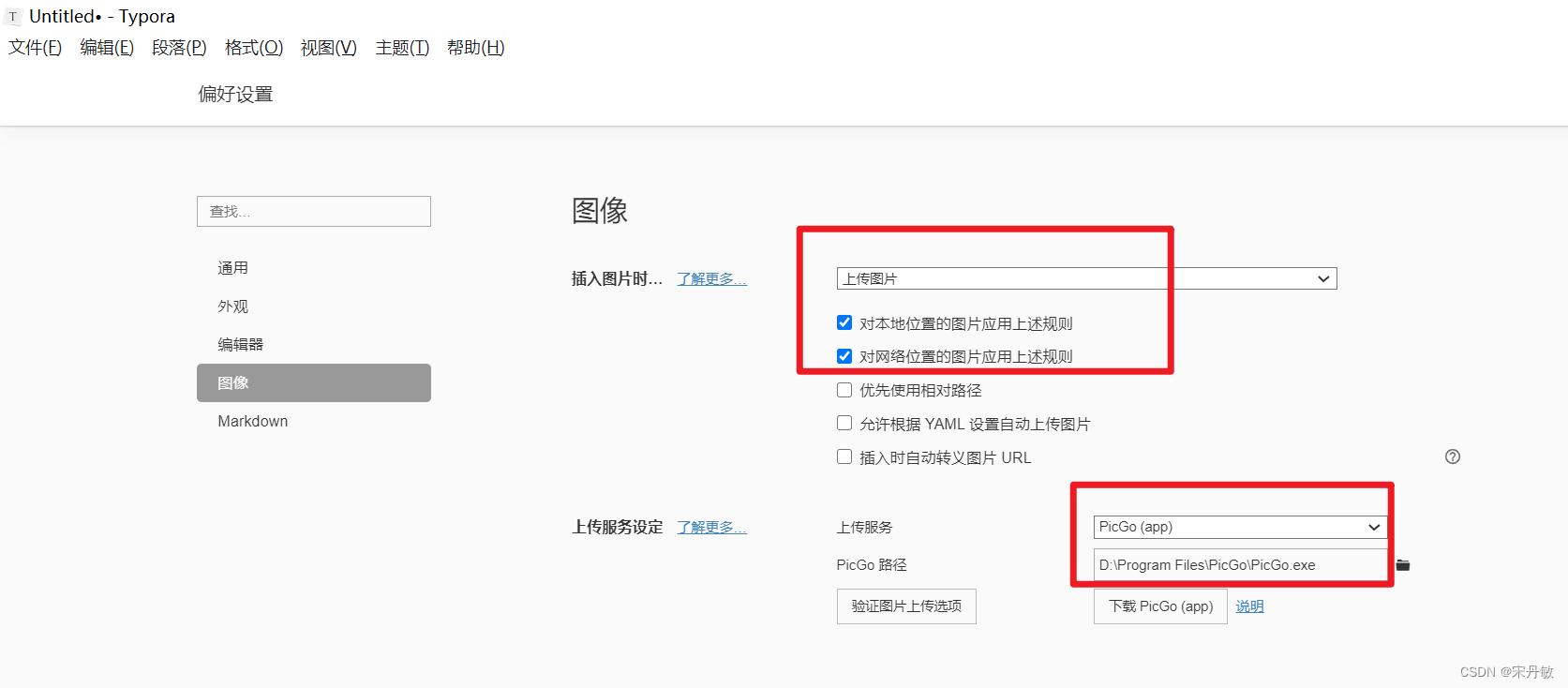
大型语言模型(llm)已经变得越来越复杂,能够根据各种提示和问题生成人类质量的文本。但是他们的推理能力让仍然是个问题,与人类不同LLM经常在推理中涉及的隐含步骤中挣扎,这回导致输出可能在事实上不正确或缺乏逻辑。
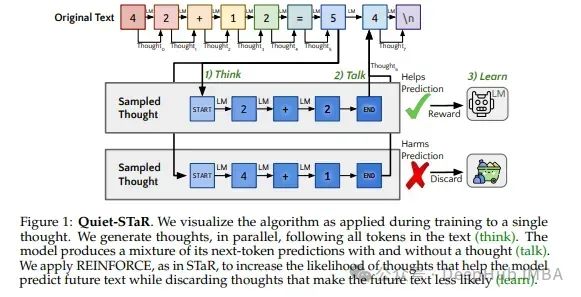
考虑以下场景:正在阅读一个复杂的数学证明。虽然最终的答案可能很清楚,但关键在于理解初始条件和结论之间未说明的步骤。在交谈中也一样,我们依靠中间的假设和背景知识来理解所说的话。这种内隐的推理的能力是Quiet-STaR为LLM提供的能力。
自学推理器(STaR)
先前的研究已经发明了STaR:一种LLM通过从问答示例中推断基本原理来学习推理的技术。但是STaR仅限于特定的任务,并且需要访问预先存在的答案-基本原理对。而Quiet-STaR建立在STaR的基础上,使LLM能够为他们生成的任何文本生成基本原理,使推理过程更加通用和适用。
挑战与解决方案
实现Quiet-STaR有几个挑战。为每个单词生成基本原理在计算上是非常昂贵的。并且LLM本身就缺乏产生或利用这些内在思想的能力。最后Quiet-STaR不仅需要预测下一个单词,还需要考虑文本中更长期的依赖关系。
Quiet-STaR背后的研究人员通过一系列创新技术来解决这些挑战:
令牌并行抽样:采用了一种独特的抽样算法,其中LLM在文本旁边生成基本原理,一次一个令牌(单词)。

