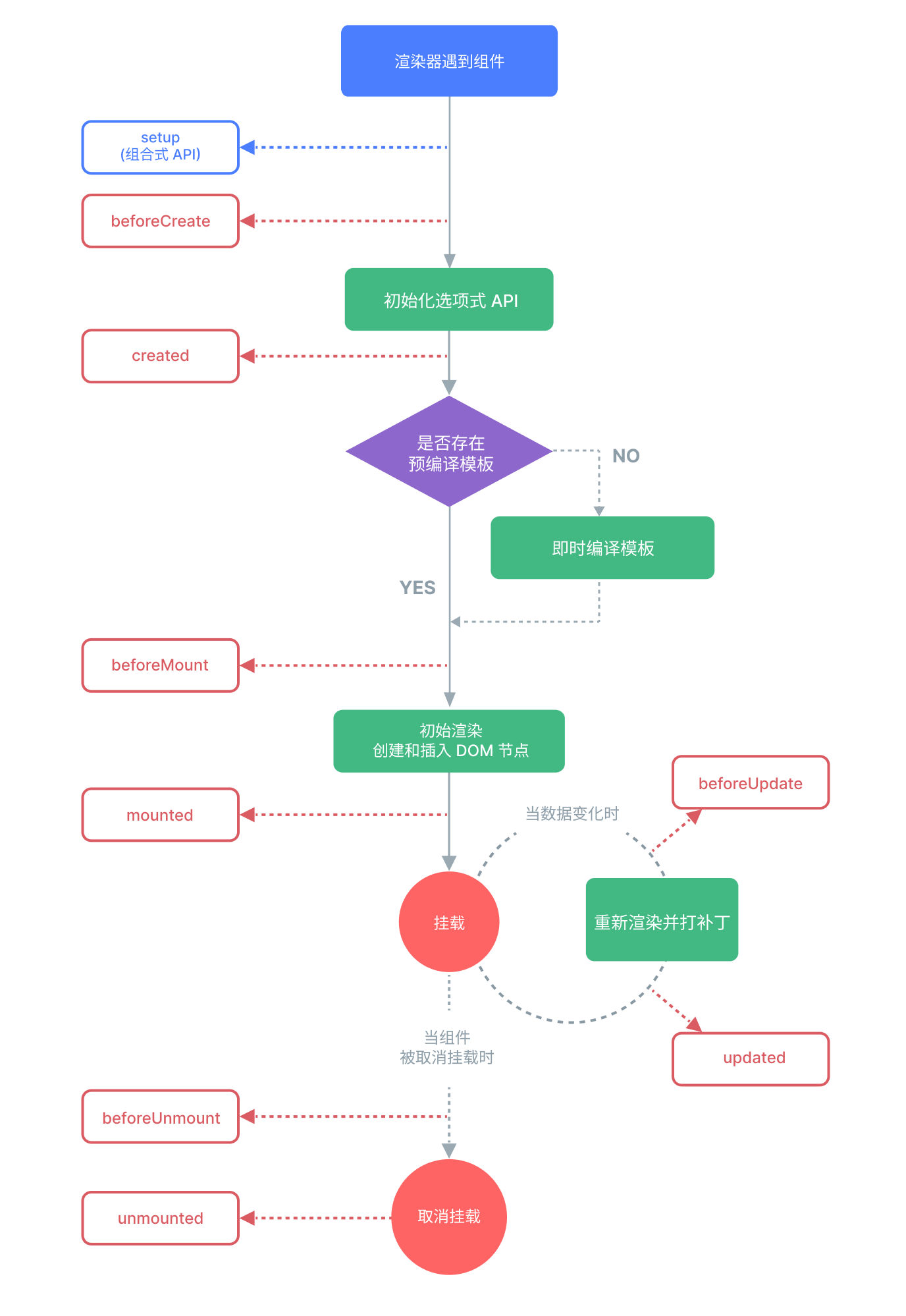
支持各种不同系列nvdia显卡和amd显卡,DeepFaceLab安装与使用,附完整的软件打包下载一键安装。

主要使用的技术:
1. 深度学习(Deep Learning)
深度学习是人工智能领域的一个重要分支,它通过模拟人脑的神经网络结构来实现对数据的学习和模式识别。在面部交换中,深度学习模型能够学习人//脸的特征,并在视频中识别和替//换面部。
2. 卷积神经网络(Convolutional Neural Networks, CNNs)
卷积神经网络是一种专门用于处理图像数据的深度学习模型。它通过卷积层来提取图像中的局部特征,非常适合用于面部识别和图像分割任务。
3. 生成对抗网络(Generative Adversarial Networks, GANs)
生成对抗网络由两部分组成:生成器(Generator)和判别器(Discriminator)。在面部交换中,生成器负责生成逼真的面部图像,而判别器则尝试区分生成的图像和真实图像。通过这种对抗过程,生成器能够产生越来越逼真的面部图像。
4. 自编码器(Autoencoders)
自编码器是一种神经网络,它通过编码和解码过程来学习数据的有效表示。在面部交换中,自编码器可以用来压缩和重建面部图像,有助于提高处理速度和减少数据损失。
5. 面部识别和检测(Face Detection and Recognition)
面部识别技术用于检测图像或视频中的人//脸,并识别出具体的个体。面部检测则是识别出图像中人//脸的位置和大小。这些技术是面部交换中不可或缺的一部分,因为它们确保了面部图像能够准确地对齐和替//换。
6. 图像分割(Image Segmentation)
图像分割技术用于将图像分割成多个部分或对象,这在面部交换中用于精确地识别和提取面部区域,以便将其与背景分离并替//换到目标视频中。
7. 预训练模型(Pre-trained Models)
预训练模型是在大量数据上训练好的神经网络模型,可以直接用于新的任务或进行微调。在面部交换项目中,使用预训练模型可以节省大量的时间和计算资源,因为它们已经学习了丰富的面部特征。
8. 视频处理库(Video Processing Libraries)
为了在视频中实时或离线进行面部交换,需要使用视频处理库来处理视频流。这些库提供了视频解码、帧提取、图像处理和视频编码等功能。
9. 并行计算和硬件加速(Parallel Computing and Hardware Acceleration)
为了提高面部交换的效率,项目可能会利用GPU或其他专用硬件进行并行计算。深度学习框架如TensorFlow和PyTorch都支持GPU加速,可以显著提高模型的训练和推理速度。
结论
s0md3v/roop项目结合了多种先进的计算机视觉和机器学习技术,以实现高效的面部交换。这些技术的应用不仅推动了人工智能领域的发展,也为创意产业、娱乐和教育等领域带来了新的可能性。然而,由于该项目已停止维护,用户在使用时应注意潜在的技术限制和安全风险,并考虑寻找其他更新和受支持的解决方案。
- Setup your platform
1.1 Setup Linux
Python
sudo apt install python3.10
PIP
sudo apt install python3-pip
GIT
sudo apt install git-all
FFmpeg
sudo apt install ffmpeg
1.2 Setup MacOS
Python
brew install python@3.10
PIP
python -m ensurepip
GIT
brew install git
FFmpeg
brew install ffmpeg
1.3 Setup Windows
Python
winget install -e --id Python.Python.3.10
PIP
python -m ensurepip
GIT
winget install -e --id Git.Git
FFmpeg
winget install -e --id Gyan.FFmpeg
Reboot your system in order for FFmpeg to function properly.
shutdown /r
Toolset
Microsoft Visual C++ 2015 Redistributable
winget install -e --id Microsoft.VCRedist.2015+.x64
Microsoft Visual Studio 2022 build tools
During installation, ensure to select the Desktop Development with C++ package.
winget install -e --id Microsoft.VisualStudio.2022.BuildTools --override "--wait --add Microsoft.VisualStudio.Workload.NativeDesktop --includeRecommended"
- Clone Repository
git clone https://github.com/s0md3v/roop
- Install dependencies
We highly recommend to work with a venv or conda to avoid issues.
pip install -r requirements.txt
- Done
You should be able to run roop using python run.py command. Keep in mind that while running the program for first time, it will download some models which can take time depending on your network connection.
python run.py
- Acceleration
CUDA (Nvidia)
Install CUDA Toolkit 11.8 and cuDNN for Cuda 11.x
https://developer.nvidia.com/cuda-11-8-0-download-archive
https://developer.nvidia.com/rdp/cudnn-archive
Install dependencies:
pip uninstall onnxruntime onnxruntime-gpu
pip install onnxruntime-gpu==1.15.1
Usage in case the provider is available:
python run.py --execution-provider cuda
CoreML (Apple)
Apple Silicon
Install dependencies:
pip uninstall onnxruntime onnxruntime-silicon
pip install onnxruntime-silicon==1.13.1
Usage in case the provider is available:
python run.py --execution-provider coreml
Apple Legacy
1.Install dependencies:
pip uninstall onnxruntime onnxruntime-coreml
pip install onnxruntime-coreml==1.13.1
Usage in case the provider is available:
python run.py --execution-provider coreml
DirectML (Windows)
Install dependencies:
pip uninstall onnxruntime onnxruntime-directml
pip install onnxruntime-directml==1.15.1
Usage in case the provider is available:
python run.py --execution-provider dml
OpenVINO (Intel)
Install dependencies:
pip uninstall onnxruntime onnxruntime-openvino
pip install onnxruntime-openvino==1.15.0
Usage in case the provider is available:
python run.py --execution-provider openvino
Usage
Start the program with arguments:
python run.py [options]
-h, --help show this help message and exit
-s SOURCE_PATH, --source SOURCE_PATH select an source image
-t TARGET_PATH, --target TARGET_PATH select an target image or video
-o OUTPUT_PATH, --output OUTPUT_PATH select output file or directory
--frame-processor FRAME_PROCESSOR [FRAME_PROCESSOR ...] frame processors (choices: face_swapper, face_enhancer, ...)
--keep-fps keep target fps
--keep-frames keep temporary frames
--skip-audio skip target audio
--many-faces process every face
--reference-face-position REFERENCE_FACE_POSITION position of the reference face
--reference-frame-number REFERENCE_FRAME_NUMBER number of the reference frame
--similar-face-distance SIMILAR_FACE_DISTANCE face distance used for recognition
