本次DPO训练采用TRL的方式来进行训练
Huggingface TRL是一个基于peft的库,它可以让RL步骤变得更灵活、简单,你可以使用这个算法finetune一个模型去生成积极的评论、减少毒性等等。
本次进行DPO的模型是一个500M的GPT-2,目的是训练快,少占资源,快速看到结果。
下载Tokenizer:
from transformers import AutoTokenizer
AutoTokenizer.from_pretrained('gpt2').save_pretrained('tokenizer/gpt2')
下载Datasets:
from datasets import load_dataset
load_dataset('b-mc2/sql-create-context').save_to_disk(
'dataset/b-mc2/sql-create-context')
下载Model:
from transformers import AutoModelForCausalLM
AutoModelForCausalLM.from_pretrained('gpt2').save_pretrained('model/gpt2')

图 下载Tokenizer,model,数据
首先我们看一下原始数据集,原始数据集的构成分为3部分,一个是question,代表想提出的问题,一个是answer代表回答,第三部分是context代表参考的表结构。
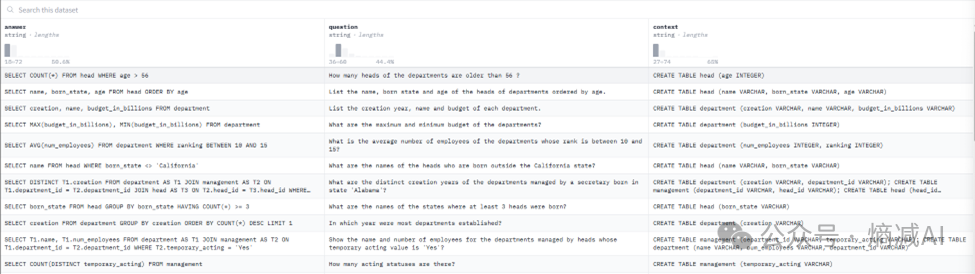
图 原始数据集

