摘要
本文使用GCNet注意力改进YoloV8,在YoloV8的Neck中加入GCNet实现涨点。改进方法简单易用,欢迎大家使用!
论文:《GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond》
非局部网络(NLNet)通过为每个查询位置聚合特定于查询的全局上下文,为捕获长距离依赖关系提供了一个开创性的方法。然而,经过严格的实证分析,我们发现非局部网络所建模的全局上下文在图像中的不同查询位置几乎相同。在本文中,我们利用这一发现,创建了一个基于查询独立公式的简化网络,该网络保持了NLNet的准确性,但计算量大大减少。我们还观察到,这种简化的设计与压缩-激励网络(SENet)具有相似的结构。因此,我们将它们统一成一个用于全局上下文建模的三步通用框架。在通用框架内,我们设计了一个更好的实例化,称为全局上下文(GC)块,它轻量级且可以有效地建模全局上下文。轻量级的特性使我们能够将其应用于骨干网络中的多个层,以构建全局上下文网络(GCNet),该网络在各种识别任务的主要基准测试中通常优于简化的NLNet和SENet。代码和配置已发布在https://github.com/xvjiarui/GCNet。
1、简介
捕捉长距离依赖关系,旨在提取对视觉场景的全局理解,已被证明对广泛的识别任务有益,如图像/视频分类、目标检测和分割[31, 12, 38, 14]。在卷积神经网络中,由于卷积层在局部邻域内构建像素关系,长距离依赖关系主要通过深层堆叠卷积层来建模。然而,直接重复卷积层计算效率低下且难以优化[31]。这会导致长距离依赖关系建模不够有效,部分原因在于远距离位置之间信息传递的困难。
为了解决这个问题,提出了非局部网络[31],通过自注意力机制[28]使用一层来建模长距离依赖关系。对于每个查询位置,非局部网络首先计算查询位置与所有位置之间的成对关系以形成注意力图,然后使用由注意力图定义的权重对所有位置的特征进行加权求和。最后,将聚合的特征添加到每个查询位置的特征上,形成输出。

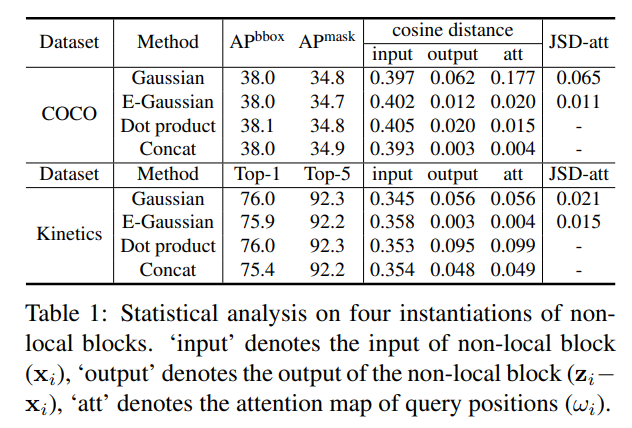
非局部网络中查询特定的注意力权重通常暗示了对应位置对查询位置的重要性。虽然可视化查询特定的重要性权重有助于深入理解,但原始论文中此类分析在很大程度上缺失。我们弥补了这一遗憾,如图1所示,但令人惊讶的是,我们发现不同查询位置的注意力图几乎相同,表明只学习了与查询无关的依赖关系。这一观察结果在表1的统计分析中进一步得到验证,即不同查询位置注意力图之间的距离非常小。
基于这一观察结果,我们简化了非局部块,明确地为所有查询位置使用一个与查询无关的注意力图。然后,我们使用这个注意力图将相同的聚合特征添加到所有查询位置的特征上,形成输出。这个简化后的块比原始的非局部块具有显著更小的计算成本,但在几个重要的视觉识别任务上几乎没有观察到准确率的下降。此外,我们还发现这个简化后的块与流行的压缩-激励(SE)网络[14]具有相似的结构。它们都通过从所有位置聚合的相同特征来加强原始特征,但在聚合策略、变换和增强函数的选择上有所不同。通过抽象这些函数,我们得出了一个将简化后的NL块和SE块统一起来的三步通用框架:(a)一个上下文建模模块,它将所有位置的特征聚合在一起以形成全局上下文特征;(b)一个特征变换模块,用于捕获通道间的相互依赖性;(c)一个融合模块,用于将全局上下文特征合并到所有位置的特征中。
简化的NL块和SE块是这个通用框架的两种实例化,但在三个步骤的实现上有所不同。通过对每一步的比较研究,我们发现简化的非局部块和SE块都不是最优的,每个块在部分步骤上优于另一个。通过结合每一步的最优实现,我们得到了通用框架的一个新实例化,称为全局上下文(GC)块。新块在上下文建模(使用全局注意力池化)和融合(使用加法)步骤上与简化的NL块共享相同的实现,而与SE块共享相同的转换步骤(使用两层瓶颈)。GC块在多个视觉识别任务上的性能优于简化的非局部块和SE块。
与SE块一样,提出的GC块也很轻量,因此可以应用于ResNet架构中的所有残差块,而原始的非局部块由于计算量大,通常只应用在一层或几层之后。使用GC块增强的网络被称为全局上下文网络(GCNet)。在COCO目标检测/分割任务上,GCNet在 A P box AP^{\text {box}} APbox上分别比NLNet和SENet高出 1.9 % 1.9\% 1.9%和 1.7 % 1.7\% 1.7%,在 A P mask AP^{\text {mask}} APmask上分别高出 1.5 % 1.5\% 1.5%和 1.5 % 1.5\% 1.5%,而浮点运算量(FLOPs)仅相对增加了 0.07 % 0.07\% 0.07%。此外,GCNet在三个一般的视觉识别任务上取得了显著的性能提升:在COCO上进行的目标检测/分割(与以FPN和ResNet-50为骨干网络的Mask R-CNN相比, A P bbox AP^{\text {bbox}} APbbox提高了 2.7 % 2.7\% 2.7%, A P mask AP^{\text {mask}} APmask提高了 2.4 % 2.4\% 2.4%),在ImageNet上的图像分类(与ResNet-50相比,top-1准确率提高了 0.8 % 0.8\% 0.8%),以及在Kinetics上的动作识别(与ResNet-50 Slow-only基线相比,top-1准确率提高了 1.1 % 1.1\% 1.1%),而计算成本仅增加了不到 0.26 % 0.26\% 0.26%。
2、相关工作
深度架构。随着卷积网络在大规模视觉识别任务中取得巨大成功,为了提高原始架构的精度,已经进行了许多尝试[18,26,27,10,37,15,34,14,43,13,40,11,4,42,19,2,24,31,35,6]。网络设计的一个重要方向是改进基本组件的功能公式,以提升深度网络的性能。ResNeXt[34]和Xception[3]采用分组卷积来增加基数。可变形卷积网络(Deformable ConvNets)[4, 42]设计了可变形卷积以增强几何建模能力。挤压激励网络(Squeeze-Excitation Networks,SE-Net)[14]采用通道缩放来显式建模通道依赖关系。
