1.双向链表
redis中的普通链表是双向链表。通过链表节点结构体可知有全驱节点和后继节点。
1.链表节点和链表
//adlist.h
typedef struct listNode {
struct listNode *prev; //前驱节点
struct listNode *next; //后继节点
void *value; //节点值
} listNode;
//链表结构
typedef struct list {
listNode *head; //头节点
listNode *tail; //尾结点
void *(*dup)(void *ptr); //节点值复制函数
void (*free)(void *ptr); //节点值释放函数
int (*match)(void *ptr, void *key); //节点值比对函数
unsigned long len; //当前节点的个数
} list;链表中的函数指针主要是对节点值的操作,包括复制,析构,判断是否相等。
2.迭代器
此外,Redis还为链表提供迭代器的功能,主要是对链表节点的封装,另外通过链表节点的前驱节点和后继节点,可以轻松的完成向前移动和向后移动。
//adlist.h
typedef struct listIter {
listNode *next; //指向的实际节点
int direction; //表示迭代器方向,向前还是向后
} listIter;
/* Directions for iterators */
#define AL_START_HEAD 0 //从表头向表尾迭代
#define AL_START_TAIL 1 //从表尾向表头迭代3.宏定义函数
这些看宏名字就很容易知道其功能的。
#define listLength(l) ((l)->len)
#define listFirst(l) ((l)->head)
#define listLast(l) ((l)->tail)
#define listPrevNode(n) ((n)->prev)
#define listNextNode(n) ((n)->next)
#define listNodeValue(n) ((n)->value)
#define listSetDupMethod(l,m) ((l)->dup = (m))
#define listSetFreeMethod(l,m) ((l)->free = (m))
#define listSetMatchMethod(l,m) ((l)->match = (m))
#define listGetDupMethod(l) ((l)->dup)
#define listGetFreeMethod(l) ((l)->free)
#define listGetMatchMethod(l) ((l)->match)4.链表的操作
list *listCreate(void); //创建链表
void listRelease(list *list); //释放链表,会释放内存,就是完全释放链表了
void listEmpty(list *list); //置空链表,没有释放内存的
list *listAddNodeHead(list *list, void *value); //添加节点在头部
list *listAddNodeTail(list *list, void *value); //在尾部添加节点
list *listInsertNode(list *list, listNode *old_node, void *value, int after);
void listDelNode(list *list, listNode *node); //删除该节点
listNode *listSearchKey(list *list, void *key);
listNode *listIndex(list *list, long index);
void listRewind(list *list, listIter *li);
void listRewindTail(list *list, listIter *li);
void listRotateTailToHead(list *list);
void listRotateHeadToTail(list *list);
void listJoin(list *l, list *o);
//有关迭代器的操作
listIter *listGetIterator(list *list, int direction); //创建一个链表迭代器,并根据传入的direction来返回链表的头或尾节点
listNode *listNext(listIter *iter);
void listReleaseIterator(listIter *iter);
list *listDup(list *orig);链表的创建和添加节点这些比较好理解,就不多说。这里主要讲解下有关迭代器的操作。
4.1. listGetIterator
listIter *listGetIterator(list *list, int direction)
{
listIter *iter;
if ((iter = zmalloc(sizeof(*iter))) == NULL) return NULL;
// 根据迭代方向,设置迭代器的起始节点
if (direction == AL_START_HEAD) //这个表示迭代器的方向是从头到尾
iter->next = list->head; //迭代器对应的节点就是头节点
else
iter->next = list->tail;
iter->direction = direction; //记录迭代方向
return iter;
}4.2.listRewind和listRewindTail
handleClientsWithPendingReadsUsingThreads函数中使用到的。
在列表专用迭代器结构中创建迭代器,listRewind即是通过传入一个listIter变量,从而创建了迭代器,从而可以得到链表中的节点了。
void listRewind(list *list, listIter *li) {
li->next = list->head;
li->direction = AL_START_HEAD;
}
void listRewindTail(list *list, listIter *li) {
li->next = list->tail;
li->direction = AL_START_TAIL;
}4.3.listNext
返回迭代器当前所指向的节点,即是iter->next。
这个函数也是在handleClientsWithPendingReadsUsingThreads中有使用到的,通过一个 while((ln = listNext(&li)))循环获取链表中的节点。
listNode *listNext(listIter *iter)
{
listNode *current = iter->next;
if (current != NULL) {
//之后要更行迭代器当前所指向的节点
if (iter->direction == AL_START_HEAD)
iter->next = current->next; //保存下一个节点,防止当前节点被删除而造成指针丢失
else
iter->next = current->prev;
}
return current;
}4.4.listDup,复制链表
前面说了那么多操作,其实就是为了把它们组合起来使用,handleClientsWithPendingReadsUsingThreads函数就是把他们组合起来使用的。也比如listDup函数,就是上面的综合体。
list *listDup(list *orig)
{
list *copy;
listIter iter;
listNode *node;
//创建链表
if ((copy = listCreate()) == NULL)
return NULL;
// 设置节点值处理函数
copy->dup = orig->dup;
copy->free = orig->free;
copy->match = orig->match;
listRewind(orig, &iter); //迭代整个输入链表
while((node = listNext(&iter)) != NULL) {
void *value;
if (copy->dup) { // 复制节点值到新节点
value = copy->dup(node->value);
if (value == NULL) {
listRelease(copy);
return NULL;
}
} else
value = node->value;
if (listAddNodeTail(copy, value) == NULL) { //将节点添加到链表
listRelease(copy);
return NULL;
}
}
return copy;
}2.简单动态字符串
2.1为什么不用char传统数组来表示字符串
Redis使用一种称为 简单动态字符串(Simple Dynamic Strings,SDS) 来存储字符串和整型数据。 这是为什么呢?
