索引的基本认识
索引是为了快速检索和定位数据行而创建的一种数据结构。索引是由表中索引列数据进行排序后的集合和指向这些值的物理标识(例如:ROWID 等聚集索引键)共同组成。在 DM 中,除了位图索引、位图连接索引、全文索引和空间索引外,索引数据都采用 B+ 树结构进行存储,在 DM 手册的其余地方都简称为 B 树。索引也是占存储空间,所以我们需要将索引存储在专属的表空间中。
解析:
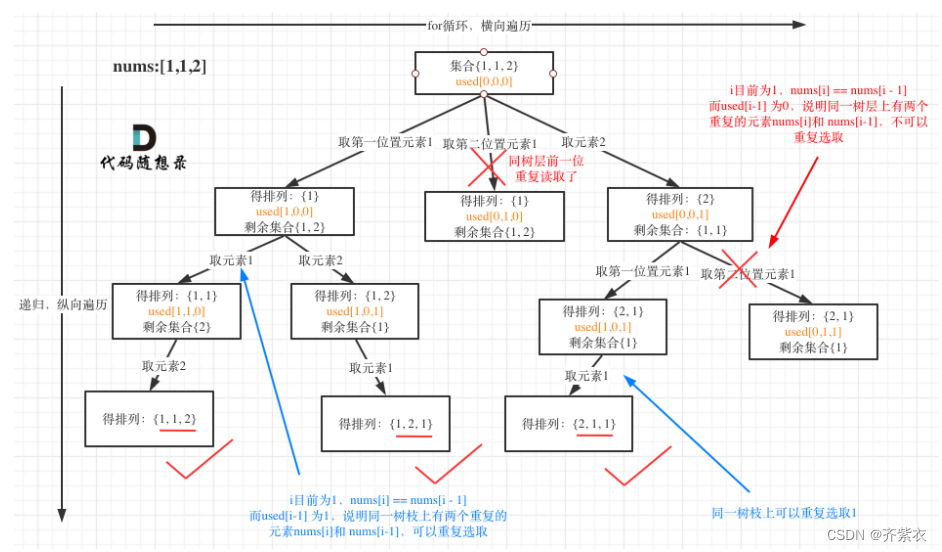
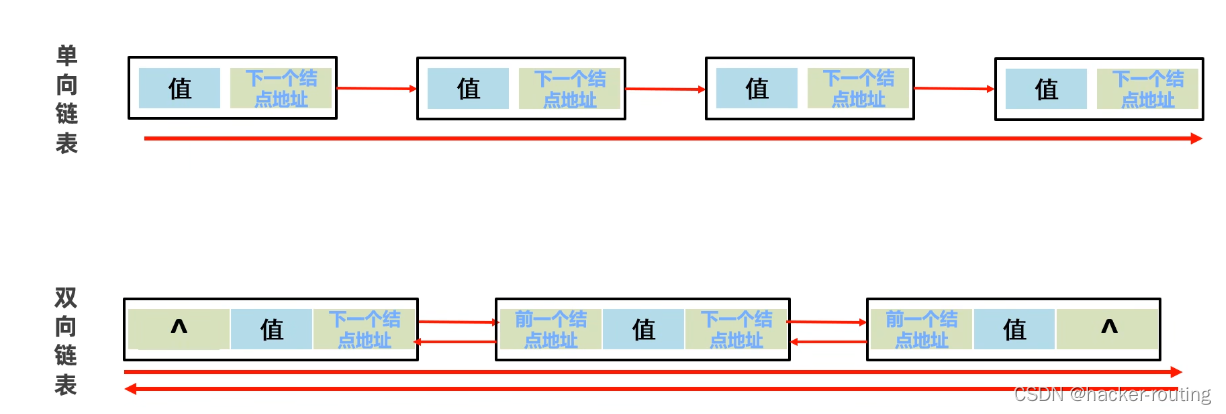
所有的数据页存放在叶子节点
深度比较小 访问层次不多
需要找的数据全部在叶子节点
叶子节点是双向链表 访问一个节点,就能访问到所有节点
叶子节点上不是一个数据,是一个PAGE,每个页默认大小16K