我们的全局上下文网络是一种新的骨干架构,具有新颖的全局上下文(GC)块,能够实现更有效的全局上下文建模,在物体检测、实例分割、图像分类和动作识别等广泛的视觉任务上提供优越的性能。
长距离依赖建模。最近的长距离依赖建模方法可以分为两类。第一类是采用自注意力机制来建模成对关系。第二类是建模与查询无关的全局上下文。
自注意力机制最近已成功应用于各种任务,如机器翻译[7, 8, 28]、图嵌入[29]、生成建模[39]和视觉识别[30, 12, 31, 36]。[28]是首次尝试将自注意力机制应用于机器翻译中的长距离依赖建模的尝试之一。[12]将自注意力机制扩展到对象检测中,以建模对象之间的关系。NLNet[31]采用自注意力机制来建模像素级的成对关系。CCNet[16]通过堆叠两个交叉块加速NLNet,并应用于语义分割。然而,NLNet实际上为每个查询位置学习查询无关的注意力图,这对于建模像素级的成对关系来说是一种计算成本的浪费。
为了建模全局上下文特征,SENet[14]、GENet[13]和PSANet[41]通过重新缩放不同通道来校准具有全局上下文的通道依赖性。CBAM[32]通过重新缩放同时校准不同空间位置和通道的重要性。然而,这些方法都采用重新缩放来进行特征融合,这对于全局上下文建模来说不够有效。
提出的GCNet可以有效地通过加法融合来建模全局上下文,就像NLNet[31]一样(NLNet虽然功能强大但难以集成到多层网络中),同时拥有像SENet[14](虽然采用缩放但对于全局上下文建模不够有效)一样的轻量级特性。因此,通过更有效的全局上下文建模,GCNet在各种识别任务的主要基准测试中均优于NLNet和SENet。
3、非局部网络的分析
在本节中,我们首先回顾非局部块[31]的设计。为了直观理解其工作原理,我们可视化了一个广泛使用的非局部块实例化在不同查询位置生成的注意力图。为了从统计上分析其行为,我们计算了所有查询位置的注意力图之间的平均距离(余弦距离和Jensen-Shannon散度)。

3.1、重访非局部块
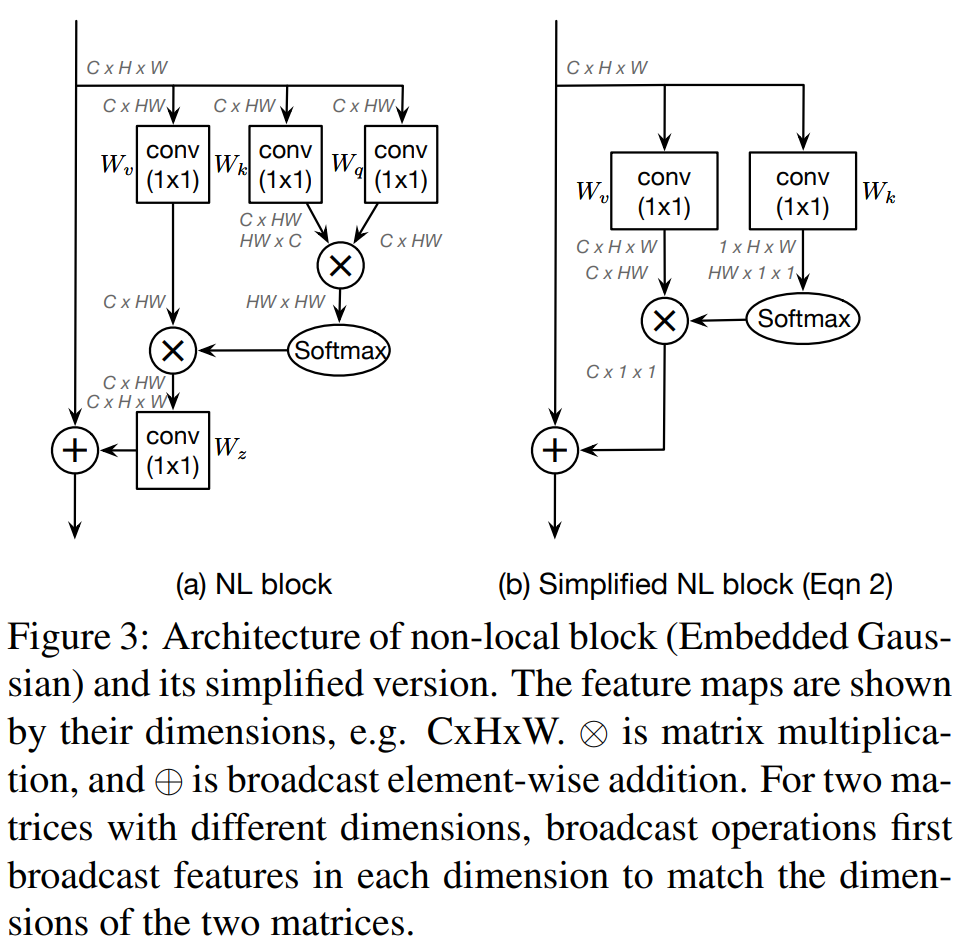
基本的非局部块[31]旨在通过从其他位置聚合信息来增强查询位置的特征。我们将输入实例(例如图像或视频)的特征图表示为 x = { x i } i = 1 N p \mathbf{x}=\left\{\mathbf{x}_{i}\right\}_{i=1}^{N_{p}} x={xi}i=1Np,其中 N p N_{p} Np是特征图中的位置数量(例如,对于图像, N p = H ⋅ W N_{p}=\mathrm{H} \cdot \mathrm{W} Np=H⋅W;对于视频, N p = H ⋅ W ⋅ T N_{p}=\mathrm{H} \cdot \mathrm{W} \cdot \mathrm{T} Np=H⋅W⋅T)。 x \mathbf{x} x和 z \mathbf{z} z分别表示非局部块的输入和输出,它们具有相同的维度。非局部块可以表达为:
z i = x i + W z ∑ j = 1 N p f ( x i , x j ) C ( x ) ( W v ⋅ x j ) \mathbf{z}_{i}=\mathbf{x}_{i}+W_{z} \sum_{j=1}^{N_{p}} \frac{f\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right)}{\mathcal{C}(\mathbf{x})}\left(W_{v} \cdot \mathbf{x}_{j}\right) zi=xi+Wz∑j=1NpC(x)f(xi,xj)(Wv⋅xj)
其中 i i i是查询位置的索引, j j j枚举了所有可能的位置。 f ( x i , x j ) f\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right) f(xi,xj)表示位置 i i i和 j j j之间的关系,并且具有一个归一化因子 C ( x ) \mathcal{C}(\mathbf{x}) C(x)。 W z W_{z} Wz和 W v W_{v} Wv表示线性变换矩阵(例如 1 × 1 1 \times 1 1×1卷积)。为了简化表示,我们将 ω i j = f ( x i , x j ) C ( x ) \omega_{i j}=\frac{f\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right)}{\mathcal{C}(\mathbf{x})} ωij=C(x)f(xi,xj)表示为位置 i i i和 j j j之间的归一化成对关系。
为了满足实际应用中的各种需求,非局部块设计了四种不同的
ω
i
j
\omega_{i j}
ωij实例化,分别是高斯、嵌入高斯、点积和拼接:(a) 高斯表示
ω
i
j
\omega_{i j}
ωij中的
f
f
f是高斯函数,定义为
ω
i
j
=
exp
(
⟨
x
i
,
x
j
⟩
)
∑
m
exp
(
⟨
x
i
,
x
m
⟩
)
\omega_{i j}=\frac{\exp \left(\left\langle\mathbf{x}_{i}, \mathbf{x}_{j}\right\rangle\right)}{\sum_{m} \exp \left(\left\langle\mathbf{x}_{i}, \mathbf{x}_{m}\right\rangle\right)}
ωij=∑mexp(⟨xi,xm⟩)exp(⟨xi,xj⟩);(b) 嵌入高斯是高斯的一个简单扩展,它在嵌入空间中计算相似性,定义为
ω
i
j
=
exp
(
⟨
W
q
x
i
,
W
k
x
j
⟩
)
∑
m
exp
(
⟨
W
q
x
i
,
W
k
x
m
⟩
)