首先想想c语言字符串的一些问题
- 获取字符串长度strlen,效率低。其时间复杂度是O(N)。
- 缓冲区溢出问题。使用mepcy(a,b,n)时候,可能a长度不够,就导致溢出。
- 二进制不安全。在 C 语言中,字符串实际上是使用字符 '\0'终止的一维字符数组。所以在 C 语言获取一个字符串长度,会逐个字符遍历,直到遇到代表字符串结尾的空字符为止。这就会导致二进制安全问题。通俗的讲,C 语言中,用 “\0” 表示字符串的结束,如果字符串本身就有 “\0” 字符,字符串就会被截断,即非二进制安全;若通过某种机制,保证读写字符串时不损害其内容,则是二进制安全。
- 修改字符串可能需要进行多次分配内存,耗时耗空间。C 字符串本身不记录字符串的长度,所以对于一个包含了 N 个字符的 C 字符串来说, 这个 C 字符串的底层实现总是一个 N+1 个字符长的数组。因为 C 字符串的长度和底层数组的长度之间存在着这种关联性,所以每次增长或缩短一个 C 字符, 程序都总要对保存这个 C 字符串的数组进行一次内存重分配操作。比如执行增长操作之前需要先进行内存重分配,以扩展底层数组的空间大小,如果忘了就会导致缓冲区溢出。然而内存重分配需要执行系统调用,所以它通常是一个比较耗时的操作。
所以 Redis 为 SDS 设计了冗余空间,追加时只要内容不是太大,是可以不必重新分配内存的。
基于以上的问题,Redis就设计了SDS。
2.2 SDS类型
Redis为了灵活的保存不同大小的字符串节省内存空间,设计了不同的结构头sdshdr64、sdshdr32、sdshdr16、sdshdr8和sdshdr5(已不再使用)。
2.2.1SDS结构
//sds.h
typedef char *sds;
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
//还有sdshdr32,sdshdr64没有展示.......................
