🌈个人主页:Fan_558
🔥 系列专栏:高并发内存池
🌹关注我💪🏻带你学更多知识

文章目录
- 前言
- 本文重点
- 一、构建CentralCache结构
- 二、运用慢开始反馈调节算法
- 三、完成向CentralCache中心缓存申请
- 四、承上启下
- 小结
前言
本文将会带你走进高并发内存池的CentralCache的设计
本文重点
那我们在此模块将要完成以下任务:
1、结构上,我们需要设计CentralCache的结构——设计Span结构(双向带头链表)
2、对于CentralCache整个进程中只有一个,我们可以设计一个单例模式(饿汉)实现
3、设计慢开始反馈调节算法计算出centralcache应该给threadcache多少个对象
4、完成FetchFromCentralCache(向中心缓存申请内存对象)与FetchRangeObj(从CentralCache结构中获取一定数量的对象给threadcache)函数
5、承上启下
一、构建CentralCache结构
central cache与thread cache有两个明显不同的地方,首先,threadcache是每个线程独享的,而central cache是所有线程共享的,因为每个线程的threadcache没有内存了都会去找central cache,因此在访问central cache时是需要加锁的。
但central cache在加锁时并不是将整个central cache全部锁上了,centralcache在加锁时用的是桶锁,也就是说每个桶都有一个锁。此时只有当多个线程同时访问central
cache的同一个桶时才会存在锁竞争,如果是多个线程同时访问central cache的不同桶就不会存在锁竞争。
central cache与thread cache的第二个不同之处就是,thread cache的每个桶中挂的是一个个切好的内存块,而central cache的每个桶中挂的是一个个的span。而每个span中都会指向一个自由链表,自由链表链接的内存对象大小与桶一一对应
注意:centralcache的映射规则和threadcache是一样的,也就是说centralcache里面的哈希桶个数也是208,这样设计的好处是当线程向thread cache某个桶中申请内存对象时,如果没有内存了,就直接去central cache对应的哈希桶进行申请就可以了

每个线程都有一个属于自己的thread cache,我们是用TLS来实现每个线程无锁的访问属于自己的thread cache的。而central cache和page cache在整个进程中只有一个,对于这种只能创建一个对象的类,我们可以将其设置为单例模式。
单例模式可以保证系统中该类只有一个实例,并提供一个访问它的全局访问点,该实例被所有程序模块共享。单例模式又分为饿汉模式和懒汉模
式,懒汉模式相对较复杂,我们这里使用饿汉模式就足够了。
// 单例模式(饿汉
class CentralCache
{
public:
//提供一个全局访问点
static CentralCache* GetInstance()
{
return &_inst;
}
//获取一个非空的Span
Span* GetoneSpan(SpanList& list, size_t byte_size);
// 从中心缓存获取一定数量的对象给thread cache
size_t FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t size);
private:
SpanList _spanLists[FreeListBucket];
private:
CentralCache()
{}
//禁掉拷贝
CentralCache(const CentralCache&) = delete;
//声名
static CentralCache _inst;
};
CentralCache.cpp中存在一个CentralCache类型的静态的成员变量,当程序运行起来后此对象被立马创建,此后程序中就只有这一个单例了。
CentralCache CentralCache::_inst;
看到这里你或许会有疑问?