\omega_{i j}=\frac{\exp \left(\left\langle W_{q} \mathbf{x}_{i}, W_{k} \mathbf{x}_{j}\right\rangle\right)}{\sum_{m} \exp \left(\left\langle W_{q} \mathbf{x}_{i}, W_{k} \mathbf{x}_{m}\right\rangle\right)}
ωij=∑mexp(⟨Wqxi,Wkxm⟩)exp(⟨Wqxi,Wkxj⟩);© 对于点积,
ω
i
j
\omega_{i j}
ωij中的
f
f
f定义为点积相似度,形式为
ω
i
j
=
⟨
W
q
x
i
,
W
k
x
j
⟩
N
p
\omega_{i j}=\frac{\left\langle W_{q} \mathbf{x}_{i}, W_{k} \mathbf{x}_{j}\right\rangle}{N_{p}}
ωij=Np⟨Wqxi,Wkxj⟩;(d) 拼接的定义很直观,即
ω
i
j
=
ReLU
(
W
q
[
x
i
,
x
j
]
)
N
p
\omega_{i j}=\frac{\operatorname{ReLU}\left(W_{q}\left[\mathbf{x}_{i}, \mathbf{x}_{j}\right]\right)}{N_{p}}
ωij=NpReLU(Wq[xi,xj])。最广泛使用的实例化是嵌入高斯,如图3(a)所示。
非局部块可以视为一个全局上下文建模块,它通过查询特定的注意力图(通过查询特定的权重平均从所有位置得出)将查询特定的全局上下文特征聚合到每个查询位置。由于为每个查询位置计算注意力图,非局部块的时间和空间复杂度都与位置数 N p N_{p} Np的平方成正比。
3.2、分析
可视化 为了直观地理解非局部块的行为,我们首先可视化不同查询位置的注意力图。由于不同的实例化可以实现相当的性能[31],这里我们只可视化最广泛使用的版本,即嵌入高斯,它与[28]中提出的块具有相同的公式。由于视频中的注意力图难以可视化和理解,我们仅在以图像为输入的目标检测/分割任务上进行可视化。遵循非局部网络在目标检测中的标准设置[31],我们在带有FPN和Res50的Mask R-CNN上进行实验,仅在res_{4}的最后一个残差块之前添加一个非局部块。
在图2中,我们随机选择了COCO数据集中的六张图像,并为每张图像可视化三个不同的查询位置(红点)及其查询特定的注意力图(热图)。我们惊讶地发现,对于不同的查询位置,它们的注意力图几乎相同。为了从统计上验证这一观察结果,我们分析了不同查询位置全局上下文之间的距离。
统计分析 我们将位置i的特征向量表示为 v i \mathbf{v}_{i} vi。平均距离度量定义为avg_dist = 1 N p 2 ∑ i = 1 N p ∑ j = 1 N p dist ( v i , v j ) =\frac{1}{N_{p}^{2}} \sum_{i=1}^{N_{p}} \sum_{j=1}^{N_{p}} \operatorname{dist}\left(\mathbf{v}_{i}, \mathbf{v}_{j}\right) =Np21∑i=1Np∑j=1Npdist(vi,vj),其中 dist ( ⋅ , ⋅ ) \operatorname{dist}(\cdot, \cdot) dist(⋅,⋅)是两个向量之间的距离函数。
余弦距离是一种广泛使用的距离度量方式,定义为 dist ( v i , v j ) = ( 1 − cos ( v i , v j ) ) / 2 \operatorname{dist}\left(\mathbf{v}_{i}, \mathbf{v}_{j}\right)=\left(1-\cos \left(\mathbf{v}_{i}, \mathbf{v}_{j}\right)\right) / 2 dist(vi,vj)=(1−cos(vi,vj))/2。在这里,我们计算三种向量之间的余弦距离,分别是非局部块的输入( v i = x i \mathbf{v}_{i}=\mathbf{x}_{i} vi=xi,在表1中标记为’input’)、非局部块融合之前的输出( v i = z i − x i \mathbf{v}_{i}=\mathbf{z}_{i}-\mathbf{x}_{i} vi=zi−xi,在表1中标记为’output’)以及查询位置的注意力图( v i = ω i \mathbf{v}_{i}=\omega_{i} vi=ωi,在表1中标记为’att’)。
詹森-香农散度(JSD)用于测量两个概率分布之间的统计距离,其定义为 dist ( v i , v j ) = 1 2 ∑ k = 1 N p ( v i k log 2 v i k v i k + v j k + v j k log 2 v j k v i k + v j k ) \operatorname{dist}\left(\mathbf{v}_{i}, \mathbf{v}_{j}\right)=\frac{1}{2} \sum_{k=1}^{N_{p}}\left(v_{i k} \log \frac{2 v_{i k}}{v_{i k}+v_{j k}}+v_{j k} \log \frac{2 v_{j k}}{v_{i k}+v_{j k}}\right) dist(vi,vj)=21∑k=1Np(viklogvik+vjk2vik+vjklogvik+vjk2vjk)。由于每个注意力图 ω i \omega_{i} ωi的和为1(在高斯和嵌入高斯中),我们可以将每个 ω i \omega_{i} ωi视为离散概率分布。因此,我们计算高斯和嵌入高斯注意力图( v i = ω i \mathbf{v}_{i}=\omega_{i} vi=ωi)之间的JSD。
表1中展示了在两个标准任务上使用两种距离度量的结果。首先,“input”列中的余弦距离值较大,表明非局部块的输入特征在不同位置之间是可以区分的。然而,“output”列中的余弦距离值非常小,表明非局部块建模的全局上下文特征对于不同的查询位置几乎是相同的。所有实例化在注意力图(“att”)上的两种距离度量也都非常小,这再次验证了从可视化中得到的观察结果。换句话说,尽管非局部块旨在计算每个查询位置特定的全局上下文,但训练后的全局上下文实际上与查询位置无关。因此,无需为每个查询位置计算查询特定的全局上下文,这使我们能够简化非局部块。
