官方仓库:https://crates.io/crates/regex
文档地址:regex - Rust
github仓库地址:GitHub - rust-lang/regex: An implementation of regular expressions for Rust. This implementation uses finite automata and guarantees linear time matching on all inputs.
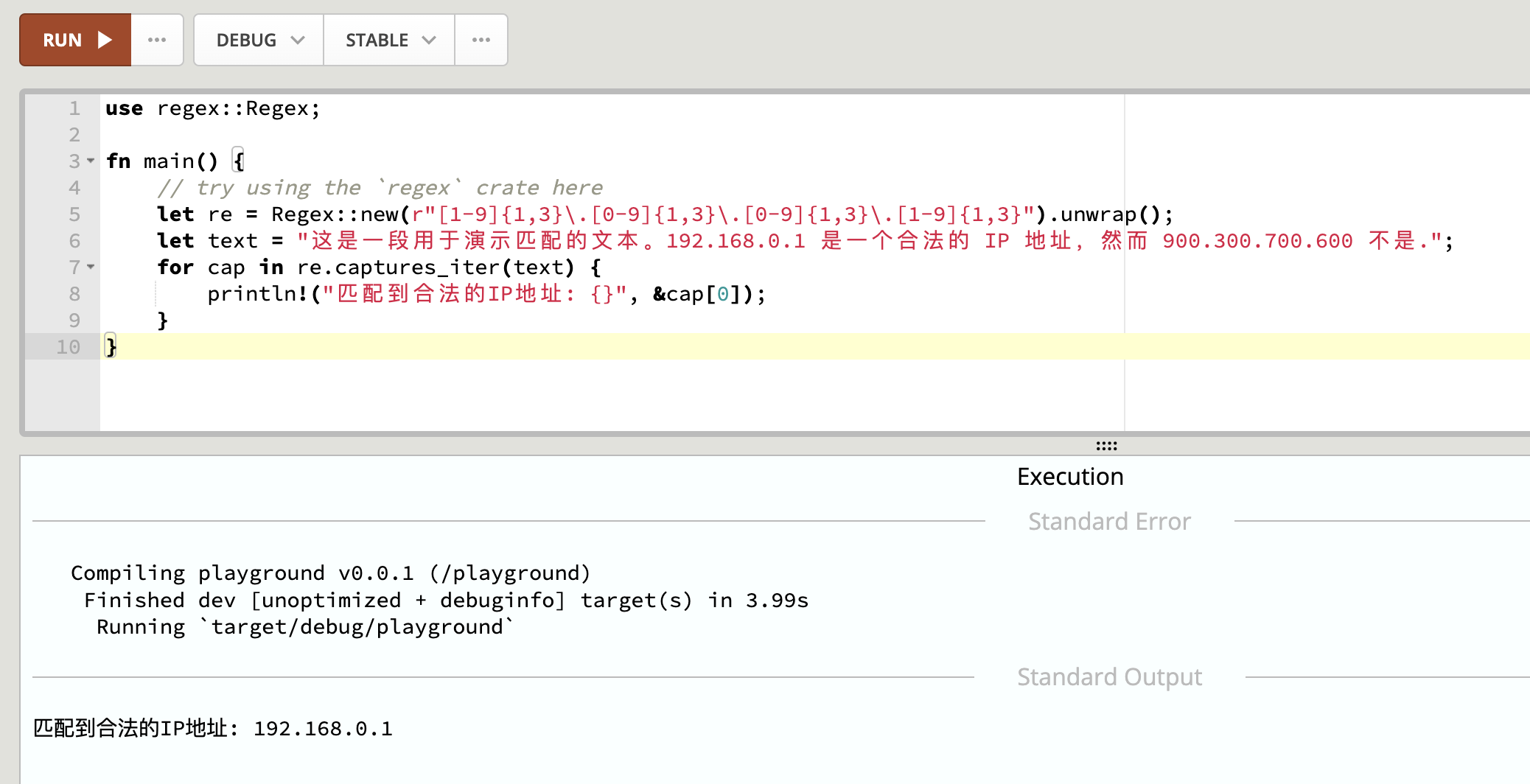
在线体验地址:Rust Playground
直接使用下面代码测试环境:
use regex::Regex;
fn main() {
// try using the `regex` crate here
let re = Regex::new(r"[1-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[1-9]{1,3}").unwrap();
let text = "这是一段用于演示匹配的文本。192.168.0.1 是一个合法的 IP 地址,然而 900.300.700.600 不是.";
for cap in re.captures_iter(text) {
println!("匹配到合法的IP地址: {}", &cap[0]);
}
}点击左上角的RUN:就可以看到匹配结果
安装regex
直接在rust项目目录中运行:
cargo add regex或者编辑 Cargo.toml 文件添加:
[dependencies]
regex = "1.10.4"然后运行:cargo run
使用正则表达式
创建正则表达式对象:
let re = Regex::new(r"(\d{4})-(\d{2})-(\d{2})").unwrap();1.是否匹配:is_match
判断字符串是否和正则表达式匹配,是的话返回true,不是的话返回false
use regex::Regex;
fn main() {
println!("Hello, world!");
//
let re = Regex::new(r"^\d{4}-\d{2}-\d{2}$").unwrap();
let date = "today is 2024-03-27";
if re.is_match(date) {
println!("完全匹配")
} else {
println!("不匹配")
}
}
2.获取分组匹配到的项: captures_iter | captures
captures:返回与文本中最左边的第一个匹配相对应的捕获组。捕获组 0 始终对应于整个匹配。如果找不到匹配,则不返回任何内容。
captures_iter:返回文本中匹配的所有非重叠捕获组的迭代器。这在操作上与 find_iter 相同,除了它产生关于捕获组匹配的信息。
captures_iter可以获取到匹配到的每一项,可以通过遍历拿到匹配的结果,如果正则里面有使用分组()来匹配内容,可以通过遍历匹配的结果,通过下表来获取分组内容。
use regex::Regex;
fn main() {
println!("Hello, world!");
let re = Regex::new(r"\d{4}-\d{2}-\d{2}").unwrap();
let date = "today is 2024-03-27, yesterday is 2023-11-23";
for cap in re.captures_iter(date) {
println!("匹配到的结果是:{}", &cap[0]);
}
}
// 输出结果
匹配到的结果是:2024-03-27
匹配到的结果是:2023-11-23不实用分组的匹配结果:captures (只能获取到匹配的第一个内容)
use regex::Regex;
fn main() {
println!("Hello, world!");
let re = Regex::new(r"\d{4}-\d{2}-\d{2}").unwrap();
let date = "today is 2024-03-27, yesterday is 2023-11-23";
let res = re.captures(date).unwrap();
println!("res is {}", &res[0]);
}
// 输出结果
