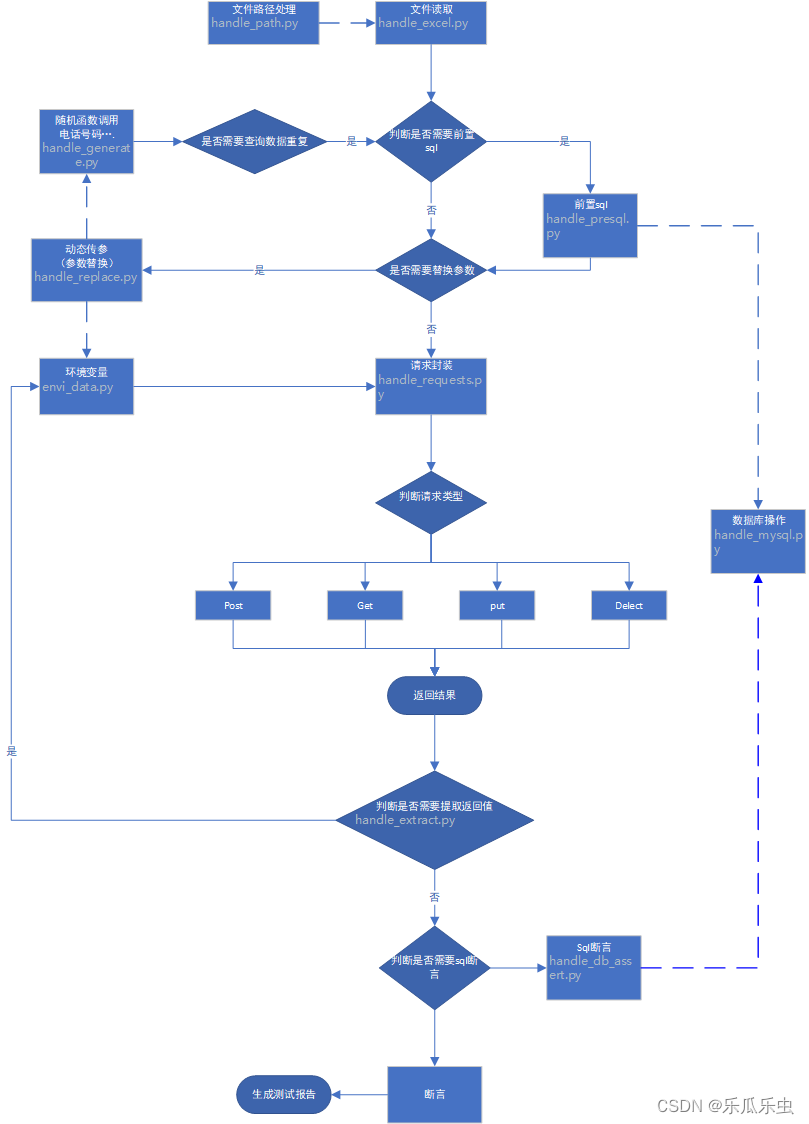
在这里,我描述了我在过去几年中关于 RAG 系统如何发展的主要经验。分享 Naive RAG、Advanced RAG 和 Modular RAG 框架之间的区别。总结了高云帆等人发表的一篇出色的RAG 技术调查论文的关键见解。
什么是 RAG 框架?
OpenAI的GPT系列、Meta的LLama系列、Google的Gemini等大型语言模型(LLM)在生成人工智能领域取得了重大成就。
但这些模型是不确定的。通常,LLM 可能会产生不准确或不相关的内容(称为幻觉),依赖过时的信息,并且他们的决策过程不透明,导致黑箱推理。
检索增强生成 (RAG) 框架旨在帮助缓解这些挑战。 RAG 通过额外的特定领域数据增强了LLM的知识库。
例如,基于 RAG 的系统用于高级问答 (Q&A) 应用程序——聊天机器人。要创建一个可以理解并响应有关私人或特定主题的查询的聊天机器人,有必要使用所需的特定数据来扩展大型语言模型 (LLM) 的知识。这就是 RAG 可以提供帮助的地方。
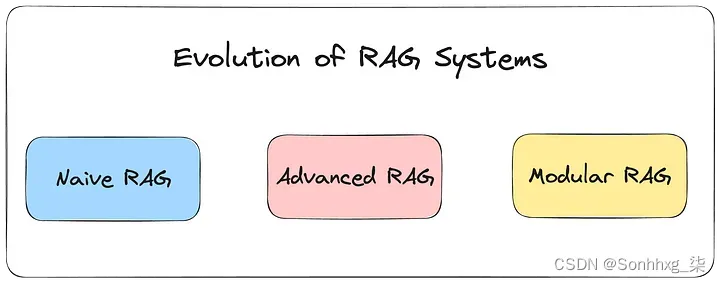
简单 RAG、高级 RAG 、 模块化 RAG
RAG 框架解决了以下问题:
- “要检索什么信息”
- “检索信息什么时候召回”
- “如何使用检索到的信息”
在过去的几年里,RAG 领域进行了大量的研究和创新。RAG 系统可分为 3 类:
- 简单 RAG
- 高级 RAG
- 模块化 RAG
下面是所有三种 RAG 范式(Naive RAG、Advanced RAG 和 Modular RAG)之间的比较。
RAG三种范式的比较
简单 RAG
简单 RAG 管道由以下关键阶段组成:
数据索引
- 数据加载:这涉及导入所有要使用的文档或信息。
- 数据分割:大文档被分成更小的部分,例如每个部分不超过 500 个字符。
- 数据嵌入:使用嵌入模型将数据转换为向量形式,使其易于计算机理解。
- 数据存储:这些向量嵌入保存在向量数据库中,以便于搜索。
数据召回
当用户提出问题时:
- 用户的输入首先使用数据索引阶段的相同嵌入模型转换为向量(查询向量)。
- 然后将该查询向量与向量数据库中的所有向量进行匹配,以找到可能包含用户问题的答案的最相似的向量(例如,使用欧几里得距离度量)。此步骤是关于识别相关知识块。
增强与生成
LLM 模型采用用户的问题和从向量数据库检索的相关信息来创建响应。此过程将问题与已识别的数据相结合(增强)以生成答案(生成)。
Naive RAG 的问题
Naive RAG 在各个阶段都面临着挑战:
- 检索——未能检索所有相关块或检索不相关块。
- 增强——从可能不连贯或包含重复信息的检索块中集成上下文的挑战。
- 生成— LLM 可能会生成不基于所提供的上下文(检索到的块)的答案,或者基于检索到的不相关上下文生成答案。
高级 RAG
高级 RAG 策略的开发是为了解决 Naive RAG 面临的挑战。以下是关键高级 RAG 技术的概述。
RAG 应用程序必须有效地从数据源检索相关文档。但每一步都面临着多重挑战。
- 我们如何实现文档和查询的准确语义表示?