span是什么呢,span在英文里是跨度的意思,span是一个管理以页为单位的大块内存,通常用于表示一段连续的内存块
span的结构如下:
//管理以页为单位的大块内存
struct Span
{
PAGE_ID _pageId = 0; //大块内存起始页的页号
size_t _n = 0; //页的数量
Span* _next = nullptr; //双链表结构
Span* _prev = nullptr;
size_t _useCount = 0; //切好的小块内存,被分配给thread cache的计数
void* _freeList = nullptr; //切好的小块内存的自由链表
};
对于span管理的以页为单位的大块内存,我们需要知道这块内存具体在哪一个位置,便于之后page cache进行前后页的合并,因此span结构当中会记录所管理大块内存起始页的页号 _pageId 。
至于每一个span管理的到底是多少个页,这并不是固定的,需要根据多方面的因素来控制,因此span结构当中有一个 _n成员,该成员就代表着该span管理的页的数量。
此外,每个span管理的大块内存,都会被切成相应大小的内存块挂到当前span的自由链表中,比如8Byte哈希桶中的span,会被切成一个个8Byte大小的内存块挂到当前span的自由链表中,因此span结构中需要存储切好的小块内存的自由链表 _freeList。
span结构当中的 _useCount成员记录的就是,当前span中切好的小块内存,被分配给thread cache的计数,当某个span的_useCount计数变为0时,代表当前span切出去的内存块对象全部还回来了,此时central cache就可以将这个span再还给page cache。
每个桶当中的span是以双链表的形式组织起来的,当我们需要将某个span归还给page cache时,就可以很方便的将该span从双链表结构中移出。如果用单链表结构的话就比较麻烦了,因为单链表在删除时,需要知道当前结点的前一个结点
_next、 _prev
在CentralCache结构中,其中每一个哈希桶里面存储的都是一个个span,而这些span用双链表链接起来,我们可以对此进行封装
SpanList结构
在此我们只简单地创建了一个双链表,并提供了两个基础的函数
//带头双向循环链表
class SpanList
{
public:
//初始化双向链表
SpanList()
{
//初始化头节点
_head = new Span;
_head->_next = _head;
_head->_prev = _head;
}
//头插
void Insert(Span* pos, Span* newSpan)
{
assert(pos);
assert(newSpan);
Span* prev = pos->_prev;
prev->_next = newSpan;
newSpan->_prev = prev;
newSpan->_next = pos;
pos->_prev = newSpan;
}
//头删
void Erase(Span* pos)
{
assert(pos);
Span* prev = pos->_prev;
Span* next = pos->_next;
prev->_next = next;
next->_prev = prev;
//不需要真正delete该pos处的span,可能需要还给pagecache
}
private:
Span* _head;
public:
std::mutex _mtx; //桶锁
};
关于页号的类型:PAGE_ID _pageId
每个程序运行起来后都有自己的地址空间,在32位平台下,进程地址空间的大小为2^32,而64位平台下,进程地址空间的大小为 2 ^64 页的大小一般是4K或者是8K,以8K为例,32位平台:进程地址空间就可以分成2^32 ÷2^13 = 2^ 19个页,在64位平台:进程地址空间被分成2^ 64÷2^13 = 2^51个页,页号本质和地址是一样的,都只是一个编号,只是地址以一个字节为一个单位,而页是以多个字节为一个单位
由于页号在64位平台下的取值范围是[0,2^51],我们需要用条件编译来解决这个问题
#ifdef _WIN64
typedef unsigned long long PAGE_ID;
#elif _WIN32
typedef size_t PAGE_ID;
#else
//linux
#endif
值得注意的是,在32位下,_WIN32有定义,_WIN64没有定义;而在64位下,_WIN32和_WIN64都有定义。因此在条件
二、运用慢开始反馈调节算法