res is 2024-03-27
使用分组正则表达式获取分组后的匹配结果:
use regex::Regex;
fn main() {
println!("Hello, world!");
let re = Regex::new(r"(\d{4})-(\d{2})-(\d{2})").unwrap();
let date = "today is 2024-03-27, yesterday is 2023-11-23";
for cap in re.captures_iter(date) {
println!("匹配到的结果是:{} {} {}", &cap[0], &cap[1], &cap[2]);
}
}
// 输出结果
匹配到的结果是:2024-03-27 2024 03
匹配到的结果是:2023-11-23 2023 11
3.替换匹配的内容:replace 和 replace_all
replace是替换一次,replace_all是替换所有匹配到的内容。
replace替换一次:
use regex::Regex;
fn main() {
println!("Hello, world!");
let re = Regex::new(r"\d{4}-\d{2}-\d{2}").unwrap();
let date = "today is 2024-03-27, yesterday is 2023-11-23";
let res = re.replace(date, "2020-02-11");
println!("replace result is:{}", res);
}
// 输出结果
replace result is:today is 2020-02-11, yesterday is 2023-11-23
replace_all替换所有:
use regex::Regex;
fn main() {
println!("Hello, world!");
let re = Regex::new(r"\d{4}-\d{2}-\d{2}").unwrap();
let date = "today is 2024-03-27, yesterday is 2023-11-23";
let res = re.replace_all(date, "2020-02-11");
println!("replace result is:{}", res);
}
// 输出结果
replace result is:today is 2020-02-11, yesterday is 2020-02-114.查找正则匹配的内容:find 和 find_iter
find:返回文本中最左边第一个匹配的开始和结束字节范围。如果不存在匹配,则返回 None。请注意,这应该只在您想要发现匹配的位置时使用。如果使用 is_match,测试匹配的存在会更快。
use regex::Regex;
fn main() {
println!("Hello, world!");
let re = Regex::new(r"\d{4}-\d{2}-\d{2}").unwrap();
let date = "today is 2024-03-27, yesterday is 2023-11-23";
let res = re.find(date).unwrap();
println!("find result is:{}", res.as_str());
}
// 输出
find result is:2024-03-27find_iter:为text中每个连续的非重叠匹配返回一个迭代器,返回相对于 text 的起始和结束字节索引。
use regex::Regex;
fn main() {
println!("Hello, world!");
let re = Regex::new(r"\d{4}-\d{2}-\d{2}").unwrap();
let date = "today is 2024-03-27, yesterday is 2023-11-23";
for fin in re.find_iter(date){
println!("find result is:{}", fin.as_str());
}
}
// 输出结果
find result is:2024-03-27
find result is:2023-11-23
5.分割匹配的内容:split 和 splitn