4、方法
4.1、简化非局部块
鉴于表1中不同实例化在COCO和Kinetics上均实现了可比的性能,我们采用使用最广泛的版本——嵌入高斯(Embedded Gaussian)作为基本的非局部块。基于观察到的不同查询位置的注意力图几乎相同的现象,我们简化非局部块,通过计算一个全局(与查询无关的)注意力图,并让所有查询位置共享这个全局注意力图。根据[12]中的结果,带有和不带有 W z W_{z} Wz的变体实现了可比的性能,因此我们在简化版本中省略了 W z W_{z} Wz。我们简化的非局部块定义为:
z i = x i + ∑ j = 1 N p exp ( W k x j ) ∑ m = 1 N p exp ( W k x m ) ( W v ⋅ x j ) \mathbf{z}_{i}=\mathbf{x}_{i}+\sum_{j=1}^{N_{p}} \frac{\exp \left(W_{k} \mathbf{x}_{j}\right)}{\sum_{m=1}^{N_{p}} \exp \left(W_{k} \mathbf{x}_{m}\right)}\left(W_{v} \cdot \mathbf{x}_{j}\right) zi=xi+j=1∑Np∑m=1Npexp(Wkxm)exp(Wkxj)(Wv⋅xj)
其中
W
k
W_{k}
Wk和
W
v
W_{v}
Wv表示线性变换矩阵。简化后的非局部块如图3(b)所示。
为了进一步降低这个简化块的计算成本,我们应用分配律将 W v W_{v} Wv移到注意力池化(attention pooling)之外,得到:
z i = x i + W v ∑ j = 1 N p exp ( W k x j ) ∑ m = 1 N p exp ( W k x m ) x j \mathbf{z}_{i}=\mathbf{x}_{i}+W_{v} \sum_{j=1}^{N_{p}} \frac{\exp \left(W_{k} \mathbf{x}_{j}\right)}{\sum_{m=1}^{N_{p}} \exp \left(W_{k} \mathbf{x}_{m}\right)} \mathbf{x}_{j} zi=xi+Wvj=1∑Np∑m=1Npexp(Wkxm)exp(Wkxj)xj
简化后的非局部块的这个版本如图4(b)所示。 1 × 1 1 \times 1 1×1卷积 W v W_{v} Wv的浮点运算量(FLOPs)从 O ( H W C 2 ) \mathcal{O}\left(\mathrm{HWC}^{2}\right) O(HWC2)减少到 O ( C 2 ) \mathcal{O}\left(\mathrm{C}^{2}\right) O(C2)。
与传统非局部块不同,式3中的第二项与查询位置
i
i
i无关,这意味着这一项在所有查询位置
i
i
i之间是共享的。因此,我们直接将所有位置的特征进行加权平均来建模全局上下文,并将全局上下文特征聚合(添加)到每个查询位置的特征上。在实验中,我们直接用简化的非局部(SNL)块替换非局部(NL)块,并在三个任务上评估了准确性和计算成本,包括COCO上的目标检测、ImageNet上的图像分类以及动作识别,如表2(a)、表4(a)和表5所示。正如我们所预期的那样,SNL块在显著降低浮点运算量(FLOPs)的同时,实现了与非局部块相当的性能。
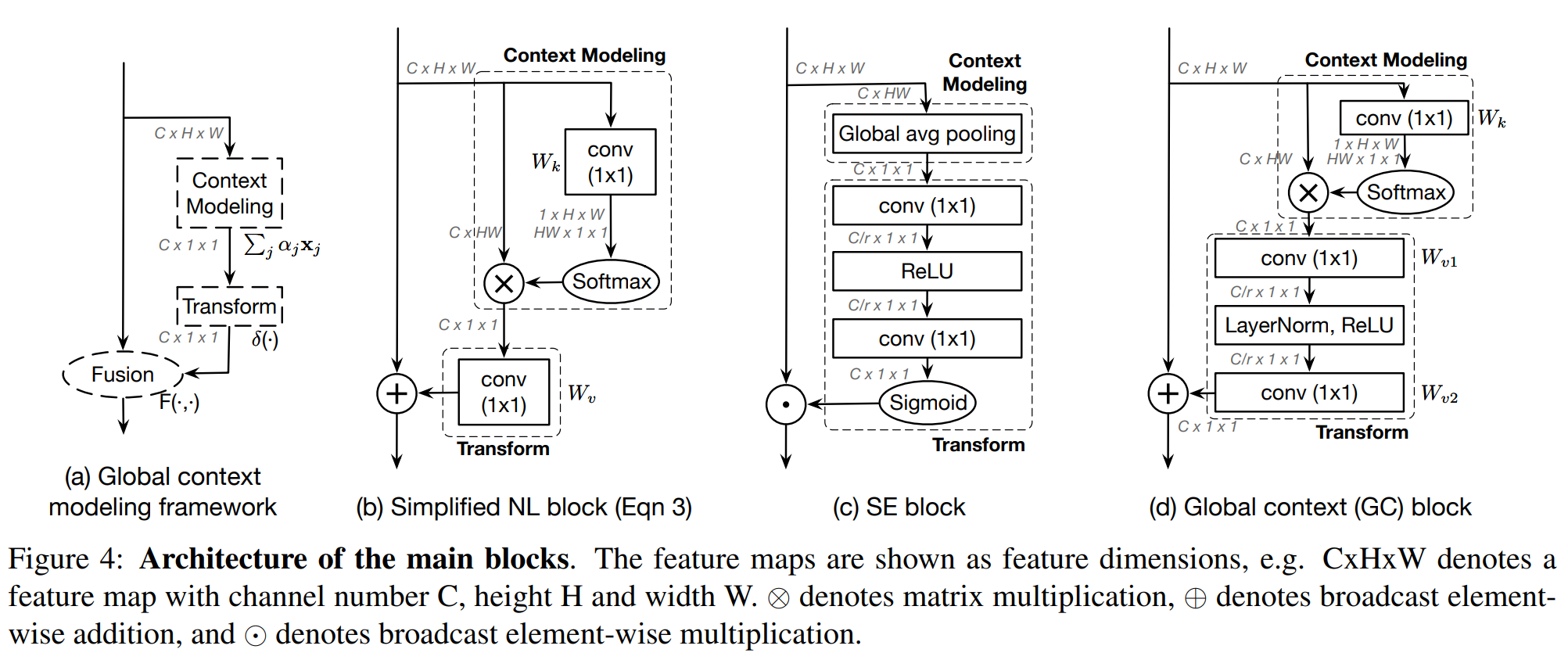
4.2、全局上下文建模框架
如图4(b)所示,简化的非局部块可以抽象为三个步骤:(a)全局注意力池化,它采用一个 1 × 1 1 \times 1 1×1卷积 W k W_{k} Wk和softmax函数来获取注意力权重,然后执行注意力池化以获取全局上下文特征;(b)通过 1 × 1 1 \times 1 1×1卷积 W v W_{v} Wv进行特征变换;©特征聚合,采用加法将全局上下文特征聚合到每个位置的特征上。
我们将这一抽象视为全局上下文建模框架,如图4(a)所示,并定义为:
z i = F ( x i , δ ( ∑ j = 1 N p α j x j ) ) \mathbf{z}_{i}=F\left(\mathbf{x}_{i}, \delta\left(\sum_{j=1}^{N_{p}} \alpha_{j} \mathbf{x}_{j}\right)\right) zi=F xi,δ j=1∑Npαjxj
其中,(a) ∑ j α j x j \sum_{j} \alpha_{j} \mathbf{x}_{j} ∑jαjxj 表示上下文建模模块,它通过加权平均将所有位置的特征组合起来,权重为 α j \alpha_{j} αj,以获取全局上下文特征(在简化的非局部(SNL)块中的全局注意力池化);(b) δ ( ⋅ ) \delta(\cdot) δ(⋅) 表示特征变换,用于捕获通道间的依赖关系(在SNL块中的 1 × 1 1 \times 1 1×1卷积);© F ( ⋅ , ⋅ ) F(\cdot, \cdot) F(⋅,⋅) 表示融合函数,用于将全局上下文特征聚合到每个位置的特征上(在SNL块中的广播逐元素加法)。
有趣的是,在[14]中提出的压缩-激励(SE)块也是我们所提出框架的一个实例化。如图4©所示,它包含:(a)全局平均池化用于全局上下文建模(在式4中设置 α j = 1 N p \alpha_{j}=\frac{1}{N_{p}} αj=Np1),在SE块中称为压缩操作;(b)瓶颈变换模块(令式4中的 δ ( ⋅ ) \delta(\cdot) δ(⋅)为依次进行的 1 × 1 1 \times 1 1×1卷积、ReLU、 1 × 1 1 \times 1 1×1卷积和sigmoid函数),用于计算每个通道的重要性,在SE块中称为激励操作;©融合用的重缩放函数(令式4中的 F ( ⋅ , ⋅ ) F(\cdot, \cdot) F(⋅,⋅)为逐元素乘法),用于重新校准通道特征。与非局部块不同,SE块非常轻量,允许其应用于所有层,而计算成本仅略有增加。