当thread cache向central cache申请内存时,central cache应该给出多少个对象呢?这是一个值得思考的问题,如果central cache给的太少,那么thread cache在短时间内用完了又会来申请;但如果一次性给的太多了,可能thread cache用不完也就浪费了。
这里可以联想threadcache与centralcache结构来思考,虽然CentralCache拿span中自由链表里一个内存对象给ThreadCache就够用了,但是不保证下次还会来要
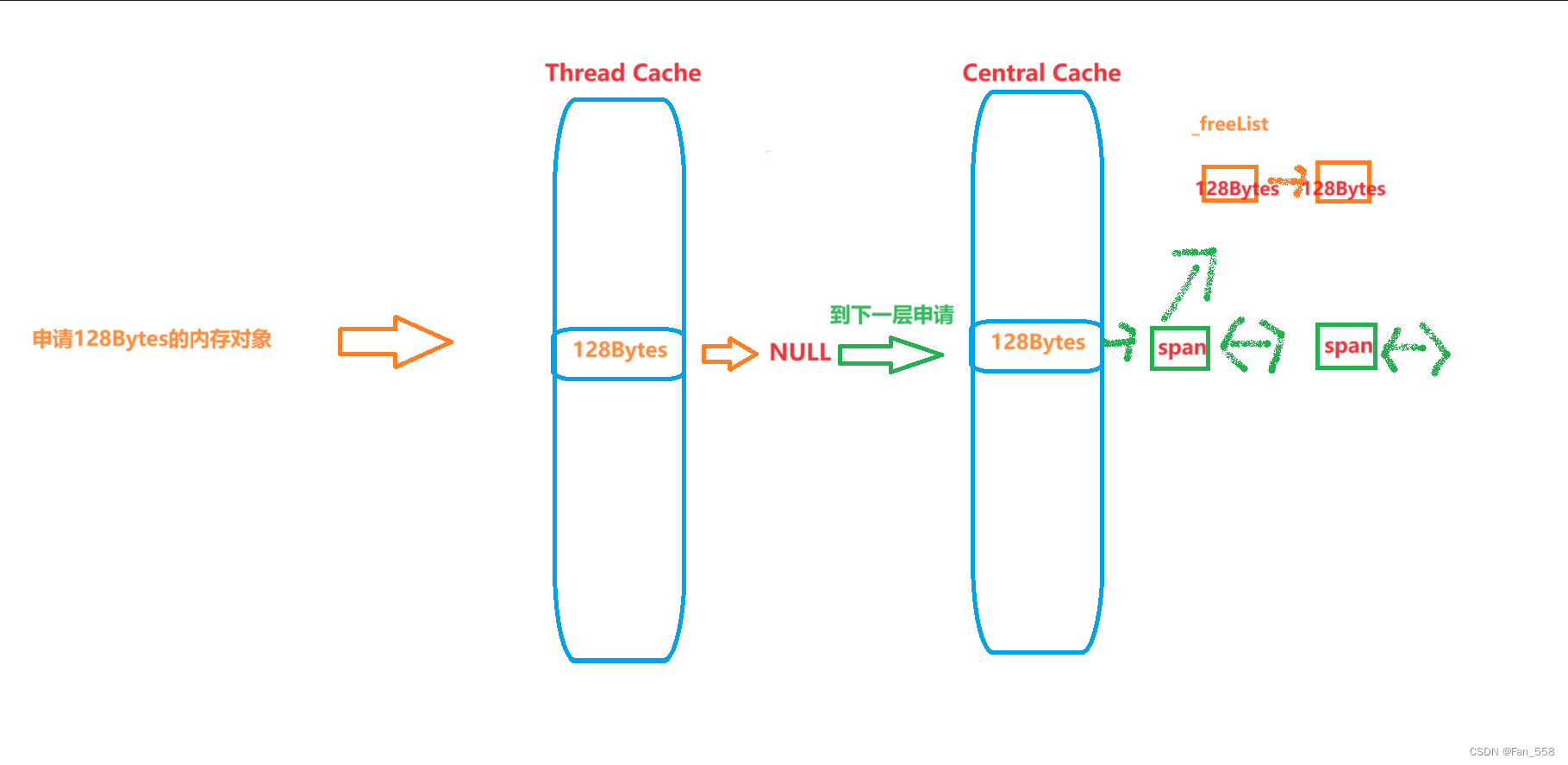
因此,我们这里采用了一个慢开始反馈调节算法。当thread cache向central cache申请内存时,如果申请的是较小的对象,那么可以多给一点,但如果申请的是较大的对象,就可以少给一点。
通过下面这个函数,我们就可以根据所需申请的对象的大小计算出具体给出的对象个数,并且可以将给出的对象个数控制到2~512个之间。也就是说,就算thread cache要申请的对象再小,我最多一次性给出512个对象;就算thread cache要申请的对象再大,我至少一次性给出2个对象。
class SizeClass
{
public:
//thread cache一次从central cache获取对象的上限
static size_t NumMoveSize(size_t size)
{
assert(size > 0);
//对象越小,计算出的上限越高
//对象越大,计算出的上限越低
size_t num = MAX_BYTES / size;
if (num < 2)
num = 2;
if (num > 512)
num = 512;
return num;
}
};
但就算申请的是小对象,一次性给出512个也是比较多的,基于这个原因,我们可以在FreeList结构中增加一个叫做_maxSize的成员变量,该变量的初始值设置为1,并且提供一个公有成员函数用于获取这个变量。也就是说,现在thread cache中的每个自由链表都会有一个自己的_maxSize。
class FreeList
{
public:
size_t& MaxSize()
{
return _maxSize;
}
private:
void* _freeList = nullptr; //指向自由链表的指针
size_t _maxSize = 1;
};
FetchFromCentralCache.cpp:
size_t batchNum = std::min(_freeLists[index].MaxSize(), SizeClass::NumMoveSize(size));
if (batchNum == _freeLists[index].MaxSize())
{
++_freeLists[index].MaxSize();
}
通过比较Max_Size和NumMoveSize返回的上限,取出二者之间的最小值,thread cache第一次向central cache申请某大小的对象时,申请到的都是一个,但下一次thread cache再向central cache申请同样大小的对象时,因为该自由链表中的_maxSize增加了,最终就会申请到两个。直到该自由链表中_maxSize的值,增长到超过NumMoveSize函数计算出的值后就不会继续增长了,此后申请到的对象个数就是NumMoveSize函数计算出的个数。
三、完成向CentralCache中心缓存申请
每次threadcache向centralcache申请对象时,先通过慢开始反馈调节算法计算出本次应该申请的对象的个数,然后再通过FetchRangeObj查看真实情况下centralcache对应桶中span的自由链表上有几个内存对象(actualNum),如果只有一个就直接返回。
//从中心存储中获取
void* ThreadCache::FetchFromCentralCache(size_t index, size_t size)
{
//慢开始反馈调节算法
//选出合适的对象申请数,慢开始
size_t batchNum = std::min(_freeLists[index].MaxSize(), SizeClass::NumMoveSize(size));
if (batchNum == _freeLists[index].MaxSize())
{
++_freeLists[index].MaxSize();
}
void* start = nullptr;
void* end = nullptr;
//实际能从CentralCache中获取到的对象数
size_t actualNum = CentralCache::GetInstance()->FetchRangeObj(start, end, batchNum, size);