用户自己建立的索引 二级索引

索引相当于一本书的目录,根据目录中的页码标识快速检索并定位到的查找内容。
达梦默认的是索引组织表,当建表语句未指定聚簇索引键,DM 的默认的聚簇索引是 rowid,即记录默认以 rowid 在表中排序。
DM 提供三种方式供用户指定聚簇索引:
1、cluster primary key
2、Cluster key
3、Cluster unique key
DM8 索引:
1、聚簇索引:每一个索引组织表有且只有一个聚簇索引
2、唯一索引:保证表上的不会有两行数据具有相同的值. 3、函数索引:包含函数表达式的预先计算的值。
4、位图索引:列上的值的类型少
5、复合索引:表中两个或两个以上的列一起建立索引
6、全文索引:在表中文本列上建索引. 7、分区索引:
优点:
大大加快数据的检索速度
加速表和表之间的连接
缺点:
索引需要占物理空间
表中的数据进行DML操作时,增加数据库维护成本
聚集索引
DM8 中表(列存储表和堆表除外)都是使用 B 树索引结构管理的,每一个普通表都有且
仅有一个聚集索引,数据都通过聚集索引键排序,根据聚集索引键可以快速查询任何记录。
当建表语句未指定聚集索引键时,DM8 的默认聚集索引键是 ROWID。若指定索引键,表
中数据都会根据指定索引键排序。
建表后,DM8 也可以用创建新聚集索引的方式来重建表数据,并按新的聚集索引排序。
CREATE CLUSTER INDEX T1_CLUSTER ON T1(ID);
注意:
新建聚集索引会重建这个表以及其所有索引,包括二级索引、函数索引,是一个代价非
常大的操作。因此,最好在建表时就确定聚集索引键,或在表中数据比较少时新建聚集索引,
而尽量不要对数据量非常大的表建立聚集索引。
唯一索引
create tablespace "IND" datafile 'C:\Users\Admin\Desktop\DM\IND' size 32 CACHE = NORMAL;
create table SYSDBA.T1(id int ,name varchar(20));
create unique index SYSDBA.T1_ind on SYSDBA.T1(id) tablespace IND;
select owner,index_name,index_type,table_name from dba_indexes where table_name='T1';

DM8 创建 UNIQUE KEY 或 PRIMARY KEY 约束时,DM8 会隐式地自动创建唯一索引。
主键和唯一索引有什么不同:
1、主键是一个约束,唯一索引是一种索引
2、主键创建后包含唯一索引,唯一索引不一定是主键
3、一个表只能有一个主键,但是可以有多个唯一索引。
4、主键不能为 null, 唯一索引可以有多个 null 值
5、主键可以作为外键,唯一索引不可以。
函数索引
正确使用函数索引,可以带来以下好处:
- 创建更强有力的分类,例如可以用 UPPER 和 LOWER 函数执行区分大小写的分类;
- 预先计算出计算密集的函数的值,并在索引中将其分类。可以在索引中存储要经常
访问的计算密集的函数,当需要访问值时,该值已经计算出来了。因此,极大地改
善了查询的执行性能; - 增加了优化器执行范围扫描而不是全表扫描的情况的数量。
create table SYSDBA.emp as select * from dmhr.employee;
explain select employee_name, email from SYSDBA.emp where
upper(email)=upper('maxueming@dameng.com');

create index SYSDBA.ind_emp on SYSDBA.emp(upper(email)) tablespace IND;
explain select employee_name, email from SYSDBA.emp where
upper(email)=upper('maxueming@dameng.com');

