↑↑↑请在文章头部下载测试项目原代码↑↑↑
文章目录
- 前言
- 4.2 商户查询缓存
- 4.2.1 缓存介绍
- 4.2.2 查询商户信息的传统做法
- 4.2.2.1 接口文档
- 4.2.2.2 代码实现
- 4.2.2.3 功能测试
- 4.2.3 查询商户信息添加Redis缓存
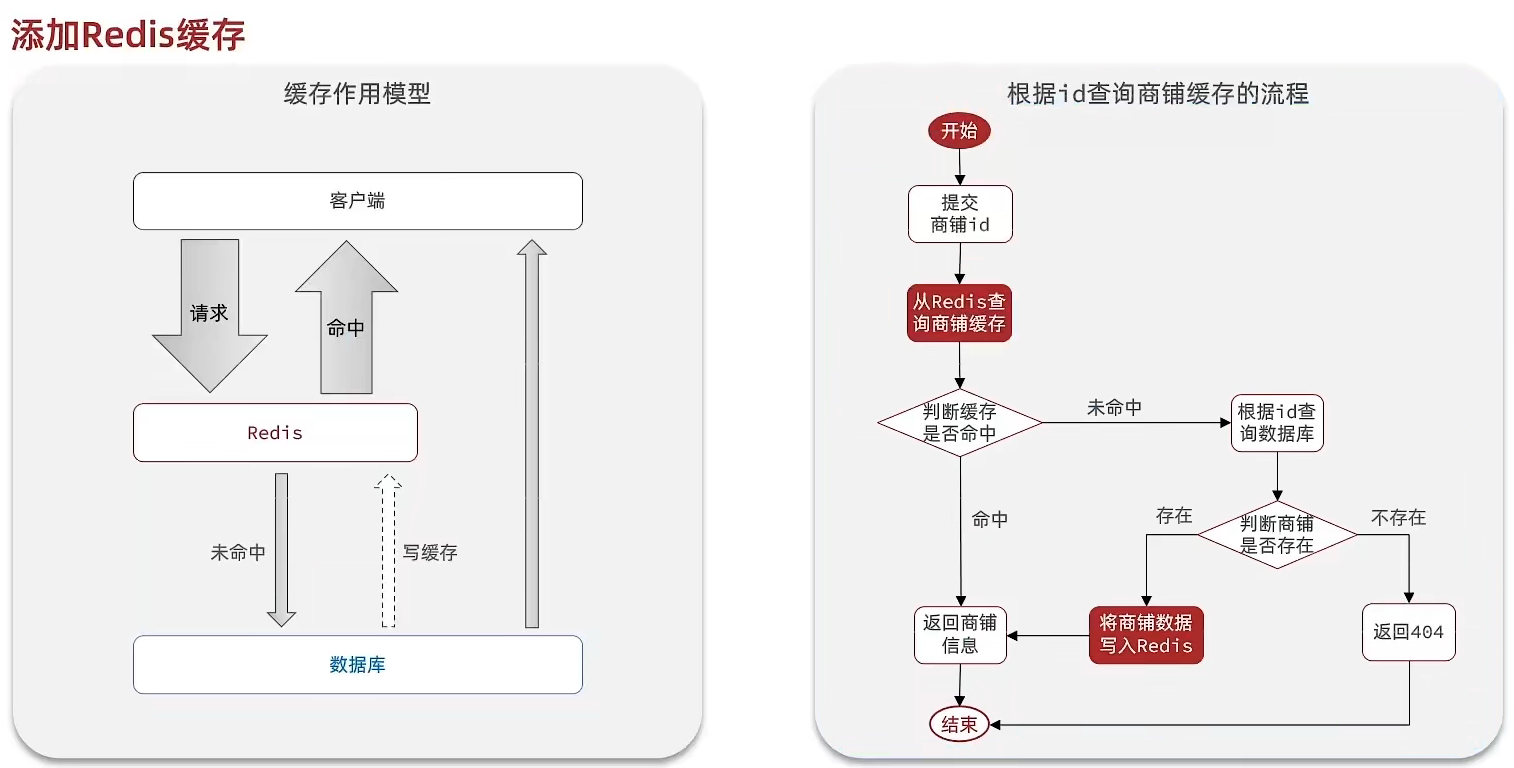
- 4.2.3.1 逻辑分析
- 4.2.3.2 代码实现
- 4.2.3.3 功能测试
- 4.2.3 数据一致性问题及其解决方案
- 4.2.3.1 问题分析
- 4.2.3.2 实现商户信息的双写一致
- 4.2.4 缓存穿透问题及其解决方案
- 4.2.4.1 什么是缓存穿透问题
- 4.2.4.2 缓存穿透问题的解决方案
- 4.2.4.3 基于缓存空对象解决缓存穿透问题
- 4.2.5 缓存击穿问题及其解决
- 4.2.5.1 什么是缓存击穿问题
- 4.2.5.2 缓存击穿问题的解决方案
- 4.2.5.3 利用互斥锁解决缓存击穿问题
- 4.2.5.4 利用逻辑过期解决缓存击穿问题
前言
上一节实现了Redis实战项目的第一个功能:短信登录。项目最初采用session方式实现短信登录,但该方式存在session共享问题,因此改为基于Redis来实现。
Redis从入门到精通(四)Redis实战(一)短信登录
4.2 商户查询缓存
4.2.1 缓存介绍
缓存(Cache),即数据交换的缓存区,俗称的缓存就是指缓存区中的数据。缓存最大的特点就是它运行在内存中,速度快,可以大大降低用户访问并发量带来的服务器读写压力。
但缓存也有不足之处,就是会增加代码复杂度和运营成本:

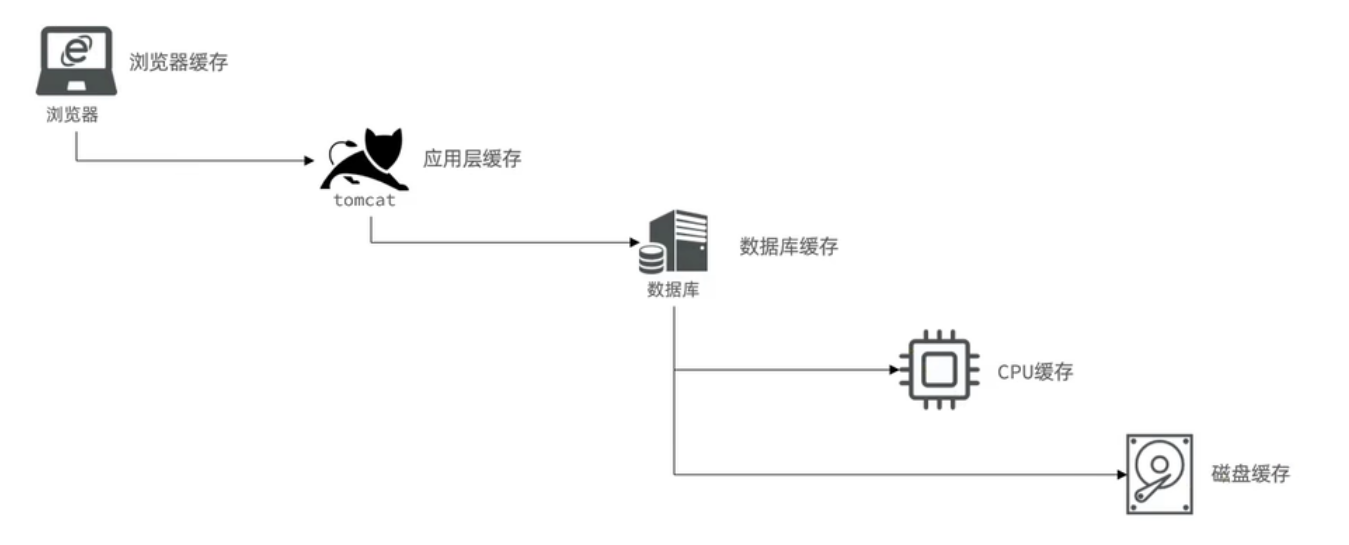
在实际开发中,会构筑多级缓存来使系统运行速度进一步提升,包括:
- 浏览器缓存:浏览器在用户磁盘上对最近请求过的文档进行存储,当访问者再次请求这个页面时,浏览器就可以从本地磁盘显示文档,这样就可以加速页面的阅览。。
- 应用层缓存:例如Tomcat本地缓存或Redis缓存。
- 数据库缓存:例如MySQL缓存,是指MySQL数据库服务器中的内存区域,用于存储经常访问的数据和查询结果,以提高查询性能和响应时间。。
- CPU缓存:CPU的L1、L2、L3级缓存。
4.2.2 查询商户信息的传统做法
根据ID查询商户信息,传统做法是直接从数据库查询,并将查询结果返回。
4.2.2.1 接口文档
| 项目 | 说明 |
|---|---|
| 请求方式 | GET |
| 请求路径 | /shop/{id} |
| 请求参数 | id |
| 返回值 | Shop |
4.2.2.2 代码实现
在ShopController类中实现一个queryById()方法,调用IShopService接口的queryShopById()方法:
// com.star.redis.dzdp.controller.ShopController
@Slf4j
@RestController
@RequestMapping("/shop")
public class ShopController {
@Resource
private IShopService shopService;
/**
* 根据ID查询商户信息
* @author hsgx
* @since 2024/4/3 11:23
* @param id
* @return com.star.redis.dzdp.pojo.BaseResult<com.star.redis.dzdp.pojo.Shop>
*/
@GetMapping("/{id}")
public BaseResult<Shop> queryById(@PathVariable Long id) {
return shopService.queryShopById(id);
}
}
然后在IShopService接口的实现类ShopServiceImpl类中实现queryShopById()方法:
// com.star.redis.dzdp.service.impl.ShopServiceImpl
@Slf4j
@Service
@Transactional(rollbackFor = Exception.class)