--temp-frame-format {jpg,png} image format used for frame extraction
--temp-frame-quality [0-100] image quality used for frame extraction
--output-video-encoder {libx264,libx265,libvpx-vp9,h264_nvenc,hevc_nvenc} encoder used for the output video
--output-video-quality [0-100] quality used for the output video
--max-memory MAX_MEMORY maximum amount of RAM in GB
--execution-provider {cpu} [{cpu} ...] available execution provider (choices: cpu, ...)
--execution-threads EXECUTION_THREADS number of execution threads
-v, --version show program's version number and exit
Headless
Using the -s/–source, -t/–target and -o/–output argument will run the program in headless mode.
DeepFaceLive是由iperov开发的开源项目,旨在实现实时的面部交换功能,主要用于PC流媒体或视频通话。这个项目基于深度学习和神经网络技术,允许用户将自己的面部实时替//换到其他视频源上,例如,可以在直播流、视频会议或社交媒体直播中使用这一技术。
功能
DeepFaceLive的主要功能包括:
-
实时面部捕捉:DeepFaceLive能够实时捕捉用户的面部动作,包括面部表情、嘴巴动作和头部移动等。
-
面部替//换:用户可以选择一个预设的面部模型或自定义的面部数据集,DeepFaceLive会将捕捉到的面部动作应用到选定的面部模型上。
-
视频源融合:DeepFaceLive可以将替//换后的面部与原始视频的背景和其他元素无缝融合,创造出自然逼真的视频效果。
-
多平台支持:DeepFaceLive支持多种流媒体和视频通话平台,如OBS Studio、Zoom、Skype等。
-
预训练模型:项目提供了一些预训练的面部模型,用户可以直接使用这些模型进行面部替//换。
作用
DeepFaceLive的作用主要体现在以下几个方面:
-
娱乐和创意:内容创作者和直播主可以使用DeepFaceLive为观众提供新颖的娱乐体验,例如角色扮演、虚拟形象直播等。
-
匿名性和隐私保护:在需要保护个人隐私的场合,用户可以使用DeepFaceLive隐藏自己的真实面貌,以匿名身份进行视频通话或直播。
-
教育和培训:教育工作者可以利用DeepFaceLive进行远程教育,通过有趣的方式吸引学生的注意力,提高教学效果。
-
商业演示:企业可以使用DeepFaceLive进行产品演示或广告宣传,通过创造吸引人的视觉效果来吸引潜在客户。
使用方法
使用DeepFaceLive的基本步骤如下:
-
安装和配置:首先,用户需要从GitHub下载DeepFaceLive的最新版本,并根据提供的安装说明进行安装。安装过程中可能需要配置一些环境变量和依赖库。
-
准备面部模型:用户需要准备一个或多个面部模型,可以是项目提供的预训练模型,也可以是用户自己创建的。创建面部模型通常需要一系列高质量的面部图像或视频。
-
设置视频源:用户需要在DeepFaceLive中设置视频源,这可以是网络摄像头、预录制的视频文件或其他视频流。
-
实时面部捕捉:在视频源设置完成后,DeepFaceLive会开始实时捕捉用户的面部动作。用户需要确保面部光照均匀,背景简洁,以便软件更好地捕捉面部特征。
-
面部替//换和融合:DeepFaceLive会将捕捉到的面部动作应用到预设的面部模型上,并将替//换后的面部与原始视频融合。
-
输出到视频平台:用户可以将处理后的视频输出到支持的流媒体平台或视频通话软件中。DeepFaceLive提供了一些常用的输出选项,如OBS Studio、Zoom等。
-
调整和优化:用户可以根据需要调整面部替//换的参数,如面部大小、位置、透明度等,以达到最佳的视觉效果。
注意事项
在使用DeepFaceLive时,用户需要注意以下几点:
-
合法合规:用户应确保使用DeepFaceLive遵守当地法律法规,不得用于制作或传播违法内容。
-
尊重他人权利:在使用他人的肖像或面部数据时,应获得本人的明确同意,并尊重其隐私权和肖像权。
-
技术限制:虽然DeepFaceLive能够实现实时面部替//换,但技术仍有局限性,可能无法完全模拟复杂的面部表情和动作。
-
硬件要求:DeepFaceLive对计算资源有一定要求,用户应确保自己的设备具备足够的处理能力,以保证软件的流畅运行。
-
持续学习和更新:深度学习和神经网络技术在不断进步,用户应关注DeepFaceLive的更新,学习新的技术和方法,以提高使用效果。
DeepFaceLive作为一个开源项目,鼓励用户参与贡献和改进。用户可以通过GitHub页面报告问题、提交改进建议或分享自己的使用经验。同时,用户也应该注意,随着技术的发展,DeepFaceLive可能会引入新的功能和改进,因此应定期查看项目的更新和文档。
DeepFaceLab是一个开源项目,由iperov在GitHub上发起。该项目是创建深度伪造(deepfakes)视频的领先软件,深度伪造是一种通过人工智能技术将人//脸替//换到其他视频上的技术。DeepFaceLab特别针对利用深度学习算法进行面部替//换的操作进行了优化,使得用户能够相对容易地创建看起来非常逼真的伪造视频。
功能
DeepFaceLab提供了一系列功能,使得用户能够进行高级的面部替//换编辑。以下是DeepFaceLab的一些主要功能:
-
面部替//换:用户可以将一个视频中的面部替//换为另一个视频或图片中的面部。这种功能可以用于娱乐、教育或其他目的。
-
面部年轻化:DeepFaceLab提供了一种功能,可以将视频中人物的面部年轻化,这在电影制作和特效中尤其有用。
-
头部替//换:除了面部替//换,用户还可以将整个头部替//换为另一个视频或图片中的头部。
-
政治家嘴唇操控:DeepFaceLab可以用来操控视频中政治家的嘴唇动作,使其说出没有说过的话。这需要一定的视频编辑技能,并结合使用Adobe After Effects或DaVinci Resolve等视频编辑软件。
-
深度伪造进度优化:DeepFaceLab支持对深度伪造视频的质量进行优化,以提高最终视频的逼真度。
作用
DeepFaceLab的作用不仅限于娱乐和创意产业。它还可以用于以下几个方面:
-
电影和视频制作:电影制作人和视频编辑者可以使用DeepFaceLab来创建高质量的特效,如更换演员、改变角色外观等。
-
教育和研究:教育工作者和研究人员可以利用DeepFaceLab来创建教学视频或进行面部识别技术的研究。
-
社交媒体内容创作:社交媒体创作者可以使用DeepFaceLab制作独特的内容,吸引观众和粉丝。
-
技术演示和展示:技术公司和研究机构可以利用DeepFaceLab展示人工智能和深度学习的能力。
使用方法
使用DeepFaceLab的基本步骤如下:
-
安装软件:首先,用户需要从GitHub页面下载DeepFaceLab的最新版本,并根据提供的安装说明进行安装。
-
准备素材:用户需要准备源视频(包含要替//换的面部)和目标视频(包含要替//换到的面部)。此外,还需要准备相应的面部数据集,用于训练深度学习模型。
-
创建面部数据集:用户需要使用DeepFaceLab提供的指导手册创建面部数据集(称为faceset)。这个过程包括选择高质量的图像和视频片段,并使用DeepFaceLab的内置工具进行处理。
-
训练模型:使用准备好的面部数据集,用户需要训练一个深度学习模型。这个过程可能需要一些时间,具体取决于数据集的大小和计算机的性能。
-
进行面部替//换:模型训练完成后,用户可以开始使用DeepFaceLab进行面部替//换。用户需要导入源视频和目标视频,然后使用训练好的模型进行面部替//换。
-
视频编辑和优化:面部替//换完成后,用户可能需要使用其他视频编辑软件(如Adobe After Effects)进行进一步的编辑和优化,以提高最终视频的质量。
-
导出和分享:最后,用户可以将完成的深度伪造视频导出,并在社交媒体、视频分享平台或其他渠道上分享。
注意事项
DeepFaceLab是一个强大的工具,但它也带来了潜在的道德和法律问题。用户在使用DeepFaceLab时应该遵守以下准则:
-
合法使用:确保你的使用符合当地法律法规,不要制作或传播误导性或诽谤性的内容。
-
尊重隐私:在使用他人的图像或视频时,应该获得明确的许可,并尊重他们的隐私权。
-
负责任的分享:在分享深度伪造视频时,应该清楚地标明视频是经过编辑的,以避免误导观众。
-
安全存储:由于DeepFaceLab处理的数据可能包含敏感信息,用户应该确保他们的数据存储和传输是安全的。
DeepFaceLab是一个不断发展的项目,其功能和使用方法可能会随着新版本的发布而更新。因此,用户应该定期查看GitHub页面上的更新和文档,以获取最新的信息和指导。

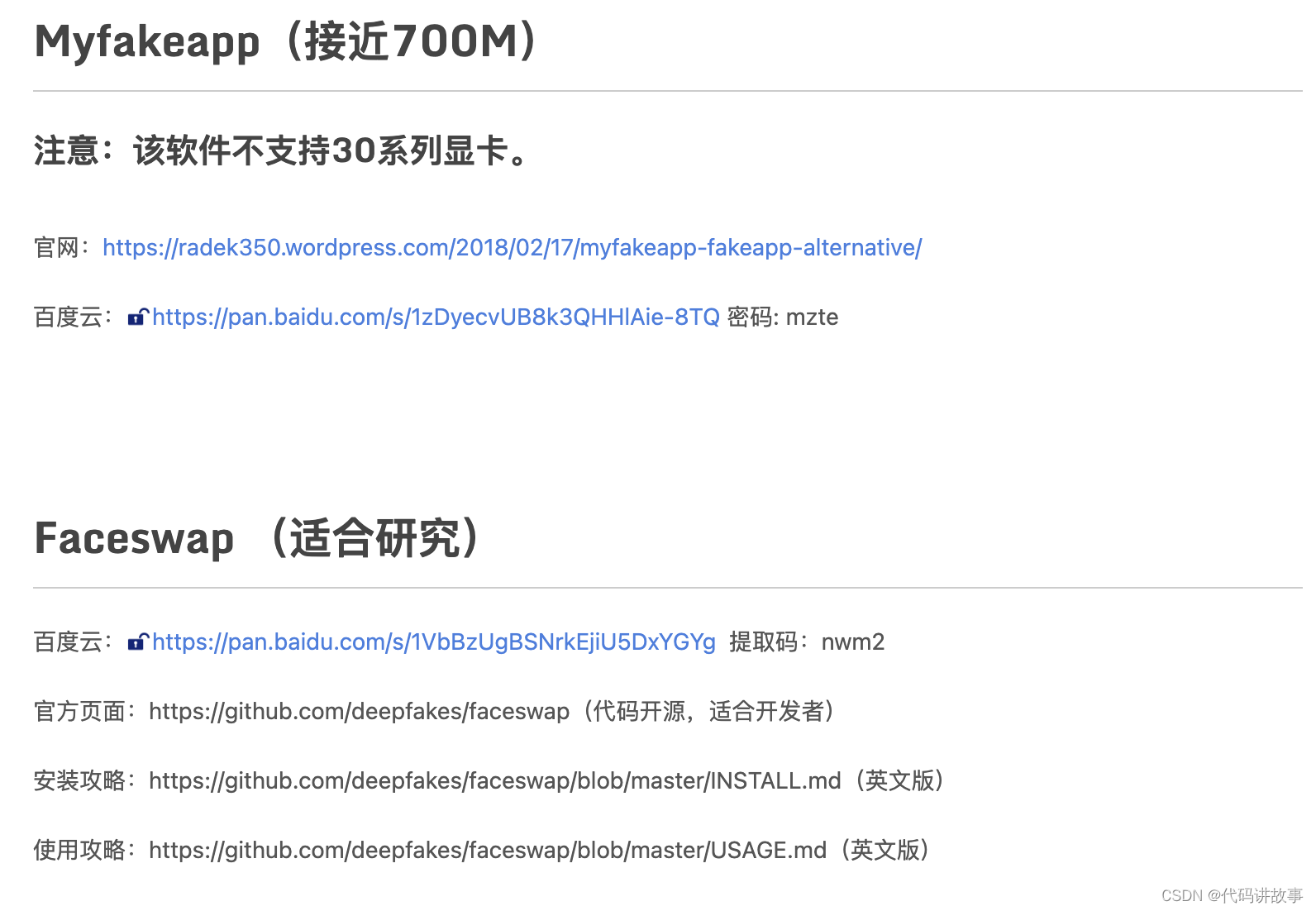

安装方法:
双击最新版的7z文件。
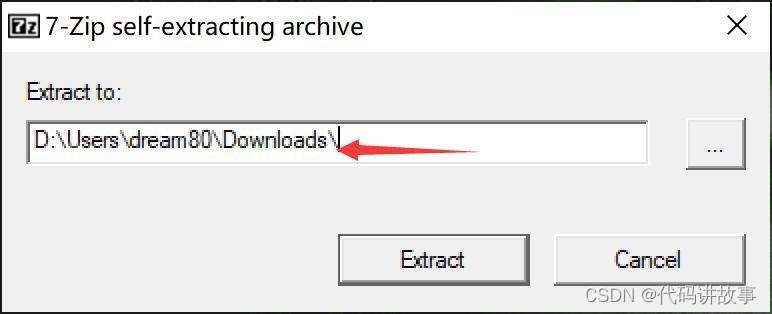
选择安装路径,建议放在C盘以外的磁盘,路径尽量短点不要包含特色字符。
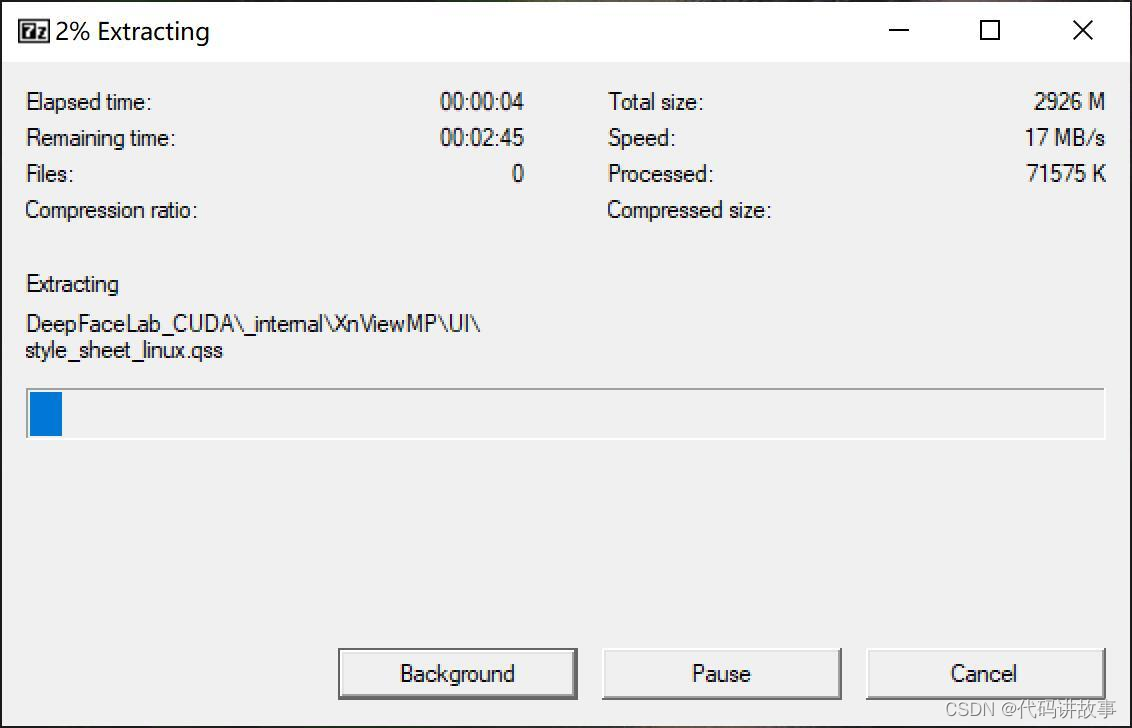
单击Extract开始解压软件。
软件安装本质上只是解压而已,无需安装,就像很多绿色软件一样。如果QQ管家或者360报毒(都是流氓软件),添加信任放行即可。
依赖安装:依赖的意思就是使用这个软件之前必须要先安装的软件,DFL的唯一依赖就是显卡驱动。所以你只需要更新驱动即可使用此软件,CUDA和CUDNN不是必须的。
目录介绍
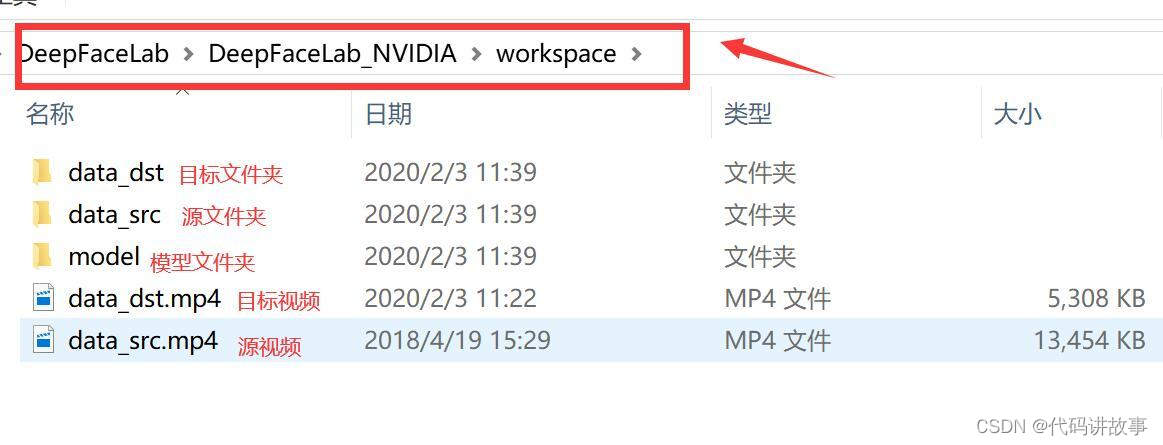
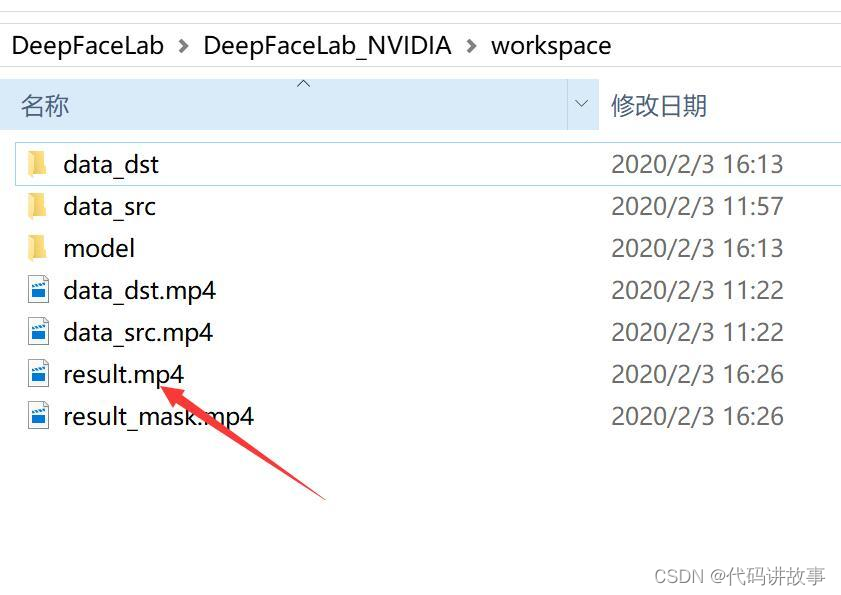
软件解压完成后会出现一个叫DeepFaceLab_NVIDIA的文件夹,里面有一个workspace,我们需要的文件都会在这里。这个文件夹下面有三个文件,两个视频,代表的意义如上图! 需要换自己的视频,只需要把这两个MP4换成自己的就好了。
软件运行过程中,在Data_dst 和data_src 中里面还会产生一个aligned的文件,里面会放置提取到的人//脸图片,比较重要!
