在自然语言处理(NLP)的领域,大语言模型(LLMs)已经在各种下游语言任务中展现出了卓越的性能。这些任务包括但不限于问答、摘要、机器翻译等。LLMs的强大能力在于其生成的文本质量和多样性。为了控制生成过程,温度采样(temperature sampling)策略被广泛应用于调整下一个生成词的概率分布,从而影响模型的性能。
分享几个网站
GPT-3.5研究测试:
https://hujiaoai.cn
GPT-4研究测试:
https://higpt4.cn
Claude-3研究测试(全面吊打GPT-4):
https://hiclaude3.com
然而,现有的方法大多采用固定的温度参数,这在实际应用中可能并非最佳选择。固定温度在平衡生成质量和多样性方面存在局限性。如果模型每次生成高度相似甚至相同的内容,那么在需要多次生成的情况下,固定的温度设置就显得不够合理。
鉴于此,研究者们开始探索动态选择温度参数的方法,以期在生成质量和多样性之间实现更好的平衡。本文将介绍一种基于熵的动态温度采样(EDT)方法,该方法能够在每个解码步骤动态选择温度参数,以期在几乎不增加计算成本的情况下,显著提升模型在不同任务中的表现。
论文标题:EDT: Improving Large Language Models’ Generation by Entropy-based Dynamic Temperature Sampling
论文链接:https://arxiv.org/pdf/2403.14541.pdf
南京大学新软件技术国家重点实验室与字节跳动公司合作研究
在近期的研究中,南京大学新软件技术国家重点实验室与字节跳动公司合作,提出了一种基于熵的动态温度(Entropy-based Dynamic Temperature, EDT)采样方法,旨在改善大语言模型(Large Language Models, LLMs)在生成任务中的表现。该方法通过动态选择温度参数,实现了生成质量与多样性之间更好的平衡。
1. 研究背景与动机
在自然语言生成(Natural Language Generation, NLG)任务中,除了输出质量,输出的多样性、事实一致性等因素也受到关注。温度采样(temperature sampling)是控制解码过程中常用的方法之一,但大多数情况下使用的是固定的温度设置,这可能并不总是最佳选择。通过对四个不同任务的1000个实例进行单实例级别的最优生成质量温度选择分析,研究者发现固定温度在许多情况下并非最佳选项。
2. EDT方法介绍
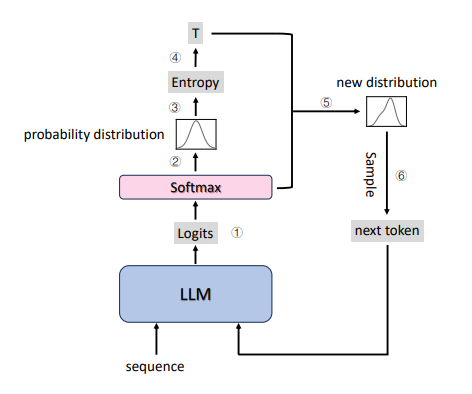
基于上述动机,研究者提出了EDT方法,这是一种新的温度选择策略,可以在每个解码步骤中动态选择温度。EDT方法使用单个模型,并根据每一步的预测分布计算温度,从而节省了大量GPU内存使用,并消除了双并行解码架构中的潜在瓶颈。研究者还介绍了如何通过模型在当前步骤的置信度来动态选择温度,其中熵被用作衡量模型置信度的指标。