public class ShopServiceImpl extends ServiceImpl<ShopMapper, Shop> implements IShopService {
@Override
public BaseResult<Shop> queryShopById(Long id) {
log.info("query Shop by id = {}", id);
// 查询数据库
Shop shop = getById(id);
if(shop == null) {
return BaseResult.setFail("商户不存在!");
}
return BaseResult.setOkWithData(shop);
}
}
4.2.2.3 功能测试
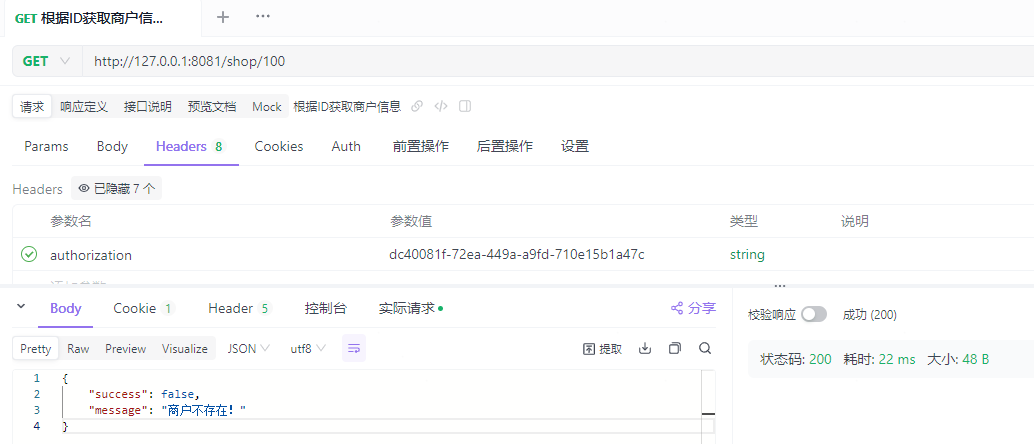
当id=100时,返回“商户不存在”:
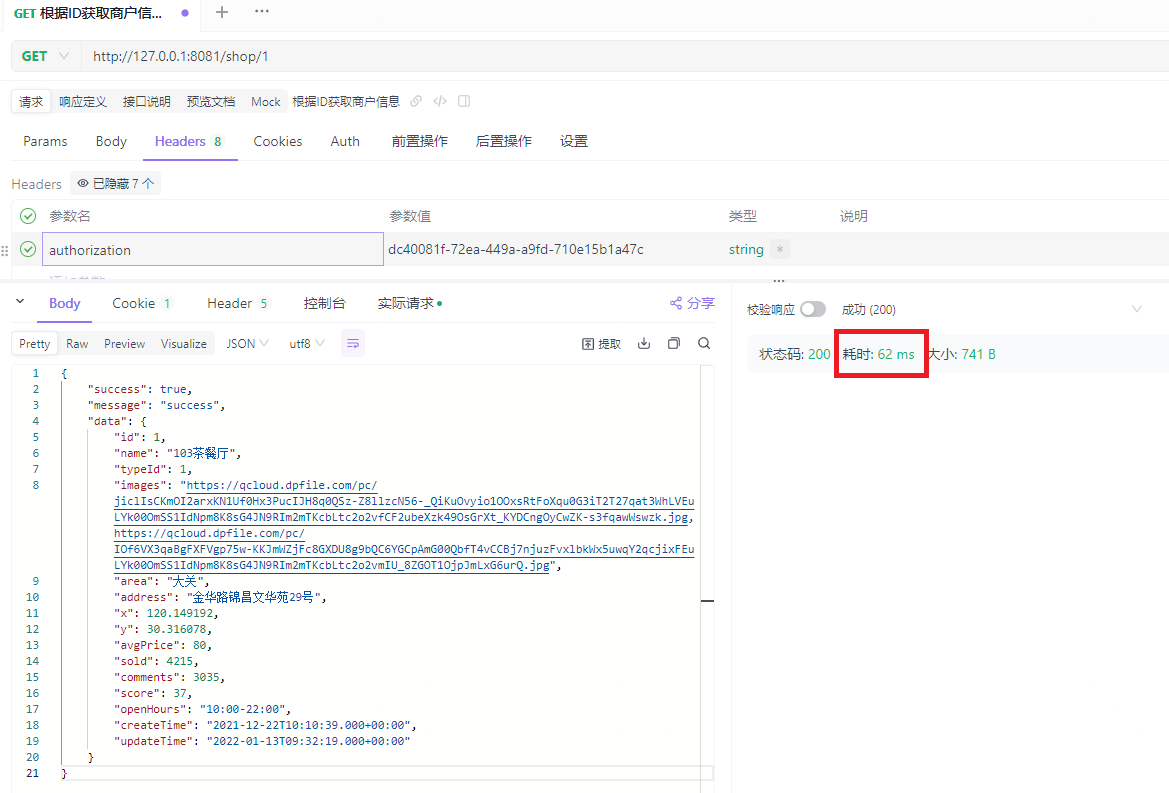
当id=1时,成功获取到商户信息,耗时62ms:
4.2.3 查询商户信息添加Redis缓存
4.2.3.1 逻辑分析
通常情况下,该功能的逻辑是在查询数据库之前先查询Redis,如果Redis中存在数据,则直接从Redis中返回数据;如果Redis中没有数据,再查询数据库,并将查询结果保存到Redis中。
4.2.3.2 代码实现
修改ShopServiceImpl类中实现queryShopById()方法,添加查询Redis的逻辑:
// com.star.redis.dzdp.service.impl.ShopServiceImpl
@Resource
private StringRedisTemplate stringRedisTemplate;
@Override
public BaseResult<Shop> queryShopById(Long id) {
log.info("query Shop by id = {}", id);
// 1.构建Key,并从Redis中查询商户信息
String key = "cache:shop:" + id;
String shopJson = stringRedisTemplate.opsForValue().get(key);
log.info("get from Redis: Key = {}, Value = {}", key, shopJson);
// 2.判断商户信息是否存在
if(StrUtil.isNotBlank(shopJson)) {
// 3.存在,直接返回
Shop shop = JSONUtil.toBean(shopJson, Shop.class);
return BaseResult.setOkWithData(shop);
}
// 4.不存在,根据ID查询数据库
Shop shop = getById(id);
if(shop == null) {
return BaseResult.setFail("商户不存在!");
}
// 5.将商户信息写入Redis
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop));
log.info("set to Redis: Key = {}, Value = {}", key, JSONUtil.toJsonStr(shop));
// 6. 返回信息
return BaseResult.setOkWithData(shop);
}
4.2.3.3 功能测试
当id=1时,由于此时Redis中还没有数据,所以会从数据库查询数据并保存到Redis。控制台打印信息如下(省略了一些不重要的信息):
query Shop by id = 1
get from Redis: Key = cache:shop:1, Value = null
==> Preparing: SELECT id,name,type_id,images,area,address,x,y,avg_price,sold,comments,score,open_hours,create_time,update_time FROM tb_shop WHERE id=?