可学习的思想令牌:在生成的文本中引入了特殊的符号令牌来表示基本原理的开始和结束。随着时间的推移,LLM学会有效地使用这些令牌。
加强教师指导:使用了一种改进的教师指导技术来指导LLM确保正确的输出文本和相应的基本原理。

Quiet-STaR的流程如下:

Quiet-STaR的好处
1、Quiet-STaR有助于LLM在句子中预测具有挑战性的单词。这些理由提供了额外的上下文,使LLM能够做出更加明智的预测。
2、使用Quiet-STaR训练的LLM在直接回答困难问题方面表现出显著改进。理由引发的推理过程使LLM更有效地处理复杂问题。
3、Quiet-STaR导致推理基准(GSM8K和CommonsenseQA)上的性能提升,而无需在这些特定任务上进行任何微调。这表明LLM将其推理能力推广到未见问题,提升了零样本性能
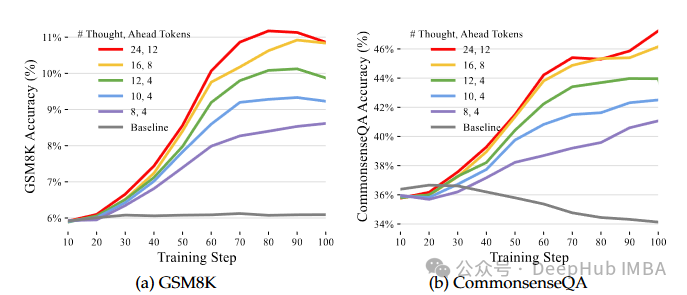
4、Quiet-STaR明显降低了困惑度,这是一个指示预测序列中下一个单词难度的度量。这表明理由使得LLM的整体文本生成过程更加顺畅和高效。
总结
Quiet-STaR代表了LLM发展的重大进步。通过使它们能够生成理由并经过与文本生成相关的步骤进行推理,Quiet-STaR为更可靠、准确并且能够处理复杂任务的LLM铺平了道路。
目前的研究侧重于文本理由。未来的工作可以探索将其他形式的理由纳入其中,例如视觉或符号表示。将理由生成与可解释AI技术结合可以使LLM不仅能够生成理由,还能够向用户解释其推理过程,增进信任和透明度。Quiet-STaR可以通过将领域特定的知识源纳入到理由生成过程中来进一步针对特定任务进行定制。
论文地址:Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking
https://avoid.overfit.cn/post/1ea458c86cf14b45ac219e7d7e82cdc4