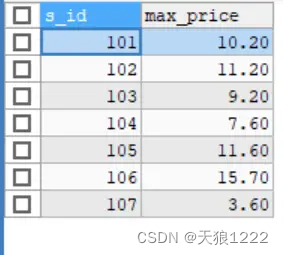
由结果可以看到,GROUP BY 关键字根据s_id字段对记录进行分组,然后计算出每个分组中的最大值。
MAX()函数不仅适用于查找数值类型,也可应用于字符类型。
【例43】在fruits表中查找f_name的最大值,SQL语句如下:
SELECT MAX(f_name) FROM fruits;查询结果:

由结果可以看到,MAX()函数可以对字母进行大小判断,并返回最大的字符或者字符串值。
MAX()函数除了用来找出最大的列值或日期值之外,还可以返回任意列中的最大值,包括返回字符类型的最大值。在对字符类型数据进行比较时,按照字符的ASCII 码值大小进行比较,从a~z,a的 ASCII 码最小,z的最大。在比较时,先比较第一个字母,如果相等,继续比较下一个字符,一直到两个字符不相等或者字符结束为止。例如,‘b’与‘t'比较时,‘t’为最大值;“bcd”与“bca”比较时,“bed”为最大值。
5,MIN()函数
MIN()返回查询列中的最小值。
【例44】在fruits表中查找市场上价格最低的水果值,SQL语句如下:
SELECT MIN(f_price) AS min_price FROM fruits;查询结果:

由结果可以看到,MIN(函数查询出了f price字段的最小值2.20。
MIN()也可以和GROUP BY 关键字一起使用,求出每个分组中的最小值。
【例45】在 fruits表中查找不同供应商提供的价格最低的水果值,SQL语句如下:
SELECT s_id,MIN(f_price) AS min_price
FROM fruits
GROUP BY s_id;查询结果:
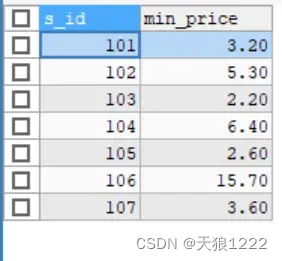
由结果可以看到,GROUP BY 关键字根据s_id字段对记录进行分组,然后计算出每个分组中的最小值。
MIN(函数与MAX()函数类似,不仅适用于查找数值类型,也可应用于字符类型。
总结
在基本查询中,查询字段的时候,一般情况下,除非需要使用表中所有的字段数据,最好不要使用通配符‘*’。查询分组和结合聚合函数一起用,会多一些。
上一篇: 《msyql 常用函数》
下一篇: 《mysql 连接查询和子查询》