==> Parameters: 1(Long)
<== Total: 1
set to Redis: Key = cache:shop:1, Value = {"area":"大关","openHours":"10:00-22:00",...省略...,"id":1}
此时可以查询Redis中已经保存了商户的数据:
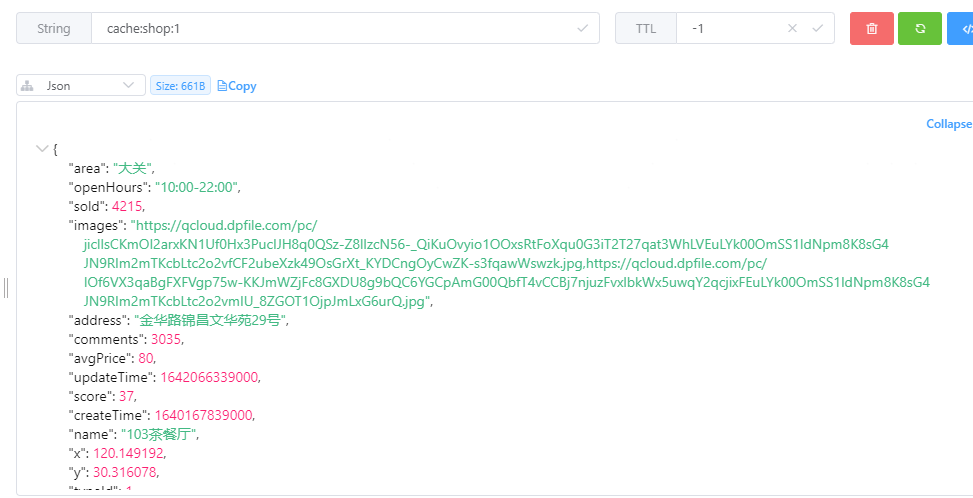
再次查询id=1的商户信息,由于此时Redis中已经存在数据,所以会直接从Redis中返回。控制台打印信息如下(省略了一些不重要的信息):
query Shop by id = 1
get from Redis: Key = cache:shop:1, Value = {"area":"大关","openHours":"10:00-22:00",...省略...,"id":1}
再比较一下两次查询的性能,第二次查询耗时15ms,比前面直接查询数据库的方式的62ms要快。
4.2.3 数据一致性问题及其解决方案
4.2.3.1 问题分析
如果我们向Redis添加的大量数据,就会导致Redis缓存中的数据过多,为了节约宝贵的内存资源,Redis会对部分数据进行动态更新。 主要有三种方式:
- 1)内存淘汰
在Redis的配置文件redis.conf中,有两个关于内存淘汰的配置:
# 最大内存限制
maxmemory 512mb
# 当达到最大内存限制时的缓存更新策略
maxmemory-policy noeviction
maxmemory用于配置最大内存限制,当Redis中保存的数据超过该限制时,就会根据maxmemory-policy配置的策略自动淘汰一部分数据。
- 2)超时剔除
Redis支持单独为每个Key设置有效期,超过有效期后,Redis会自动删除。
- 3)主动更新
我们还可以手动调用Redis的DEL命令删除数据,通常用于解决缓存和数据库不一致的问题。
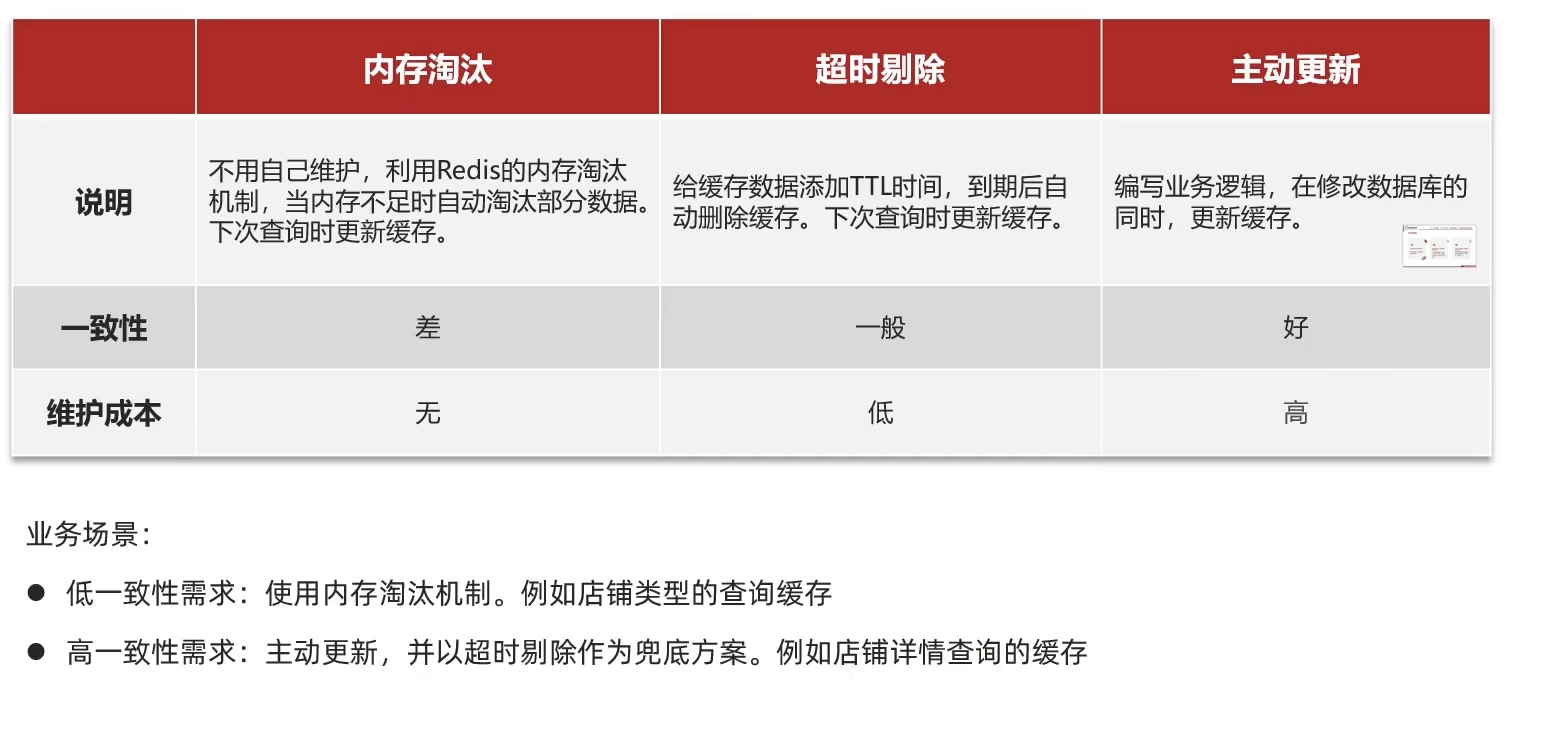
Redis缓存中的数据来源于数据库,因此当数据库的数据发生变化时,如果Redis缓存没有同步,就会产生数据一致性问题。
解决数据一致性问题也有三种方案:
- 1)Cache Aside Pattern:人工编码方式,由开发者在更新完数据库后再去更新缓存,也称之为双写方案。
- 2)Read/Write Through Pattern:缓存与数据库整合为一个服务,由该服务来维护缓存与数据库的数据一致性。
- 3)Write Behind Caching Pattern:调用者只操作缓存,由其他线程去异步处理数据库实现数据的最终一致。
通常情况下,双写方案是最易实现,且可靠性最好的方案。因此本案例采用的就是双写方案。
下面继续来考虑双写方案的两个问题:
- 1)无效写操作过多问题
假设需要对数据库的记录进行N次修改。如果每次修改记录后都更新缓存,则需要更新N次缓存,但如果在这N次修改期间并没有另一个用户查询数据,那对缓存来说,只有最后一次更新是有效的,中间的几次更新都是无效的。这就导致了无效写操作较多的问题。
要避免这个问题,可以放弃每次修改记录都更新缓存的方案,而是在修改记录后删除缓存,等待再次查询时再更新缓存。这样就能确保缓存中的数据始终是最新的,且避免多次写操作。
- 2)操作顺序问题
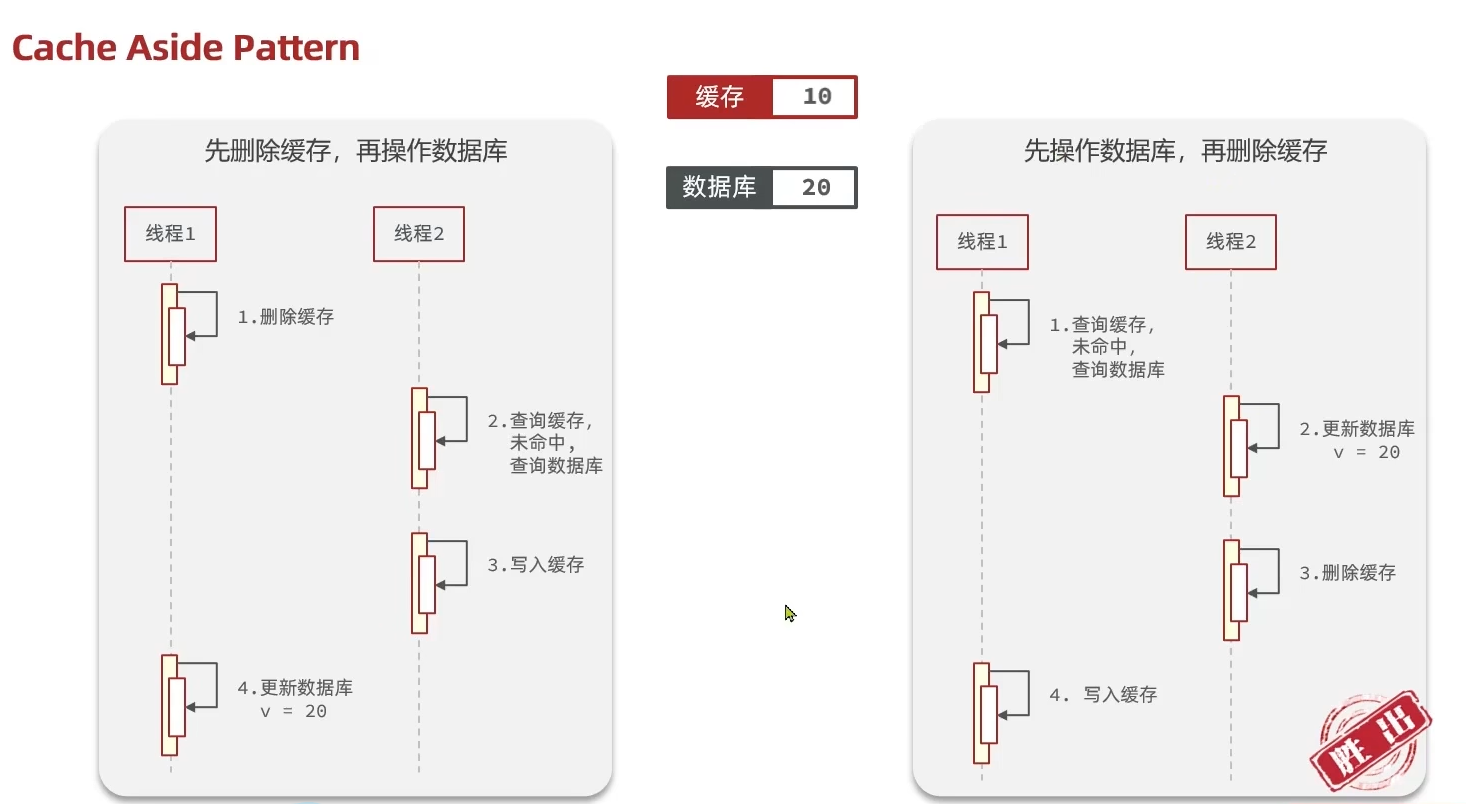
先修改数据库,再更新缓存?还是先更新缓存,再修改数据库?
