1.引用
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空
间。在语法层面,我们认为它和它引用的变量共用同一块内存空间。
可以取多个别名,也可以给别名取别名。
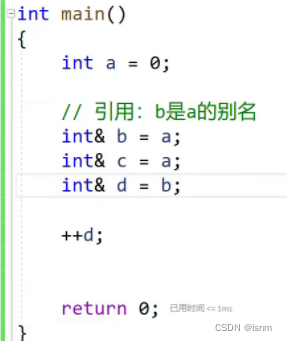
b/c/d本质都是别名,对d进行一个++
对于符号&,用其定义时就是引用,其他时候就是取地址
从此,改变一个变量不需要传地址,而可以在形参处定义别名,达到类似指针的效果。

“经典的错误,标准的零分”
为什么a的值还是没有改变?
尽管传入的是别名 ,但是函数接受的参数依然是个数值,是实参的拷贝。应当在形参处建立引用,这样才能真正修改我们希望修改的变量。

这样就成功改变a的值了。
结论:形参是引用,则通过形参就能改变实参,不需要传更高级的指针。
引用中需要注意的细节:
1.1引用在定义时必须先初始化
![]() 引用在定义时必须已经初始化(不能先取绰号,再找谁合适这个绰号)
引用在定义时必须已经初始化(不能先取绰号,再找谁合适这个绰号)
一个引用可以有多个变量,就如上文的a b c d
引用一旦引用一个实体,就不能再改变

可见,不是让y变成z的别名,而是通过y,将z的值赋值给y和x
1.2引用中的权限问题
![]() 存在的问题:权限的放大
存在的问题:权限的放大
m是只读的,当n变成m的别名后,n作为int类型的变量是可读可写的。为了避免通过n修改了m这个const类型的变量(权限放大),所以不能通过编译。
 这样,是权限的平移,就能通过编译了。
这样,是权限的平移,就能通过编译了。
对一个对象(C语言中喜欢称为变量),权限可以缩小和平移,但是不能放大。


此处我可以通过y修改x,修改后z的数值也会改变(相当于z只是没有“write”的权限,z只能访问x, 并不代表这个值真真正正地锁死了)
回忆:const int* int const* int* const
const默认与其左边结合,当左边没有任何东西则与右边结合。
换句话说,const只要在*的左边,限制的就是*p1;const在*右边,限制的就是这个指针,该指针只能指向这个空间,不能改变指向。
上文中的前两种所限制的是一样的,最后一种限制的是指针,不能进行加减法。
报错的原因是:p2是可读可写的,我们可以通过p2去改变p1所指向的空间。但是p1指向的空间是被锁死了的,是不能改变的,又扩大了权限,因此报错。

数值之间没有权限的概念,只有指针和引用之间有权限的概念。
类型转化中的权限问题:
不管是强制类型转化还是隐式类型转化,其底层都是通过建立一个临时变量来进行转化。
我们先用double定义一个变量为12.34:

其转化的本质是把d的整数部分取出,赋给整形类型的临时变量,再通过临时变量赋给i。
既然是这样的赋值方法,就不难理解下图为什么会报错了:
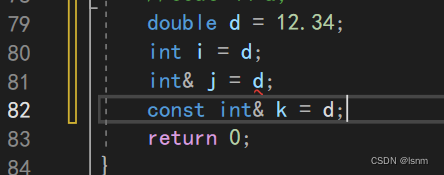
在82行代码执行时,d先将其整数部分赋值给临时变量,但是临时变量具有常性(像一个常数一样,不可被改变),而按照int& j的方法接受该临时变量后,j作为别名,可以通过j修改该临时变量,这是不被允许的。
但如果我给这个变量定义为“只读”类型,也就是const int& k=d;
权限没有被放大,就合规了。
所有的表达式运算也会产生临时变量
int x=1;
int y=2;
x+y;没有用变量接受x+y,但是x+y还是会进行计算,计算出的结果会放进临时变量。
同理,有变量接受x+y时也一样,x+y的值放入临时变量,所以r2前面必须加const(只读)才能保证不越界。

1.3传参和传引用效率比较
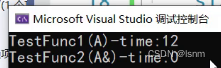
直接传值会拷贝整个变量(形参是实参的copy),传参效率弱于引用传参。
再利用一个测试函数:

(将传值执行10000次,再将传引用执行10000次,0表示其所消耗的时间是小于1ms的)
1.4从底层看引用

我们在语法层面认为:别名不开空间,存地址的变量(指针)是需要开辟空间的。
但是在汇编层面:

通过底层可知,定义指针p和引用b的汇编代码是一样的。
不过在日常的语法层面,我们依然认为引用不开空间,指针变量要开空间。
1.5指针和引用的区别
1. 引用概念上定义一个变量的别名,指针存储一个变量地址。2. 引用 在定义时 必须初始化 ,指针没有要求3. 引用 在初始化时引用一个实体后,就 不能再引用其他实体 ,而指针可以在任何时候指向任 何一个同类型实体4. 没有 NULL 引用 ,但有 NULL 指针5. 在 sizeof 中含义不同 : 引用 结果为 引用类型的大小 ,但 指针 始终是 地址空间所占字节个数 (32 位平台下占4 个字节 )6. 引用自加即引用的实体增加 1 ,指针自加即指针向后偏移一个类型的大小7. 有多级指针,但是没有多级引用8. 访问实体方式不同, 指针需要显式解引用,引用编译器自己处理9. 引用比指针使用起来相对更安全
不过对于第四点,可以单独说明一下:

不是说没有NULL引用吗?
结合底层思考为什么没有报错

通过观察汇编,我们可以发现,并没有发生解引用这一步骤。
因为其本质是和指针一样的汇编代码,所以并没有发生报错。
cpp的引用为什么不能替代指针?
如:链表:

引用不能改变指向,如果用引用的方法存下下一个节点,当你想改变链接方式时,如何处理?
所以next必须使用指针。这单纯的是语法设计的原因,因为本贾尼是按照c为基础设计的,并没有想过要完全替代C语言。在Java中,引用就是可改变的,因此java没有指针。
2.内联函数
对于一些小型的、会大量重复调用的函数,如(Swap,Add等)。不停的建立函数栈帧性价比太低,C语言使用含参数的宏来解决这个问题。
宏没有栈帧消耗,但是容易出语法问题:复杂、没有类型检查、无法调试
cpp虽然兼容c的所有用法,但是cpp更倾向于使用内联函数(inline修饰):
以 inline 修饰 的函数叫做内联函数, 编译时 C++ 编译器会在 调用内联函数的地方展开 ,没有函数调 用建立栈帧的开销,内联函数提升程序运行的效率。本质是一种空间换时间的做法。
用inline修饰函数

注意:在debug模式下,为了调试方便,依然会执行call语句,像以前的函数一样建立栈帧。

没有执行call语句,也就是没有按照函数去调用,而是直接展开。
内联函数的特点:
编译器并没有把是否展开的权利完全释放给你,而是会自己选择是否展开。
当函数中的语句过多时,就不会展开
inline对于编译器只是一种建议,编译器会自己决定是否展开(如递归等就一定不会展开)
为什么有的函数语句过多时不会展开?
大函数展开的缺点:
若我们要对一个100行的代码调用10000次:

导致编译出的可执行程序变大。可执行程序大了是一件很麻烦的事情。
最后,内联函数不能声明和定义相分离
因为内联函数是直接展开的,没有函数的地址,在链接过程中是找不到的。
其本质就是一个小型功能直接展开。
3.auto
随着程序越来越复杂,程序中用到的类型也越来越复杂,经常体现在:1. 类型难于拼写2. 含义不明确导致容易出错

根据赋值的内容,自动识别i的类型。
当然,typedef有类似的功能,但是typedef有时候会有些问题:


pstring p1 与 char* const p1是一个意思,p1 作为一个被const的变量,也具有常性,必须初始化,所以此处报错。
tips:typeid可以用来查看变量的类型名:
typeid(a).name();auto修饰的限定

auto可以根据后面的内容进行赋值内容的条件限制。
规定:auto不能直接用来声明数组

4.基于范围的for循环
基于auto的用法,cpp抄了python的作业,使用自动循环:
for循环迭代的范围必须是确定的

for (auto e: array){
e/=2;
}
auto可以改成具体的类型(int、double)等都可以,只要匹配就行
但是遍历方式是写死了的,只能从数组首到数组尾遍历。
但是传参进入的数组不能使用范围for
数组的传参本质是传入数组首元素地址,会退化。(c/cpp追求效率,在语言层进行了优化,传的是首元素地址)

而针对一个数组首元素地址,该数组循环迭代的范围是不确定的,所以不能执行。
5.nullptr和NULL
cpp的设计缺陷:
将NULL作为一个宏,代表0,而不是之前的空指针。因此,cpp中的NULL会被当作整形的int而不是空指针
所以,引入了关键字nullptr
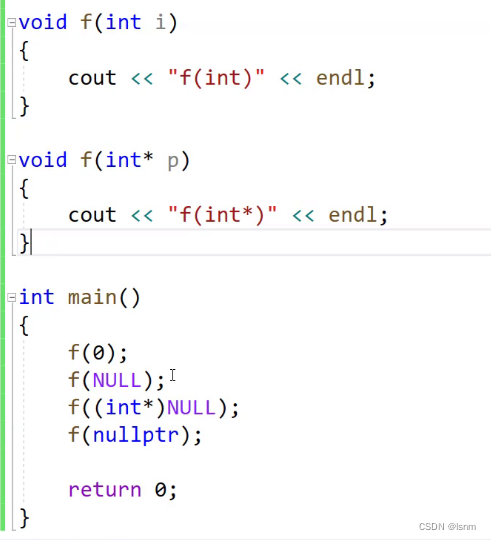
主函数中:第一个f调用第一个函数,第二个f也调用第一个函数,第三个f调用第二个函数,第四个函数调用第二个函数。
nullptr作为关键字,是不需要包含任何头文件的
6.小结
本篇中多为零碎的c过渡到cpp的语法知识,先进行铺垫和了解,在之后会有具体而详细的使用。