流程介绍
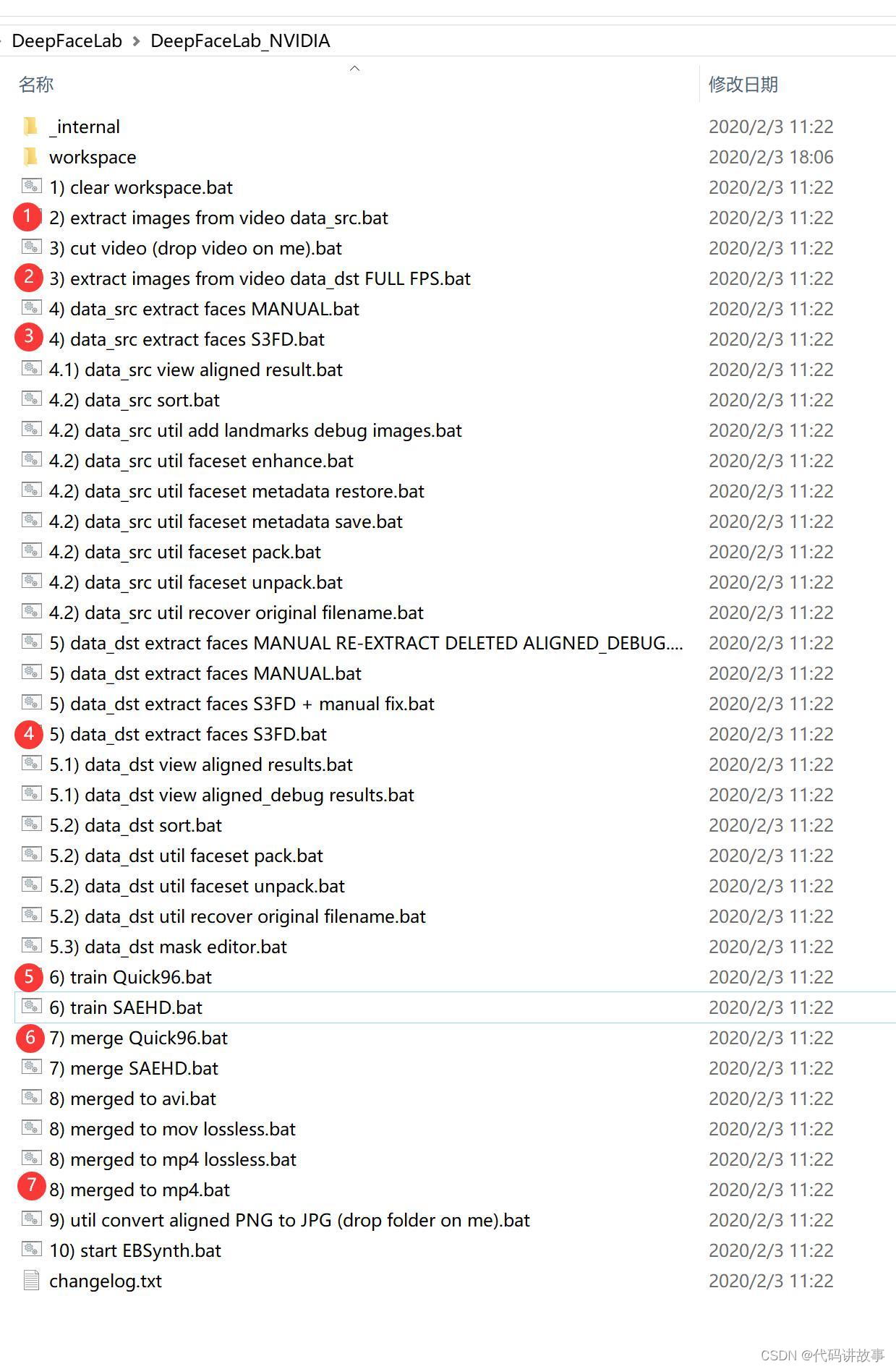
进入软件目录后会发现很多以.bat结尾的文件,叫批处理文件。此类文件在window系统下可以直接双击运行,和exe没有两样了。大致步骤如上。
软件使用的大概流程是:
- 把视频转成图片
- 从图片中提取头像
- 用头像训练模型(模型相当于……)
- 用训练好的模型实现图片换//脸
5 . 把换好脸的图片合成视频!
搞定。
具体的流程如下:
- extract images from video data_src.bat (把源视频拆分成图片)
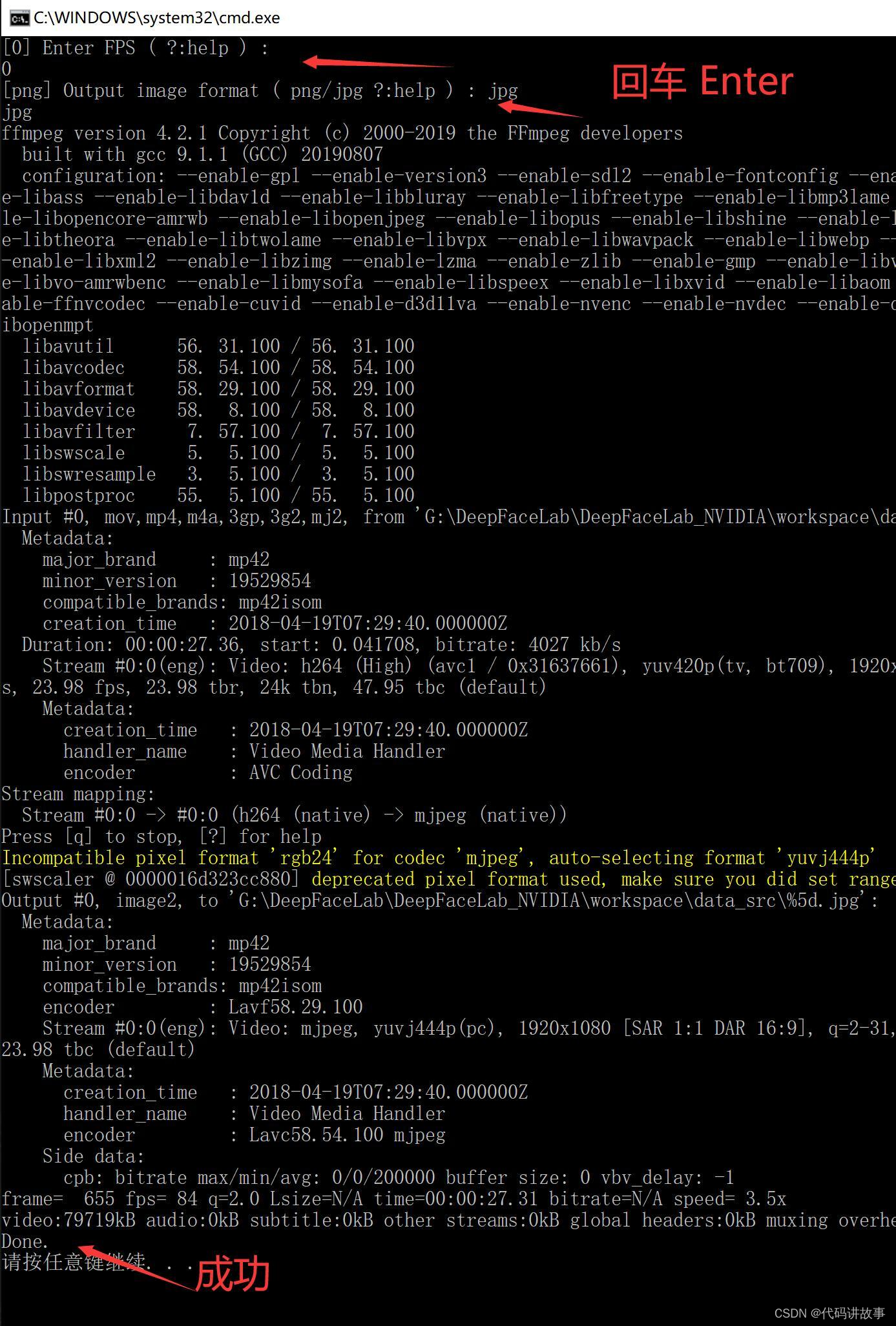
开头两个回车,等待,出现Done即表示处理成功。FPS :表示帧率,可以按回车默认,也可以输入一个数字。 Format代表图片格式,可以选JPG或者PNG,默认PNG。
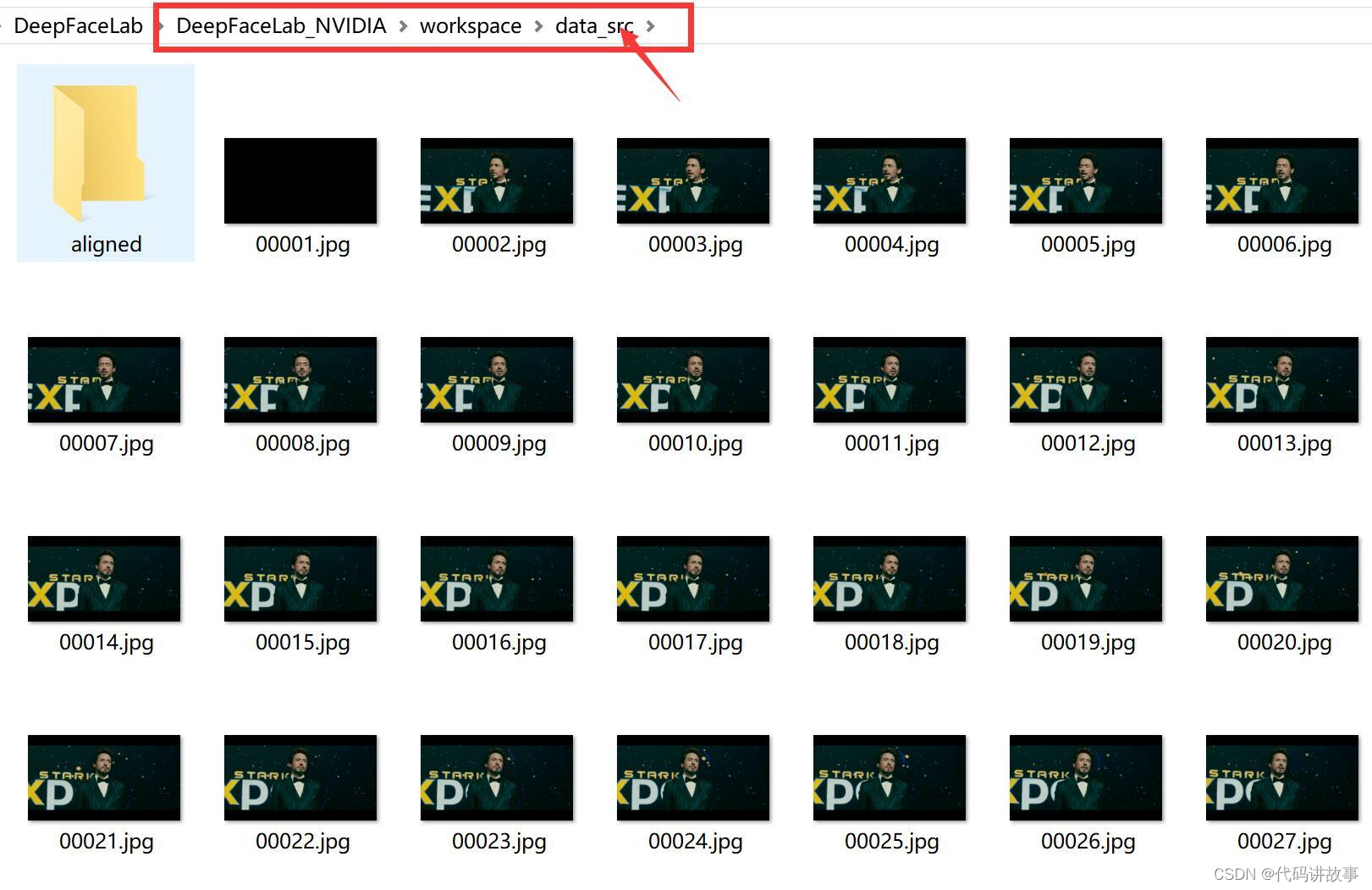
处理完成后,data_src文件夹下面会出现很多图片,这些图片就来自data_src.mp4视频。
- extract images from video data_dst FULL FPS.bat(把目标视频拆分成图片)
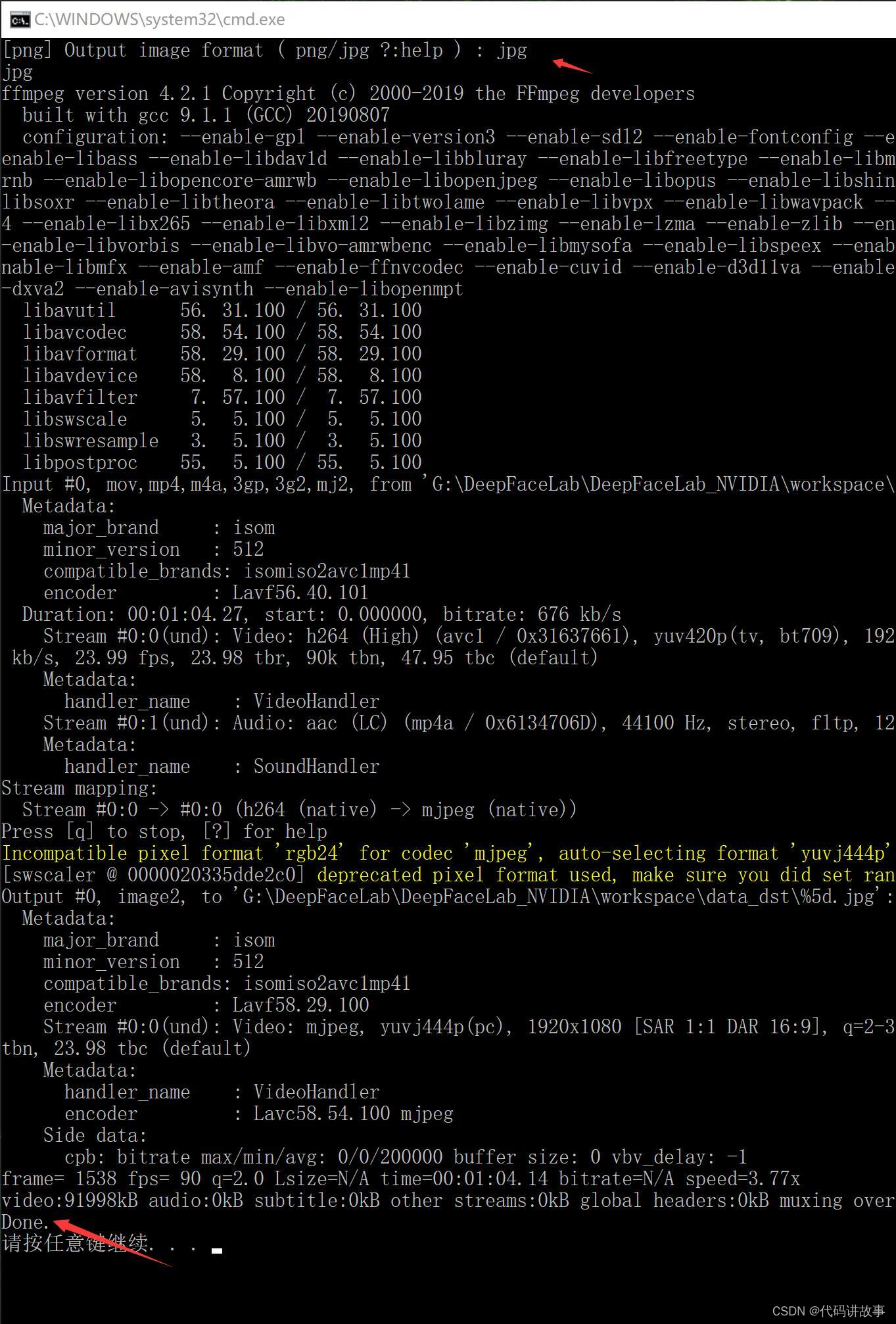
一个回车,等待一段时间,看到Done表示结束。
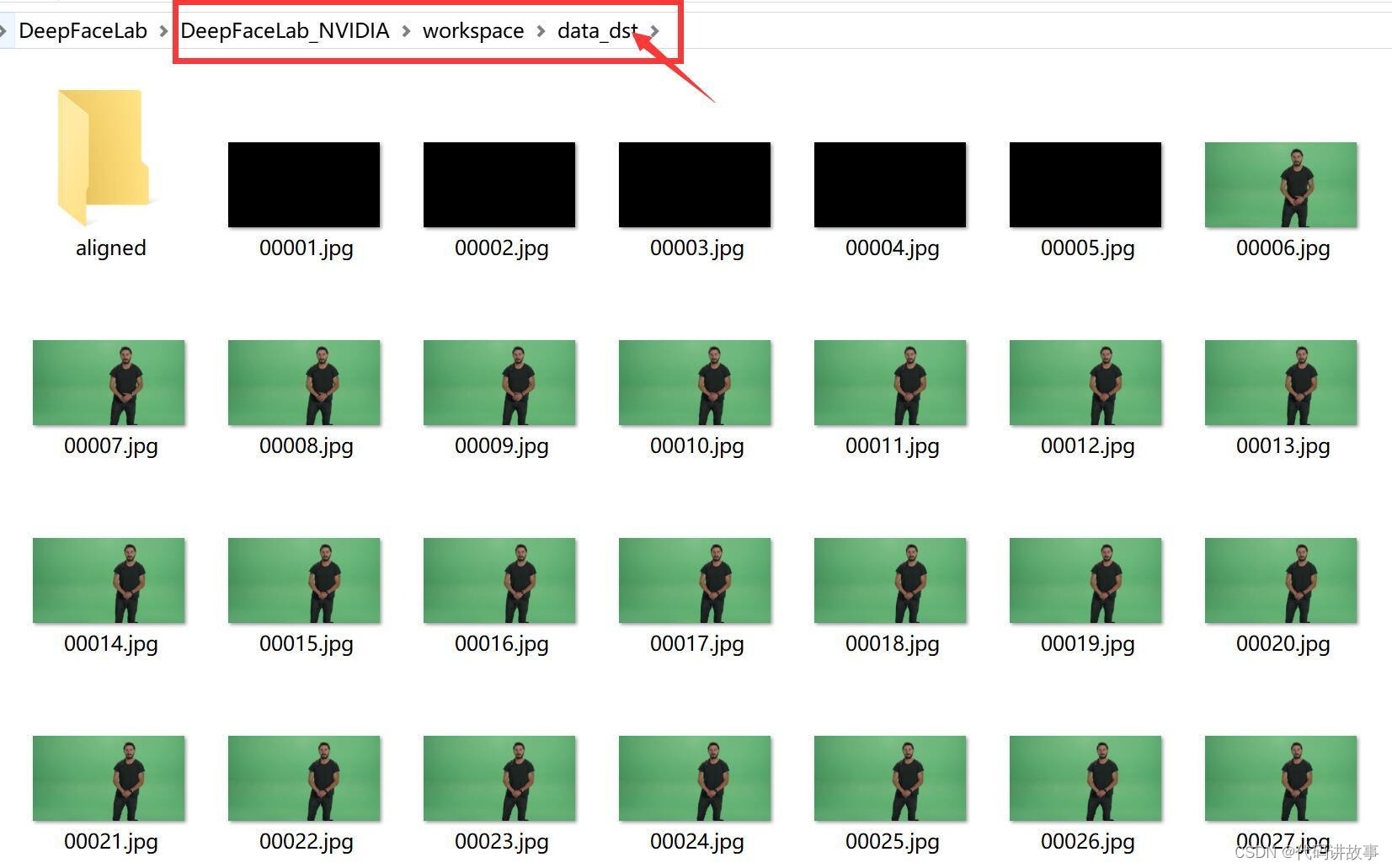
处理完成后,data_dst文件夹下面会出现很多图片,这些图片就来自data_dst.mp4视频。
- data_src extract faces S3FD.bat(从源图片中提取人//脸,也叫切脸)