//这些就是对应结构体中的flags
#define SDS_TYPE_5 0
#define SDS_TYPE_8 1
#define SDS_TYPE_16 2
#define SDS_TYPE_32 3
#define SDS_TYPE_64 4
#define SDS_TYPE_MASK 7 //二进制是0b0111,用来按位与
#define SDS_TYPE_BITS 3
虽然结构头不同,但是他们都具有相同的属性:
- len:字符数组buf实际使用的大小,也就是字符串的长度(不包括'\0')
- alloc:字符数组buf分配的空间大小,不包含结束标识符('\0')
- flags:标记SDS的类型:sdshdr64、sdshdr32、sdshdr16、sdshdr8
- buf[]:字符数组,用来存储实际的字符数据
有成员len就可以常数时间复杂度得到sds字符串的长度了,也因为以len 属性而不是空字符‘\0’来判断字符串是否结束,那也就可以存放二进制数据了。
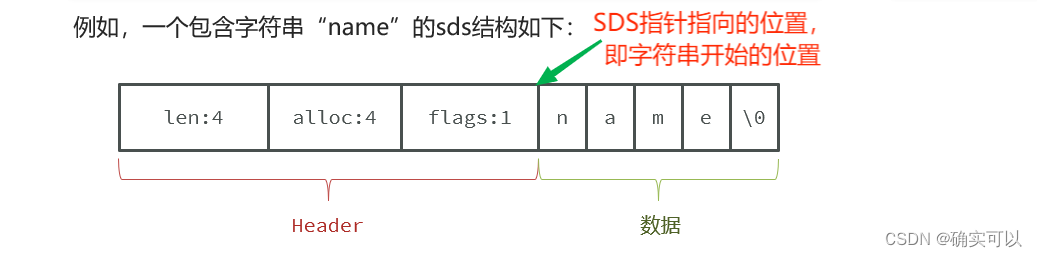
redis一些设计点
Redis使用了_attribute_ (( __packed__))节省内存空间,它可以告诉编译器使用紧凑的方式分配内存,不使用字节对齐的方式给变量分配内存。这也是代表着sdshdr结构体是按1字节对齐(默认结构体会按其所有变量大小的最小公倍数做字节对齐),即结构体的各属性是连续存储的,可以使用flags = s[-1] 这种操作。
在结构体定义中,可以看到最后一个buf数组是没有设置大小的,这种放在结构体中最后一个元素位置并且没有设置大小的数组称为柔性数组,它可以在程序运行过程中进行动态内存分配。
2.3宏定义SDS_HDR_VAR和SDS_HDR
//sds.h
#define SDS_HDR_VAR(T,s) struct sdshdr##T *sh = (void*)((s)-(sizeof(struct sdshdr##T)));
#define SDS_HDR(T,s) ((struct sdshdr##T *)((s)-(sizeof(struct sdshdr##T))))关于 sdshdr##T ,不太懂,在这里理解成它将 sdshdr 和 T 连接在一起,即表示不同的 sdshdr 类型。
关于 SDS_HDR_VAR(T,s), 参数 s 是sdshdr 结构体中的字符串指针,即等价于 buf,参数 T 则是表示不同类型的 sdshdr,取值可以为 8/16/32/64。然后看其实现,struct sdshdr##T *sh 是宏定义的一个变量, void* 是将结果转换为void* 类型,以便 sh 接收。而 (s) - ( sizeof(struct sdshdr##T) )则表示指向结构体变量的地址。首先sizeof(struct sdshdr##T) 计算的大小不包含 buf (柔性数组特点),而 s 的指向的地址就跟在 sdshdr 之后。
通过sdslen和sdsavail两个函数来看看他们的区别和使用:
SDS_HDR是SDS_HDR(8,s)->len;
SDS_HDR_VAR是直接就使用SDS_HDR_VAR(8,s);sh->alloc->sh->len。
所以 SDS_HDR(T, S) 就是返回一个 保存字符串 s 的结构体地址,然后就可以调用其成员。
SDS_HDR_VAR 是定义一个指向保存字符串 s 的结构体指针,即是先定义一个结构体指针sh,然后再使用sh.
注意两者的差别:SDS_HDR_VAR 是定义变量保存结构体地址,SDS_HDR 是返回结构体地址。
函数中的s[-1],即表示 sdshdr 结构中的成员 flags,因为其结构体的各属性是连续存储的。通过 flags 我们可以判断 sdshdr 的类型。
//得到字符串长度,即是已使用长度
static inline size_t sdslen(const sds s) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_8:
return SDS_HDR(8,s)->len;
case SDS_TYPE_16:
return SDS_HDR(16,s)->len;
//...............................
}
return 0;
}
//得到还没使用的长度
static inline size_t sdsavail(const sds s) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s);
return sh->alloc - sh->len;
}
case SDS_TYPE_16: {
SDS_HDR_VAR(16,s);
return sh->alloc - sh->len;
}
//......................
}
return 0;
}还有一些其他关于sds属性的函数
这些函数的实现是相似的。
sdssetlen:修改 sds 的有效长度。
sdsinclen:增加 sds 的有效长度。
sdsalloc:返回 sds 的已分配空间大小。也可以通过 sdsavail() + sdslen() 来获取。
sdssetalloc:设置 sds 的已分配空间大小。
//sds.h
//修改 sds 的有效长度
static inline void sdssetlen(sds s, size_t newlen) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_8:
SDS_HDR(8,s)->len = newlen;
break;
case SDS_TYPE_16:
SDS_HDR(16,s)->len = newlen;
break;
//...............
}
}
//增加 sds 的有效长度
static inline void sdsinclen(sds s, size_t inc) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_8:
SDS_HDR(8,s)->len += inc;
break;
case SDS_TYPE_16:
SDS_HDR(16,s)->len += inc;
break;
//...............