图 数据集样例
实际数据样例,我们进一步规范了三种数据类型:
·第一个prompt,包含了context表结构和问题。
·第二个chose,表示希望训练之后的模型按着什么范式来回答问题。
·第三个reject,表示不希望用什么方式来回答,这里就留空了,代表隐式确认,如果有条件也可以整理不喜欢的回答范式。
这个训练的目的就是不管回答什么问题,都要用SQL语句的形式来回答,强调一种受欢迎回答的范式,这也是RLHF/DPO训练的主要目的。
下面开始训练部分,首先load tokenizer。
图8-9 load tokenizer
按照需求来整理数据格式。
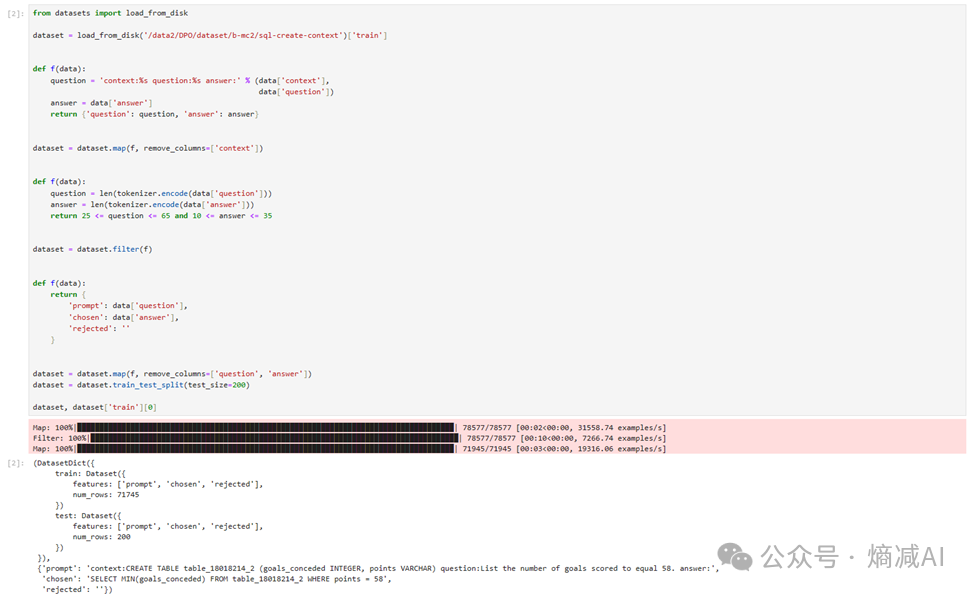
图 整理数据格式
读取模型。
from transformers import AutoTokenizer
import random
import torch
tokenizer = AutoTokenizer.from_pretrained('/data2/DPO/tokenizer/gpt2')
tokenizer.pad_token_id = 0
tokenizer
from transformers import AutoModelForCausalLM
model_dpo = AutoModelForCausalLM.from_pretrained('/data2/DPO/model/gpt2').to('cuda')
model_dpo_ref = AutoModelForCausalLM.from_pretrained('/data2/DPO/model/gpt2').to('cuda')
先做个测试看看模型目前是怎么回答的。
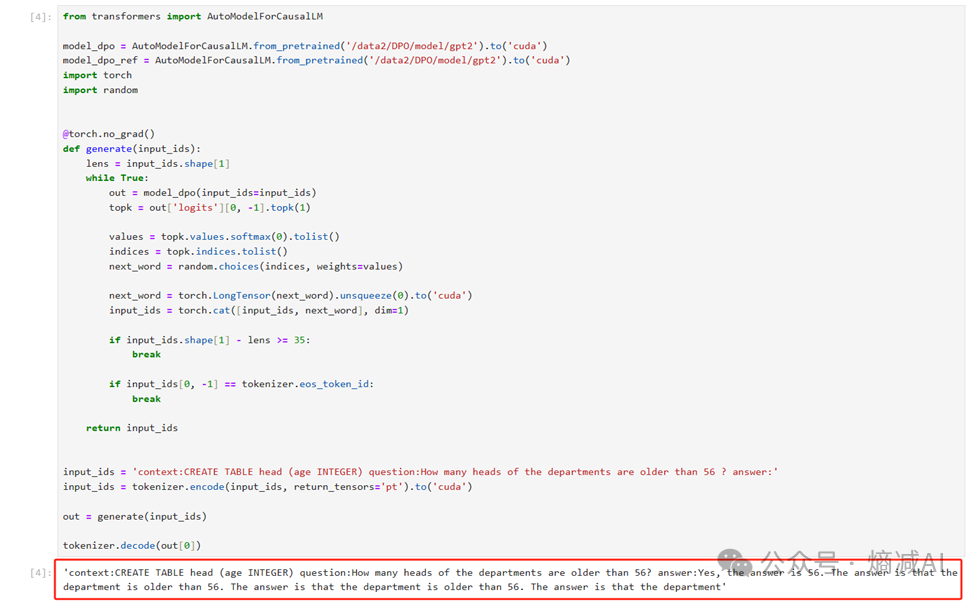
图 训练前的回答方式
如上图所示,很显然这个回答方式不是我们要求的方式,我们需要它把问题都按着SQL语句来进行回答。
最后一步就是正式训练了。
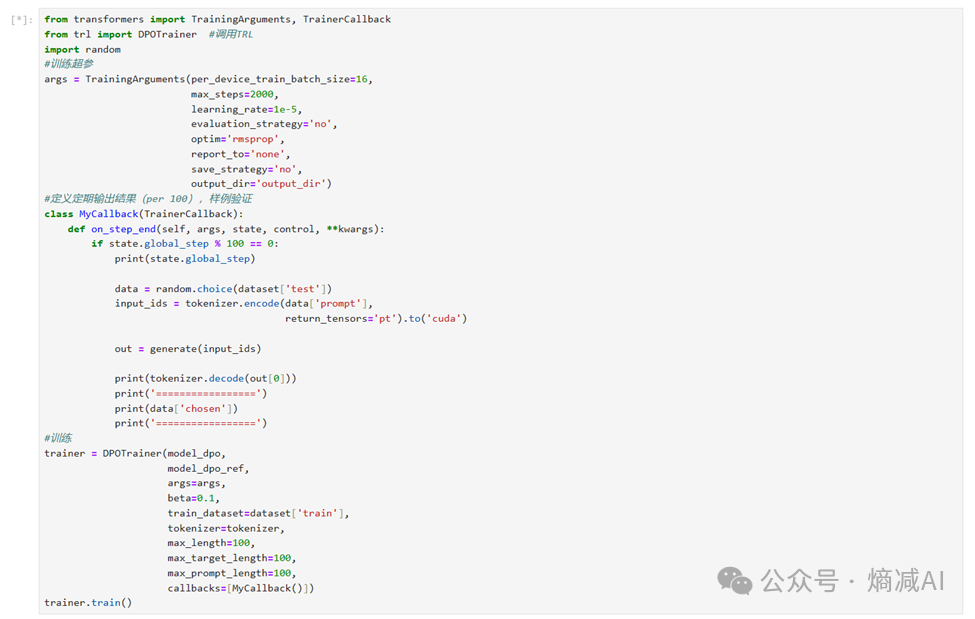
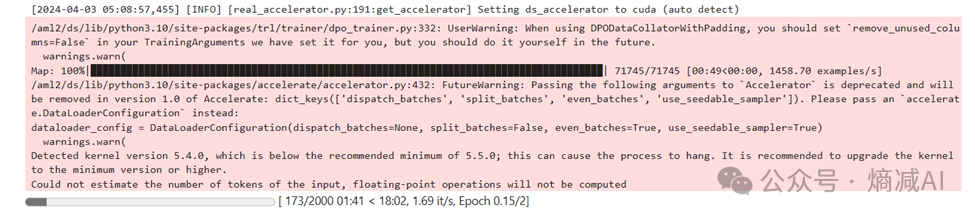

如上图所示,随着训练的开展,模型回复对话的方式,基本就越来越向着正规SQL的方向演进。
这就是DPO训练所达成的目的。
也没有多废资源,我是点auto-map技能点了,正常也就一张A100够了。









![[技术闲聊]我对电路设计的理解(三)](https://img-blog.csdnimg.cn/direct/45bdfbf399c248039631876127124fab.png)