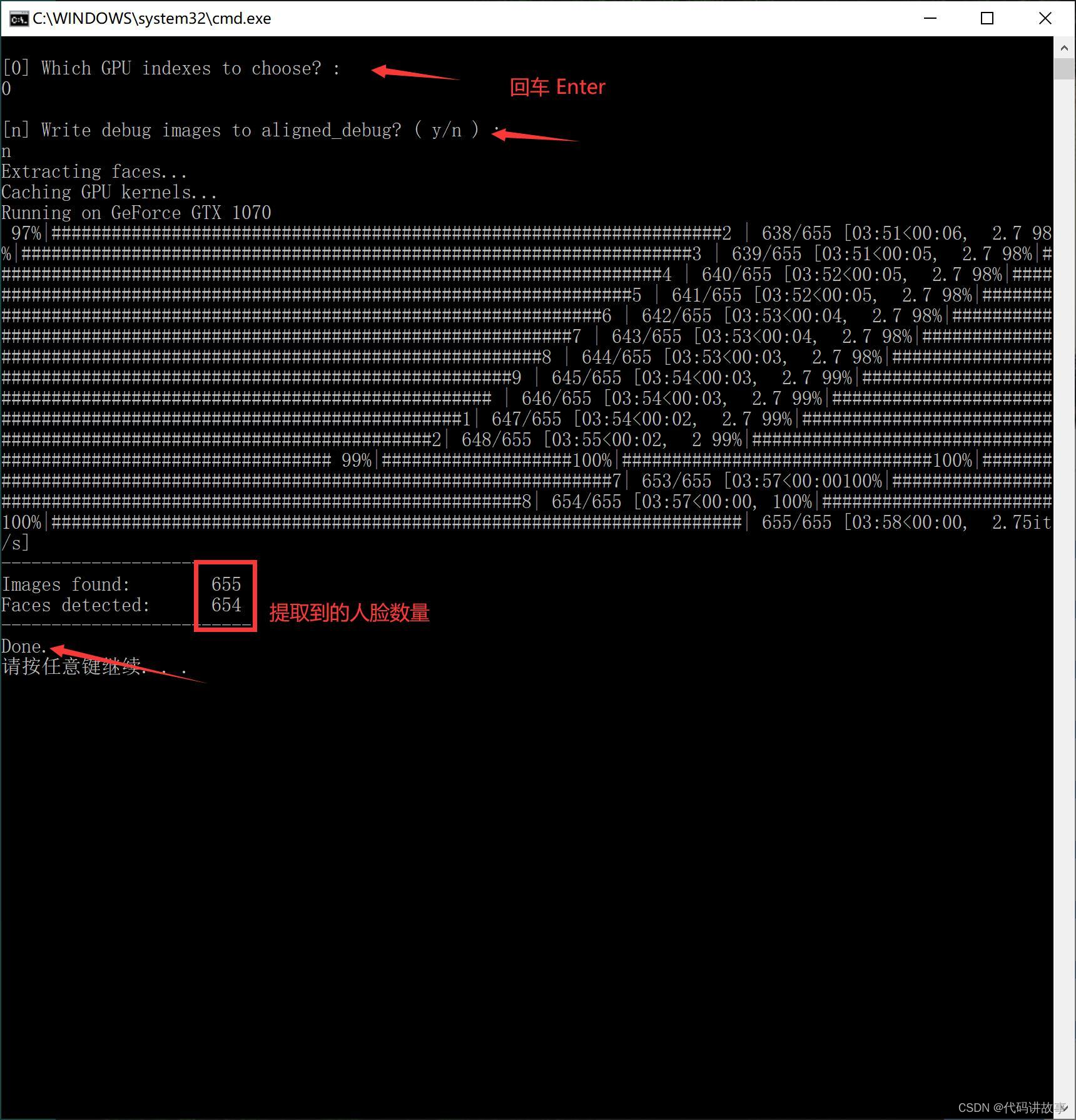
两个回车,显示进度条,最后会显示发现的图片和提取到的人//脸数量。 GPU index 是针对多卡用户,单卡用户直接回车。 Debug Image 一般不需要,默认回车即可。

操作成功后,data_src/aligned 文件夹下面会出现唐尼的头像。
- data_dst extract faces S3FD.bat (从目标图片中提取人//脸)
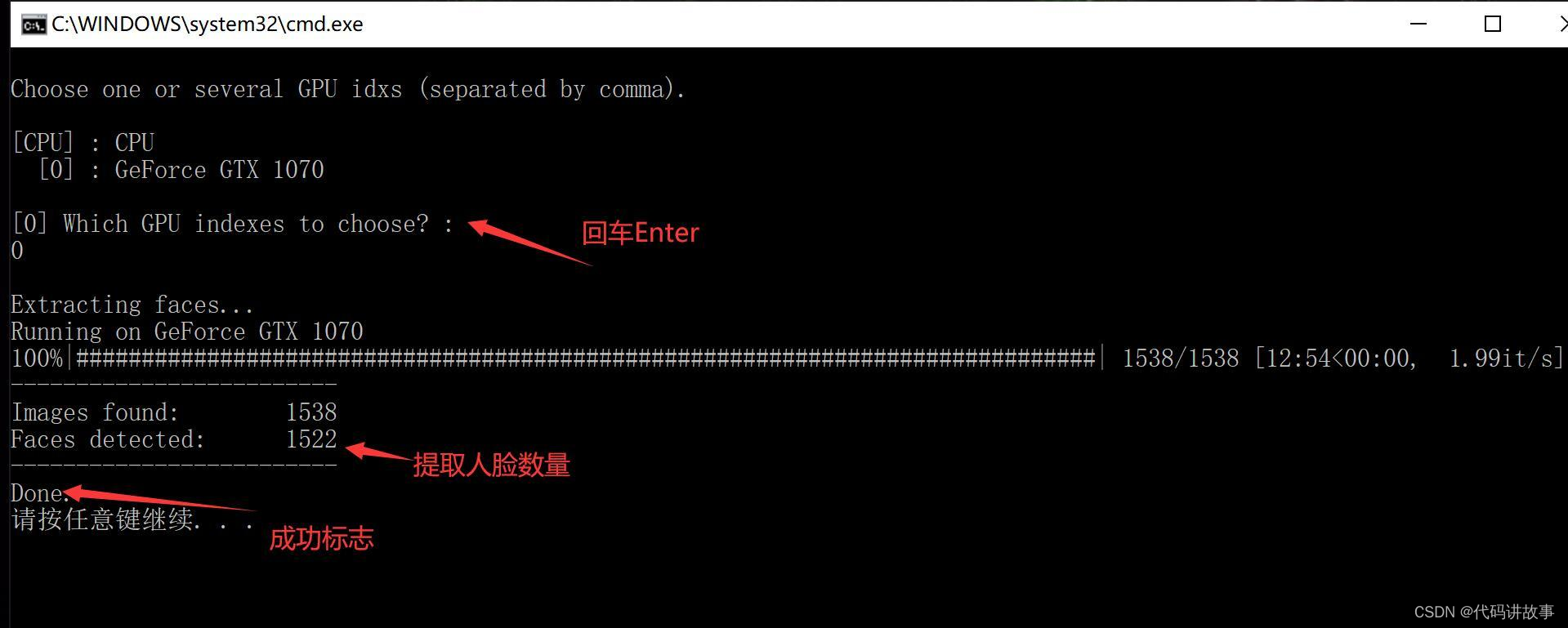
和上一步类似,只是少了一个参数Debug Image,其实是默认就启用了这个参数。
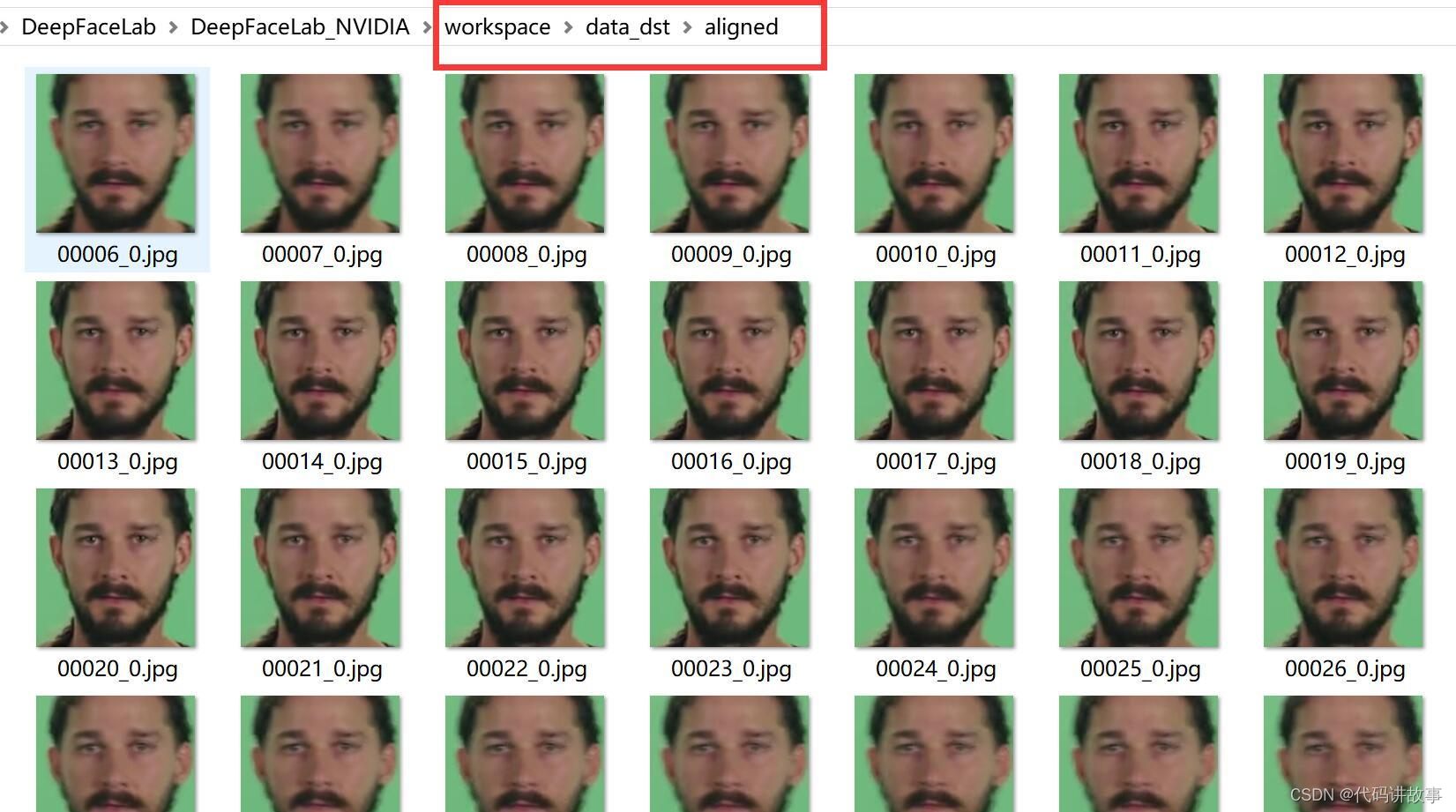
操作成功后,data_dst/aligned文件夹下会出现希亚·拉博夫的人头。在data_dst下面会出现一个aligned_debug文件夹。

打开里面的图片大概就是这个样子,作为新手看看就好了,不影响你后面的步骤。
- train Quick96.bat (训练模型,耗时,不会自己结束)
DeepFaceLab是基于深度学习的软件,而深度学习基本都会涉及到一个叫“模型”的东西。 模型就像是提炼出来的仙丹,可以理解为易容丹。 炼丹自然不是一件简单的事情,而且特别耗时间,还需要好丹炉,好药材。这一部至关重要。
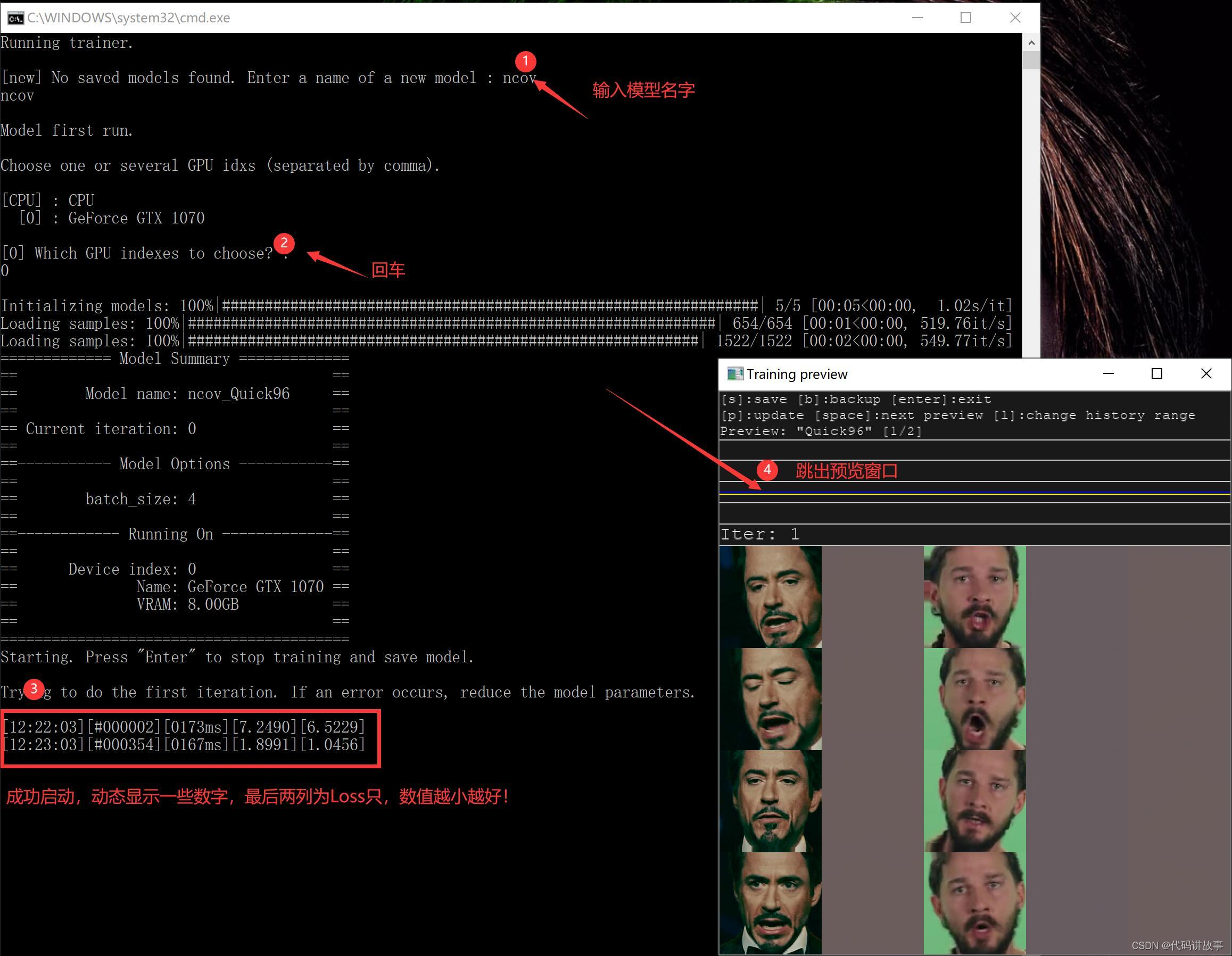
打开这个步骤后,需要先输入模型的名字。然后选择显卡,如果没有意外,就会出现③中的一行一行跳动的数字,代表已经开始炼丹。其中的Quick96表示模型的类型,除此之外还有SAEHD模型,SAEHD模型做出来的视频质量更好,但是要求的配置更高!