答案是先修改数据库,再更新缓存。 原因如下:
4.2.3.2 实现商户信息的双写一致
- 1)修改ShopServiceImpl类的
queryShopById()方法
根据id查询商户时,如果缓存中没有,则查询数据库,再将数据库结果写入缓存并返回。此处将写入缓存这一步,增设超时时间。到时间后商户缓存自动失效,再次查询时自动更新为最新信息。
// com.star.redis.dzdp.service.impl.ShopServiceImpl#queryShopById()
// 5.将商户信息写入Redis
// 旧逻辑
// stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop));
// 新逻辑:增设超时时间,30分钟
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop), 30, TimeUnit.MINUTES);
- 2)实现根据ID修改商户信息功能
接口文档如下:
| 项目 | 说明 |
|---|---|
| 请求方式 | POST |
| 请求路径 | /shop/edit |
| 请求参数 | Shop |
| 返回值 | 无 |
在ShopController类中白那些一个editById()方法,调用IShopService接口的editShopById()方法:
// com.star.redis.dzdp.controller.ShopController
/**
* 根据ID修改商户信息
* @author hsgx
* @since 2024/4/3 15:17
* @param shop
* @return com.star.redis.dzdp.pojo.BaseResult
*/
@PostMapping("/edit")
public BaseResult edit(@RequestBody Shop shop) {
return shopService.editShopById(shop);
}
然后在IShopService接口的实现类ShopServiceImpl类中编写editShopById()方法:
// com.star.redis.dzdp.service.impl.ShopServiceImpl
@Override
public BaseResult editShopById(Shop shop) {
log.info("edit Shop by id = {}", shop.toString());
if(shop.getId() == null) {
return BaseResult.setFail("商户ID不能为空");
}
// 1.更新数据库记录
updateById(shop);
// 2.删除缓存
Boolean delete = stringRedisTemplate.delete("cache:shop:" + shop.getId());
log.info("delete from Redis: Key = {}, result = {}", "cache:shop:" + shop.getId(), delete);
return BaseResult.setOk();
}
最后进行功能测试:
调用/shop/1接口获取id=1的商户信息,日志显示从Redis直接返回:
query Shop by id = 1
get from Redis: Key = cache:shop:1, Value = {"area":"大关","openHours":"10:00-22:00",...省略...,"id":1}
调用/shop/edit接口修改id=1的商户信息,日志显示先修改数据库记录后删除Redis缓存:
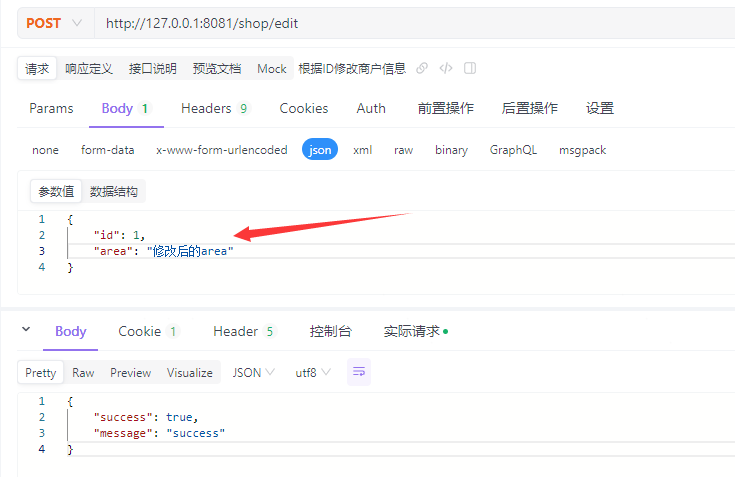
edit Shop by id = Shop(id=1, name=null, typeId=null, images=null, area=修改后的area, address=null, x=null, y=null, avgPrice=null, sold=null, comments=null, score=null, openHours=null, createTime=null, updateTime=null, distance=null)
==> Preparing: UPDATE tb_shop SET area=? WHERE id=?
==> Parameters: 修改后的area(String), 1(Long)
<== Updates: 1
delete from Redis: Key = cache:shop:1, result = true
再次调用/shop/1接口获取id=1的商户信息,日志显示从数据库查询后再存入Redis,且数据是最新的:
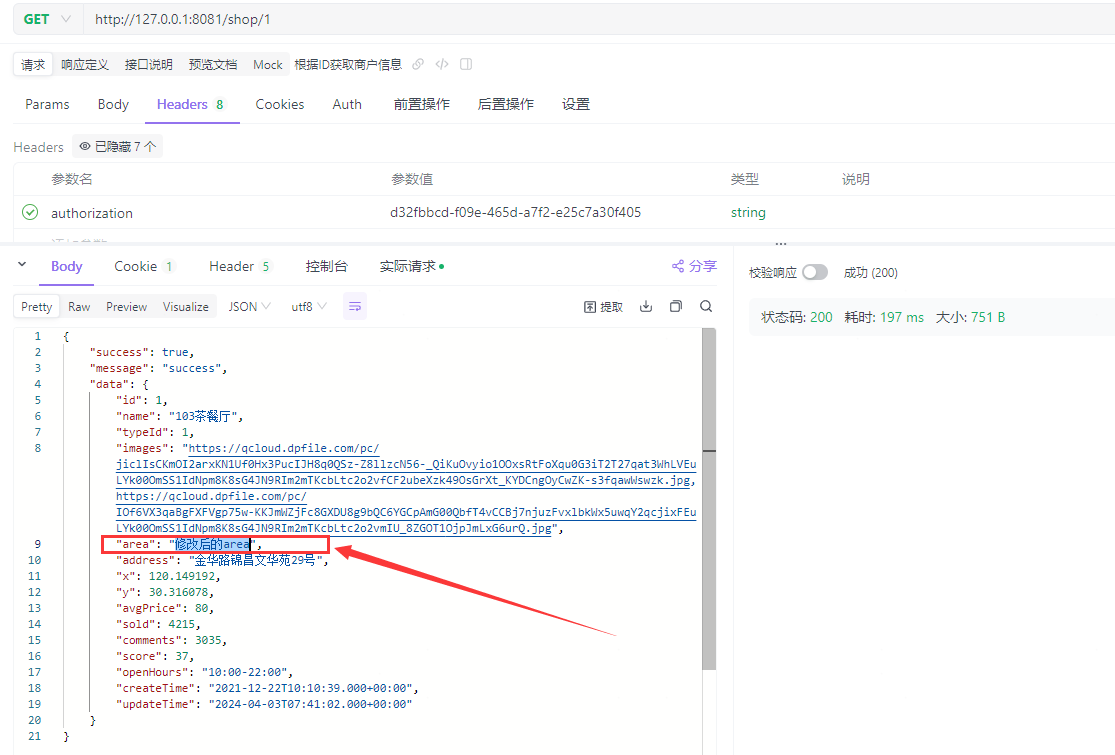
query Shop by id = 1
get from Redis: Key = cache:shop:1, Value = null
==> Preparing: SELECT id,name,type_id,images,area,address,x,y,avg_price,sold,comments,score,open_hours,create_time,update_time FROM tb_shop WHERE id=?