4.3、全局上下文块
在这里,我们提出了全局上下文建模框架的一个新实例化,称为全局上下文(GC)块。它兼具简化非局部(SNL)块在远程依赖上的有效建模能力和压缩-激励(SE)块的轻量级计算优势。
在如图4(b)所示的简化非局部块中,变换模块具有最多的参数,包括一个具有C×C参数的 1 × 1 1 \times 1 1×1卷积。当我们将这个SNL块添加到更高层时,例如res_{5},这个 1 × 1 1 \times 1 1×1卷积的参数数量,即C×C=2048×2048,将主导该块的参数数量。为了获得SE块的轻量级特性,这个 1 × 1 1 \times 1 1×1卷积被瓶颈变换模块替代,从而显著减少参数数量,从C×C减少到2×C×C/r,其中r是瓶颈比率,C/r表示瓶颈的隐藏表示维度。当默认缩减比率设为r=16时,变换模块的参数数量可以减少到原始SNL块的1/8。不同瓶颈比率r值的更多结果如表2(e)所示。
由于两层瓶颈变换增加了优化的难度,我们在瓶颈变换内部(ReLU之前)添加了层归一化,以简化优化,同时也作为一个可以提高泛化能力的正则化器。如表2(d)所示,层归一化可以显著提高COCO上的目标检测和实例分割性能。
全局上下文(GC)块的详细架构如图4(d)所示,其公式为:
z i = x i + W v 2 ReLU ( LN ( W v 1 ∑ j = 1 N p e W k x j ∑ m = 1 N p e W k x m x j ) ) , \mathbf{z}_{i}=\mathbf{x}_{i}+W_{v 2} \operatorname{ReLU}\left(\operatorname{LN}\left(W_{v 1} \sum_{j=1}^{N_{p}} \frac{e^{W_{k} \mathbf{x}_{j}}}{\sum_{m=1}^{N_{p}} e^{W_{k} \mathbf{x}_{m}}} \mathbf{x}_{j}\right)\right), zi=xi+Wv2ReLU LN Wv1j=1∑Np∑m=1NpeWkxmeWkxjxj ,
其中, α j = e W k x j ∑ m e W k x m \alpha_{j}=\frac{e^{W_{k} \mathbf{x}_{j}}}{\sum_{m} e^{W_{k} \mathbf{x}_{m}}} αj=∑meWkxmeWkxj 是全局注意力池化的权重,而 δ ( ⋅ ) = W v 2 ReLU ( LN ( W v 1 ( ⋅ ) ) ) \delta(\cdot)=W_{v 2} \operatorname{ReLU}\left(\operatorname{LN}\left(W_{v 1}(\cdot)\right)\right) δ(⋅)=Wv2ReLU(LN(Wv1(⋅))) 表示瓶颈变换。具体来说,我们的GC块包括:(a) 用于上下文建模的全局注意力池化;(b) 用于捕获通道间依赖性的瓶颈变换;以及 © 用于特征融合的广播逐元素加法。
由于GC块是轻量级的,因此可以将其应用于多个层中,以更好地捕获远程依赖关系,同时仅增加少量的计算成本。以用于ImageNet分类的ResNet-50为例,GC-ResNet-50表示在ResNet-50的所有层(c3+c4+c5)上添加GC块,且瓶颈比率为16。GC-ResNet-50将ResNet-50的计算量从约3.86 GFLOPs增加到约3.87 GFLOPs,相对增加了0.26%。此外,GC-ResNet-50在ResNet-50所需的约25.56M参数的基础上增加了约2.52M参数,即增加了约9.86%。
全局上下文可以广泛受益于各种视觉识别任务,GC块的灵活性使其能够插入到用于各种计算机视觉问题的网络架构中。在本文中,我们将GC块应用于三个一般视觉任务——图像识别、目标检测/分割和动作识别,并在所有三个任务中都观察到了显著的改进。
与非局部块(Non-local block)的关系:由于非局部块实际上学习的是与查询无关的全局上下文,我们的全局上下文块(GC block)中的全局注意力池化模块与非局部块建模了相同的全局上下文,但计算成本显著降低。这是因为GC块采用了瓶颈变换(bottleneck transform)来减少全局上下文特征中的冗余,从而进一步减少了参数数量和浮点运算量(FLOPs)。GC块的FLOPs和参数数量明显低于非局部块,这使得我们的GC块可以在计算量略有增加的情况下应用于多层,同时更好地捕获长程依赖关系并有助于网络训练。
与压缩激发块(Squeeze-Excitation block,简称SE块)的关系:SE块与我们的GC块之间的主要区别在于融合模块,这反映了这两个块的不同目标。SE块采用重新缩放来重新校准通道的重要性,但它在建模长程依赖关系方面存在不足。我们的GC块则遵循非局部块的做法,利用加法将全局上下文聚合到所有位置,以捕获长程依赖关系。两者的第二个区别是瓶颈变换中的层归一化(layer normalization)。由于我们的GC块采用加法进行融合,层归一化可以简化两层架构的瓶颈变换的优化,这有助于提升性能。第三,SE块中的全局平均池化是GC块中全局注意力池化的一个特例。表2(f)和4(b)中的结果表明,我们的GCNet在性能上优于SENet。
5、实验
为了评估所提出的方法,我们在三个基本任务上进行了实验,包括在COCO数据集上的目标检测/分割[21]、在ImageNet数据集上的图像分类[5]以及在Kinetics数据集上的动作识别[17]。实验结果表明,提出的GCNet通常优于非局部网络(具有较低的浮点运算次数)和挤压-激励网络(具有可比较的浮点运算次数)。
5.1、在COCO上的目标检测/分割
我们在COCO 2017数据集[21]上研究了我们的模型在目标检测和实例分割方面的性能。该数据集的训练集包含118k张图像,验证集包含5k张图像,测试开发集包含20k张图像。我们遵循标准设置[9],通过不同边界框的平均精度分数和掩码IoU分别评估目标检测和实例分割。