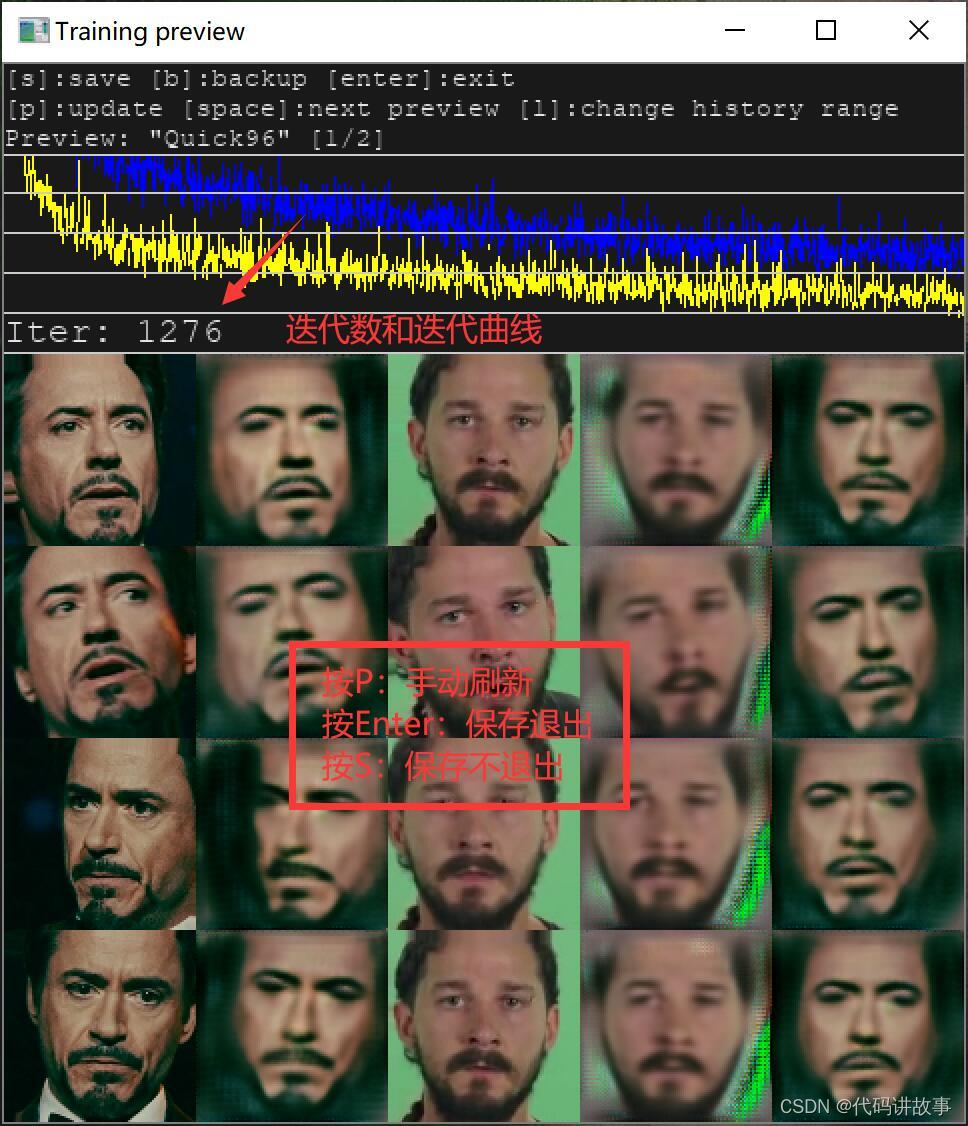
开始训练模型后,还会跳出一个新的窗口预览窗口,上面有使用帮助,迭代历史,迭代次数,还有五列头像。第一列和第二列是源头像,第三列和第四列是目标头像,第五列是最终头像。1,3 是参考标准,2,4,5是生成的头像,生成头像越来越接近参考标准,就证明模型越来越好。
当鼠标点击这个窗口后,在英文输入法下,可以使用快捷键。
P:刷新预览图
S:保存模型
Enter :保存模型,然后退出!
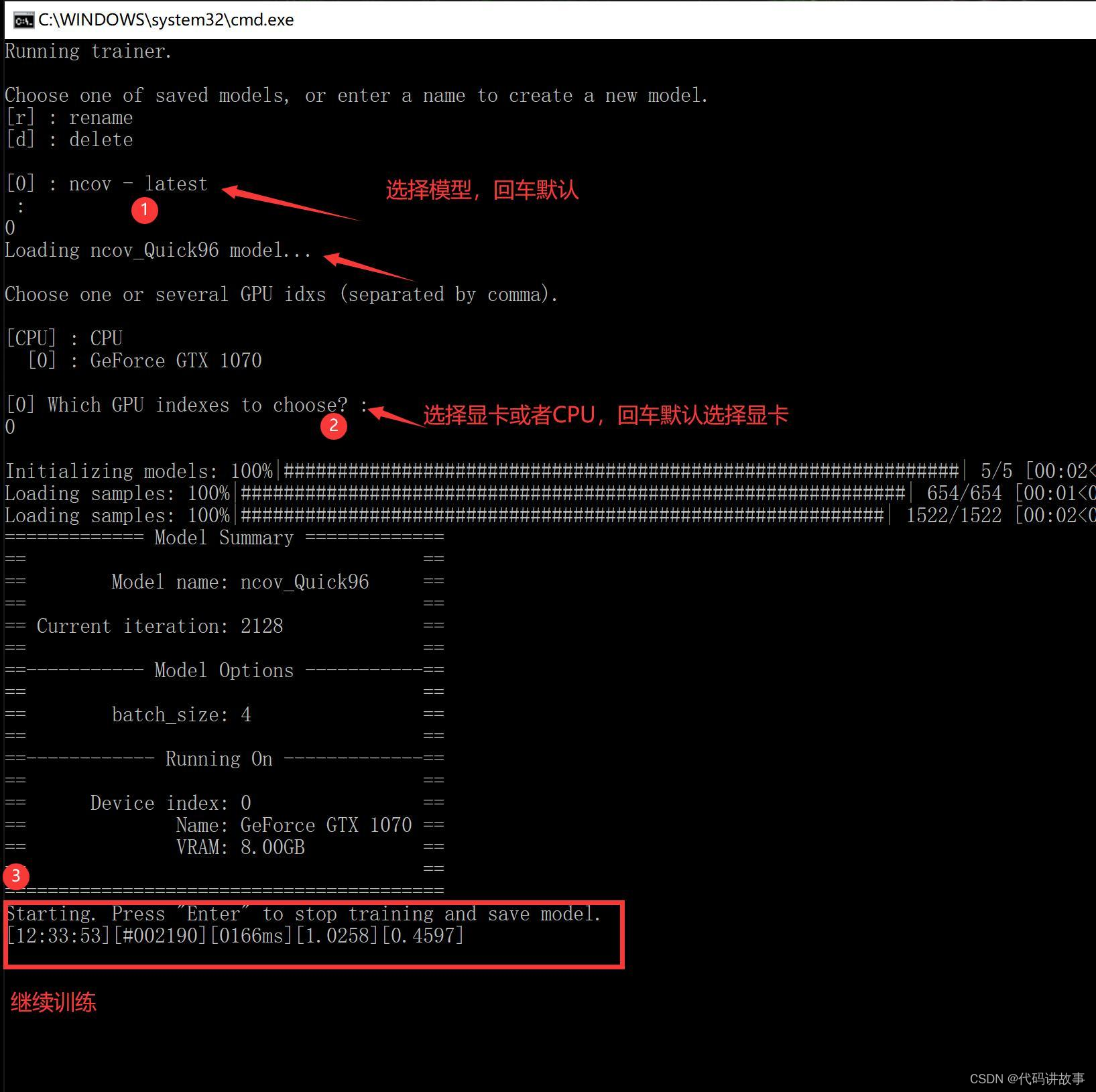
退出后再次点击train Quick96.bat 可以继续训练,进度不会丢失。 继续训练的时候需要选择模型,选择显卡,然后同样会显示一行数字,跳出预览窗口
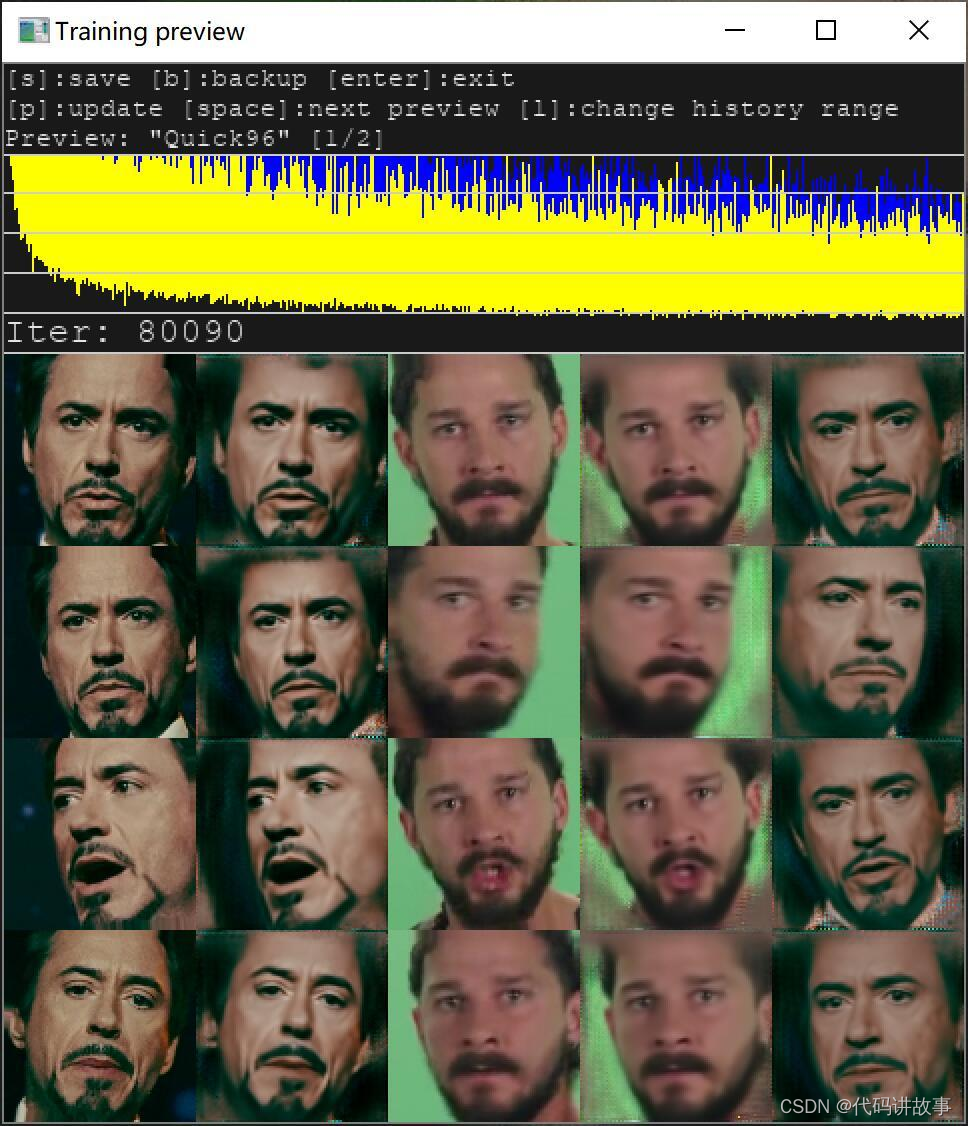
随着时间的推移,2,4,5列头像会越来越清晰,如果你觉得够清晰了,就可以关闭窗口,进入下一个步骤。
- merge Quick96.bat (图片换//脸)
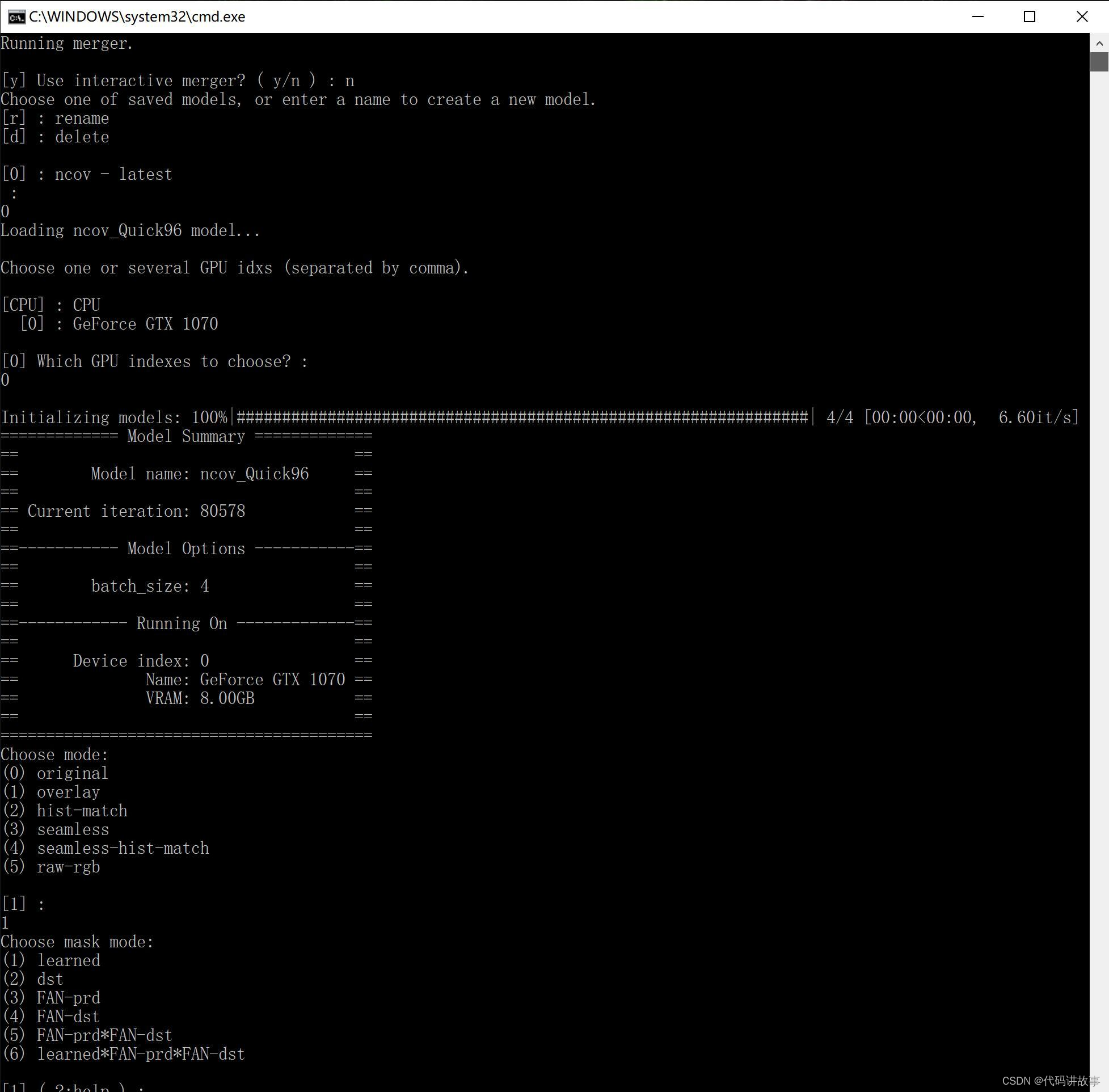
这个步骤,有两种方式。Use interactive merger? 输入y启动交互式转换器(默认为y), 输入n为普通的命令行。我这里先输入:n,回车,继续回车选择模型,继续回车选择显卡。在此之后,还会有非常多的参数需要输入,一律按回车!