==> Parameters: 1(Long)
<== Total: 1
set to Redis: Key = cache:shop:1, Value = {"area":"修改后的area","openHours":"10:00-22:00",...省略...,"id":1}
4.2.4 缓存穿透问题及其解决方案
4.2.4.1 什么是缓存穿透问题
查询商户信息时,目前的做法仍然存在漏洞,即当id=100时,Redis和数据库都没有数据,程序最终会操作数据库。那如果有大量id=100的查询请求,每次都会去查询数据库,Redis缓存就相当于摆设了。
这就是缓存穿透问题,即客户端请求的数据在缓存中和数据库中都不存在,这些请求会穿透缓存,直击数据库,给数据库造成压力。
4.2.4.2 缓存穿透问题的解决方案
常见的解决缓存穿透问题的方案有两种:缓存空对象、布隆过滤。
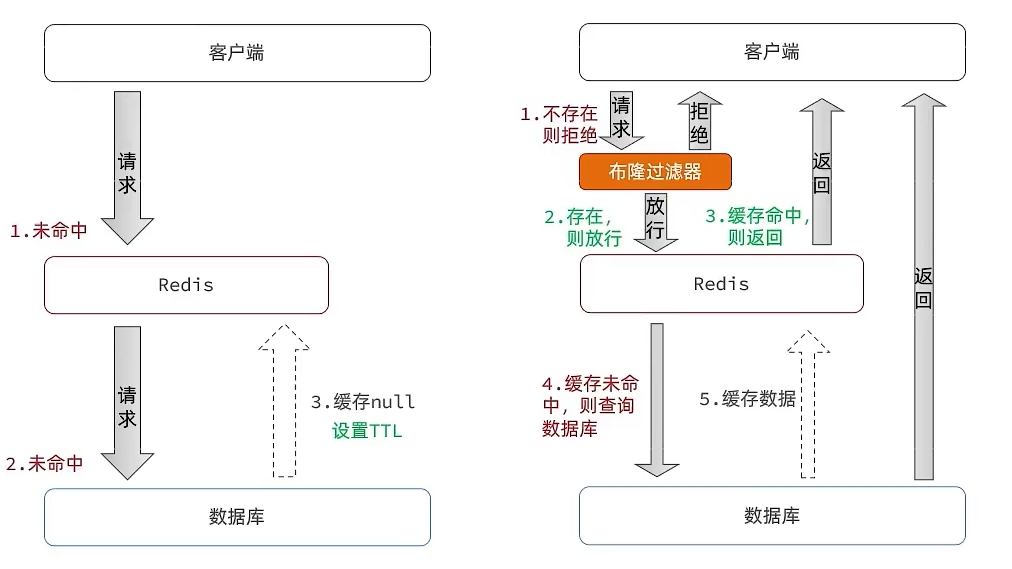
- 1)缓存空对象
服务端接收到查询请求后,如果Redis和数据库都不存在,也将这个数据存入Redis,只是其Value值设置为空字符串""。那么下次查询这个不存在的数据时,在Redis这里就可以知道数据不存在了,而不用继续访问数据库。
缓存空对象的优点在于实现简单、维护方便;缺点在于有额外的内存消耗。
- 2)布隆过滤
布隆过滤是指采用哈希思想来解决这个问题,通过一个庞大的二进制数组,利用哈希思想判断当前要查询的数据是否存在。如果布隆过滤器判断存在,则放行,这个请求会去访问Redis或数据库;如果布隆过滤器判断这个数据不存在,则直接返回不存在。
布隆过滤的优点在于节约内存空间,没有多余的Key;缺点是布隆过滤器走的是哈希思想,可能存在误判。
综合考虑,本案例采用缓存空对象的方案。
4.2.4.3 基于缓存空对象解决缓存穿透问题
修改ShopServiceImpl类的queryShopById方法:
// com.star.redis.dzdp.service.impl.ShopServiceImpl#queryShopById()
// 2.判断商户信息是否存在
if(StrUtil.isNotBlank(shopJson)) {
// 3.存在,直接返回
Shop shop = JSONUtil.toBean(shopJson, Shop.class);
return BaseResult.setOkWithData(shop);
} else if("".equals(shopJson)) {
// 新增逻辑:如果保存了空字符串,则说明是商户信息不存在,直接返回不存在
return BaseResult.setFail("商户不存在!");
}
// 4.不存在,根据ID查询数据库
Shop shop = getById(id);
// 旧逻辑:shop为空时直接返回不存在
// 新逻辑:要将字符串写入Redis,因此这里不直接返回
// if(shop == null) {
// return BaseResult.setFail("商户不存在!");
// }
// 5.将商户信息写入Redis
// 新逻辑:如果商户信息为空,则将空字符串写入Redis
stringRedisTemplate.opsForValue().set(key,
shop != null ? JSONUtil.toJsonStr(shop) : "",
30, TimeUnit.MINUTES);
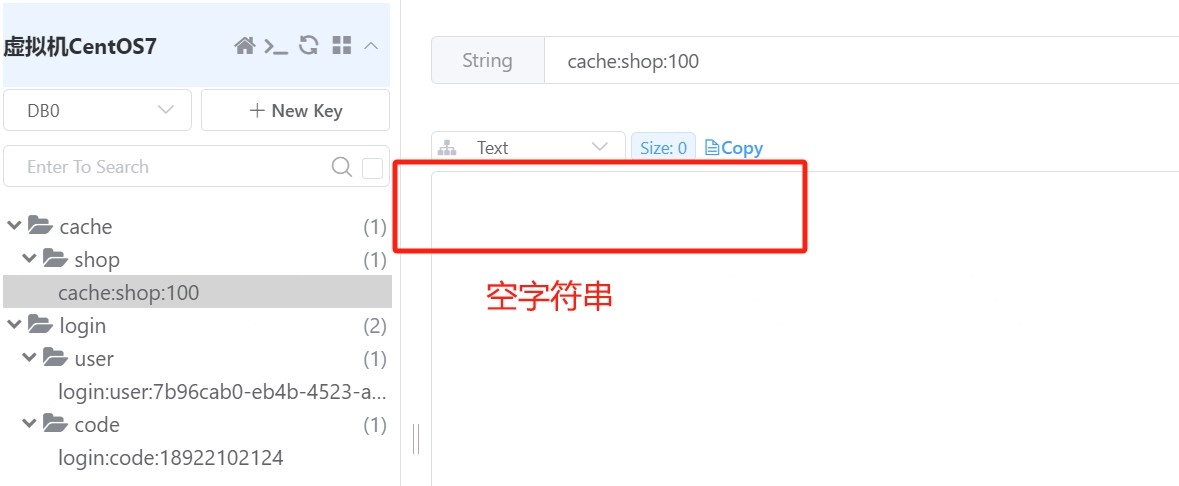
接下来进行功能测试:调用/shop/100接口获取id=100的商户信息,日志显示将空字符串写入了Redis:
query Shop by id = 100
get from Redis: Key = cache:shop:100, Value = null
==> Preparing: SELECT id,name,type_id,images,area,address,x,y,avg_price,sold,comments,score,open_hours,create_time,update_time FROM tb_shop WHERE id=?