split:返回由匹配的正则表达式分隔的文本子字符串的迭代器。也就是说,迭代器的每个元素对应于正则表达式不匹配的文本。此方法不会复制给定的文本。
use regex::Regex;
fn main() {
println!("Hello, world!");
let re = Regex::new(r"[ \t]+").unwrap();
let fields: Vec<&str> = re.split("a b \t c\td e").collect();
println!("split result is:{:?}", fields)
}
// 输出结果
split result is:["a", "b", "c", "d", "e"]
splitn:返回最多有限个文本子字符串的迭代器,这些子字符串由正则表达式的匹配项分隔。(限制为0将不会返回任何子字符串。)也就是说,迭代器的每个元素对应于正则表达式不匹配的文本。字符串中未被拆分的剩余部分将是迭代器中的最后一个元素。
use regex::Regex;
fn main() {
println!("Hello, world!");
let re = Regex::new(r"\W+").unwrap();
let fields: Vec<&str> = re.splitn("Hey! How are you?", 3).collect();
println!("splitn result is:{:?}", fields)
}
// 输出结果
splitn result is:["Hey", "How", "are you?"]
高级或“低级”搜索方法
shortest_match:返回给定文本中匹配的结束位置。
该方法可以具有与 is_match 相同的性能特征,除了它提供了匹配的结束位置。特别是,返回的位置可能比通过 Regex::find 找到的最左边第一个匹配的正确结尾要短。
注意,不能保证这个例程找到最短或“最早”的可能匹配。相反,这个 API 的主要思想是,它返回内部正则表达式引擎确定发生匹配的点的偏移量。这可能因使用的内部正则表达式引擎而异,因此偏移量本身可能会改变。
通常,a+ 会匹配某个文本中 a 的整个第一个序列,但是shortest_match 一看到第一个 a 就会放弃:
use regex::Regex;
fn main() {
println!("Hello, world!");
let text = "aaaaa";
let pos = Regex::new(r"a+").unwrap().shortest_match(text).unwrap();
println!("shortest match is:{}", pos)
}
// 输出结果
shortest match is:1
shortest_match_at:返回与 shortest_match 相同的值,但从给定的偏移量开始搜索。
起点的意义在于它考虑了周围的环境。例如,\A 定位点只能在 start == 0 时匹配。
use regex::Regex;
fn main() {
println!("Hello, world!");
let re = Regex::new(r"\d+").unwrap();
// 在字符串中查找最短匹配
let text = "123456789";
let shortest_match = re.shortest_match_at(text, 0).unwrap();
println!("Shortest match found at index {}", shortest_match);
}
// 输出结果
Shortest match found at index 1
is_match_at:返回与 is_match 相同的值,但从给定的偏移量开始搜索。
起点的意义在于它考虑了周围的环境。例如,\A 锚点只能在 start == 0 时匹配。
use regex::Regex;
fn main() {
println!("Hello, world!");
let re = Regex::new(r"\d{3}-\d{2}-\d{4}").unwrap();
let s = "123-45-6789";
// 使用is_match_at方法判断字符串是否匹配正则表达式
if re.is_match_at(s, 0) {
println!("Matched!");
} else {
println!("Not matched!");
}
}
// 输出结果
Matched!