//将从CentralCache中获取到的对象数给ThreadCache
assert(actualNum >= 1);
if (actualNum == 1)
{
assert(start == end);
return start;
}
//将第一个对象返回以外,还需要将剩下的对象挂到threadcache对应的哈希桶中
else
{
_freeLists[index].PushRange(FreeList::NextObj(start), end, size);
return start;
}
}
如果申请到多个对象,除了将第一个对象返回以外,还需要将剩下的对象挂到threadcache对应的哈希桶中。根据需求,我们需要向封装的自由链表继续添加一个函数PushRange将多内存对象链接到对应的桶中
//将自由链表链接到ThreadCache的桶中
void PushRange(void* start, void* end, size_t n)
{
NextObj(end) = _freeList;
_freeList = start;
}
FetchRangeObj函数将central cache对应的哈希桶中span里freeList链接的内存对象数量返回
//从中心缓存中申请
size_t CentralCache::FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t size)
{
//根据对齐规则选择从哪一个桶拿(threadcache与centralcache的对齐规则相同)
size_t index = AlignmentRules::Index(size);
//加桶锁(由于centralcache只有一个,threadcache向centralcache申请内存时可能
面临着多个线程向centralcache同一个桶申请)
_spanLists[index]._mtx.lock();
Span* span = CentralCache::GetoneSpan(_spanLists[index], size);
assert(span); //保证span不为空
assert(span->_freeList); //保证span对象中自由链表_freeList不为空
start = span->_freeList;
end = start;
//返回actual个对象,有多少返回多少
size_t actualNum = 1;
size_t i = 0;
while (i < batchNum - 1 && FreeList::NextObj(end) != nullptr)
{
end = FreeList::NextObj(end);
i++;
actualNum++;
}
//将分配剩余的对象重新挂在span中
span->_freeList = *(void**)end;
*(void**)end = nullptr;
//为释放流程作准备
span->_useCount += actualNum;
_spanLists[index]._mtx.unlock();
return actualNum;
}
值得注意的是,我们实际申请到的内存对象数可能是比通过慢开始反馈调节算法计算出的batchNum要少的,但这不会产生什么影响,有多少拿多少,thread
cache的本意就是向central cache申请一个对象,之所以一次要申请多个内存对象,是因为这样的话下一次直接可以在threadcache中获取了
四、承上启下
在FetchRangeObj函数中调用了GetoneSpan函数,GetoneSpan函数用来获取一个非空的span,一开始会先遍历span的链表结构,如果span不为空就返回一个span给FetchRangeObj函数,如果为空就要向下一层进行申请PageCache
Span* CentralCache::GetoneSpan(SpanList& list, size_t byte_size)
{
//从list中取出一个非空的span,遍历
Span* it = list.Begin();
while (it != list.End())
{
//存在非空的span就返回
if (it->_freeList != nullptr)
{
return it;
}
else it = it->_next;
}
...本函数还有一些步骤,以下就是向PageCache页缓存中申请,且听下回分解
}
小结
今日的项目分享就到这里啦,迄今为止也已经介绍了ThreadCache与CentralCache,大家一定一定要把结构给理解好,欲知PageCache,且听下回分解