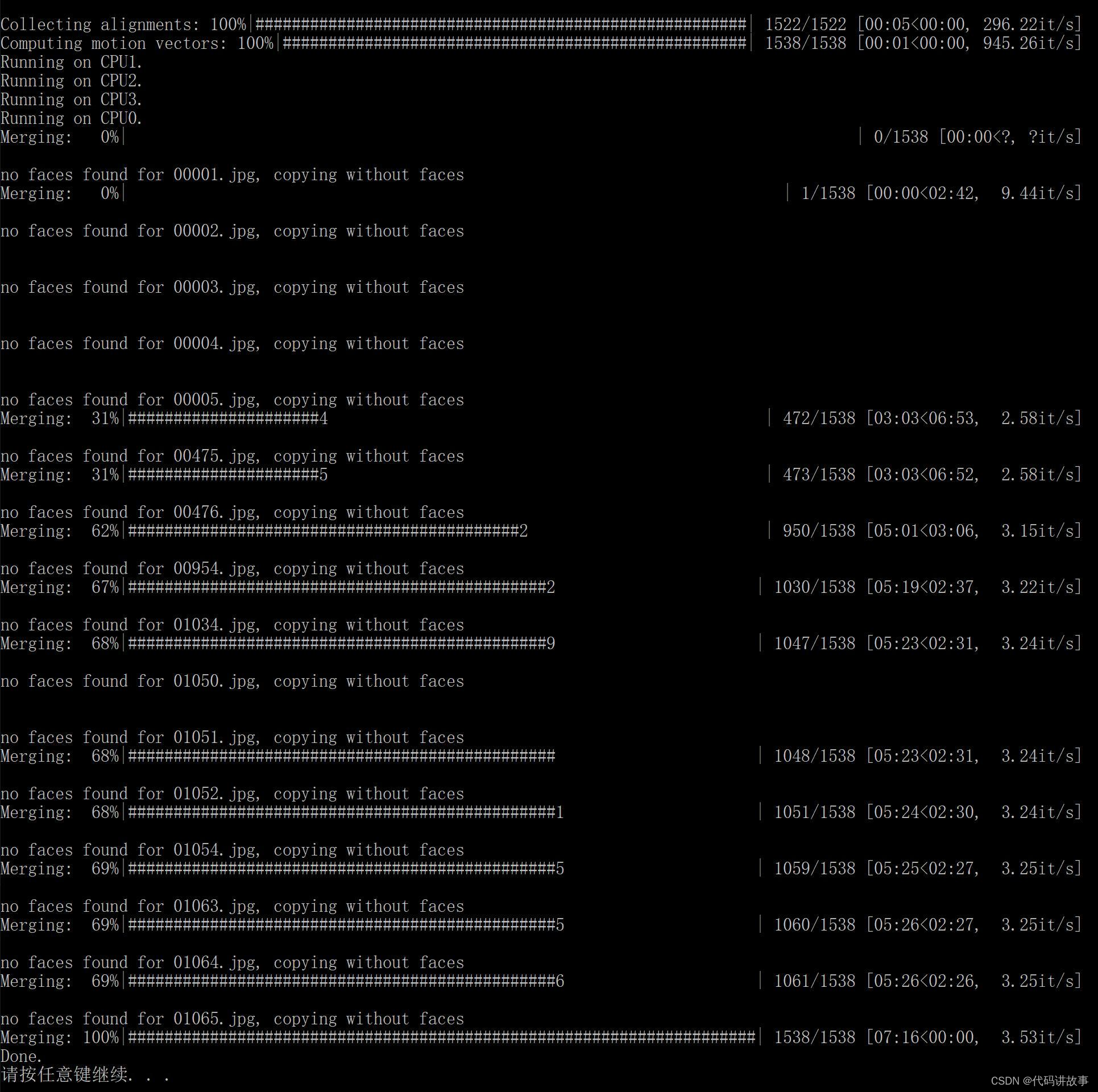
回车到不能回车之后,就会自动开始转换过程。过程中会显示百分比,当到达100% Done 就代表转换结束。
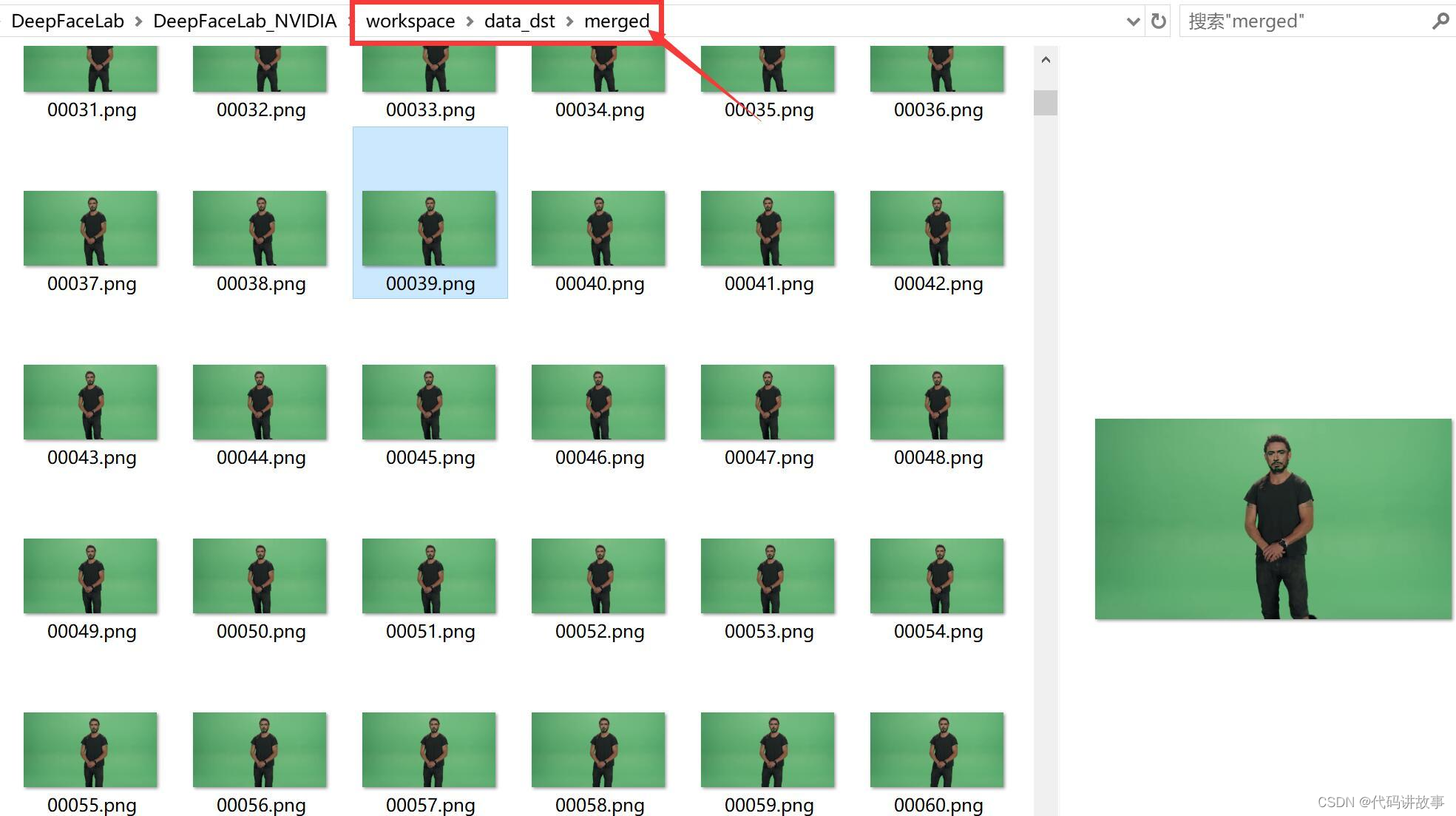
此时, 在data_dst 下面会多出一个merged文件夹,文件夹里面就是已经换//脸成功的图片。

随便打开一张,大概是这个样子的。唐尼的脸已经换上去了。边缘之所以有些生硬,是因为我们全部使用的默认参数。适当调整可以改善,具体调整方法与之前版本类似。
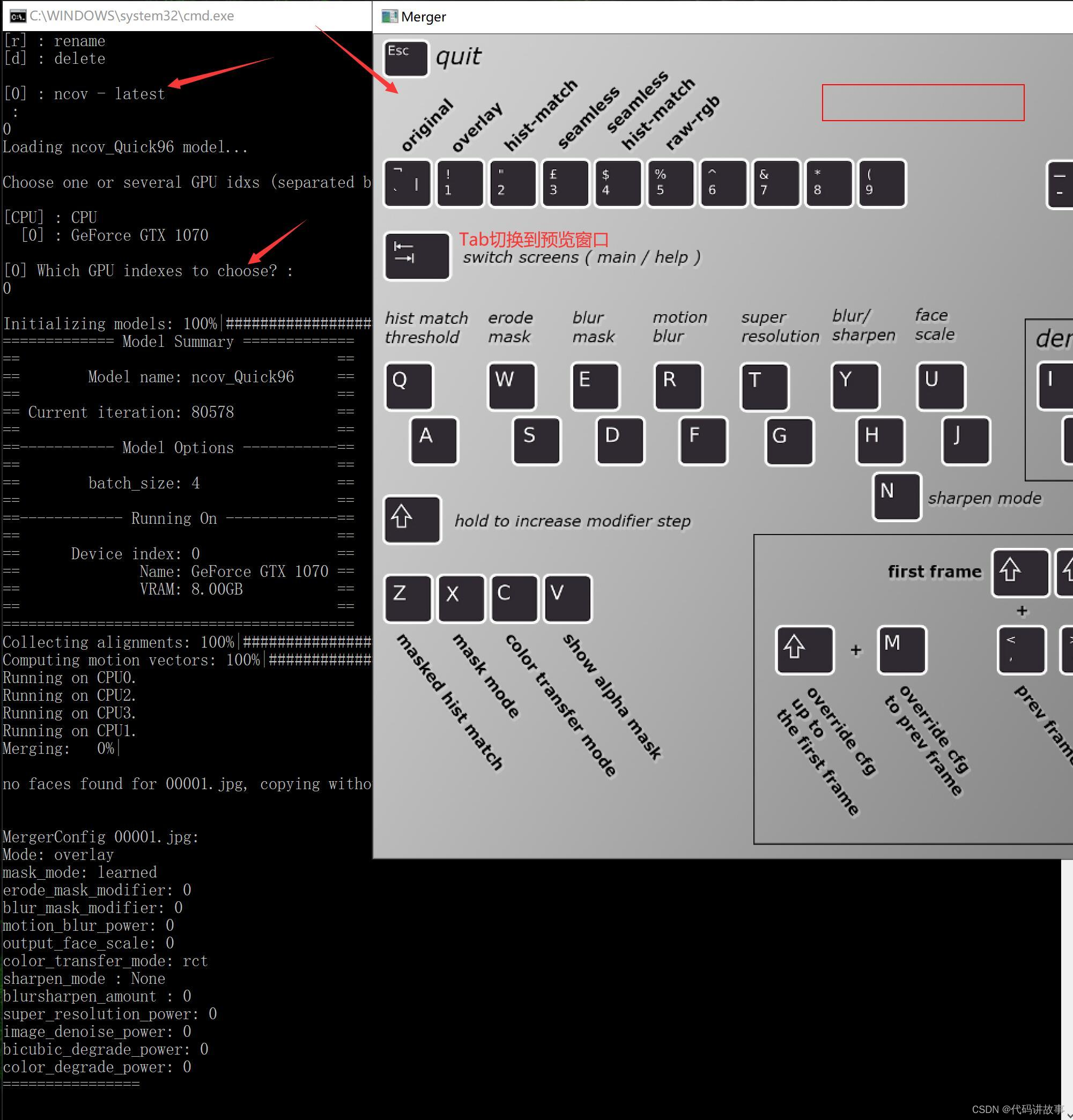
另外一种方法:Use interactive merger? 输入y 或者直接回车。此时进入交互式界面的帮助窗口,上面写着调整合成参数的快捷键,考验手速和记忆力的时候到了。通过按键盘上的Tab键可以进入预览界面。

在预览界面上,按对应的快捷键就可以调整效果。调整方法和老版本基本类似。 自动合成的快捷键调整成了shift+>
- merged to mp4.bat (把图片合成视频)
这一步的功能是把已经换//脸成功的图片合成视频。打开后有一个参数:码率。可以直接默认,默认情况下码率很高清晰度最高但是合成文件非常大,也可以输入特定的值比如:3 。
这个步骤并不会消耗太多时间,结束后在workspace下面可以看到一个叫result.mp4的文件。

AI领域人才辈出,突然就跳出一个大佬“s0md3v”,开源了一个单图就可以进行视频换//脸的项目。
https://colab.research.google.com/github/dream80/roop_colab/blob/main/roop_v1.ipynb
项目主页给了一张换//脸动图非常有说服力,真是一图胜万言。

快速在本地配置一个环境,验证了一下,确实还不错。主要是,简单,快速,简单,快速,简单,快速!只是本地配置要下一堆东西,配一堆东西,对普通人来说可能还是有一点压力,动手能力强一点的估计也得折腾一阵子。
为了节省大家的时间和脑细胞。我已经快速编写了另一个基于谷歌Colabd的脚本。有需要的直接可以拿去用!
只要魔法加持,无需本地配置,无需高配电脑,点点鼠标即可完成。
下面简单地介绍一下使用方法~~
首选,打开这个地址:
https://github.com/dream80/roop_colab
然后点击红色圈中的ipynb文件!