3. 实验设计与结果
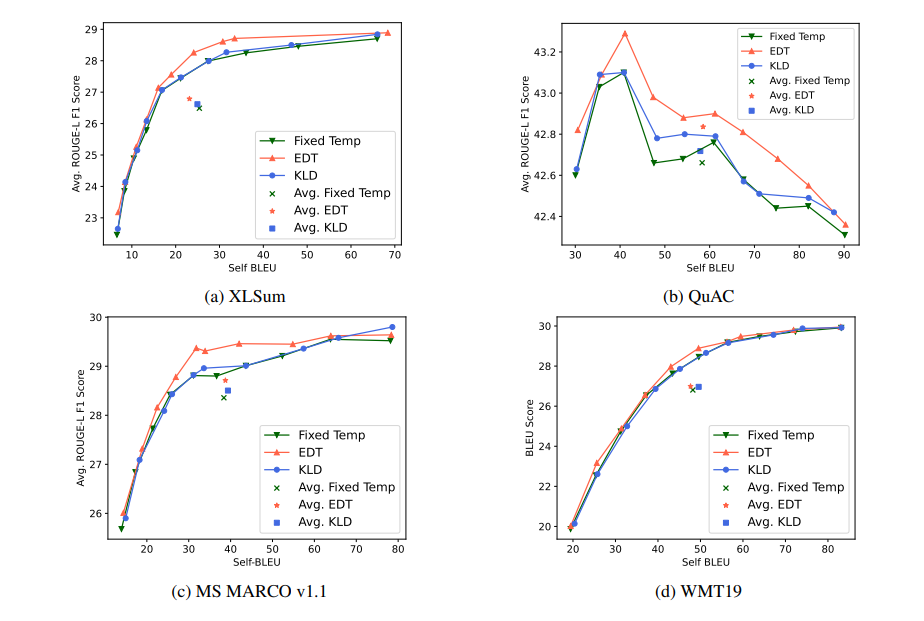
研究者在文本摘要、问答和机器翻译等代表性基准上评估了EDT策略。实验结果表明,EDT策略在所有任务中都取得了比固定温度策略和基于KL散度的动态温度策略(KLD)更好的性能。此外,EDT策略在生成质量和多样性之间取得了更好的平衡,并且几乎不增加推理成本。
温度采样策略的介绍与问题分析
1. 温度采样的基本概念
温度采样是大语言模型(LLMs)生成过程中常用的解码策略之一。这种策略通过调整下一个生成词汇的概率分布来影响模型的生成性能。具体来说,温度采样策略通过一个参数T,即温度,来调整概率分布,从而控制生成内容的质量和多样性。在解码过程中,较高的温度通常会导致更具创造性的生成,而较低的温度则倾向于生成质量更高但变化较少的内容。
2. 固定温度设置的局限性
尽管温度采样策略广泛用于平衡生成质量和多样性,但目前主流的做法是使用固定的温度设置。这种方法存在明显的局限性。例如,在对四个不同任务的1000个实例进行最优温度选择分析时,结果表明,在许多情况下,任何固定的温度都不是最佳选择。
这说明固定温度策略不能充分满足多样性和质量的需求,因此,有必要寻找一种更合理的动态温度选择策略。
动态温度采样(EDT)方法的提出
1. 动态温度采样的动机与初步研究
动态温度采样(EDT)的提出源于对固定温度采样局限性的认识。通过对不同任务中单个实例的最优温度选择进行分析,研究者发现在大量情况下,固定温度并非最佳选择。此外,LLMs在不同解码步骤中的置信度存在显著波动,这为通过模型置信度来控制解码过程提供了可能性。
2. 模型置信度与熵的关系
在EDT方法中,研究者选择熵作为每个解码步骤中模型置信度的度量。
-
熵越大,模型在选择当前词汇时置信度越低;熵越小,置信度越高。
当模型对当前位置的选择不够自信时,使用较高的温度可以帮助模型探索更多可能的答案,而不会显著影响输出质量。相反,当模型在当前步骤非常自信时,使用较低的温度可以使模型更坚定地执行其当前决策。
3. EDT算法的核心思想与实现
EDT算法的核心思想是在每个解码步骤动态选择温度。
在解码过程中,首先获取词汇的对数几率和预测概率分布,然后根据概率分布的熵来测量模型在当前步骤的置信度,并据此计算该步骤的温度。通过这种方式,可以在不增加显著计算成本的情况下,动态调整温度,从而在生成质量和多样性之间取得更好的平衡。
实验结果表明,EDT算法在不同任务中都显著优于现有策略,并且与固定温度策略相比,几乎没有额外的计算成本,同时节省了约一半的GPU内存。
实验设计与评估指标
1. 实验设置:数据集与任务类型
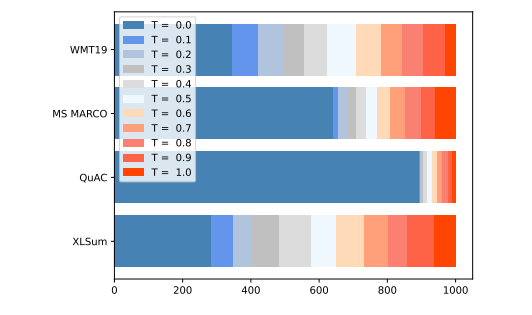
在本研究中,研究者们采用了四个不同的基准数据集来评估此基于熵的动态温度(EDT)采样方法。这些数据集包括文本摘要的XLSum、问答任务的MS MARCO v1.1和QuAC,以及机器翻译的WMT19。