设置。我们的实验使用PyTorch[23]实现。除非另有说明,否则我们的GC块(比率为r=16)应用于ResNet/ResNeXt的c3、c4、c5阶段。
训练。我们使用带有FPN和ResNet/ResNeXt作为骨干架构的Mask R-CNN[9]的标准配置。输入图像的大小被调整为短边为800像素[20]。我们在8个GPU上进行训练,每个GPU上2张图像(有效的小批量大小为16)。所有模型的骨干网络都在ImageNet分类任务[5]上进行预训练,然后除了c1和c2层之外的所有层都与检测和分割头一起进行微调。与[9]中针对RPN的阶段式训练不同,我们的实现采用了像[25]中的端到端训练,从而获得了更好的结果。与常规微调设置[9]不同,我们使用Synchronized BatchNorm来替换冻结的BatchNorm。所有模型都使用带有权重衰减为0.0001和动量为0.9的同步SGD进行12个周期的训练,这大致对应于Mask R-CNN基准测试中的1x计划[22]。学习率初始化为0.02,并在第9个和第11个周期时分别降低10倍。超参数的选择也遵循Mask R-CNN基准测试的最新发布版本[22]。
5.1.1、消融实验
消融实验在COCO 2017验证集上进行。报告了标准的COCO指标,包括针对边界框和分割掩码的 A P AP AP、 A P 50 AP_{50} AP50、 A P 75 AP_{75} AP75。
块设计。按照[31]的方法,我们在c4的最后一个残差块之前插入1个非局部块(NL)、1个简化的非局部块(SNL)或1个全局上下文块(GC)。表2(a)显示,SNL和GC在参数和计算量较少的情况下,性能与非局部块相当,这表明原始非局部设计中的计算和参数存在冗余。此外,在所有残差块中添加GC块可以获得更高的性能(在 A P b b o x AP^{\mathrm{bbox}} APbbox上提高了 1.1 % 1.1\% 1.1%,在 A P mask AP^{\text {mask }} APmask 上提高了 0.9 % 0.9\% 0.9%),同时FLOPs和参数数量略有增加。
位置。非局部块(NL)插入在残差块之后(afterAdd),而挤压-激励块(SE)则集成在残差块内部的最后一个 1 × 1 1 \times 1 1×1卷积之后(after 1 × 1 1 \times 1 1×1)。在表2(b)中,我们调查了GC块的两种情况,并得到了类似的结果。因此,我们采用after 1 × 1 1 \times 1 1×1作为默认设置。
阶段。表2©展示了在不同阶段集成GC块的结果。所有阶段都受益于GC块中的全局上下文建模(在 A P bbox AP^{\text {bbox }} APbbox 和 A P mask AP^{\text {mask }} APmask 上分别提高了 0.7 % − 1.7 % 0.7\%-1.7\% 0.7%−1.7%)。在 c 4 \mathrm{c} 4 c4和 c 5 \mathrm{c} 5 c5中插入GC块都比在 c 3 \mathrm{c} 3 c3中插入效果更好,这表明更好的语义特征可以从全局上下文建模中获益更多。在FLOPs略有增加的情况下,将GC块插入所有层( c 3 + c 4 + c 5 \mathrm{c} 3+\mathrm{c} 4+\mathrm{c} 5 c3+c4+c5)的性能甚至高于仅插入单一层的性能。
瓶颈设计。表2(d)展示了瓶颈变换中每个组件的影响。w/o ratio表示使用单个
1
×
1
1 \times 1
1×1卷积作为变换的简化NLNet,与基线相比具有更多的参数。尽管r16和r16+ReLU的参数远少于w/o ratio变体,但发现两层更难优化,并且性能比单层更差。因此,我们利用LayerNorm(LN)来简化优化,导致性能与w/o ratio相似,但参数数量大大减少。
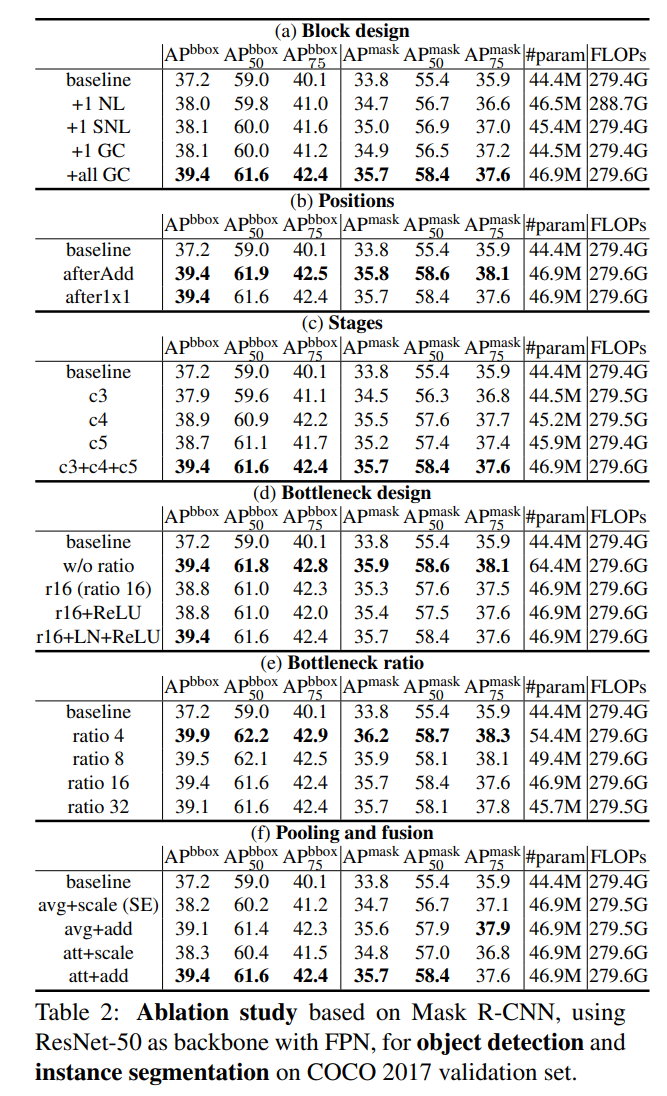
瓶颈比率。瓶颈设计的目的是减少参数中的冗余,并在性能和参数之间提供权衡。在表2(e)中,我们改变了瓶颈的比率 r \mathrm{r} r。随着比率 r \mathrm{r} r的减小(从32到4),参数和FLOPs的数量增加,性能也持续提高(在 A P b b o x AP^{\mathrm{bbox}} APbbox上提高了 0.8 % 0.8\% 0.8%,在 A P mask AP^{\text {mask }} APmask 上提高了 0.5 % 0.5\% 0.5%),这表明我们的瓶颈设计在性能和参数之间达到了良好的平衡。值得注意的是,即使比率 r = 32 \mathrm{r}=32 r=32,网络仍然以较大幅度优于基线。
池化和融合。表2(f)展示了池化和融合的不同选择的结果。首先,它表明在融合阶段,加法比缩放更有效。令人惊讶的是,注意力池化仅比普通的平均池化取得稍好的结果。这表明,如何将全局上下文聚合到查询位置(融合模块的选择)比如何将所有位置的特征组合在一起(上下文建模模块的选择)更重要。值得注意的是,我们的GCNet(att+add)显著优于SENet,这是因为使用注意力池化进行上下文建模,并使用加法进行特征聚合,可以有效地建模长距离依赖关系。
5.1.2、在更强骨干网络上的实验
我们通过将ResNet-50替换为ResNet-101和ResNeXt-101 [34],在多个层次( c 3 + c 4 + c 5 \mathrm{c} 3+\mathrm{c} 4+\mathrm{c} 5 c3+c4+c5)添加可变形卷积[4,42],并采用Cascade策略[1],来在更强的骨干网络上评估我们的GCNet。我们报告了在所有层( c 3 + c 4 + c 5 \mathrm{c} 3+\mathrm{c} 4+\mathrm{c} 5 c3+c4+c5)集成了GC块,且瓶颈比率为4和16的GCNet的结果。表3(a)展示了在验证集上的详细结果。值得注意的是,即使采用更强的骨干网络,GCNet与基线相比的增益仍然显著,这表明我们的带有全局上下文建模的GC块与当前模型的容量是互补的。对于最强的骨干网络,即ResNeXt101中的可变形卷积和Cascade RCNN,我们的GC块仍然可以提高 0.8 % 0.8\% 0.8%的 A P b b o x AP^{\mathrm{bbox}} APbbox和 0.5 % 0.5\% 0.5%的 A P mask AP^{\text {mask }} APmask 性能。为了进一步评估我们提出的方法,我们还报告了test-dev集上的结果,如表3(b)所示。在test-dev上,添加GC块也大大提高了强大的基线性能,这与验证集上的结果一致。这些结果证明了我们提出方法的稳健性。