find_at:返回与 find 相同的值,但从给定的偏移量开始搜索。
起点的意义在于它考虑了周围的环境。例如,\A 锚点只能在 start == 0 时匹配。
use regex::Regex;
fn main() {
println!("Hello, world!");
let s = "hello world";
let re = Regex::new(r"world").unwrap();
// 使用find_at方法查找字符串中第一个匹配正则表达式的位置
let pos = re.find_at(s, 0).unwrap().start();
// 输出匹配位置
println!("Match found at position: {}", pos);
}
// 输出结果
Match found at position: 6
辅助方法
as_str 方法:返回该正则表达式的原始字符串。
use regex::Regex;
fn main() {
println!("Hello, world!");
let re = Regex::new(r"\d+").unwrap();
let text = "2021-08-01";
let result = re.find(text).unwrap();
println!("{}", result.as_str());
}
// 输出结果
2021
captures_len 方法:返回捕获的数量。
正则匹配规则
下面说明了一些常用的正则匹配规则:
| 符号 | 描述 | 说明 |
| ^ | 匹配一个字符串的起始字符 | 如果多行标志被设置为 true,那么也匹配换行符后紧跟的位置。 |
| $ | 匹配一个字符串的结尾字符 | 如果多行标志被设置为 true,那么也匹配换行符前的位置。 |
| \b | 匹配一个单词的边界 | - |
| \B | 匹配非单词边界 | 相当于\b匹配的反集 |
限定符:
| 符号 | 描述 | 说明 |
| ? | 匹配该限定符前的字符0或1次 | 等价于 {0,1},如 colou?r 可以匹配colour和color |
| + | 匹配该限定符前的字符1或多次 | 等价于 {1,},如 hel+o可以匹配helo、hello、helllo、… |
| * | 匹配该限定符前的字符0或多次 | 等价于 {0,},如 hel*o可以匹配heo、helo、hello、helllo、… |
| {n} | 匹配该限定符前的字符n次 | 如 hel{2}o只可以匹配hello |
| {n,} | 匹配该限定符前的字符最少n次 | 如 hel{2,}o可以匹配hello、helllo、… |
| {n,m} | 匹配该限定符前的字符最少n次,最多m次 | 如 hel{2,3}o只可以匹配hello 和 helllo |
单个字符:
| 符号 | 描述 | 说明 |
| \d | 匹配任意数字 | |
| \s | 匹配任意空白符 | |
| \w | 匹配任意字母、数字、下划线、汉字等 | |
| \D | 匹配任意非数字 | |
| \S | 匹配任意非空白符 | |
| \W | 匹配除了字母、数字、下划线、汉字以外的字符 | |
| . | 匹配除了换行符以外的任意字符 |
| 形式 | 描述 | 说明 |
| [A-Z] | 区间匹配,匹配字母表该区间所有大写字母 | 如[C-F]匹配字符C、D、E、F |
| [a-z] | 区间匹配,匹配字母表该区间所有小写字母 | 如[c-f]匹配字符c、d、e、f |
| [0-9] | 区间匹配,匹配该区间内的所有数字 | 如[3-6]匹配字符3、4、5、6 |
| [ABCD] | 列表匹配,匹配[]中列出的所有字母 | 如这里列出的A、B、C、D都会被匹配 |
| [^ABCD] | 列表排除,匹配除了[]中列出的字符外的所有字符 | 如这里列出的A、B、C、D都会被排除而匹配其它字符 |