==> Parameters: 100(Long)
<== Total: 0
set to Redis: Key = cache:shop:100, Value = null
查看Redis中保存的数据:
再次调用/shop/100接口获取id=100的商户信息,日志显示从Redis中获取到了空值,注解返回商户不存在:
query Shop by id = 100
get from Redis: Key = cache:shop:100, Value =
4.2.5 缓存击穿问题及其解决
4.2.5.1 什么是缓存击穿问题
缓存击穿问题也叫热点Key问题,就是一个被高并发访问并且缓存重建业务较复杂的Key突然失效了,大量的请求击穿缓存到达数据库,给数据库造成压力。 例如:
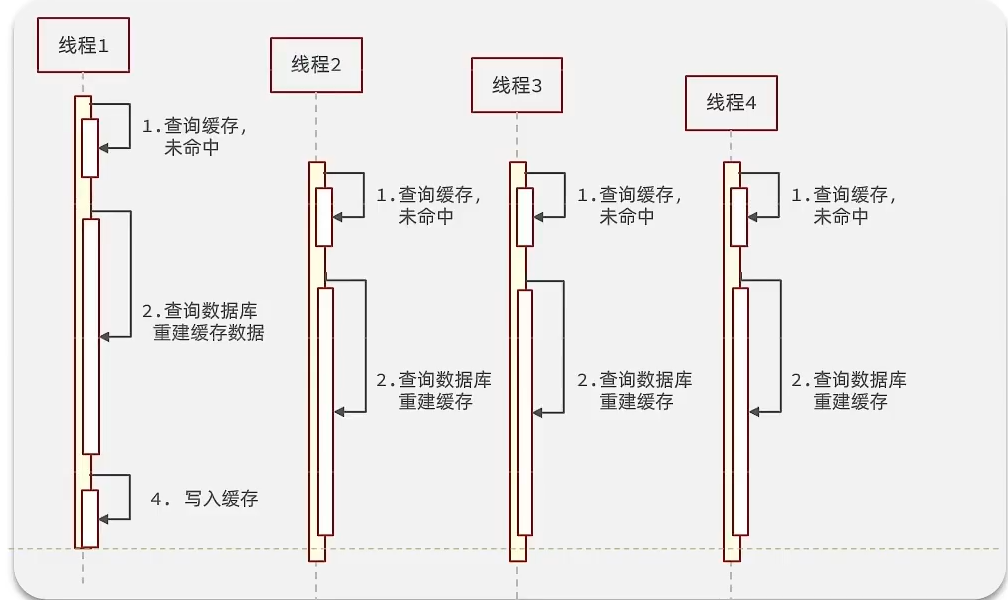
如上图所示,线程1查询缓存未命中,然后继续查询数据库并重建缓存数据,但由于重建缓存数据业务复杂,没等重建完成,线程2、3、4就来查询缓存了,线程2、3、4都不能从缓存中查到数据,转而去查数据库。最终结果是4个线程都访问了数据库,给数据库造成压力。
4.2.5.2 缓存击穿问题的解决方案
解决方案一:互斥锁
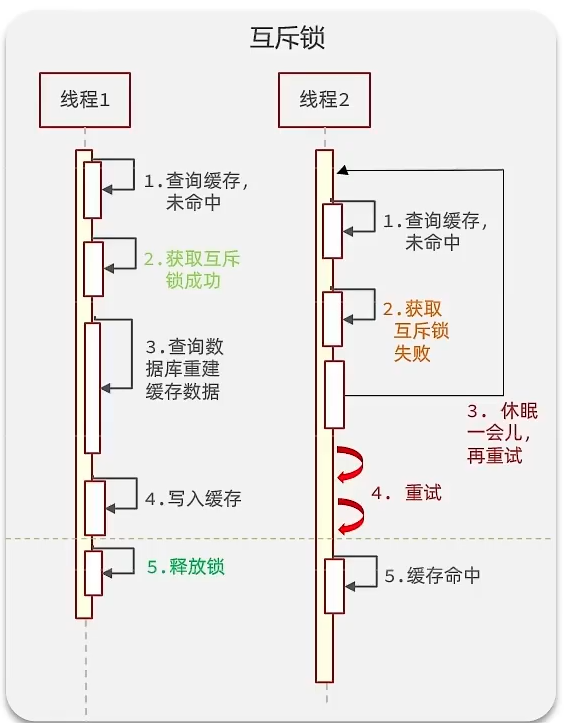
如上图所示,线程1查询缓存未命中,然后会获取互斥锁,获取到了锁再继续查询数据库并重建缓存数据,最后释放锁。而此时线程2查询缓存未命中,也去获取互斥锁,但锁只能一个线程使用,所以会获取失败,转而进入休眠状态,不断地尝试查询缓存和获取锁这两步;等线程1重建缓存完成并释放锁后,线程2获取到互斥锁,就能跳出休眠状态,从缓冲中获取到数据了。
解决方案二:逻辑过期
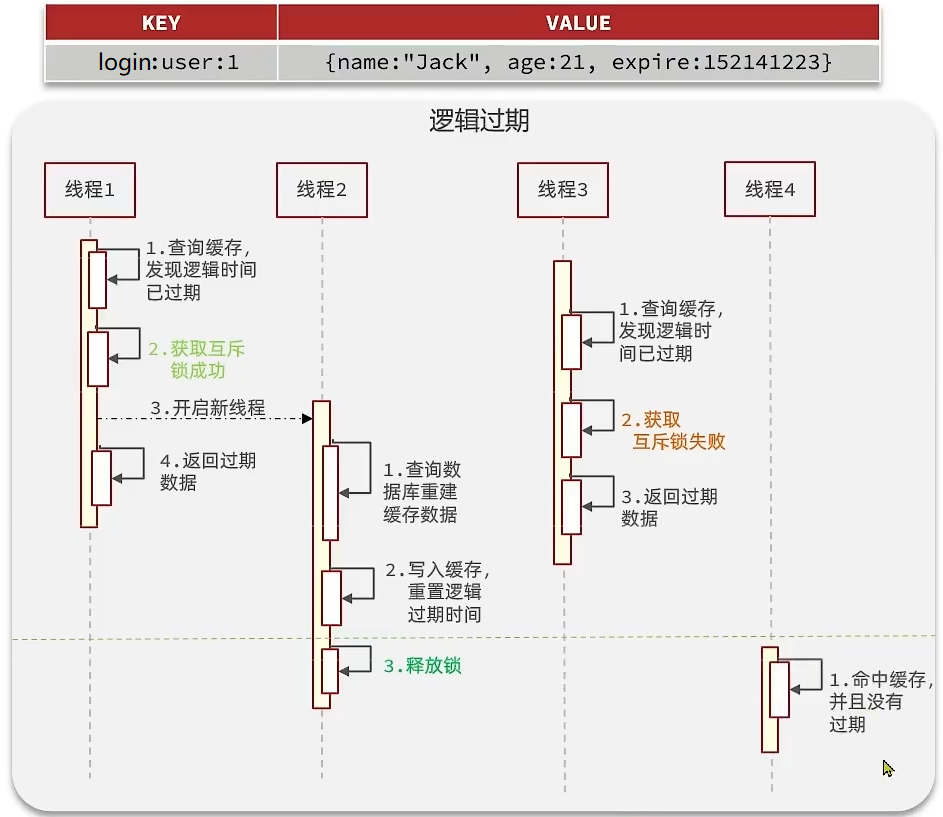
如上图所示,逻辑过期方案的要点是不对key设置过期时间,而是将过期时间设置在Value值中。 假设线程1查询缓存,发现逻辑时间已经过期,则开启一个新的线程2并直接返回过期的数据。线程2获取互斥锁,去查询数据库和重构缓存数据,完成后释放锁。假设线程3过来访问,由于线程2持有着锁,所以线程3无法获得锁,线程3也直接返回过期数据,只有等到线程2重建缓存数据完成后,才能返回正确的数据。
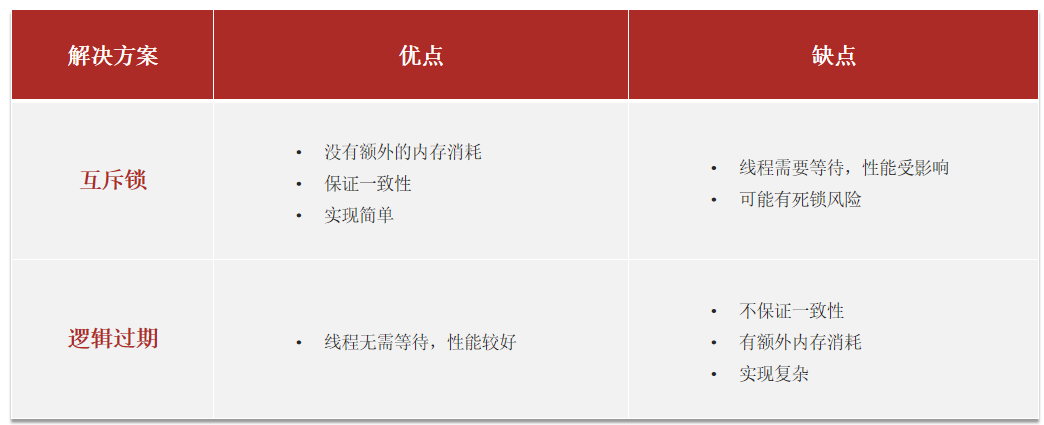
两种解决方案各有优缺点:
互斥锁:由于保证了互斥性,所以数据一致,且实现简单,仅仅只需要加一把锁,没有额外的内存消耗,缺点在于有锁就有死锁问题的发生,且只能串行执行,性能会受到影响。
逻辑过期:线程读取过程中不需要等待,性能好,有一个额外的线程持有锁去进行重构数据,但是在重构数据完成前,其他的线程只能返回之前的脏数据,且实现起来麻烦。
4.2.5.3 利用互斥锁解决缓存击穿问题
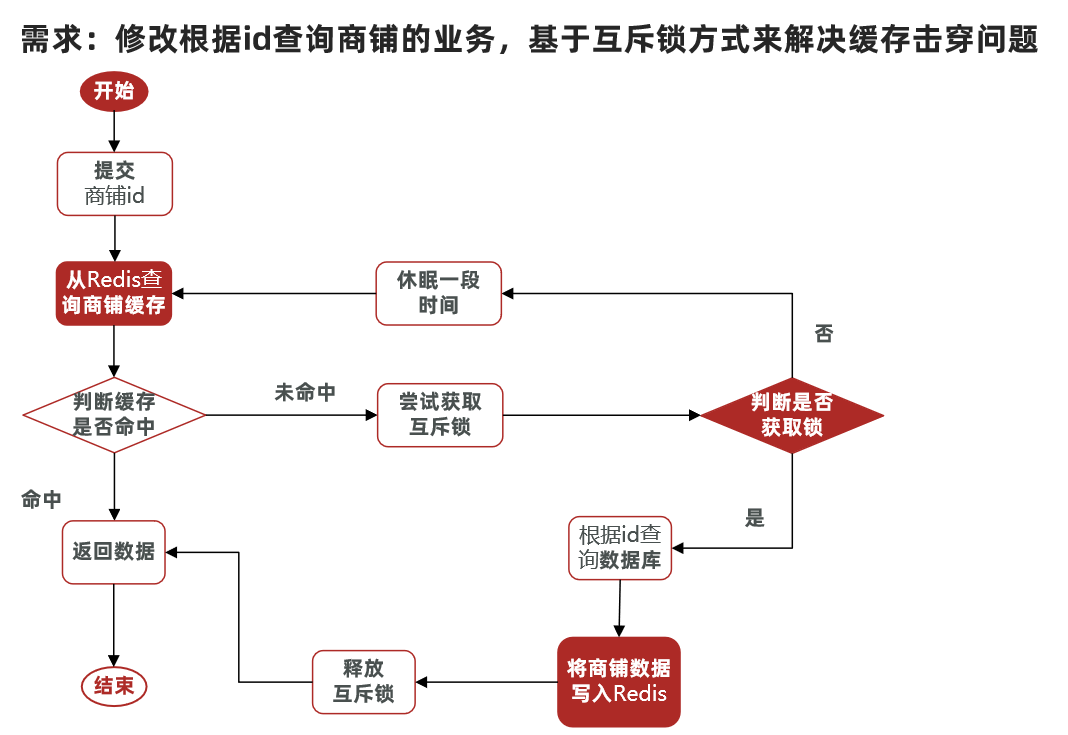
如上图所示,要利用互斥锁解决缓存击穿问题,可以在缓存未命中时,尝试获取互斥锁,只有获取到了互斥锁,才能查询数据库并将查询结果写入Redis;而没有获取到互斥锁时,则进行休眠,并重试查询缓存。
在持有互斥锁的线程完成查询数据库并将查询结果写入Redis的动作之前,其他没有获得互斥锁的线程不断重复地从Redis拿数据,直到互斥锁被释放后,才能从Redis拿到数据。
下面正式进行代码编写。首先要对互斥锁进行设计:
Redis的String类型有一个SETNX方法,该方法会尝试添加一个String类型的键值对,前提是这个key不存在,否则不执行。我们可以利用这个方法来获取互斥锁,如果调用该方法成功,说明Key不存在,获取互斥锁成功;调用该方法失败,说明Key已存在,获取互斥锁失败。
在ShopServiceImpl类中编写获取互斥锁的tryLock()方法,以及释放锁的unLock()方法:
// com.star.redis.dzdp.service.impl.ShopServiceImpl
/**
* 获取互斥锁
* @author hsgx
* @since 2024/4/3 17:19
* @param key
* @return boolean
*/
private boolean tryLock(String key) {
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS);
return BooleanUtil.isTrue(flag);
}
/**
* 释放锁
* @author hsgx
* @since 2024/4/3 17:20
* @param key
* @return void
*/
private void unLock(String key) {
stringRedisTemplate.delete(key);
}
接着在IShopService接口中定义一个queryShopByIdWithLock()方法,并在其实现类ShopServiceImpl中具体实现,功能仍然是根据ID查询商户信息,只是添加了互斥锁:
// com.star.redis.dzdp.service.impl.ShopServiceImpl
public BaseResult<Shop> queryShopByIdWithLock(Long id) {
log.info("query Shop by id = {}", id);
// 1.构建Key,并从Redis中查询商户信息
String key = "cache:shop:" + id;