5.2、ImageNet上的图像分类
ImageNet [5]是一个用于图像分类的基准数据集,包含1.28M张训练图像和50K张来自1000个类别的验证图像。我们遵循[10]中的标准设置,在训练集上训练深度网络,并报告验证集上单裁剪的top-1和top-5错误率。我们的预处理和增强策略遵循[33]和[14]中提出的基线。为了加快实验速度,所有报告的结果都是通过两个阶段进行训练的。首先,我们在8个GPU上使用标准ResNet-50训练120个epoch,每个GPU有64张图像(有效批处理大小为512),并使用5个epoch的线性预热。其次,我们将新设计的块插入到第一阶段训练的模型中,并使用0.02的初始学习率进行其他40个epoch的微调。基线也遵循这种两阶段训练,但第二阶段不添加新块。在训练和微调阶段都使用余弦学习率衰减。
块设计。与在COCO上进行块设计的方法相同,不同块的结果如表4(a)所示。GC块在参数和计算量更少的情况下,性能略优于NL和SNL块,这表明了我们设计的通用性和泛化能力。通过将GC块插入所有残差块( c 3 + c 4 + c 5 \mathrm{c} 3+\mathrm{c} 4+\mathrm{c} 5 c3+c4+c5)中,性能得到进一步提升(与基线相比,top-1准确率提高了0.82%),且计算开销增加相对较少(FLOPs相对增加了0.26%)。
池化和融合。我们还研究了不同池化和融合方法在图像分类中的功能。通过比较表4(b)和表2(f),可以看出注意力池化在图像分类中起到了更大的作用,这可能是[14]中缺失的因素之一。此外,采用加法的注意力池化(GCNet)在几乎相同的参数数量和浮点运算量(FLOPs)下,比采用缩放的普通平均池化(SENet)在top-1准确率上高出0.44%。
5.3、Kinetics上的动作识别
对于人体动作识别,我们采用了广泛使用的Kinetics [17] 数据集,它包含约24万个训练视频和2万个验证视频,这些视频分布在400个人体动作类别中。所有模型都在训练集上进行训练,并在验证集上进行测试。我们遵循[31]中的做法,报告top-1和top-5识别准确率。我们采用了[6]中的slow-only基线,这是目前能够利用从ImageNet预训练模型中膨胀[2]权重的最佳单一模型。这种膨胀3D策略[31]大大加快了收敛速度,相比于从头开始训练。所有实验设置均明确遵循[6];slow-only基线使用8帧(8×8)作为输入,并采用multi(30)-clip验证。
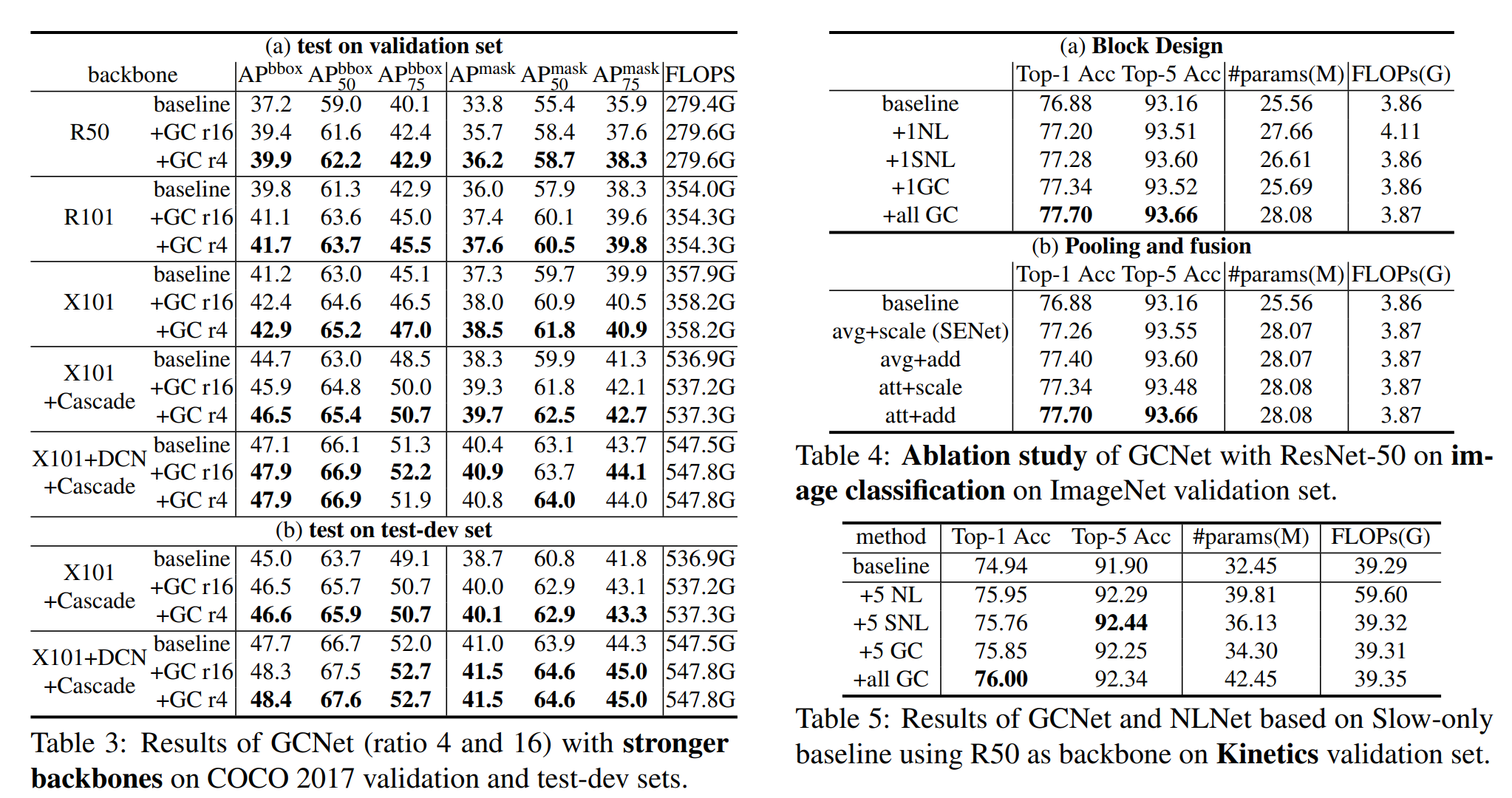
消融研究的结果如表5所示。对于Kinetics实验,GC块的比例设置为4。首先,当用简化的NL块和GC块替换NL块时,性能可以认为是相当的(top-1准确率下降了0.19%和0.11%,top-5准确率上升了0.15%和0.14%)。与COCO和ImageNet一样,添加更多的GC块可以进一步改进结果,并且以更少的计算量优于NL块。
6、结论
长距离依赖建模的开创性工作——非局部网络,旨在建模特定于查询的全局上下文,但实际上只建模了与查询无关的上下文。基于这一点,我们简化了非局部网络,并将这个简化版本抽象为一个全局上下文建模框架。接着,我们提出了该框架的一个新颖实例——GC块,它轻量且能有效建模长距离依赖。我们的GCNet是通过在多个层中应用GC块构建的,在各种识别任务的主要基准测试中,它通常优于简化的NLNet和SENet。
YoloV8官方结果
YOLOv8l summary (fused): 268 layers, 43631280 parameters, 0 gradients, 165.0 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 29/29 [
all 230 1412 0.922 0.957 0.986 0.737
c17 230 131 0.973 0.992 0.995 0.825
c5 230 68 0.945 1 0.995 0.836
helicopter 230 43 0.96 0.907 0.951 0.607
c130 230 85 0.984 1 0.995 0.655
f16 230 57 0.955 0.965 0.985 0.669
b2 230 2 0.704 1 0.995 0.722
other 230 86 0.903 0.942 0.963 0.534
b52 230 70 0.96 0.971 0.978 0.831
kc10 230 62 0.999 0.984 0.99 0.847
command 230 40 0.97 1 0.995 0.811
f15 230 123 0.891 1 0.992 0.701
kc135 230 91 0.971 0.989 0.986 0.712
a10 230 27 1 0.555 0.899 0.456
b1 230 20 0.972 1 0.995 0.793
aew 230 25 0.945 1 0.99 0.784
f22 230 17 0.913 1 0.995 0.725
p3 230 105 0.99 1 0.995 0.801
p8 230 1 0.637 1 0.995 0.597
f35 230 32 0.939 0.938 0.978 0.574
f18 230 125 0.985 0.992 0.987 0.817
v22 230 41 0.983 1 0.995 0.69
su-27 230 31 0.925 1 0.995 0.859
il-38 230 27 0.972 1 0.995 0.811