-
在实验设置中,研究者们从XLSum英文数据集的训练子集中提取了10k实例作为训练集,并从测试子集中随机提取了1k实例进行测试。
-
问答任务的数据集设置类似,从每个训练集中提取10k实例进行训练,并从验证集中提取1k实例进行测试。
-
对于机器翻译任务,选择了WMT19英文到中文数据集的验证子集,同样采用了10k实例进行训练和1k实例进行测试。
2. 评估指标:质量与多样性的衡量
为了全面评估生成任务的性能,研究者们采用了多个评估指标。
-
对于文本摘要和问答任务,使用ROUGE-L的平均F1分数来评估生成质量,并遵循Aharoni等人(2022)和Nishida等人(2019)的方法。
-
对于机器翻译任务,使用平均SacreBLEU分数来评估生成质量。
-
此外还使用了平均Self-BLEU分数来衡量生成的多样性,参考了Zhu等人(2018b)的方法。
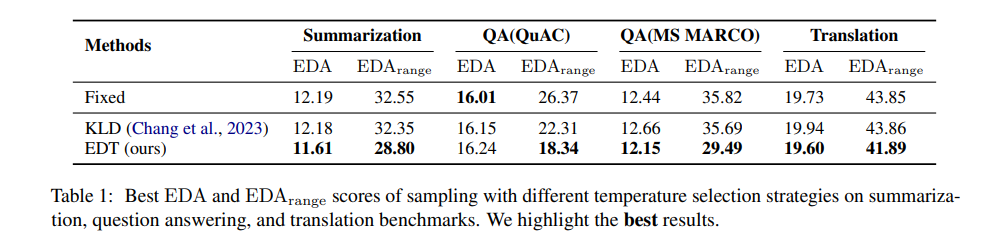
为了反映生成质量和多样性之间的综合性能,研究者们计算了EDA(Euclidean Distance from the ultimate Aim)分数,该分数考虑了BLEU或ROUGE评分的质量分数和Self-BLEU评分的多样性分数,以及这两个指标之间的权衡。
实验结果与分析
1. EDT与固定温度策略的对比
实验结果表明,与固定温度策略相比,EDT在不同的任务中均能实现更好的性能。
-
在文本摘要任务的XLSum数据集上,使用EDT的ROUGE分数从23提高到29,而在WMT19机器翻译任务中,BLEU分数从20提高到30。
这些结果表明,适当的温度调节对于提高LLMs的生成质量至关重要。
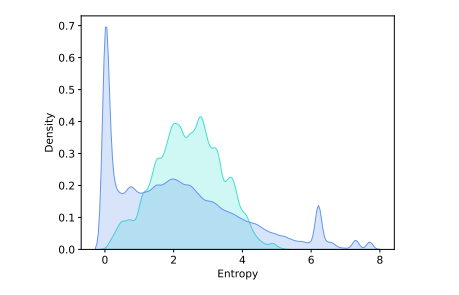
2. EDT与其他动态温度策略的对比
与其他动态温度策略(如KLD)相比,EDT展现出了更好的性能。平均而言,EDT在质量和多样性的平衡上优于KLD,且在实现这一平衡的同时,EDT的计算成本几乎可以忽略不计,这使得EDT成为一种更简单、更有效的策略。
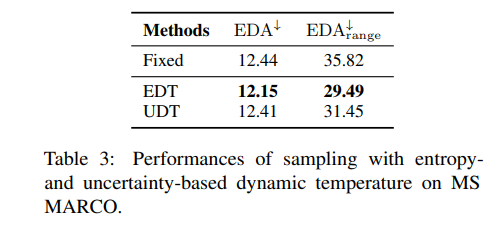
3. 参数T0和θ对EDT性能的影响
通过对MS MARCO问答任务的实验分析,研究者们发现T0和θ这两个超参数对EDT的性能有着显著的影响。
-
T0决定了温度范围,而θ则在温度对熵的敏感性方面发挥着重要作用。
实验结果表明,适当调整T0和θ可以帮助模型获得更好的性能。例如,当T0固定时,通过调整θ可以帮助模型获得更好的性能,但如果θ调整不当,可能会产生比原始算法更差的结果。
总体而言,设置合适的超参数T0和θ对于算法的有效性至关重要。
通过案例研究,研究者们还展示了EDT在XLSum数据集上的优势,其中EDT的输出明显更加简洁,同时准确传达了原文的意义,并且在相似的Self-BLEU分数下实现了显著更好的生成质量分数。