String shopJson = stringRedisTemplate.opsForValue().get(key);
log.info("get from Redis: Key = {}, Value = {}", key, shopJson);
// 2.判断商户信息是否存在
if(StrUtil.isNotBlank(shopJson)) {
// 存在,直接返回
Shop shop = JSONUtil.toBean(shopJson, Shop.class);
return BaseResult.setOkWithData(shop);
} else if("".equals(shopJson)) {
// 如果保存了空字符串,则说明是商户信息不存在,直接返回不存在
return BaseResult.setFail("商户不存在!");
}
// 3.使用互斥锁方案解决缓存击穿问题
String lockKey = "lock:shop:" + id;
Shop shop = null;
try {
// 尝试获取互斥锁
boolean isLock = tryLock(lockKey);
log.info("isLock = {}", isLock);
if(!isLock) {
// 没有获取到互斥锁,则休眠重试
log.info("Retry queryShopByIdWithLock()...");
Thread.sleep(50);
return queryShopByIdWithLock(id);
}
// 获取到了互斥锁,则根据ID查询数据,并重构缓存数据
shop = getById(id);
if(shop == null) {
// 商户不存在,保存空字符串
stringRedisTemplate.opsForValue().set(key, "", 30, TimeUnit.MINUTES);
log.info("set to Redis: Key = {}, Value = \"\"", key);
return BaseResult.setFail("商户不存在!");
} else {
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop), 30, TimeUnit.MINUTES);
log.info("set to Redis: Key = {}, Value = {}", key, JSONUtil.toJsonStr(shop));
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// 释放锁
unLock(lockKey);
}
return BaseResult.setOkWithData(shop);
}
然后修改ShopController类中的调用方法:
// com.star.redis.dzdp.controller.ShopController
@GetMapping("/{id}")
public BaseResult<Shop> queryById(@PathVariable Long id) {
//return shopService.queryShopById(id);
// 使用互斥锁解决缓存击穿问题
return shopService.queryShopByIdWithLock(id);
}
修改完毕后,进行功能测试:首先在shop = getById(id);这一行代码上打一个断点,用于模拟重建缓存数据的时间很久。
然后调用/shop/102接口获取id=102的商户信息,日志显示线程5从Redis中没有获取到数据,并获取互斥锁成功,进入查询数据库和重建缓存的逻辑,停在了断点处:
[http-nio-8081-exec-5] query Shop by id = 102
[http-nio-8081-exec-5] get from Redis: Key = cache:shop:102, Value = null
[http-nio-8081-exec-5] tryLock key = lock:shop:102
[http-nio-8081-exec-5] isLock = true
接着再次调用/shop/102接口获取id=102的商户信息,日志显示线程6从Redis中没有获取到数据,并获取互斥锁失败,进入重试逻辑,再次调用queryShopByIdWithLock()方法:
[http-nio-8081-exec-6] query Shop by id = 102
[http-nio-8081-exec-6] get from Redis: Key = cache:shop:102, Value = null
[http-nio-8081-exec-6] tryLock key = lock:shop:102
[http-nio-8081-exec-6] isLock = false
[http-nio-8081-exec-6] Retry queryShopByIdWithLock()...
此时放开断点,线程5继续执行,查询数据库信息,并将查询结果写入Redis,最后释放锁:
[http-nio-8081-exec-5] ==> Preparing: SELECT id,name,type_id,images,area,address,x,y,avg_price,sold,comments,score,open_hours,create_time,update_time FROM tb_shop WHERE id=?