- 什么方法可以对齐查询和文档(块)的语义空间?
- 检索员的输出如何与LLM的偏好保持一致?
这里我概述一下检索前、检索和检索后策略:
预检索
- 如何优化数据索引?
- 提高数据质量——删除不相关的信息,消除实体和术语中的歧义,确认事实的准确性,维护上下文并更新过时的信息。
- 优化索引结构- 优化块大小以捕获相关上下文或从图形结构添加信息以捕获实体之间的关系。
- 添加元数据— 将日期、章节、小节、目的或任何其他相关信息作为元数据添加到块中,以改进数据过滤
块优化——当使用外部数据源/文档构建 RAG 管道时,第一步是将它们分解成更小的块以提取细粒度的特征。然后嵌入块来表示它们的语义。但是嵌入太大或太小的文本块可能会导致次优结果,因此我们需要针对 RAG 管道中使用的文档类型优化块大小。
关键预检索技术总结
- 滑动窗口— 使用块之间重叠的分块方法。
- 自动合并检索——在初始搜索阶段利用小文本块,随后向语言模型提供更大的相关文本块进行处理。
- 摘要嵌入——根据文档摘要(或摘要)优先进行 Top-K 检索,提供对整个文档上下文的全面理解。
- 元数据过滤——利用文档元数据来增强过滤过程。
- 图索引——将实体和关系转换为节点和连接,显着提高相关性。
-
检索
一旦确定了块的大小,下一步就是使用嵌入模型将这些块嵌入到语义空间中。
在检索阶段,目标是识别要查询的最相关的块。这是通过计算查询和块之间的相似性来完成的。在这里,我们可以优化用于嵌入查询和块的嵌入模型。
领域知识微调——为了确保嵌入模型准确捕获 RAG 系统的特定领域信息,使用特定领域数据集进行微调非常重要。用于嵌入模型微调的数据集应包含:查询、语料库和相关文档。
-
相似性度量——有许多不同的度量来衡量向量之间的相似性。相似性度量的选择也是一个优化问题。矢量数据库(ChromaDB、Pinecode、Weaviate...)支持多种相似性指标。以下是不同相似性度量的几个示例:
- 余弦相似度
- 欧氏距离 (L2)
- 点积
- L2 平方距离
- 曼哈顿距离
检索后
从向量数据库检索上下文数据(块)后,下一步是将上下文与查询合并,作为 LLM 的输入。但一些检索到的块可能是重复的、有噪声的或包含不相关的信息。这可能会影响 LLM 如何处理给定的上下文。
下面我列出了一些用于克服这些问题的策略。
重新排名- 对检索到的信息重新排名,以优先考虑最相关的内容。当引入额外的上下文时,LLM 通常会面临性能下降,而重新排名通过对检索到的块进行重新排名并识别 Top-K 最相关的块(然后将其用作 LLM 中的上下文)来解决此问题。LlamaIndex、Langchain 、 HayStack等库提供不同的重新排序器。
及时压缩——检索到的信息可能会有噪音,在提交给LLM之前压缩不相关的上下文并减少上下文长度很重要。使用小语言模型计算即时互信息或复杂度来估计元素重要性。当上下文较长时使用摘要技巧。
模块化 RAG
模块化 RAG 集成了 Adanced RAG 的各种模块和技术,以改进整个 RAG 系统。例如,合并用于相似性检索的搜索模块并在检索器中应用微调方法。模块化 RAG 成为构建 RAG 应用程序时的标准范例。模块的一些示例:
搜索模块——除了从向量数据库中检索上下文之外,搜索模块还集成来自其他来源的数据,例如搜索引擎、表格数据、知识图等。
内存模块- 将内存组件添加到 RAG 系统中,其中 LLM 不仅可以引用从向量数据库检索的块,还可以引用存储在系统内存中的先前查询和答案。
融合——涉及原始查询和扩展查询的并行矢量搜索、智能重新排名以优化结果,以及将最佳结果与新查询配对。
路由——查询路由决定用户查询的后续操作,例如摘要、搜索特定数据库等。