}
}
//返回 sds 的已分配空间大小。也可以通过 sdsavail() + sdslen() 来获取
/* sdsalloc() = sdsavail() + sdslen() */
static inline size_t sdsalloc(const sds s) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_8:
return SDS_HDR(8,s)->alloc;
case SDS_TYPE_16:
return SDS_HDR(16,s)->alloc;
//...............
}
return 0;
}
//设置 sds 的已分配空间大小
static inline void sdssetalloc(sds s, size_t newlen) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_8:
SDS_HDR(8,s)->alloc = newlen;
break;
case SDS_TYPE_16:
SDS_HDR(16,s)->alloc = newlen;
break;
//.......................
}
}2.4.SDS的创建
要创建一个 sds 对象,首先要确认其 sds 结构属于哪一种,要根据字符串长度来选择 sdshdr 。
下面是根据字符串长度来确认 sds 类型的几个相关函数
//sds.c
//通过长度去获取类型
static inline char sdsReqType(size_t string_size) {
if (string_size < 1<<8)
return SDS_TYPE_8;
if (string_size < 1<<16)
return SDS_TYPE_16;
//............
}
//得到对应的结构体的大小
static inline int sdsHdrSize(char type) {
switch(type&SDS_TYPE_MASK) {
case SDS_TYPE_5:
return sizeof(struct sdshdr5);
case SDS_TYPE_8:
return sizeof(struct sdshdr8);
//............................
}
return 0;
}创建函数sdsnewlen
创建sds的思路是:
- 根据字符串长度来计算出sds类型,
- 申请sdshdr的内存
- 根据sdsHdr的类型设置 len, alloc, flag 属性,
- 将字符串内容设置到sdsHdr中,并最后添加'\0'结尾。
//sds.c
//用于标识, 创建sds时, 不初始化字符数组
extern const char *SDS_NOINIT;
//如果init指针是NULL, 则将内存初始化为0, 如果init是SDS_NOINIT, 则不进行初始化
sds sdsnewlen(const void *init, size_t initlen) {
void *sh;
sds s;
//1.根据长度得出要使用的sds的类型
char type = sdsReqType(initlen);
//如果类型是 5, 或者初始字符串长度是 0 , 则默认给 8
if (type == SDS_TYPE_5 && initlen == 0) type = SDS_TYPE_8;
int hdrlen = sdsHdrSize(type); //得到sds类型的大小
unsigned char *fp; /* flags pointer. */
assert(initlen + hdrlen + 1 > initlen); //防止溢出
//2.分配内存
sh = s_malloc(hdrlen+initlen+1);
if (sh == NULL) return NULL;
if (init==SDS_NOINIT) //如果init是SDS_NOINIT, 则不进行初始化
init = NULL;
else if (!init) //如果init指针是NULL, 则将内存初始化为0,
memset(sh, 0, hdrlen+initlen+1);
s = (char*)sh+hdrlen; //字符串的开始位置
fp = ((unsigned char*)s)-1; //得到flags
//3.根据sdsHdr的类型设置 len, alloc, flag 属性,
switch(type) {
case SDS_TYPE_5: {
*fp = type | (initlen << SDS_TYPE_BITS);
break;
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s); //这是找到结构体初始的地址,并赋值给sh
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_16: {
SDS_HDR_VAR(16,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_32: {
SDS_HDR_VAR(32,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_64: {
SDS_HDR_VAR(64,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
}
//4.将字符串内容设置到sdsHdr中
if (initlen && init)
memcpy(s, init, initlen);
s[initlen] = '\0'; //最后添加'\0'结尾
return s;
}还有一些其他的创建函数,其就是内部调用了sdsnewlen。
//sds.c
//创建一个空的sds
sds sdsempty(void) {
return sdsnewlen("",0);
}
//根据给定的C字符串创建sds
sds sdsnew(const char *init) {
size_t initlen = (init == NULL) ? 0 : strlen(init);
return sdsnewlen(init, initlen);
}
//复制一个sds
sds sdsdup(const sds s) {