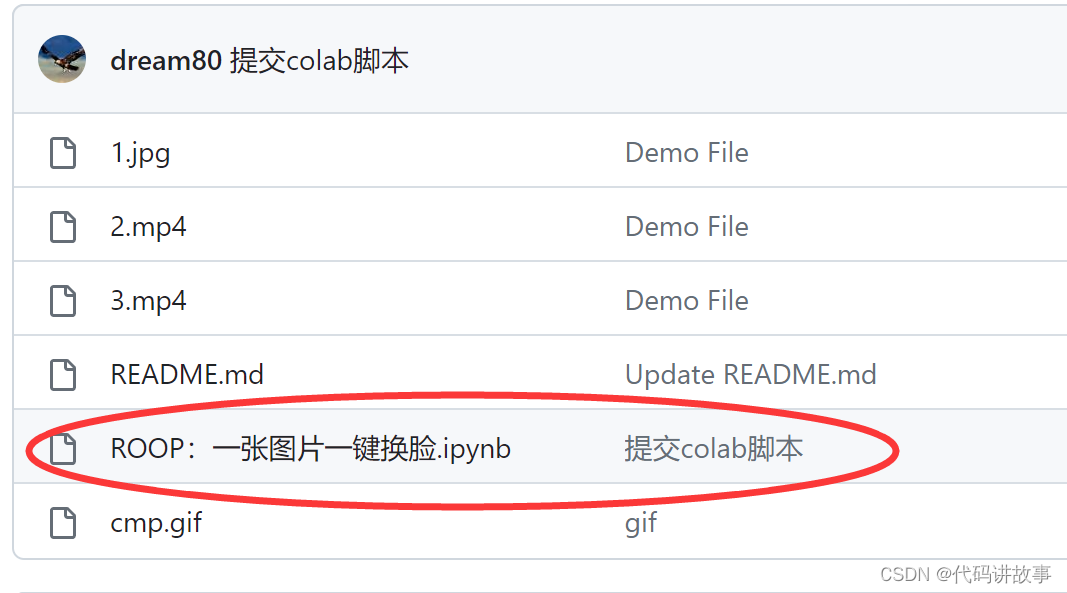
然后点击“Open in Colab ”

进入谷歌Colab平台之后,依次点击脚本。就可以完成整个换//脸流程了。鼠标移到“括号”就会出现一个可以点击的“播放”按钮。
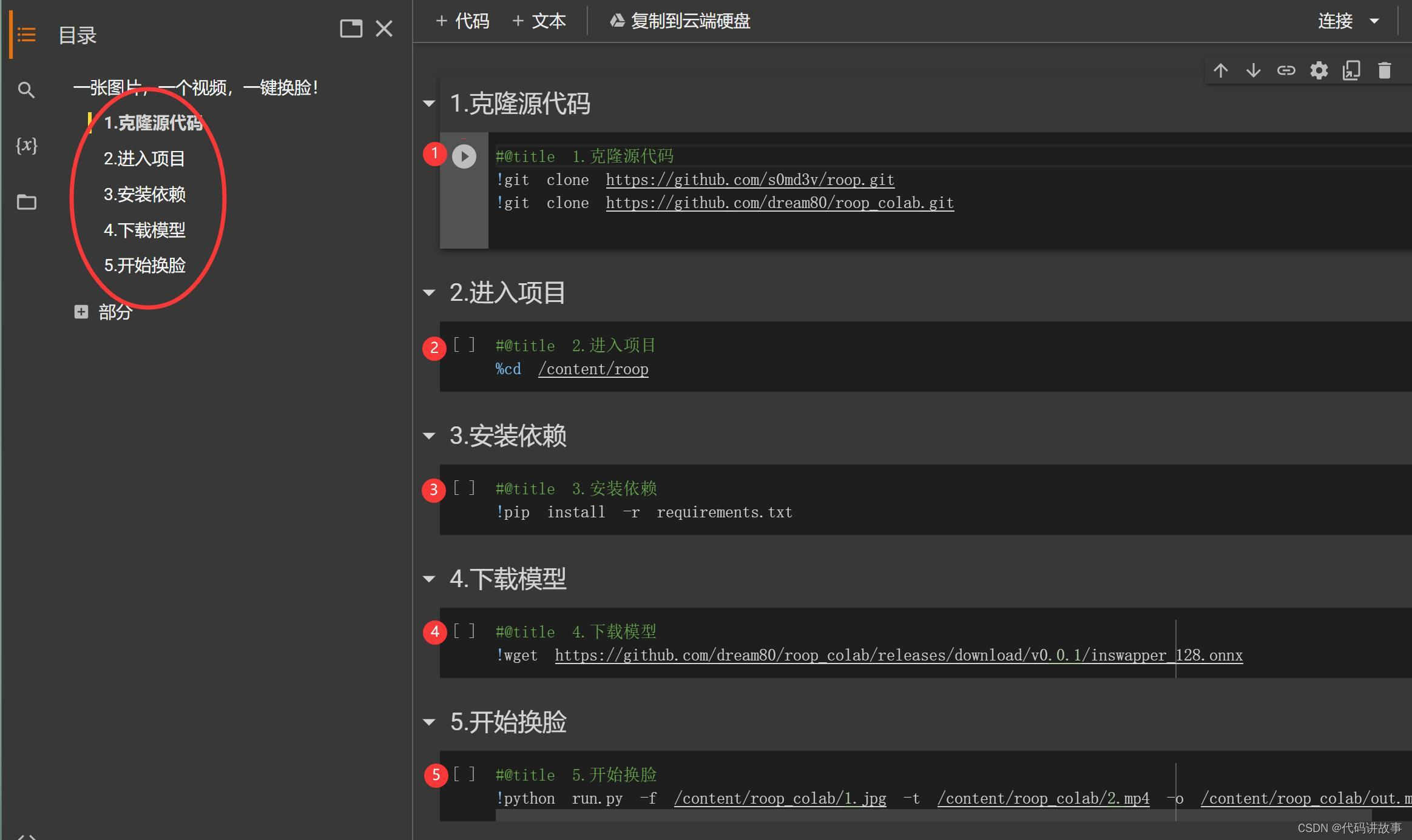
也可以在顶部菜单中找到“代码执行程序”-> “全部运行” ,这样就可以一键运行了!
为了让大家快速切无异常的体验到单图换//脸的乐趣,我已经准备好了演示的图片和视频素材。
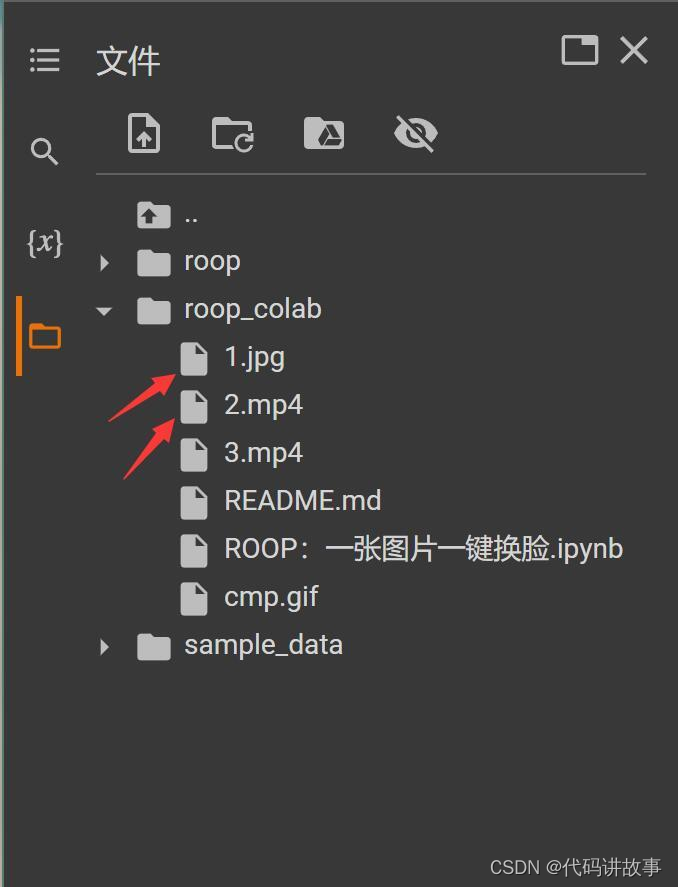
运行完①之后,可以在左边的文件管理里面查看。如果你想替//换图片和视频,只要把这两个文件换掉。替//换之后,重新点击⑤就好了。
文件不是很大的话,可以直接右键点击roop_colab文件夹,点击上传,找到电脑上的视频文件上传就可以了。
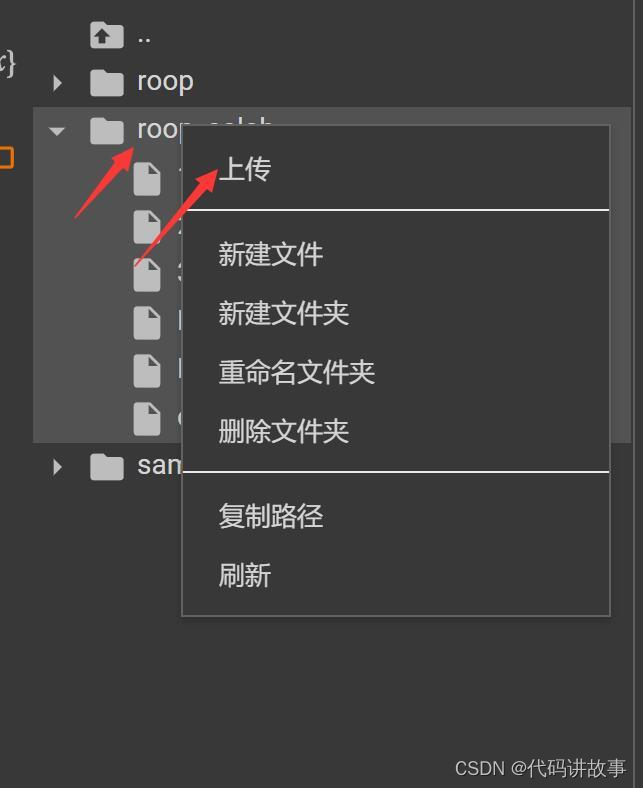
上传成功之后,把原来的1.jpg和2.MP4删除,把你自己上传的照片和视频改成这两个名字,然后运行第⑤步就可以了。
第⑤运行完成之后,会生成一个叫out.mp4的视频文件,这个就是换//脸后的文件了。
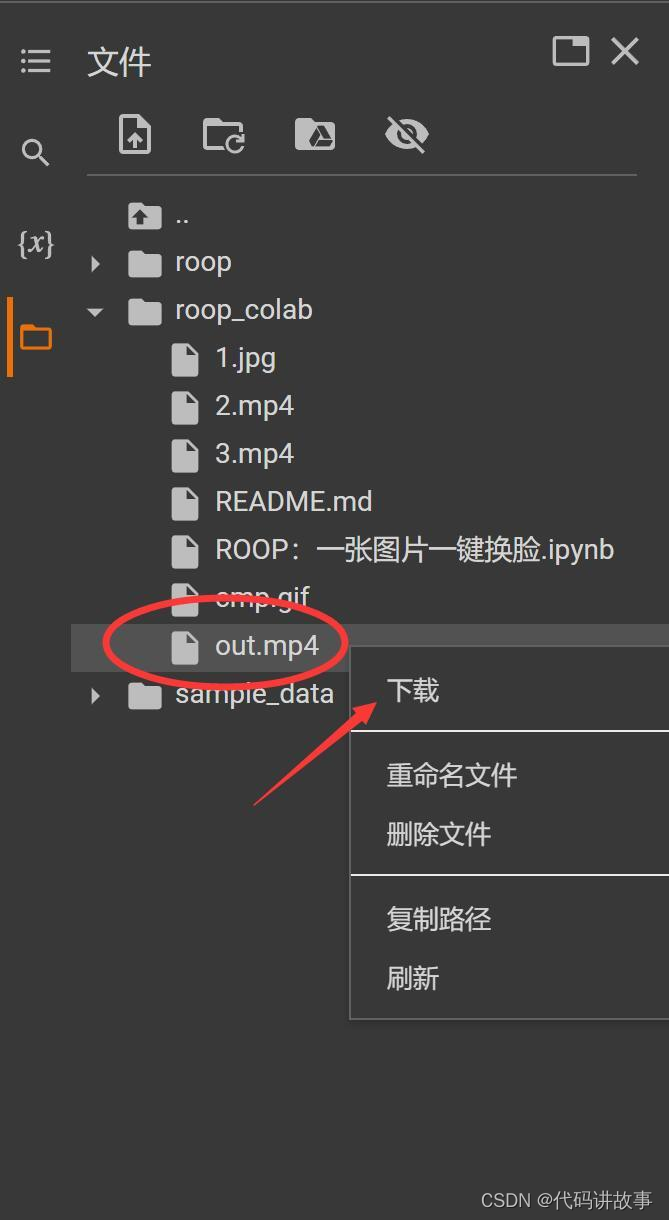
在左侧的文件管理器中,右键,下载就可以了。下载到本地电脑上就直接可以查看效果咯。
本地离线版:
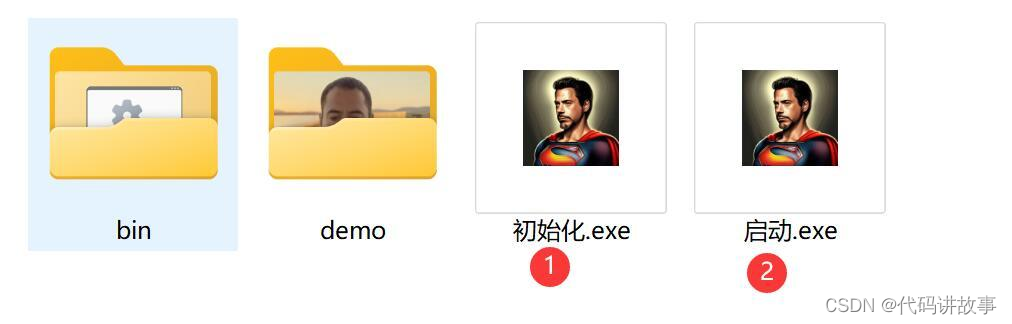
Roop作为一个新出的开源项目,配置起来还是有一定难度的。我已经把各种依赖,模型,环境配置已经都弄好了。
另外还放了一个演示素材,兄弟们,一条龙了啊。
下面就简单说一下使用方法。
①初始化
这个步骤主要是把一些辅助模型拷贝到对应的位置,如果你电脑有魔法,直接点“启动”也会自动下载。
既然是离线版,肯定要考虑到“局域网”用户,所以我想了个办法,先把东西放在压缩包里,点一下,会自动把文件放到指定位置。这个指定的位置就是你电脑的用户目录。
②启动
点击“启动.exe”就可以启动软件了。
点击之后,会先跳出黑色的命令窗口,等一会儿会跳出一个界面。跳不出来,那就是出问题了,可以反馈给我!
