1、Style Aligned Image Generation via Shared Attention
中文标题:共享注意力下的风格对齐图像生成


简介:大规模文本到图像(T2I)模型在创意领域迅速崭露头角,可以从文本提示中生成视觉上引人入胜的输出。然而,控制这些模型以确保一致的风格仍然具有挑战性,现有方法需要微调和手动干预以区分内容和风格。在本文中,我们介绍了StyleAligned,一种旨在在一系列生成的图像之间建立样式对齐的新技术。通过在扩散过程中采用最小的“注意共享”,我们的方法在T2I模型中保持图像之间的样式一致性。这种方法允许通过简单的反演操作使用参考样式创建样式一致的图像。我们的方法在不同的样式和文本提示中的评估表明,它具有高质量的综合和保真度,强调了它在实现各种输入的一致风格方面的功效。
2、GIVT: Generative Infinite-Vocabulary Transformers
中文标题:GIVT: 生成无限词汇量的变换器


简介:我们介绍了生成无限词汇变换器(GIVT),它们生成具有实值条目的向量序列,而不是来自有限词汇的离散标记。为了实现这一点,我们对仅解码器变换器进行了两个简单但令人惊讶的修改:1)在输入端,我们用输入向量的线性投影替换了有限词汇查找表;2)在输出端,我们用多元高斯混合模型的参数替换了对数预测(通常映射到分类分布)。受到VQ-GAN和MaskGIT的图像生成范例的启发,其中变换器用于模拟VQ-VAE的离散潜在序列,我们使用GIVT来模拟VAE的未量化实值潜在序列。当将GIVT应用于迭代掩蔽建模的类条件图像生成时,我们展示了与MaskGIT相竞争的结果,而在使用它进行因果建模时,我们的方法优于VQ-GAN和MaskGIT。最后,我们将我们的方法应用于基于VAE的UViM框架的全景分割和深度估计时,获得了具有竞争力的结果。
3、MagicLens: Self-Supervised Image Retrieval with Open-Ended Instructions
中文标题:MagicLens: 自监督图像检索与开放式指导

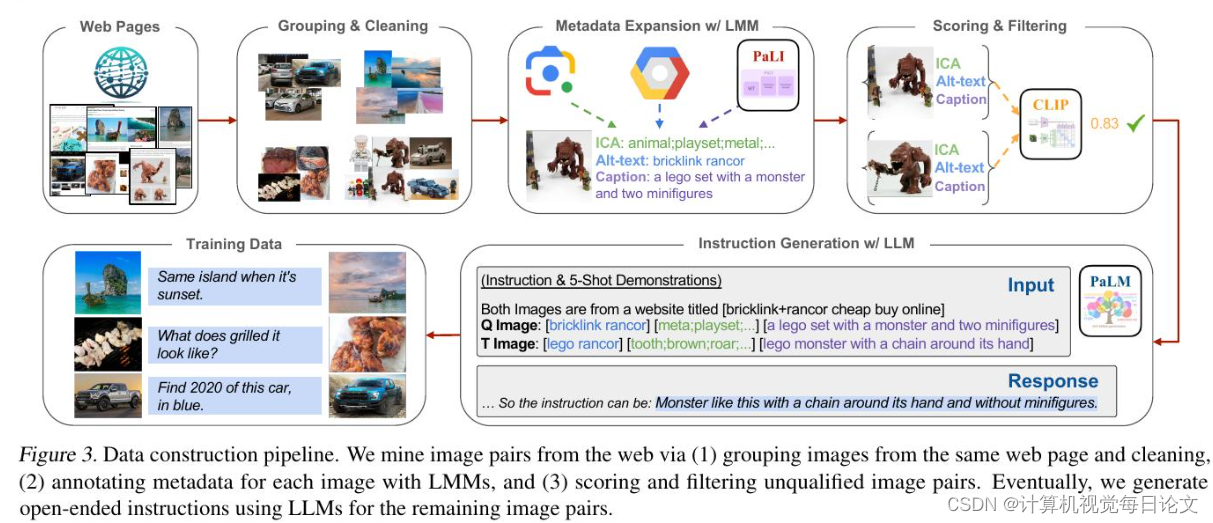
简介:本文的主要观点是,通过文本指令,图像检索可以展现出比视觉相似性更丰富的关联。为了验证这一点,我们介绍了MagicLens,这是一种支持开放式指令的自监督图像检索模型。MagicLens的构建基于一个全新的关键见解:同一网页上自然出现的图像对包含各种隐含关系(例如内部视图),我们可以通过合成指令来明确这些隐含关系,从而利用大型多模态模型(LMMs)和大型语言模型(LLMs)。经过对从网络中挖掘的具有丰富语义关系的36.7M个(查询图像,指令,目标图像)三元组进行训练后,MagicLens在八项不同的图像检索任务的基准测试中取得了与之前最先进方法相当或更好的结果。值得注意的是,它在多个基准测试中的表现优于之前最先进的方法,但模型大小却减小了50倍。对一个包含1.4M张图像的未曾见过的语料库进行的额外人类分析进一步展示了MagicLens所支持的搜索意图的多样性。



![[Python GUI PyQt] PyQt5快速入门](https://img-blog.csdnimg.cn/direct/dfab37ca62e24f6ea4a0eb9dde8626c6.png#pic_center)