return sdsnewlen(s, sdslen(s));
}2.5.预分配SDS内存,可以动态扩容
sds是简单动态字符串,说明是可以自动扩容的。那sdsMakeRoomFor就是来实现这个功能的。
扩大sds字符串末尾的可用空间,以便调用方确保在调用此函数后,可以覆盖字符串末尾后最多addlen个字节,再加上一个nul项字节。
过程:
- 得到剩余的空间大小和sds类型,若剩余的空间>=要扩容的空间,那就直接返回即可。
- 若剩余的空间不够,则获取已使用的长度和该结构体起始的地址位置,并计算出新的长度(已使用的长度+要扩容的长度),并进行判断,最终得到新长度。
- 根据新长度来确定新的sds类型,并得到结构体大小,若旧类型和新类型是一致的,那就在原有内存上重分配,扩展空间;否则,重新分配空间,再设置好结构体的一下成员数据。
sds sdsMakeRoomFor(sds s, size_t addlen) { //要扩容addlen长度
void *sh, *newsh;
//步骤1
size_t avail = sdsavail(s); //得到剩余的空间大小
size_t len, newlen, reqlen;
char type, oldtype = s[-1] & SDS_TYPE_MASK; //得到类型
int hdrlen;
if (avail >= addlen) return s;
//步骤2
len = sdslen(s); //得到已使用的长度
sh = (char*)s-sdsHdrSize(oldtype); //该结构体起始的地址位置
reqlen = newlen = (len+addlen); //已使用的长度+要扩容的长度,即是新的总长度
assert(newlen > len); /* Catch size_t overflow */
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC;
//步骤3
type = sdsReqType(newlen);//根据新总长度来确定sds类型
if (type == SDS_TYPE_5) type = SDS_TYPE_8;
hdrlen = sdsHdrSize(type); //得到结构体大小
assert(hdrlen + newlen + 1 > reqlen); /* Catch size_t overflow */
if (oldtype==type) {
newsh = s_realloc(sh, hdrlen+newlen+1); //重分配,扩展空间
if (newsh == NULL) return NULL;
s = (char*)newsh+hdrlen; //字符串开始的位置
} else {
//表示 sds 类型发生了变化,分配新的内存
newsh = s_malloc(hdrlen+newlen+1);
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len+1);
s_free(sh);
s = (char*)newsh+hdrlen;
s[-1] = type;
sdssetlen(s, len); //设置已使用的长度
}
sdssetalloc(s, newlen); //设置总的长度
return s;
}那么这个调用该函数不会改变函数返回的sds字符串的长度len,只会改变其可用的剩余空间。
那来看看这个函数的使用例子
sdscatlen是把字符串t追加到s的末尾。类似于c语言的char *strcat(char *dest, const char *src)。
sds sdscatlen(sds s, const void *t, size_t len) {
size_t curlen = sdslen(s); //得到已使用的长度,即是字符串长度
s = sdsMakeRoomFor(s,len); //分配空间,确保不会越界
if (s == NULL) return NULL;
memcpy(s+curlen, t, len);
sdssetlen(s, curlen+len);
s[curlen+len] = '\0';
return s;
}sdscpylen函数就类似c语言的 void *memcpy(void *str1, const void *str2, size_t n)。
sds sdscpylen(sds s, const char *t, size_t len) {
if (sdsalloc(s) < len) { //总的分配的长度小于要复制的长度len,所以要预分配新空间
s = sdsMakeRoomFor(s,len-sdslen(s));
if (s == NULL) return NULL;
}
memcpy(s, t, len);
s[len] = '\0';
sdssetlen(s, len);
return s;
}每次需要字符串增长的时候,就会调用sdsMakeRoomFor,若是需要就进行预分配空间,就可以确保不会出现缓冲区溢出问题。
而通过空间预分配策略,Redis 可以减少连续执行字符串增长操作所需的内存重分配次数。
2.6.字符串释放(惰性空间释放)
SDS 提供了直接释放内存的方法——sdsfree,该方法通过对 s 的偏移,可定位到 SDS 结构体的首部,然后调用 s_free 释放内存。
void sdsfree(sds s) {
if (s == NULL) return;
s_free((char*)s-sdsHdrSize(s[-1]));
}而 为了优化性能(减少申请内存的开销),SDS 也提供了不直接释放内存,而是通过重置统计值达到清空目的的方法——sdsclear。该方法仅将 SDS 的 len 归零,此处已存在的 buf 并没有真正被清除,新的数据可以覆盖写,而不用重新申请内存。
void sdsclear(sds s) {
sdssetlen(s, 0); //设置已使用的长度
s[0] = '\0';
}通过惰性空间释放策略,SDS 避免了缩短字符串时所需的内存重分配操作,并为将来可能有的增长操作提供了优化。
2.7. SDS总结







![练习 16 Web [极客大挑战 2019]LoveSQL](https://img-blog.csdnimg.cn/direct/cbbfc9d58e95478b89b119b7e6ee77ff.png)