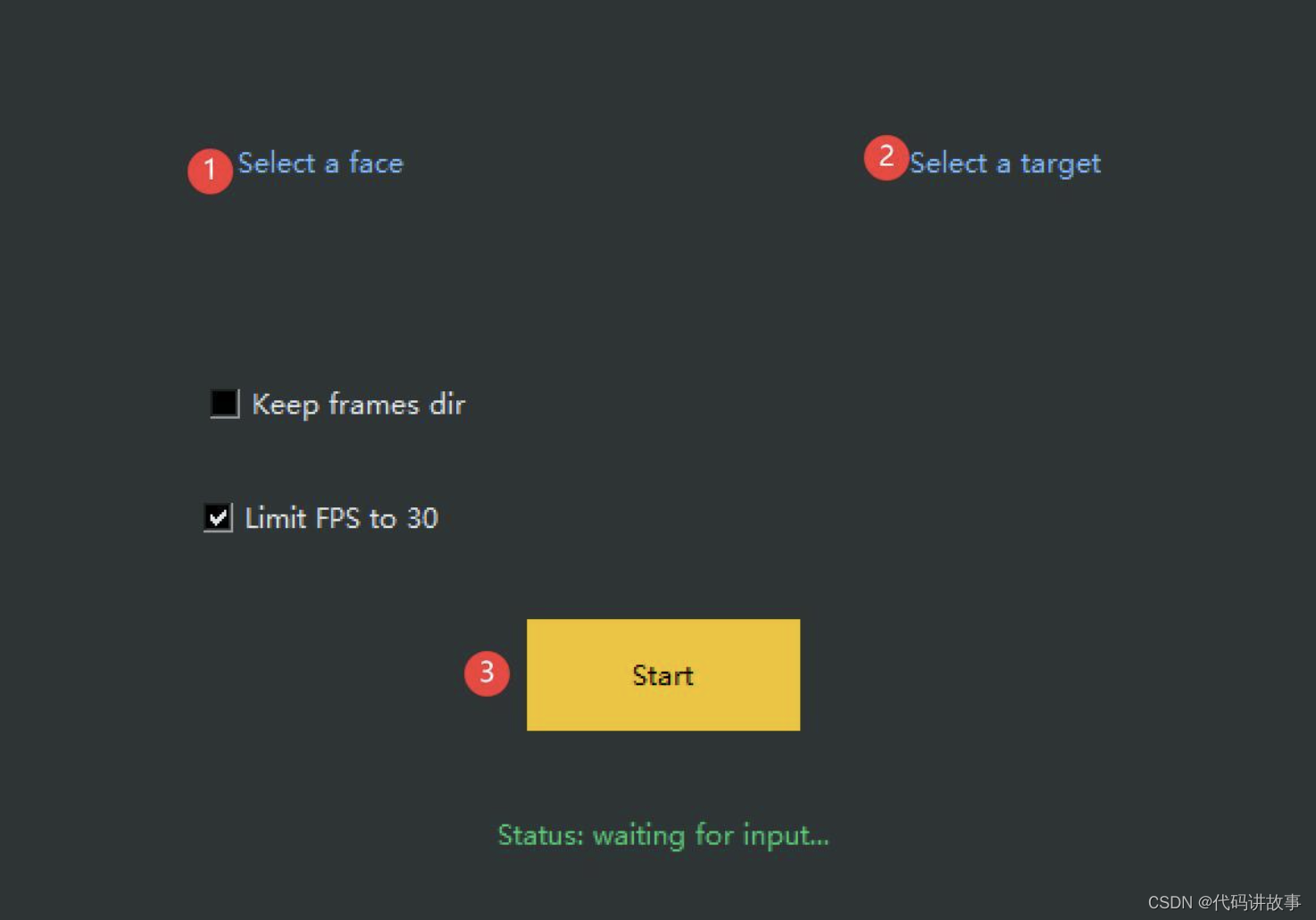
③选择图片和视频
界面出现后,就可以选①照片和②视频了。照片肯定是要选有人//脸,清晰,完整,正面的图片(路径和文件名不要有中文,不要有中文,不要有中文)。最好选特征比较明显的人,换//脸效果更明显。视频最好是不要整太大,先搞个720P,几十秒钟的练练手。如果要快速体验,可以用我放在demo里的素材。
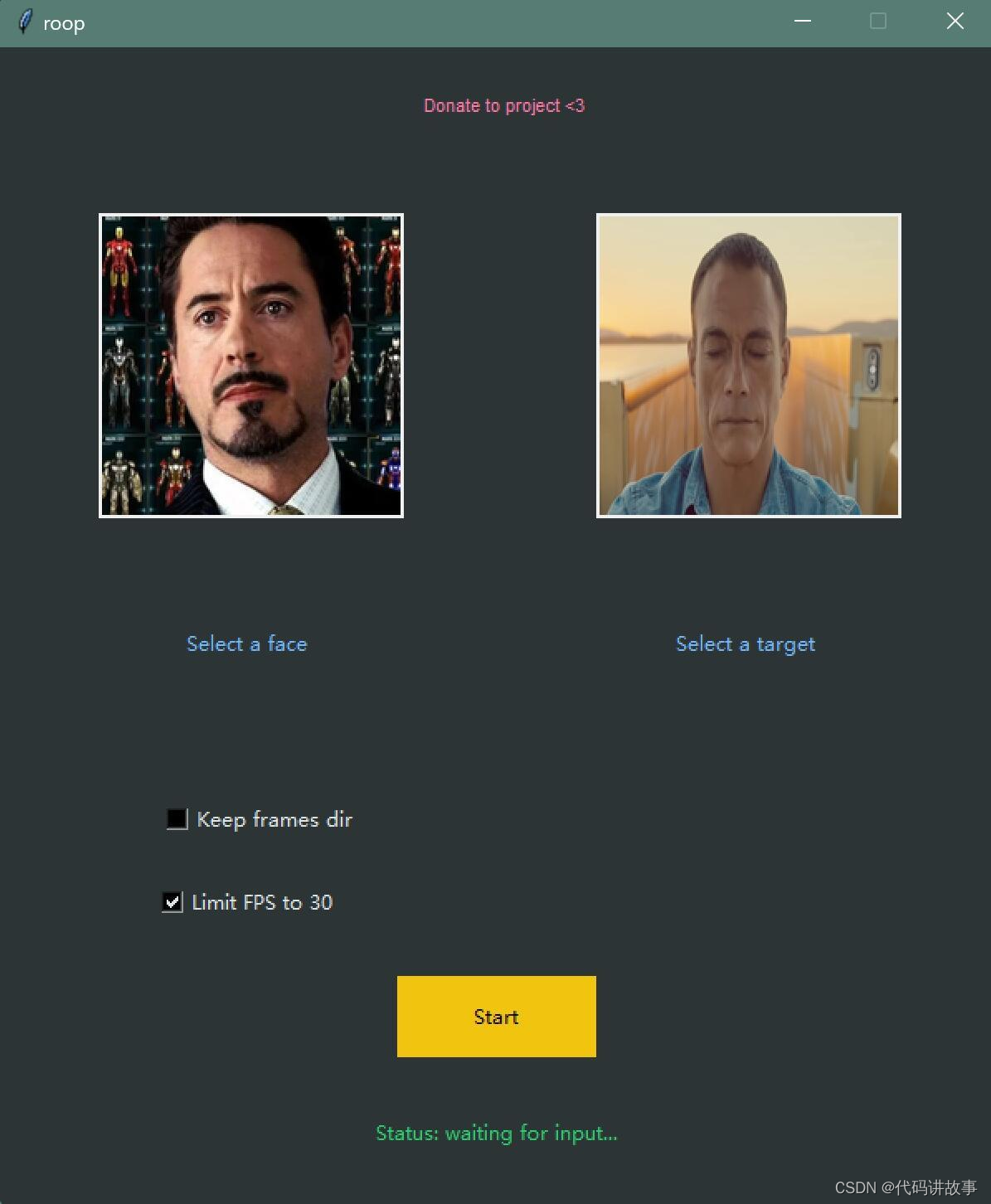
界面上有两个参数可以设置,一般来说,不要动,用默认。
④开始换//脸
设置和照片和视频之后,只要点击③Start 就可以开始了。点击之后会跳出一个窗口,让你选择换//脸后的视频放在哪里。设置好存储路径之后,就真的开始处理了。处理过程中这个界面会卡死,命令窗口会有进度。
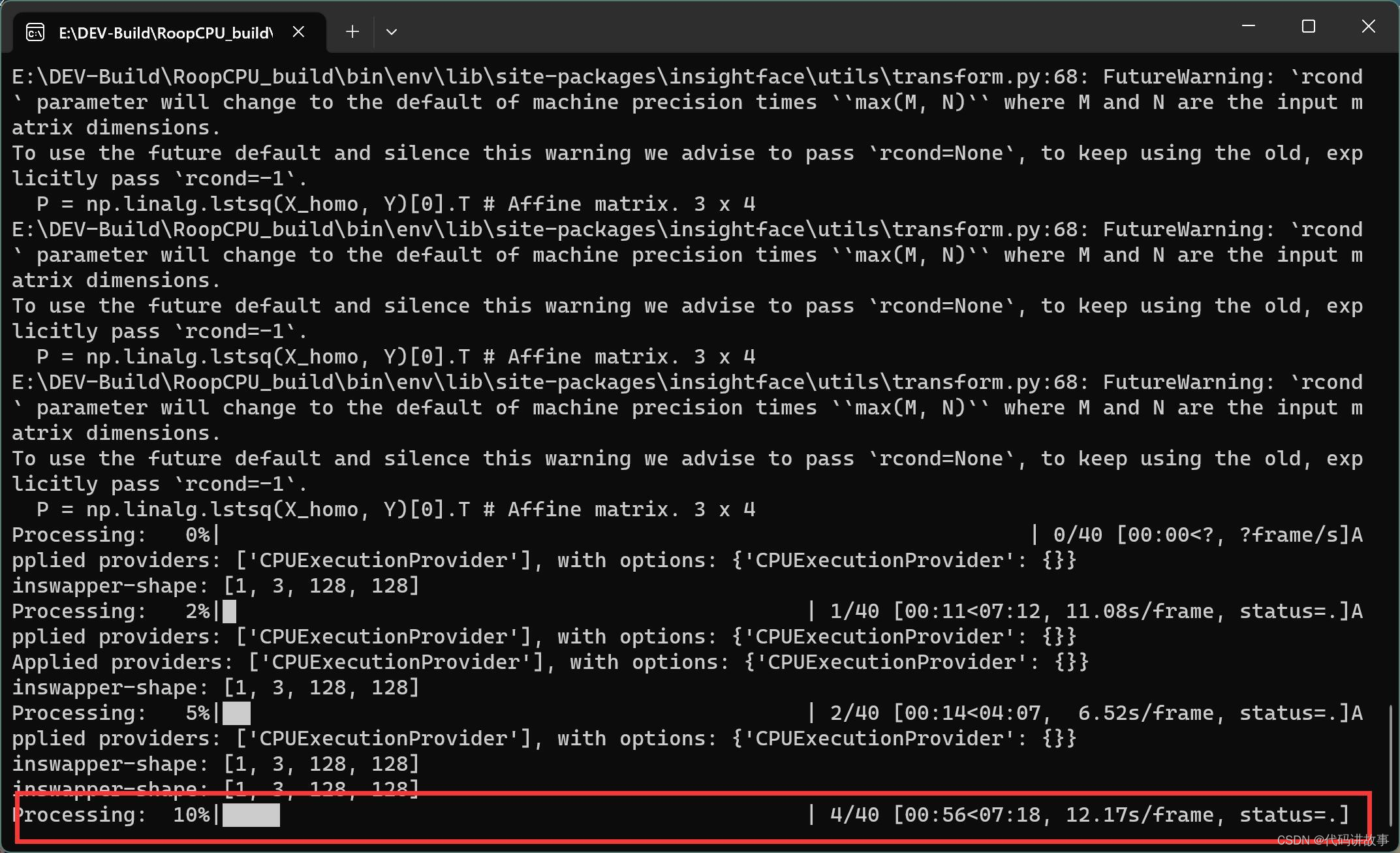
处理大概分了三个阶段,第一阶段是视频分割,然后处理,最后是合成。在处理阶段会把CPU资源占满,不管你多少的CPU都会爆卡,但是也不用担心CPU。
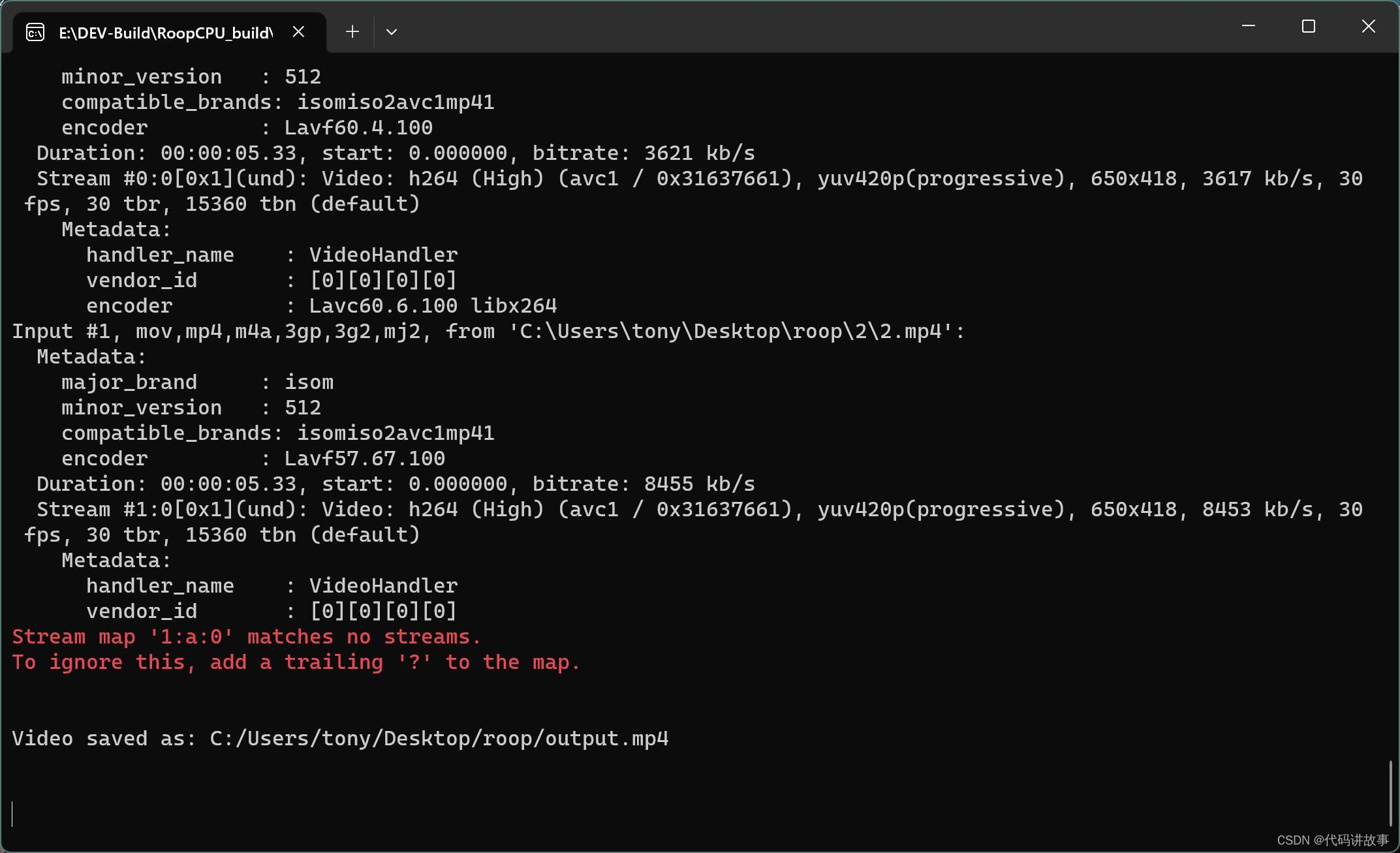
处理完成后,会看到”Video Saved as ….” 这里可以看到具体的保存路径。
⑤查看效果
通过事先的设置,或者最后的路径提示,找到视频,打开,就可以看到效果了。

换//脸效果还是可以的,融合得也不错。就是人//脸比较大的话看起来会有些模糊。用来做做小视频,或者搞笑视频,足够了。
侧脸部分,幅度不能太大,太大了会乱飘。多人的场景也会出现混乱,所以最好用来处理单人的视频。
相比DFL来说,操作真的是简单太多,制作也快了很多。但是论可玩性,效果上限,DFL依旧是换//脸界的王者。
另外,我这次制作的是CPU版,理论上所有Windows系统的电脑都可以跑。我有测试过AMD和inter的CPU都可以。
GPU版本正在研究,我在3060 12G上能正常运行,但是3070 8G上却一直卡死,这个项目对系统资源的利用相当“残暴”。我看看有啥优化方式,等我搞明白了,再发布。
还有一个问题,roop刚上的时候是没有限制涩涩的,但是很快就加入了NSFW的检测。好多人问,在线脚本为啥不能换素材,就是这个原因。
参考资料:
https://github.com/iperov/DeepFaceLive
https://github.com/iperov/DeepFaceLab
https://github.com/dream80/roop_colab
https://github.com/s0md3v/roop