tu-134 230 1 0.663 1 0.995 0.895
su-33 230 2 1 0.611 0.995 0.796
an-70 230 2 0.766 1 0.995 0.73
tu-22 230 98 0.984 1 0.995 0.831
Speed: 0.2ms preprocess, 3.8ms inference, 0.0ms loss, 0.8ms postprocess per image
源码以及注释
import torch
import torch.nn as nn
class GlobalContextBlock(nn.Module):
def __init__(self, in_channels, scale=16):
super(GlobalContextBlock, self).__init__()
# 输入通道数
self.in_channels = in_channels
# 输出通道数,是输入通道数除以一个缩放因子scale
self.out_channels = self.in_channels // scale
# 用于生成key的卷积层,将输入通道数变为1
self.Conv_key = nn.Conv2d(self.in_channels, 1, 1)
# Softmax激活函数,用于归一化key
self.SoftMax = nn.Softmax(dim=1)
# 用于生成value的卷积序列
self.Conv_value = nn.Sequential(
# 将输入通道数变为out_channels
nn.Conv2d(self.in_channels, self.out_channels, 1),
# 层归一化
nn.LayerNorm([self.out_channels, 1, 1]),
# ReLU激活函数
nn.ReLU(),
# 将通道数变回in_channels
nn.Conv2d(self.out_channels, self.in_channels, 1),
)
def forward(self, x):
# 获取输入x的batch大小、通道数、高度和宽度
b, c, h, w = x.size()
# 生成key,并进行Softmax归一化
# key -> [b, 1, H, W] -> [b, 1, H*W] -> [b, H*W, 1]
key = self.SoftMax(self.Conv_key(x).view(b, 1, -1).permute(0, 2, 1).view(b, -1, 1).contiguous())
# 将输入x的通道维度和空间维度合并
query = x.view(b, c, h*w)
# 将query和key进行矩阵乘法,得到每个位置的全局上下文信息
# [b, c, h*w] * [b, H*W, 1]
concate_QK = torch.matmul(query, key)
# 将concate_QK的形状调整为与x相同,除了通道维度外,其他维度均为1
concate_QK = concate_QK.view(b, c, 1, 1).contiguous()
# 通过Conv_value生成value,并将其与原始输入x相加
value = self.Conv_value(concate_QK)
out = x + value
return out
GlobalContextBlock 是一个神经网络模块,旨在捕捉全局上下文信息。该模块将输入特征映射到全局上下文表示,并将其与原始特征进行结合,以增强特征表示能力。下面是关于这个类的详细解释:
初始化函数 __init__
在初始化函数中,首先通过调用父类 nn.Module 的初始化函数 super(GlobalContextBlock, self).__init__() 来初始化这个模块。然后,定义了一些属性和层。
in_channels: 输入特征的通道数。out_channels: 输出特征的通道数,是输入通道数除以一个缩放因子scale。Conv_key: 一个卷积层,用于从输入特征中提取关键信息,输出通道数为1。SoftMax: Softmax层,用于将关键信息归一化为权重。Conv_value: 一个卷积序列,用于从输入特征中提取值信息,并经过层归一化、ReLU激活函数和另一个卷积层,最后输出通道数与输入相同。
前向传播函数 forward
在前向传播函数中,首先获取输入张量 x 的尺寸 (b, c, h, w),其中 b 是批次大小,c 是通道数,h 和 w 分别是高度和宽度。
接下来,执行以下步骤:
-
提取关键信息(Key):
- 通过
Conv_key卷积层对输入x进行卷积,得到关键信息。 - 将卷积后的结果从形状
[b, 1, h, w]重塑为[b, 1, h*w]。 - 使用
permute方法将维度顺序调整为[b, h*w, 1]。 - 应用 Softmax 层对关键信息进行归一化,得到权重。
- 通过
-
提取查询信息(Query):
- 将输入
x从形状[b, c, h, w]重塑为[b, c, h*w],作为查询信息。
- 将输入
-
计算查询和关键信息的点积(Concatenation of Query and Key):
- 使用
torch.matmul计算查询和关键信息的点积,得到形状为[b, c, h*w]的张量。 - 将点积结果重塑为
[b, c, 1, 1],为接下来的操作做准备。
- 使用
注意:在给出的代码片段中,forward 函数在 concate_QK = concate_QK.view(b, c, 1, 1).contiguous() 之后被截断了,并没有显示如何处理值信息(Value)以及如何将全局上下文信息与原始特征进行结合。通常,这部分会涉及将值信息通过 Conv_value 进行处理,然后与查询和关键信息的点积结果进行某种形式的结合(例如加法或乘法),以得到最终的输出。
全局上下文块通常用于增强特征的表示能力,通过捕捉全局上下文信息来帮助模型更好地理解输入数据的整体结构。这种机制在多种计算机视觉任务中都有广泛应用,如图像分类、目标检测和语义分割等。