[http-nio-8081-exec-5] ==> Parameters: 102(Long)
[http-nio-8081-exec-5] <== Total: 0
[http-nio-8081-exec-5] set to Redis: Key = cache:shop:102, Value = ""
锁释放后,线程6已可以从Redis中拿到数据并返回结果:
[http-nio-8081-exec-6] query Shop by id = 102
[http-nio-8081-exec-6] get from Redis: Key = cache:shop:102, Value =
至此,基于互斥锁的方案测试完成。
4.2.5.4 利用逻辑过期解决缓存击穿问题
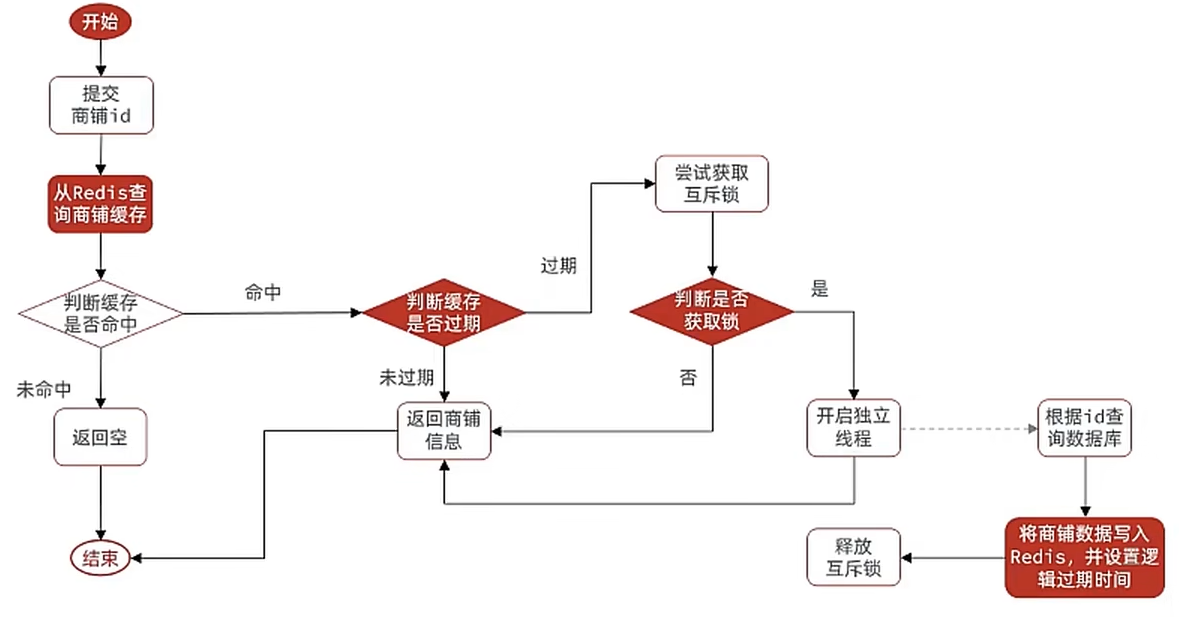
由上图可知,当查询缓存未命中时,则直接返回空;如果命中了,则将缓存数据中的Value值取出,判断Value值中保存的时间是否过期,如果没有过期,则直接返回缓存数据;如果过期了,则获取互斥锁,并开启一个独立的线程后直接返回过期数据。
独立线程负责查询数据库并更新缓存数据。而其他线程在获得过期数据后,由于无法获取互斥锁,也直接返回过期数据。
下面开始编写代码。由于要在Value值中保存过期时间,我们首先要重新定义一个保存到Redis的实体类。
// com.star.redis.dzdp.pojo.RedisData
@Data
public class RedisData {
private Date expireTime;
private Object data;
}
接着在IShopService接口中定义一个queryShopByIdWithExpire()方法,并在其实现类ShopServiceImpl中具体实现,功能仍然是根据ID查询商户信息,只是添加了逻辑过期:
// com.star.redis.dzdp.service.impl.ShopServiceImpl
private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);
@Override
public BaseResult<Shop> queryShopByIdWithExpire(Long id) {
log.info("query Shop by id = {}", id);
// 1.构建Key,并从Redis中查询商户信息
String key = "cache:shop:" + id;
String shopJson = stringRedisTemplate.opsForValue().get(key);
log.info("get from Redis: Key = {}, Value = {}", key, shopJson);
// 2.商户信息不存在,直接返回
if(StrUtil.isBlank(shopJson)) {
return BaseResult.setFail("商户不存在!");
}
// 3.商户信息存在,先反序列化为Java对象
RedisData redisData = JSONUtil.toBean(shopJson, RedisData.class);
Date expireTime = redisData.getExpireTime();
Shop shop = JSONUtil.toBean((JSONObject) redisData.getData(), Shop.class);
// 4.判断是否过期
if(expireTime.after(new Date())) {
// 没过期,直接返回数据
return BaseResult.setOkWithData(shop);
}
// 5.已过期,则尝试获取互斥锁
String lockKey = "lock:shop:" + id;
try {
boolean isLock = tryLock(lockKey);
log.info("isLock = {}", isLock);
if(!isLock) {
// 没有获取到互斥锁,则直接返回过期数据
return BaseResult.setOkWithData(shop);
}
// 获取到了互斥锁,则开启一个新的线程
log.info("create a new thread ...");
CACHE_REBUILD_EXECUTOR.submit(() -> {
log.info("a new thread begin...");
// 查询数据库
Shop newShop = getById(id);
// 写入Redis
RedisData newRedisDate = new RedisData();
newRedisDate.setData(newShop);
long expire = System.currentTimeMillis() + 30 * 60 * 1000;
newRedisDate.setExpireTime(new Date(expire));
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(newRedisDate));
log.info("set to Redis: Key = {}, Value = {}", key, JSONUtil.toJsonStr(newRedisDate));
// 释放锁
unLock(lockKey);
log.info("a new thread end...");
});
} catch (Exception e) {
e.printStackTrace();
}
// 当前线程直接返回过期数据
return BaseResult.setOkWithData(shop);
}
然后修改ShopController类中的调用方法:
// com.star.redis.dzdp.controller.ShopController
@GetMapping("/{id}")
public BaseResult<Shop> queryById(@PathVariable Long id) {
// return shopService.queryShopById(id);
// 使用互斥锁解决缓存击穿问题
// return shopService.queryShopByIdWithLock(id);
// 使用逻辑过期解决缓存击穿问题
return shopService.queryShopByIdWithExpire(id);
}
由于在queryShopByIdWithExpire()方法中,只要Redis未命中就直接返回不存在,因此这种方式需要进行初始化,也就是将数据库的商户信息同步一次到Redis中。
假设现在初始化过了,在Redis中有这样一条数据:

然后我们在线程内部添加一行代码Thread.sleep(30 * 1000);,用于模拟新线程重建缓存数据的时间很久。

接着调用/shop/2接口获取id=2的商户信息,日志显示线程1从Redis中没有获取到了过期数据,并获取互斥锁成功,然后创建新线程:
[http-nio-8081-exec-1] query Shop by id = 2
[http-nio-8081-exec-1] get from Redis: Key = cache:shop:2, Value = {"data":{"area":"拱宸桥/上塘","openHours":"11:30-03:00",...省略...,"id":2},"expireTime":1640170813000}
[http-nio-8081-exec-1] tryLock key = lock:shop:2
[http-nio-8081-exec-1] isLock = true
[http-nio-8081-exec-1] create a new thread ...
然后新线程[pool-1-thread-1]进入30s睡眠,模拟耗时很长。 此时一个新的请求过来,线程2开始执行,日志显示线程2从Redis拿到了过期数据,但获取互斥锁失败,直接返回过期数据:
[pool-1-thread-1] a new thread begin...
[http-nio-8081-exec-2] query Shop by id = 2
get from Redis: Key = cache:shop:2, Value = {"data":{"area":"拱宸桥/上塘","openHours":"11:30-03:00",...省略...,"id":2},"expireTime":1640170813000}
[http-nio-8081-exec-2] tryLock key = lock:shop:2
[http-nio-8081-exec-2] isLock = false
新线程[pool-1-thread-1]休眠结束,查询数据库,并将查询结果更新到Redis,最后释放互斥锁:
[pool-1-thread-1] ==> Preparing: SELECT id,name,type_id,images,area,address,x,y,avg_price,sold,comments,score,open_hours,create_time,update_time FROM tb_shop WHERE id=?
[pool-1-thread-1] ==> Parameters: 2(Long)
[pool-1-thread-1] <== Total: 1
[pool-1-thread-1] set to Redis: Key = cache:shop:2, Value = {"data":{"area":"拱宸桥/上塘","openHours":"11:30-03:00",...省略...,"id":2},"expireTime":1712234901457}
[pool-1-thread-1] unLock key = lock:shop:2
[pool-1-thread-1] a new thread end...
至此,基于逻辑过期的方案也测试完成。
…
本节完,更多内容请查阅分类专栏:Redis从入门到精通
感兴趣的读者还可以查阅我的另外几个专栏:
- SpringBoot源码解读与原理分析(已完结)
- MyBatis3源码深度解析(已完结)
- 再探Java为面试赋能(持续更新中…)







![[AutoSar]BSW_Memory_Stack_004 创建一个简单NV block并调试](https://img-blog.csdnimg.cn/direct/cf7515a471fb4dabb035da6bb88e0278.png)