单行函数:
字符: initcap lower upper lpad trim replace instr substr
数值运算:round trunc mod
日期: add_months month_between, next_day, last_day
SELECT DATE_ADD(sysdate,INTERVAL '2 1 ’ DAY TO SECOND);
复合索引
复合索引是由表中的多列构成,注意先后顺序
比如 where 条件使用得比较多的列,做前导列。
explain select employee_id,employee_name from sysdba.emp where employee_id=1001;

create index sysdba.emp_ind2 on sysdba.emp(employee_id,employee_name)
tablespace IND;
explain select employee_id,employee_name from sysdba.emp where employee_id=1001;

explain select employee_id from sysdba.emp where employee_name='马刚红';

explain select employee_id,employee_name from sysdba.emp where employee_id=1001 and employee_name='马刚红';

总结:
在复合索引中,单独使用前导列(第一列)优化器会走二级索引数据
定位 SSEK2,如果同时使用复合索引字段,优化器会走二级索引数据
定位 SSEK2。
如果单独使用非前导列,优化器走二级索引 SSCN 或是 CSCN2
索引在查询语句里面是否会用到和 sql 编写相关。包括索引的扫描方式,都会根据表中的列值分布,统计信息,过滤字段的不同而不同
位图索引
(1)用一个位来表示一个索引的键值,节省了存储空间
(2)对于 and ,or 或=的查询条件,位图索引查询效率高,善于处理
0,1 数据。
适合列上数值类型少的情况,比如说性别。位图索引适合 OLAP 环境。
对于 OLTP 环境位图索引基本上不适用的。
不合适:
1、频繁进行插入或更新的表。
2、列值很多,可选范围很大的表。
索引的维护
重建索引
Alter index sysdba.emp_ind2 rebuild;
Alter index sysdba.emp_ind2 rebuild online;
删除索引:
DROP INDEX sysdba.emp_ind2;
查看索引的相关信息
DBA_INDEXES, USER_INDEXES, SYSOBJECTS
有时候索引建立得不好,会使得性能变得慢,所以需要建立合适的索引。
注意:收集统计信息,查看统计信息,创建索引、重建索引、删除索引、 很耗用资源,需要在业务低峰期,
分区索引
分区表查询速度慢,可以建立分区索引。
在分区表上建立索引,子表上均为自动创建索引。
在分区表上删除索引,子表上的索引自动删除。
如果表是分区表,该表上创建的索引就是分区索引,非堆表每个
分区一个索引(局部索引),堆表可以创建全局索引,也可以创建局
部索引,在创建全局索引的时候指定 global 关键字。
create index "IND_SALE_SUM" on "TEST"."SALES_SUM"("SALE_ID")
storage(initial 1,next 1,minextents 1,on "IND");
create index "SYSDBA"."INDEX_PART" on "SYSDBA"."TABLE_4"("COLUMN_1") global storage(initial 1,next 1,minextents 1);
全文索引
全文检索技术是智能信息管理的关键技术之一,其主要目的就是实现
对大容量的非结构化数据的快速查找,DM 实现了全文检索功能,并
将其作为 DM 服务器的一个较独立的组件,提供更加准确的全文检索
功能,较好地解决了模糊查询方式带来的问题。
DM 中,全文索引必须在基表定义,而不能在系统表,视图,临时表,
列存表,外部表上定义,同一个列只能创建一个全文索引,在创建全
文索引的时候,用户可以为分词器定义分词参数,即控制分词器的数
量。
全文检索的中文分词依赖系统词库,该词库是只读的,不允许修改。
CHINESE_LEXER --中文最少分词
CHINESE_VGRAM_LEXER --机械双字分词
CHINESE_FP_LEXER 中文最多分词
ENGLISH_LEXER --英文分词
DEFAULT_LEXER --默认分词,中文英文最少分词
create context index cti_address on person .address(address1) lexer
default_lexer;
alter context index cti_address on person.address rebuild;
select * from person.address where contains(address1 ,'洪山区' and '太阳城' and
'202');
//全文索引更新
ALTER CONTEXT index cti_address on person.address rebuild;
//更新增加全文索引信息
ALTER CONTEXT INDEX CTI_ADDRESS ON PERSON.ADDRESS
INCREMENT;
//删除全文索引
drop context index "CTI_ADDRESS" on "PERSON"."ADDRESS";
//查看全文索引
Select * from ctisys.syscontextindexes;