案例研究:EDT在文本摘要任务中的应用
1. 研究背景
在自然语言生成(NLG)任务中,如文本摘要、问答和机器翻译等,生成的文本质量和多样性是评价模型性能的重要指标。大语言模型(LLMs)在这些任务中取得了显著的成绩,但在解码过程中通常采用固定的温度参数进行温度采样,这可能不是平衡生成质量和多样性的最佳选择。为了解决这一问题,本研究提出了一种基于熵的动态温度(EDT)采样方法,通过动态选择温度参数来实现更平衡的性能。
2. EDT方法介绍
EDT方法在每个解码步骤中动态选择温度参数,以此来控制模型生成的过程。该方法使用熵作为模型在每个解码步骤中的置信度指标,熵值越大,模型在选择当前token时置信度越低;熵值越小,置信度越高。
当模型对当前步骤不够自信时,采用较高的温度有助于模型探索更多可能的答案,而不会显著影响输出质量。反之,当模型对当前步骤非常自信时,采用较低的温度使模型更坚定其当前决策,有助于解决基于采样的生成策略中的长尾问题。
3. 文本摘要任务中的应用
在文本摘要任务中,EDT方法被应用于XLSum数据集。实验中,从XLSum英文数据集的训练子集中抽取了10k个实例作为训练集,并从测试子集中随机抽取了1k个实例进行测试。
EDT方法与固定温度策略和基于KL散度的动态温度策略(KLD)进行了比较。实验结果表明,EDT在生成质量和多样性之间取得了更好的平衡,且相较于KLD策略,EDT方法在计算成本上几乎可以忽略不计,同时节省了约一半的GPU内存。
4. 结果分析
通过对XLSum数据集的案例研究,发现EDT生成的摘要更加简洁,同时准确传达了原文的意义。与其他两种算法相比,EDT在生成质量得分上显著更好,同时保持了类似的自我BLEU分数。EDT输出中的冗余信息更少,因此获得了更高的ROUGE-L F1分数。
结论与展望:动态温度采样的意义与未来研究方向
1. 研究意义
本研究提出的EDT方法在多个自然语言生成任务中验证了其有效性,特别是在文本摘要任务中展现了其优势。EDT方法简单到足以无缝应用于多种语言生成任务,并且在现有温度采样策略中表现出色。这一方法遵循LLMs研究的“一体适用”精神,希望能激发后续研究者探索这一有前景的研究方向。
2. 未来研究方向
尽管EDT方法在多个NLG任务中表现出了预期的效果,并在效率和效果上都比现有方法有显著提升,但仍有一些局限性等待研究。EDT算法虽然是任务无关的,但它仍受特定任务或数据的限制,这意味着同一组超参数设置不能普遍适用于所有语言任务或数据集。
此外,EDT方法依赖于某些手动配置,这意味着开发能够自动选择超参数的神经网络将更为高效。此外,可学习的网络甚至可以为每个实例选择超参数,实现更有效的控制。这表明,可学习的参数选择策略是一个重要的研究方向。



![[Python学习篇] Python创建项目](https://img-blog.csdnimg.cn/direct/02e2e4270dd94da18937f6b4d0746b16.png)